From Weights to Features: SAE-Guided Activation Regularization for LLM Continual Learning
Pith reviewed 2026-06-26 05:29 UTC · model grok-4.3
The pith
SAE-guided activation regularization outperforms EWC on LLM continual learning by protecting monosemantic features instead of polysemantic weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
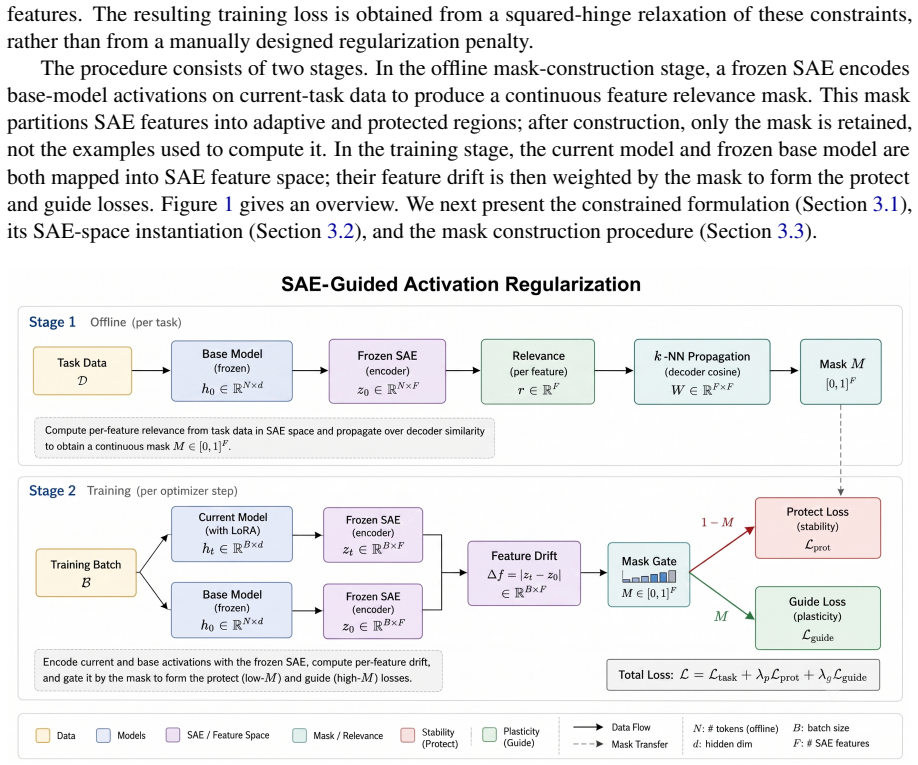
The central claim is that regularizing in the SAE feature space yields a more selective stability-plasticity trade-off than weight-space regularization, because the SAE dictionary renders task knowledge linearly separable and allows a mask computed solely from current-task activations to protect the relevant concepts without replay or task-specific modules.
What carries the argument
The SAE feature mask, a binary selector over the pretrained sparse autoencoder dictionary that is computed from current-task activations and inserted into the derived regularization loss.
If this is right
- Only the compact SAE feature mask, not any prior-task examples, needs to be stored for future training steps.
- Because the feature space has far lower dimensionality than the parameter space, memory overhead is reduced relative to EWC-style methods.
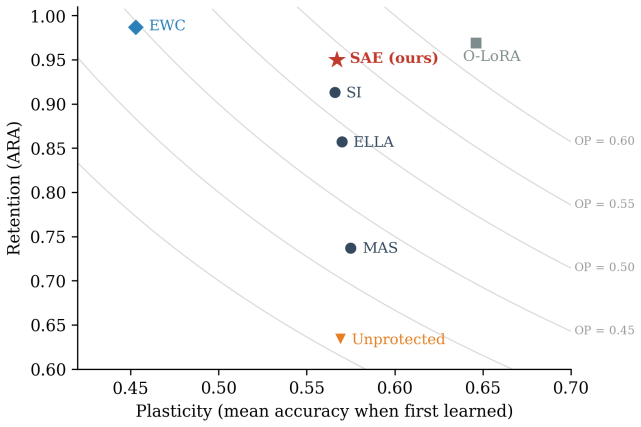
- The method achieves the highest scores on TRACE and MedCL among approaches that introduce no task-specific architectural components.
- Weight-space protection is shown to be nearly non-selective at the concept level, while the SAE mask is selective.
