Co-GLANCE: Uncertainty-Aware Active Perception for Heterogeneous Robot Teaming
Pith reviewed 2026-06-27 18:40 UTC · model grok-4.3
The pith
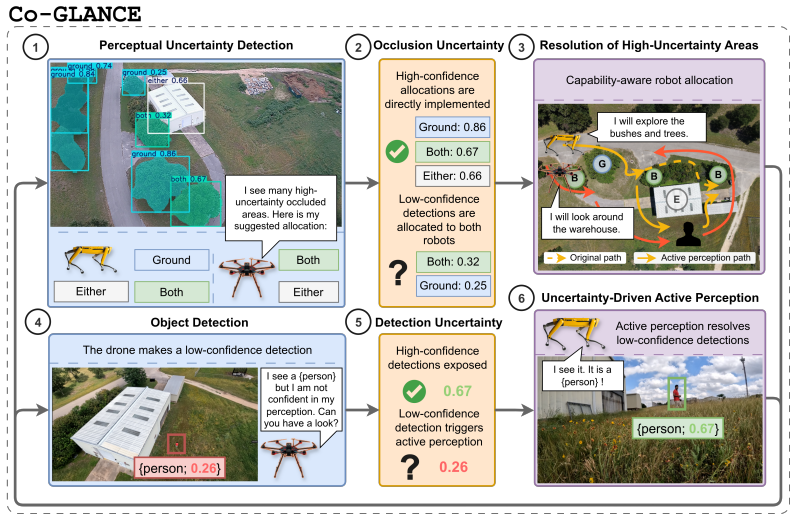
Co-GLANCE distills vision-language model reasoning into a compact onboard system that quantifies uncertainty and dispatches robots to resolve occlusions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
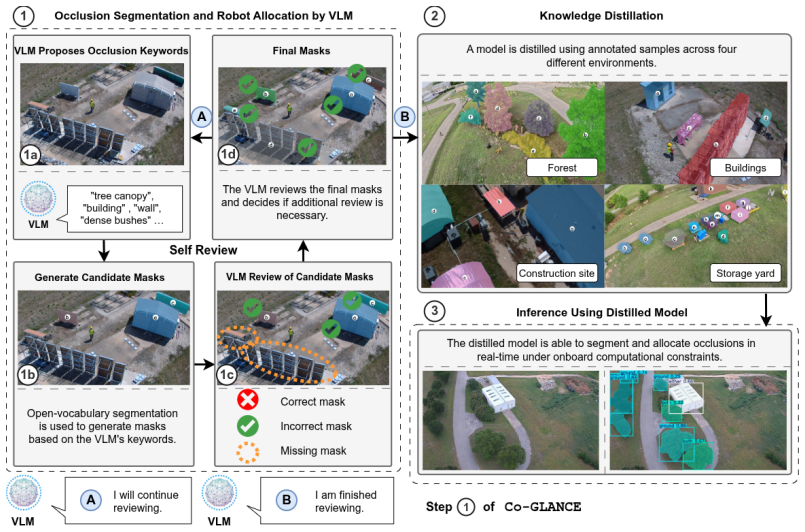
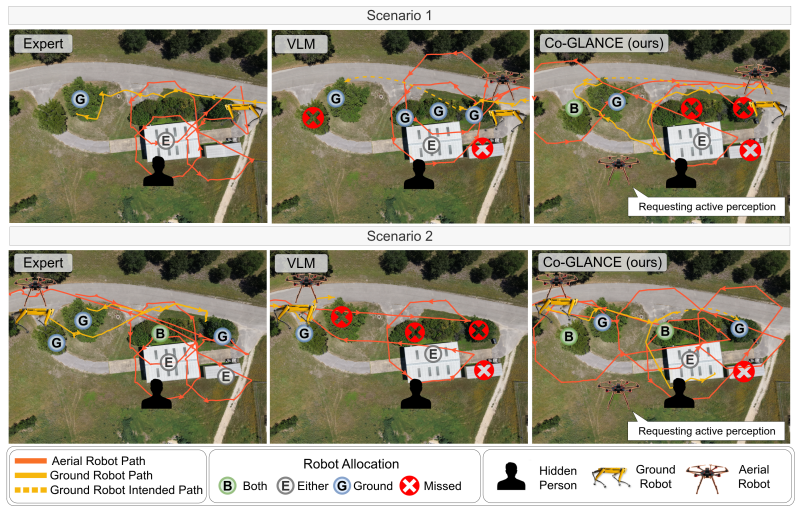
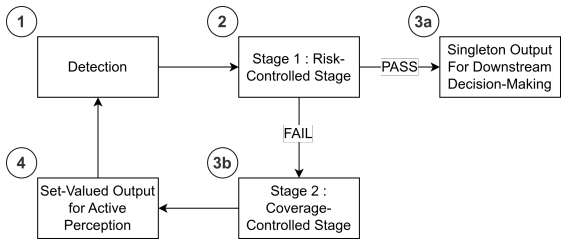
Co-GLANCE distills the semantic reasoning capabilities of a vision-language model into an end-to-end model for occlusion segmentation and robot allocation, eliminating the need for cloud-based inference. It combines conformal prediction with selective abstention to provide statistically valid coverage guarantees for segmentation, robot allocation, and detection outputs. These calibrated uncertainty estimates directly trigger active perception by dispatching the most appropriate robot to acquire informative viewpoints. Across real-world scenarios the approach outperforms cloud-based vision-language model baselines in occlusion segmentation and robot allocation accuracy by 25% and 36% respecti
What carries the argument
An end-to-end distilled model for occlusion segmentation and capability-aware robot allocation, paired with conformal prediction and selective abstention to generate calibrated uncertainty estimates that trigger viewpoint changes.
