MiniGPT: Rebuilding GPT from First Principles
Pith reviewed 2026-05-20 13:15 UTC · model grok-4.3
The pith
A 10.77 million parameter MiniGPT reaches 1.478 validation loss and generates Shakespeare-style dialogue from character tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
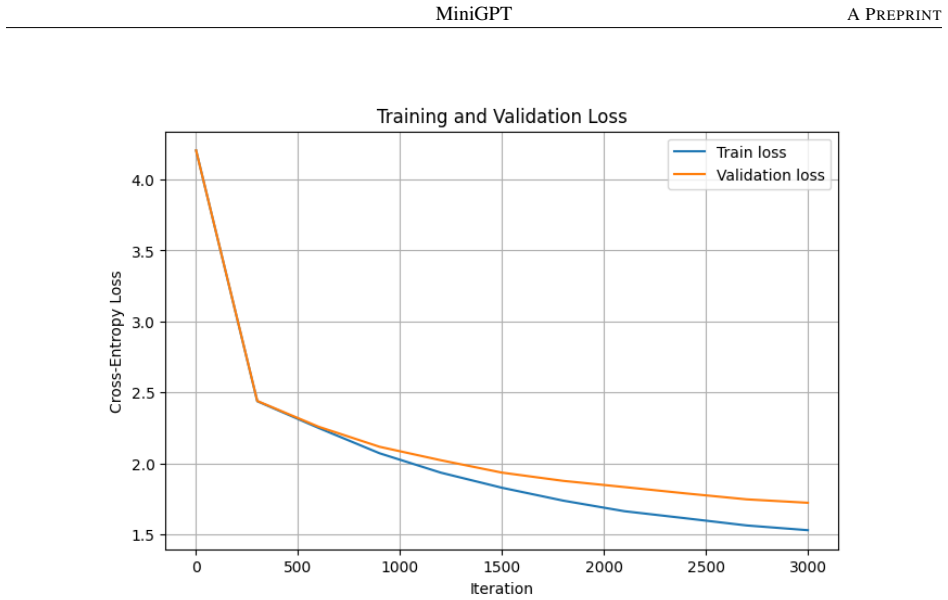
MiniGPT implements the full GPT-style autoregressive pipeline from first principles, including character-level tokenization, learned positional embeddings, causal multi-head self-attention, pre-LayerNorm transformer blocks with residual connections and feed-forward layers, teacher-forced cross-entropy training, and autoregressive sampling at inference time. On Tiny Shakespeare, the 0.83M-parameter baseline attains 1.7236 validation loss after 3000 iterations while the 10.77M-parameter model with extended context and adjusted settings reaches 1.4780 loss and emits text that follows Shakespearean dialogue structure.
What carries the argument
Causal multi-head self-attention inside pre-LayerNorm residual transformer blocks that enable stable next-token prediction on limited text data.
If this is right
- Small-scale models can capture stylistic regularities in character-level text after a few thousand iterations.
- Validation loss directly tracks improvements in generated coherence under fixed sampling temperature.
- Checkpointing on lowest validation loss yields more consistent output than final-iteration weights.
- Single-file implementations can replicate the core training loop of larger autoregressive systems.
- Character-level tokenization suffices for stylistic mimicry on datasets of a few megabytes.
Where Pith is reading between the lines
- The same notebook structure could be reused with word-level or subword tokenization to measure how token granularity affects convergence speed on the same data.
- Adding a simple temperature sweep during generation would reveal the trade-off between coherence and diversity that the paper leaves implicit.
- Comparing training dynamics across different context lengths in the same codebase would isolate the contribution of longer attention spans.
- The approach suggests that minimal working examples can serve as testbeds for experimenting with optimizer choices or initialization schemes before scaling up.
Load-bearing premise
The independently written notebook code correctly realizes the listed components without hidden bugs that would produce the reported validation losses or generation behavior.
What would settle it
Executing the notebook on the same Tiny Shakespeare split and checking whether the final generated samples contain recognizable dialogue turns or whether validation loss remains above 2.0 would confirm or refute the performance claim.