Where Pith is reading between the lines
- If the same SAE dictionary remains useful across many sequential tasks, the mask-construction step could be reused rather than recomputed from scratch each time.
- The separability result suggests that other representation-learning techniques that produce approximately monosemantic bases might serve as drop-in replacements for the SAE dictionary.
- Because the loss is derived as a constrained optimization problem in which EWC appears as a one-sided special case, the same derivation may admit additional regularizers that operate on different subspaces.
Load-bearing premise
Pretrained sparse autoencoders supply a monosemantic feature dictionary in which task-relevant knowledge is linearly separable and can be isolated by a mask computed only from current-task data.
What would settle it
An experiment showing that task-relevant activations are not linearly separable in the SAE feature space, or that the method fails to exceed EWC performance on the TRACE benchmark when both are given identical compute and data constraints, would falsify the claim.
Figures
read the original abstract
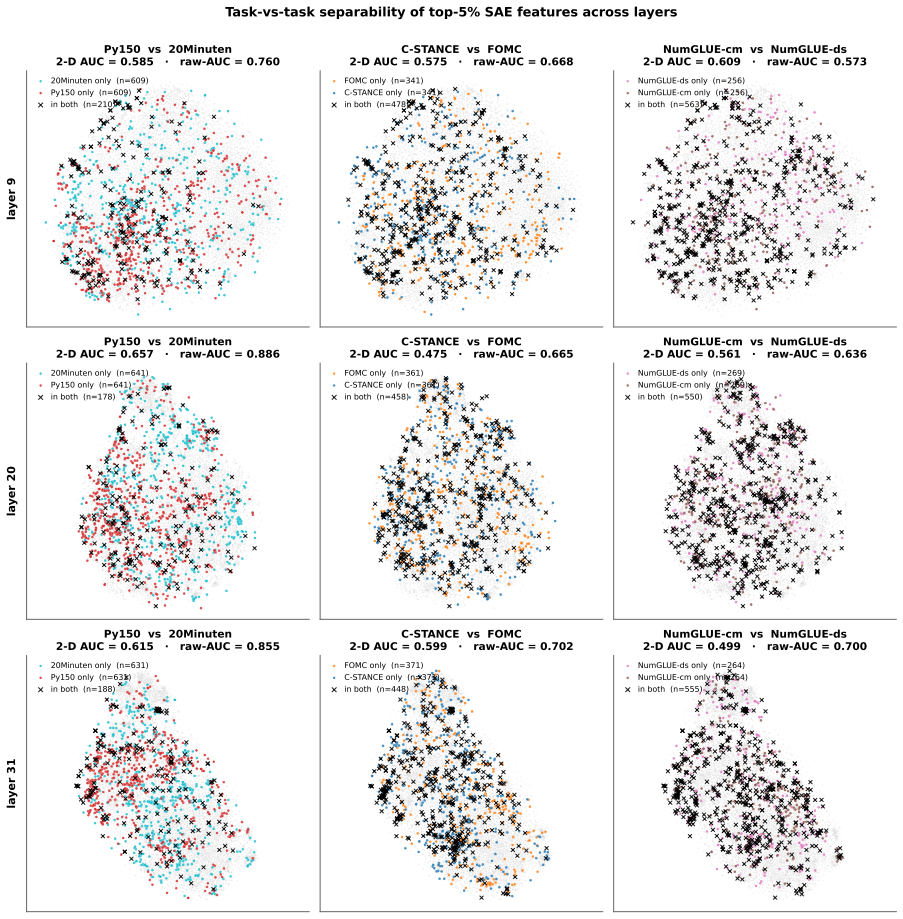
Weight-space regularization methods such as Elastic Weight Consolidation (EWC) are the standard approach to catastrophic forgetting in continual learning. However, those methods tend to underperform when applied to large language models. We argue that such underperformance can be partly explained by the ``polysemantic'' nature of large language models: per-weight importance estimates utilized by EWC-style regularization are too coarse and cannot isolate the knowledge that needs protection. In this paper, we propose regularizing instead in the model's activation space, using pretrained Sparse Autoencoders (SAEs) as a monosemantic feature dictionary. From the perspective of constrained optimization, we derive a new loss function that uses the SAE feature dictionary to explicitly balance stability and plasticity, and show that EWC is a special case in the one-sided weight-space penalty setting. Unlike replay-based methods that store or revisit examples from earlier tasks, our method requires no previous-task data after mask construction: current-task data is used to compute a compact SAE feature mask, and only this mask is retained for later training. Further, since the feature space has significantly lower dimensionality than the parameter space, the proposed method is more memory efficient. On the TRACE and MedCL continual learning benchmarks, the method achieves the strongest result among approaches without introducing task-specific architectural components, also surpassing traditional weight-space regularization methods like EWC. Beyond performance comparisons, we provide empirical evidence for the polysemanticity thesis: task-relevant representations are linearly separable in the SAE feature basis but indistinguishable from chance in the weight basis, and weight-space protection is nearly non-selective at the concept level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that weight-space regularization methods like EWC underperform on LLMs due to polysemanticity of per-weight importance estimates. It proposes SAE-guided activation regularization, using pretrained Sparse Autoencoders as a monosemantic feature dictionary to derive (via constrained optimization) a new loss balancing stability and plasticity; EWC is recovered as a special case under one-sided weight-space penalty. The method computes a compact SAE feature mask from current-task data only (no prior-task examples retained after mask construction), retains only the mask for future training, and is more memory-efficient due to lower dimensionality. On TRACE and MedCL benchmarks it reports the strongest results among methods without task-specific architectural components and surpasses EWC. It also supplies empirical evidence that task-relevant representations are linearly separable in the SAE feature basis but indistinguishable from chance in the weight basis, with weight-space protection nearly non-selective at the concept level.