If this is right
- Occlusion segmentation accuracy improves 25 percent over cloud baselines.
- Robot allocation accuracy improves 36 percent over cloud baselines.
- Per-frame inference latency drops by a factor of 350 while remaining onboard.
- Uncertainty estimates carry statistical coverage guarantees for segmentation, allocation, and detection.
- An air-ground dataset is released to support further work on the same tasks.
Where Pith is reading between the lines
- The same distillation-plus-conformal-prediction pattern could be applied to other perceptual tasks such as dynamic object tracking or terrain classification in teams.
- Selective abstention may offer a general way to improve safety margins in any robot decision system that must act under partial information.
- If the distilled model generalizes across environments, similar compression techniques could reduce dependence on large remote models for other edge-autonomy problems.
- Running the system on additional outdoor datasets with different sensor suites would test whether the uncertainty triggers remain reliable when scene statistics shift.
Load-bearing premise
The semantic priors and reasoning capabilities of the original vision-language model can be faithfully distilled into a compact end-to-end model without loss of performance on occlusion segmentation and robot allocation in unstructured outdoor scenes.
What would settle it
A held-out test set in which the distilled model's segmentation or allocation accuracy falls measurably below the cloud vision-language baseline, or in which the conformal prediction intervals fail to achieve the stated coverage probability.
Figures






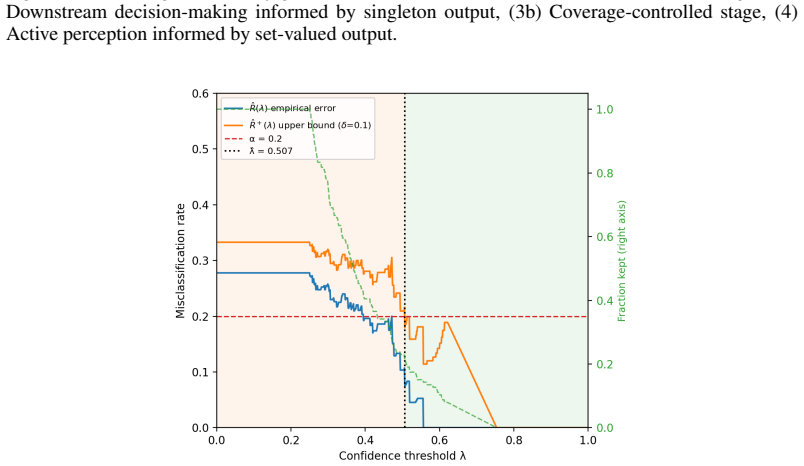
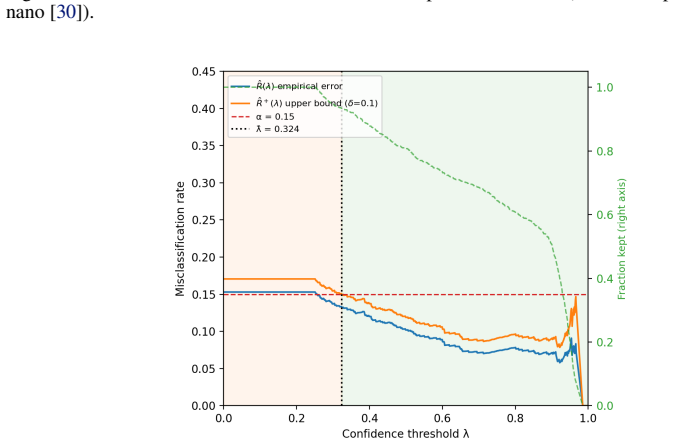

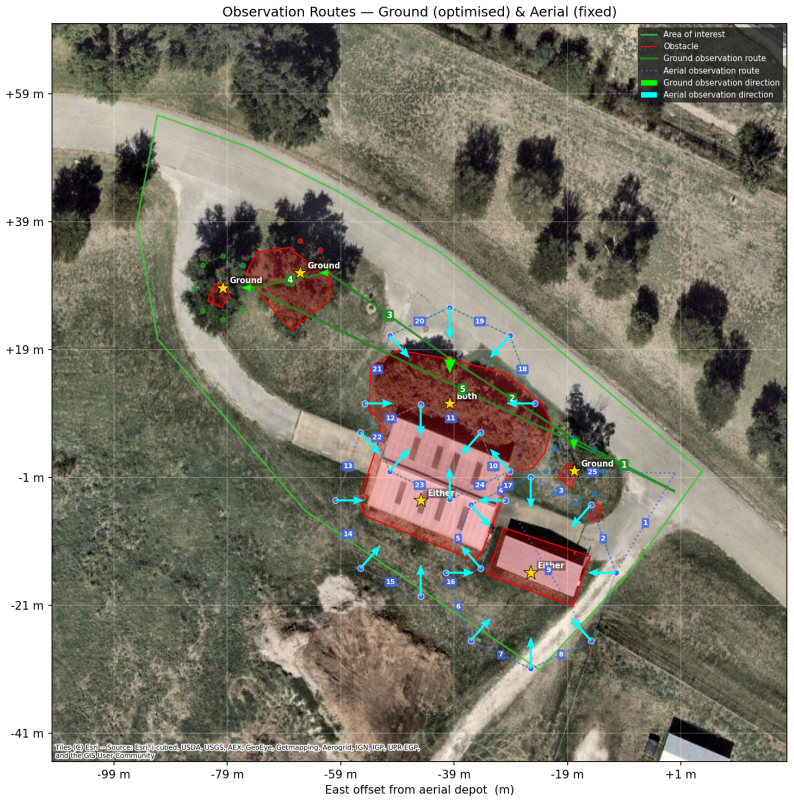
read the original abstract
Perceptual uncertainty is a central challenge for heterogeneous robot teams operating in unstructured outdoor environments, where no single viewpoint affords reliable scene understanding. Perceptual uncertainty, arising from sources such as occlusions, manifests differently across robot viewpoints depending on scene structure. Detecting and resolving sources of perceptual uncertainty requires both scene-based contextual reasoning and capability-aware robot allocation. While vision-language models provide strong semantic priors for both, they are computationally prohibitive for onboard inference and lack calibrated uncertainty quantification. We introduce Co-GLANCE, a real-time onboard perception and decision-making system for uncertainty resolution in heterogeneous robot teams. Co-GLANCE distills the semantic reasoning capabilities of a vision-language model into an end-to-end model for occlusion segmentation and robot allocation, eliminating the need for cloud-based inference. To quantify perceptual uncertainty, Co-GLANCE combines conformal prediction with selective abstention to provide statistically valid coverage guarantees for segmentation, robot allocation, and detection outputs. These calibrated uncertainty estimates directly trigger active