Figures

read the original abstract
This paper presents MiniGPT, a compact from-scratch implementation of GPT-style autoregressive language modeling in PyTorch. The aim is to rebuild the core GPT pipeline from first principles after studying the design of nanoGPT by Andrej Karpathy, while keeping the model and training code independently written in a single notebook. MiniGPT implements token and positional embeddings, causal multi-head self-attention, pre-LayerNorm Transformer blocks, residual connections, feed-forward MLP layers, next-token cross-entropy training (teacher forcing), validation tracking, checkpoint selection, and autoregressive text generation. This paper evaluates the implementation on Tiny Shakespeare dataset using character-level tokenization. A baseline 0.83M-parameter model reaches a validation loss of 1.7236 after 3000 training iterations. A stronger 10.77M-parameter configuration, using a larger context length and improved training settings, reaches a best validation loss of 1.4780 and generates text with recognizable Shakespeare-style dialogue structure. MiniGPT does not introduce a new language-model architecture. Instead, it documents a clear and reproducible implementation path from raw text to trained character-level generation, including design choices, training behavior, generation quality, and practical limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MiniGPT, a compact from-scratch PyTorch implementation of a standard GPT-style autoregressive language model in a single notebook. It implements token and positional embeddings, causal multi-head self-attention, pre-LayerNorm Transformer blocks with residual connections and feed-forward MLPs, next-token cross-entropy training via teacher forcing, validation tracking, checkpoint selection, and autoregressive generation. Evaluated on the Tiny Shakespeare dataset with character-level tokenization, a 0.83M-parameter baseline reaches 1.7236 validation loss after 3000 iterations, while a 10.77M-parameter configuration with larger context and improved settings reaches 1.4780 validation loss and produces text with recognizable Shakespeare-style dialogue structure. The work explicitly states it introduces no new architecture and instead documents a reproducible implementation path including design choices, training behavior, and limitations.
Significance. If the implementation details are accurate and the notebook code is provided for verification, the manuscript offers a clear pedagogical resource for understanding core GPT components through direct execution on a fixed dataset. Its explicit documentation of an independently written, reproducible pipeline from raw text to generation, including reported validation losses and qualitative outputs, provides educational value. However, as the paper introduces no novel methods, architectures, or theoretical contributions and rests entirely on standard components, its significance to the research literature is limited to teaching and learning rather than advancing the field.
major comments (1)
- [Abstract and implementation description] The central performance claims rest on the reported validation losses (1.7236 and 1.4780) and generation behavior, yet the manuscript describes the components without including the actual notebook code, training logs, or hyperparameter settings sufficient to independently verify the correctness of causal attention masking, residual connections, or loss computation.
minor comments (3)
- [Evaluation section] The abstract and text refer to 'improved training settings' for the 10.77M model without listing the specific changes in context length, batch size, learning rate, or optimizer relative to the baseline 0.83M configuration.
- [Generation results] Generation quality is described qualitatively as 'recognizable Shakespeare-style dialogue structure' but lacks any quantitative metrics (e.g., perplexity on held-out text or comparison to baseline outputs) to support the claim.
- [Introduction] The manuscript cites the design of nanoGPT but does not include a reference list or explicit comparison of implementation differences that would clarify the 'independently written' aspect.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the pedagogical value of MiniGPT as a reproducible implementation resource. We agree that full verification details are essential for the reported results and have prepared revisions to address this directly.
read point-by-point responses
-
Referee: [Abstract and implementation description] The central performance claims rest on the reported validation losses (1.7236 and 1.4780) and generation behavior, yet the manuscript describes the components without including the actual notebook code, training logs, or hyperparameter settings sufficient to independently verify the correctness of causal attention masking, residual connections, or loss computation.