Significance. If the central claims hold, this would be a meaningful contribution to continual learning for LLMs: it offers a practical alternative to replay and weight-regularization baselines that avoids storing prior data after mask construction while achieving stronger benchmark performance. The memory-efficiency argument and the explicit recovery of EWC as a special case are attractive. The linear-separability evidence, if robust, would lend concrete support to the polysemanticity thesis and could motivate further feature-space rather than parameter-space regularization work.
major comments (1)
- [Abstract (method paragraph)] Abstract (method paragraph): the claim that a mask computed solely from current-task activations in the SAE basis isolates task-relevant directions for selective protection (without any access to prior-task examples after mask construction) is load-bearing for both the reported performance gains over EWC and the polysemanticity evidence. If the pretrained SAEs remain entangled or the mask fails to exclude non-task directions, the derived loss reduces to a coarser regularizer comparable to EWC, and the stated linear-separability gap versus the weight basis would not hold.
Simulated Author's Rebuttal
We thank the referee for this detailed comment on the central claim regarding mask construction. We address the concern point-by-point below, grounding our response in the manuscript's method and empirical results.
read point-by-point responses
-
Referee: [Abstract (method paragraph)] Abstract (method paragraph): the claim that a mask computed solely from current-task activations in the SAE basis isolates task-relevant directions for selective protection (without any access to prior-task examples after mask construction) is load-bearing for both the reported performance gains over EWC and the polysemanticity evidence. If the pretrained SAEs remain entangled or the mask fails to exclude non-task directions, the derived loss reduces to a coarser regularizer comparable to EWC, and the stated linear-separability gap versus the weight basis would not hold.
Authors: We agree this claim is load-bearing and appreciate the referee surfacing the underlying assumption. The mask is constructed exclusively from current-task activations by identifying SAE features with high activation on the current task (via the constrained optimization that yields the feature-space penalty); only this compact mask is retained, with no prior-task data accessed thereafter. This design is feasible precisely because the SAE basis is treated as monosemantic per the cited prior literature on SAEs. The linear-separability experiments provide direct empirical support: task concepts are linearly separable above chance in the SAE feature space but at chance level in the weight space, and weight-space protection is shown to be nearly non-selective at the concept level. If the mask were non-selective, we would not expect the observed gains over EWC on TRACE and MedCL or the separability gap; the results are therefore consistent with selective protection. We will revise the abstract to cross-reference these experiments and add a brief sentence clarifying the mask-construction procedure. revision: partial
Circularity Check
Derivation from constrained optimization is independent; no reductions to inputs by construction
full rationale
The paper derives its loss from constrained optimization principles and presents EWC as a special case in the one-sided penalty setting. This framing relies on external optimization theory rather than any self-definitional loop, fitted parameter renamed as prediction, or self-citation chain. The mask is computed from current-task data as an explicit design choice, with no prior-task data required afterward, and performance claims are supported by independent empirical results on TRACE and MedCL. No equations or sections in the provided text exhibit a quantity that reduces to its own inputs by construction. The polysemanticity evidence is presented as empirical observation, not a derived prediction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained sparse autoencoders decompose LLM activations into a monosemantic feature dictionary
