The Language-Energy Divide: Measuring Energy Costs of Multilingual LLM Inference
Pith reviewed 2026-06-26 12:10 UTC · model grok-4.3
The pith
LLM inference energy use varies by up to 179 times across languages, with Pashto far costlier than English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
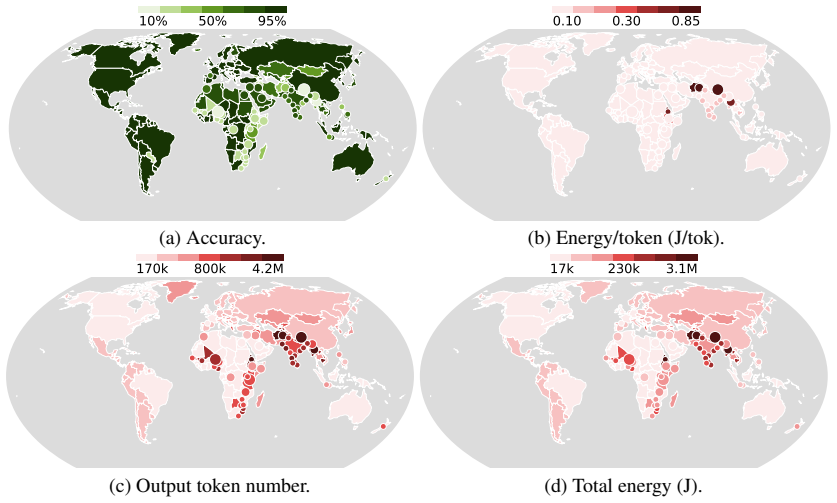
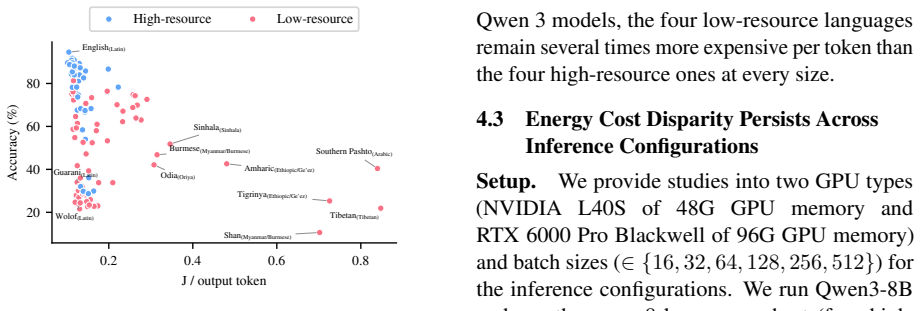
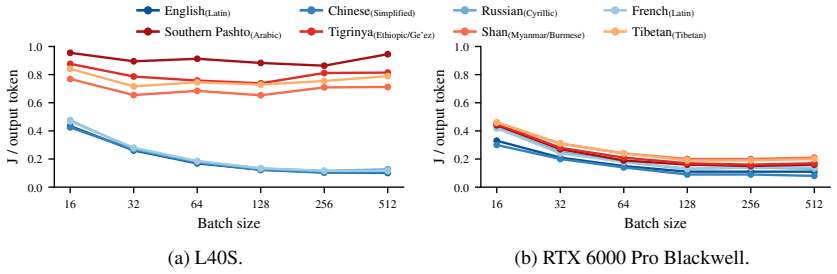
Energy consumption per output token varies by up to 8.3 times across languages, while total energy for a fixed set of requests varies by up to 179 times between the cheapest (English, 17.6 kJ) and the most expensive (Pashto, 3,147 kJ) languages. This disparity is driven by two compounding factors: higher per-token energy costs for languages using complex or rare scripts, and more tokens generated for low-resource languages. Languages with the highest energy footprints also tend to achieve the lowest task accuracy. The energy divide persists across models, hardware, and tasks.
What carries the argument
Systematic measurement of per-token and total inference energy across languages, isolating script complexity and output token count as the two main cost drivers.
If this is right
- Energy must be tracked as a standard metric when evaluating multilingual models.
- Languages with complex scripts and low resources incur both higher energy cost and lower accuracy.
- Deployment systems can reduce total energy by routing or optimizing per language.
- Model cards and evaluation checklists should include energy figures alongside accuracy.
Where Pith is reading between the lines
- Training objectives that balance tokenization efficiency across scripts could shrink the measured gap.
- Global deployment decisions may start favoring high-resource languages to control energy budgets.