Authors: We acknowledge this limitation in the current manuscript, which prioritizes a clear prose description of the pipeline over embedded code for readability. To enable independent verification, the revised version will include: (1) the complete single-notebook PyTorch source code as a new appendix, (2) a detailed table of all hyperparameters for both the 0.83M and 10.77M configurations (including context length, batch size, learning rate schedule, and optimizer settings), and (3) excerpts from training logs documenting the exact validation losses at key iterations. These additions will allow direct inspection of the causal attention mask implementation, residual connections around attention and FFN blocks, pre-LayerNorm placement, and cross-entropy loss computation under teacher forcing. We have already prepared these materials and will incorporate them without changing the paper's core claims or focus. revision: yes
Circularity Check
No significant circularity: results are direct empirical measurements from code execution
full rationale
The paper presents an educational reimplementation of the standard GPT pipeline (embeddings, causal MHA, pre-LayerNorm blocks, residuals, next-token cross-entropy) on Tiny Shakespeare with character tokenization. All reported numbers (validation losses of 1.7236 and 1.4780, generation behavior) are outcomes of running the described training procedure on a fixed dataset. No equations, predictions, or first-principles derivations are claimed; the work explicitly states it introduces no new architecture and documents a reproducible implementation path. The reference to nanoGPT is limited to design inspiration with independently written code, introducing no self-citation load-bearing step or ansatz smuggling. The derivation chain is self-contained against external benchmarks (the dataset and standard components), with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- context length and training hyperparameters
axioms (1)
- domain assumption The PyTorch code correctly realizes causal multi-head self-attention and pre-LayerNorm transformer blocks as described.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MiniGPT implements token and positional embeddings, causal multi-head self-attention, pre-LayerNorm Transformer blocks, residual connections, feed-forward MLP layers, next-token cross-entropy training
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A 10.77M-parameter MiniGPT configuration reaches a best validation loss of 1.4780
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
OpenAI technical report , year=
Improving language understanding by generative pre-training , author=. OpenAI technical report , year=
-
[4]
OpenAI technical report , year=
Language models are unsupervised multitask learners , author=. OpenAI technical report , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
minGPT: A minimal PyTorch re-implementation of GPT , author=. 2020 , howpublished=
work page 2020
-
[7]
nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs , author=. 2022 , howpublished=
work page 2022
-
[8]
International Conference on Learning Representations , year=
Decoupled weight decay regularization , author=. International Conference on Learning Representations , year=
-
[11]
Deep learning in neural networks: An overview , author=. Neural Networks , volume=. 2015 , publisher=
work page 2015
-
[12]
Journal of Machine Learning Research , volume=
A neural probabilistic language model , author=. Journal of Machine Learning Research , volume=
-
[13]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics , pages=
Neural machine translation of rare words with subword units , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics , pages=. 2016 , doi=
work page 2016
-
[14]
Transformers: State-of-the-Art Natural Language Processing , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=. 2020 , publisher=
work page 2020
-
[15]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep Residual Learning for Image Recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2016 , doi=
work page 2016
-
[16]
Journal of Machine Learning Research , volume=
Dropout: A Simple Way to Prevent Neural Networks from Overfitting , author=. Journal of Machine Learning Research , volume=. 2014 , url=
work page 2014
-
[17]
Using the Output Embedding to Improve Language Models , author=. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics , pages=. 2017 , publisher=
work page 2017
-
[18]
Proceedings of the 37th International Conference on Machine Learning , pages=
On Layer Normalization in the Transformer Architecture , author=. Proceedings of the 37th International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[19]
char-rnn: Multi-layer Recurrent Neural Networks for Character-Level Language Models , author=. 2015 , howpublished=
work page 2015
-
[20]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[21]
International Conference on Learning Representations , year=
SGDR: Stochastic Gradient Descent with Warm Restarts , author=. International Conference on Learning Representations , year=
-
[22]
Proceedings of the 30th International Conference on Machine Learning , pages=
On the Difficulty of Training Recurrent Neural Networks , author=. Proceedings of the 30th International Conference on Machine Learning , pages=. 2013 , publisher=
work page 2013
-
[23]
International Conference on Learning Representations , year=
Mixed Precision Training , author=. International Conference on Learning Representations , year=
-
[24]
Neural Networks: Tricks of the Trade , editor=