- domain assumption Task-relevant knowledge is linearly separable in the SAE feature basis
Reference graph
Works this paper leans on
-
[1]
How does a brain build a cognitive code? , author=
-
[2]
Studies of Mind and Brain: Neural Principles of Learning, Perception, Development, Cognition, and Motor Control , author=
-
[3]
Catastrophic interference in connectionist networks: The sequential learning problem , author=
-
[4]
Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions , author=
-
[5]
2017 , doi=
Overcoming catastrophic forgetting in neural networks , author=. 2017 , doi=
2017
-
[6]
Continual learning through synaptic intelligence , author=
-
[7]
Memory Aware Synapses: Learning what (not) to forget , author=
-
[8]
Natural continual learning: Success is a journey, not (just) a destination , author=
-
[9]
Gradient episodic memory for continual learning , author=
-
[10]
Efficient Lifelong Learning with
Chaudhry, Arslan and Ranzato, Marc'Aurelio and Rohrbach, Marcus and Elhoseiny, Mohamed , booktitle=ICLR, year=. Efficient Lifelong Learning with
-
[11]
Dark Experience for General Continual Learning: A Strong, Simple Baseline , author=
-
[12]
, booktitle=CVPR, pages=
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H. , booktitle=CVPR, pages=
-
[13]
Self-improving reactive agents based on reinforcement learning, planning and teaching , author=
-
[14]
Progressive Neural Networks , author=. 1606.04671 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Mallya, Arun and Lazebnik, Svetlana , booktitle=CVPR, pages=
-
[16]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=ICLR, year=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=ICLR, year=
-
[17]
Wang, Xiao and Zhang, Yuansen and Chen, Tianze and Gao, Songyang and Jin, Senjie and Yang, Xianjun and Xi, Zhiheng and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Huang, Xuanjing , journal=ArXiv, eprint=
-
[18]
Orthogonal Subspace Learning for Language Model Continual Learning , author=
-
[19]
Orthogonal Low-rank Adaptation in Lie Groups for Continual Learning of Large Language Models , author=. 2509.06100 , archivePrefix=
-
[20]
Is Parameter Collision Hindering Continual Learning in
Yang, Shuo and Ning, Kun-Peng and Liu, Yu-Yang and Yao, Jia-Yu and Tian, Yong-Hong and Song, Yi-Bing and Yuan, Li , booktitle=COLING, pages=. Is Parameter Collision Hindering Continual Learning in
-
[21]
2024 , doi=
Loss of plasticity in deep continual learning , author=. 2024 , doi=
2024
-
[22]
Understanding Plasticity in Neural Networks , author=
-
[23]
2022 , url=
Toy Models of Superposition , author=. 2022 , url=
2022
-
[24]
2020 , doi=
Zoom In: An Introduction to Circuits , author=. 2020 , doi=
2020
-
[25]
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=
-
[26]
2023 , url=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , url=
2023
-
[27]
and McDougall, Callum and MacDiarmid, Monte and Tamkin, Alex and Durmus, Esin and Hume, Tristan and Mosconi, Francesco and Freeman, C
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L. and McDougall, Callum and MacDiarmid, Monte and Tamkin, Alex and Durmus, Esin and Hume, Tristan and Mosconi, Francesco and Freeman...
-
[28]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramar, Janos and Dragan, Anca and Shah, Rohin and Nanda, Neel , booktitle=BlackboxNLP, pages=. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on. 2024 , doi=
2024
-
[29]
Polysemanticity and Capacity in Neural Networks , author=. 2210.01892 , archivePrefix=
-
[30]
Shenfeld, Idan and Pari, Jyothish and Agrawal, Pulkit , journal=ArXiv, eprint=
-
[31]
Language Models Can Explain Neurons in Language Models , author=
-
[32]
Numerical Optimization , author=
-
[33]
Zeng, Min and Zhou, Shuang and Zhan, Zaifu and Zhang, Rui , journal=ArXiv, eprint=
-
[34]
Learning without Forgetting , author=
-
[35]
Ruvolo, Paul and Eaton, Eric , booktitle=ICML, series=PMLR, volume=
-
[36]
Shuttleworth, Reece and Andreas, Jacob and Torralba, Antonio and Sharma, Pratyusha , journal=ArXiv, eprint=
-
[37]
Zhang, Mingxu and Li, Yuhan and Li, Lujundong and Shen, Dazhong and Xiong, Hui and Sun, Ying , journal=ArXiv, eprint=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.