- Hardware accelerators tuned for common scripts would leave larger relative savings on the table for rare scripts.
Load-bearing premise
The energy measurements accurately reflect only the model's inference work and are not distorted by language-specific hardware or software effects.
What would settle it
Repeating the measurements and finding that energy per token is the same for all languages once token count and script type are controlled for would falsify the claimed divide.
Figures


read the original abstract
Large language models (LLMs) are increasingly deployed in multilingual settings, yet the energy costs of serving these models across different languages remain poorly understood. We present a systematic study of inference energy consumption across languages with ML.Energy framework (Chung et al., 2026). We find striking disparities: energy consumption per output token varies by up to 8.3 times across languages, while total energy for a fixed set of requests varies by up to 179 times between the cheapest (English, 17.6 kJ) and the most expensive (Pashto, 3,147 kJ) languages. Our analysis shows that this disparity is driven by two compounding factors: (1) higher per-token energy costs for languages using complex or rare scripts, and (2) more tokens generated for low-resource languages. Moreover, we find a double cost + performance penalty: languages with the highest energy footprints also tend to achieve the lowest task accuracy. We reveal that the energy divide persists across models, hardware, and tasks, suggesting a systemic energy inequity in multilingual LLM deployment. Finally, we recommend that the community treat energy as a first-class evaluation axis, extend reporting checklists and model cards to include it, and adopt deployment-side mitigations for better energy efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical measurement study of LLM inference energy consumption across languages, using the ML.Energy framework (Chung et al., 2026). It claims energy per output token varies by up to 8.3× across languages and total energy for fixed requests by up to 179× (English at 17.6 kJ vs. Pashto at 3,147 kJ), driven by script complexity and higher token counts for low-resource languages. A double cost-performance penalty is reported, with disparities persisting across models, hardware, and tasks; recommendations include treating energy as a first-class metric in evaluations and model cards.
Significance. If the measurements hold after validation, the quantified energy disparities would establish a concrete basis for energy inequity in multilingual LLM deployment, with direct implications for fairness, efficiency mitigations, and evaluation practices. The cross-model/hardware/task consistency and identification of compounding factors (per-token cost plus token volume) add weight to the empirical contribution.
major comments (1)
- [Methods] Methods section (framework description): The headline claims of 8.3× per-token and 179× total-energy disparities rest entirely on outputs from the ML.Energy framework. No cross-language calibration, independent validation against direct power metering, or audit for potential artifacts (tokenizer overhead differences, GPU kernel scheduling by script, or power-sensor sampling biases that could correlate with output length or character set) is described. Without this, the reported ratios cannot be guaranteed to isolate language/script effects from implementation factors.
minor comments (2)
- [Abstract] Abstract: The summary of findings does not include sample sizes, number of requests per language, error bars, or statistical tests supporting the 8.3× and 179× ratios.
- Throughout: The citation to Chung et al. (2026) should clarify whether the framework paper is peer-reviewed or an arXiv preprint, and whether any language-specific extensions were made.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below, agreeing that the methods section requires expansion to better document the framework's applicability.
read point-by-point responses
-
Referee: [Methods] Methods section (framework description): The headline claims of 8.3× per-token and 179× total-energy disparities rest entirely on outputs from the ML.Energy framework. No cross-language calibration, independent validation against direct power metering, or audit for potential artifacts (tokenizer overhead differences, GPU kernel scheduling by script, or power-sensor sampling biases that could correlate with output length or character set) is described. Without this, the reported ratios cannot be guaranteed to isolate language/script effects from implementation factors.
Authors: We agree that the current methods section does not sufficiently detail the validation steps underlying the ML.Energy framework or address potential language-specific artifacts. The framework (Chung et al., 2026) was previously validated against direct power metering on the same class of hardware, but our manuscript does not reproduce or extend that validation to the multilingual setting. To address this, we will revise the Methods section to include: (1) a summary of the framework's original calibration and validation procedures, (2) explicit discussion of known limitations with respect to tokenizer behavior and script-dependent GPU kernels, and (3) an appendix containing post-hoc checks (e.g., correlation of measured energy with output length and Unicode block) performed on the existing data. These additions will clarify the scope of the reported ratios without requiring new experiments. revision: yes
Circularity Check
No circularity: empirical measurement study with external framework citation
full rationale
The paper reports empirical measurements of energy consumption using the cited ML.Energy framework. No derivation chain, equations, fitted parameters, or predictions exist that reduce to inputs by construction. The self-citation to Chung et al. 2026 supplies the measurement tool rather than justifying a theoretical result via self-reference; the findings are data outputs, not tautological re-expressions of prior claims. This is a standard non-circular empirical campaign.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. XNLI: Evaluating cross- lingual sentence representations. InProceedings of the 2018 Conference on Empirical Methods in Nat- ural Language Processing, pag...