Early Stopping---But When? , author=. Neural Networks: Tricks of the Trade , editor=. 1998 , publisher=
work page 1998
-
[25]
International Conference on Learning Representations , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
work page 2022
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Character-Level Language Modeling with Deeper Self-Attention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2019 , doi=
work page 2019
-
[29]
Advances in Neural Information Processing Systems , volume=
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Positioning and Power in Academic Publishing: Players, Agents and Agendas , pages=
Jupyter Notebooks---a Publishing Format for Reproducible Computational Workflows , author=. Positioning and Power in Academic Publishing: Players, Agents and Agendas , pages=. 2016 , publisher=
work page 2016
- [31]
-
[32]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521 0 (7553): 0 436--444, 2015. doi:10.1038/nature14539
-
[33]
Schmidhuber, Deep learning in neural networks: An overview, Neural Networks 61 (2015) 85 – 117
J \"u rgen Schmidhuber. Deep learning in neural networks: An overview. Neural Networks, 61: 0 85--117, 2015. doi:10.1016/j.neunet.2014.09.003
-
[34]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[35]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. OpenAI technical report, 2018. URL https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
work page 2018
-
[36]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI technical report, 2019. URL https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
work page 2019
-
[37]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page 1901
-
[38]
mingpt: A minimal pytorch re-implementation of gpt
Andrej Karpathy. mingpt: A minimal pytorch re-implementation of gpt. https://github.com/karpathy/minGPT, 2020. GitHub repository
work page 2020
-
[39]
nanogpt: The simplest, fastest repository for training/finetuning medium-sized gpts
Andrej Karpathy. nanogpt: The simplest, fastest repository for training/finetuning medium-sized gpts. https://github.com/karpathy/nanoGPT, 2022. GitHub repository
work page 2022
-
[40]
A neural probabilistic language model
Yoshua Bengio, R \'e jean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of Machine Learning Research, 3: 0 1137--1155, 2003
work page 2003
-
[41]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1715--1725, 2016. doi:10.18653/v1/P16-1162
-
[42]
Character-level language modeling with deeper self-attention
Rami Al-Rfou, Dokook Choe, Noah Constant, Mandy Guo, and Llion Jones. Character-level language modeling with deeper self-attention. Proceedings of the AAAI Conference on Artificial Intelligence, 33 0 (1): 0 3159--3166, 2019. doi:10.1609/aaai.v33i01.33013159
-
[43]
Transformers: State-of-the-Art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art na...
-
[44]
Deep residual learning for image recognition,
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770--778, 2016. doi:10.1109/CVPR.2016.90
-
[45]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. In Proceedings of the 37th International Conference on Machine Learning, pages 10524--10533. PMLR, 2020
work page 2020
-
[47]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Dropout: A simple way to prevent neural networks from overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15 0 (56): 0 1929--1958, 2014. URL https://jmlr.org/papers/v15/srivastava14a.html
work page 1929
-
[49]
Using the output embedding to improve language models
Ofir Press and Lior Wolf. Using the output embedding to improve language models. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, pages 157--163. Association for Computational Linguistics, 2017. doi:10.18653/v1/E17-2025
-
[50]
char-rnn: Multi-layer recurrent neural networks for character-level language models
Andrej Karpathy. char-rnn: Multi-layer recurrent neural networks for character-level language models. https://github.com/karpathy/char-rnn, 2015. GitHub repository
work page 2015
-
[51]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[52]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[53]
Sgdr: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=Skq89Scxx
work page 2017
-
[54]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, pages 1310--1318. PMLR, 2013. URL https://proceedings.mlr.press/v28/pascanu13.html
work page 2013
-
[55]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=r1gs9JgRZ
work page 2018
-
[56]
Lutz Prechelt. Early stopping---but when? In Genevieve B. Orr and Klaus-Robert M \"u ller, editors, Neural Networks: Tricks of the Trade, volume 1524 of Lecture Notes in Computer Science, pages 55--69. Springer, 1998. doi:10.1007/3-540-49430-8_3
-
[57]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rygGQyrFvH
work page 2020
-
[58]
Minigpt: Rebuilding gpt from first principles
Jibin Joseph. Minigpt: Rebuilding gpt from first principles. https://github.com/jibin10/MiniGPT, 2026. GitHub repository
work page 2026
-
[59]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[60]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perfo...
work page 2019
-
[62]
pp 87 -- 90, @doi 10.3233/978-1-61499-649-1-87
Thomas Kluyver, Benjamin Ragan-Kelley, Fernando P \'e rez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, Jessica Hamrick, Jason Grout, Sylvain Corlay, Paul Ivanov, Dami \'a n Avila, Safia Abdalla, and Carol Willing. Jupyter notebooks---a publishing format for reproducible computational workflows. In Positioning and Power in Academic ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.