Pith/arXiv arXiv 2018
-
[2]
Power hungry processing: Watts driving the cost of ai deployment? InProceedings of the 2024 ACM conference on fairness, accountability, and transparency, pages 85–99. Jeff J. Ma, Jae-Won Chung, Jisang Ahn, Yizhuo Liang, Runyu Lu, Akshay Jajoo, Myungjin Lee, and Mosharaf Chowdhury. 2026. Cornfigurator: Auto- mated planning for any-to-any multimodal model s...
Pith/arXiv arXiv 2024
-
[3]
InProceedings of the 22nd Annual Con- ference of the European Association for Machine Translation, pages 91–104, Lisboa, Portugal
Revisiting round-trip translation for quality estimation. InProceedings of the 22nd Annual Con- ference of the European Association for Machine Translation, pages 91–104, Lisboa, Portugal. Euro- pean Association for Machine Translation. Chenxu Niu, Wei Zhang, Jie Li, Yongjian Zhao, Tongyang Wang, Xi Wang, and Yong Chen. 2026. To- kenpowerbench: Benchmarki...
2026
-
[4]
Aleksandar Petrov, Emanuele La Malfa, Philip Torr, and Adel Bibi
The carbon footprint of machine learning train- ing will plateau, then shrink.Computer, 55(7):18– 28. Aleksandar Petrov, Emanuele La Malfa, Philip Torr, and Adel Bibi. 2023. Language model tokenizers introduce unfairness between languages. InThirty- seventh Conference on Neural Information Process- ing Systems. David Pomerenke, Jonas Nothnagel, and Simon ...
arXiv 2023
-
[5]
Improving neural machine translation models with monolingual data. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 86–96, Berlin, Germany. Association for Computational Lin- guistics. Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush V osoughi, Hyung Won Ch...
Pith/arXiv arXiv 2023
-
[6]
Egalitarian language representation in lan- guage models: It all begins with tokenizers. In Proceedings of the 31st International Conference on Computational Linguistics, pages 5987–5996, Abu Dhabi, UAE. Association for Computational Linguis- tics. Junda Wang, Zhichao Yang, Dongxu Zhang, San- jit Singh Batra, and Robert E Tillman. 2026. Estar: Early-stopp...
arXiv 2026
-
[7]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5553–5568, Online
Consistency of a recurrent language model with respect to incomplete decoding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5553–5568, Online. Association for Computational Linguistics. Genta Indra Winata, Samuel Cahyawijaya, Zihan Liu, Zhaojiang Lin, Andrea Madotto, and Pascale Fung
2020
-
[8]
Association for Computational Linguistics
Are multilingual models effective in code- switching? InProceedings of the Fifth Workshop on Computational Approaches to Linguistic Code- Switching, pages 142–153, Online. Association for Computational Linguistics. Weihao Xuan, Rui Yang, Heli Qi, Qingcheng Zeng, Yunze Xiao, Aosong Feng, Dairui Liu, Yun Xing, Jun- jue Wang, Fan Gao, Jinghui Lu, Yuang Jiang...
2025
-
[9]
Jie You, Jae-Won Chung, and Mosharaf Chowdhury
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jie You, Jae-Won Chung, and Mosharaf Chowdhury
-
[10]
In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 119–139
Zeus: Understanding and optimizing {GPU} energy consumption of {DNN} training. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 119–139. Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Shulin Xin, Linhao Zhang, Qi Liu, Aoyan Li, Lu Chen, Xiaojian Zhong, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing S...
2026
-
[11]
DistServe: Disaggregating prefill and decod- ing for goodput-optimized large language model serv- ing. InOSDI. Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Tian Tang, Qinyu Xu, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. 2025. NanoFlow: Towards optimal lar...
2025
-
[12]
Let’s think step by step
<option 4> <per-language primer “Let’s think step by step. ”> The per-language instruction is a translation of the canonical English instruction“Read the passage and answer the multiple-choice question. Reason step by step. Then, on a new last line, write the number of the correct option (1, 2, 3, or 4) in ex- actly this format:”followed by #### N on its ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.