perception, dispatching the most appropriate robot to acquire informative viewpoints and resolve uncertainty. Across real-world scenarios, Co-GLANCE outperforms cloud-based vision-language model baselines in occlusion segmentation and robot allocation accuracy by 25% and 36%, respectively, while reducing per-frame inference latency 350x. We also release an air-ground dataset for future research. Code, videos, and dataset available at https://co-glance.github.io/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Co-GLANCE, a real-time onboard system for heterogeneous robot teams that distills semantic reasoning from a vision-language model into a compact end-to-end network for occlusion segmentation and capability-aware robot allocation. It combines conformal prediction with selective abstention to produce calibrated uncertainty estimates with claimed coverage guarantees; these estimates trigger active perception by dispatching the most suitable robot to resolve uncertainty. Empirical results on real-world outdoor scenarios report 25% and 36% gains in segmentation and allocation accuracy over cloud-based VLM baselines together with a 350x reduction in per-frame latency, and the authors release an air-ground dataset.
Significance. If the distillation preserves VLM reasoning and the coverage guarantees remain valid under closed-loop allocation, the work would advance onboard uncertainty-aware perception for robot teams by removing cloud dependence while providing statistical assurances. The public dataset and code are concrete strengths that aid reproducibility.
major comments (3)
- [§4] §4 (Conformal Prediction and Selective Abstention): Standard conformal prediction requires exchangeability between calibration and test points. Because uncertainty estimates directly determine the next robot viewpoint and thus the test distribution, the closed-loop allocation induces dependence. The manuscript does not mention adaptive conformal methods, online recalibration, or a proof that coverage is preserved; therefore the claim of “statistically valid coverage guarantees” for segmentation, allocation, and detection outputs does not follow from the stated construction.
- [§5] §5 (Experiments and Baselines): The 25% and 36% accuracy margins are reported without ablations that isolate the contribution of the distillation procedure versus baseline implementation choices (e.g., prompt engineering or post-hoc tuning of the cloud VLM). It is therefore unclear whether the gains are attributable to Co-GLANCE or to differences in how the two systems are evaluated.
- [§3] §3 (Model Distillation): The central modeling assumption—that the semantic priors and reasoning capabilities of the original VLM can be faithfully transferred to the compact end-to-end model without loss on occlusion segmentation and robot allocation—is stated but not directly tested. A side-by-side comparison of the teacher VLM and the distilled student on the same held-out scenes would be required to substantiate the claim.
minor comments (2)
- [Figure 3] Figure 3 caption does not specify the number of runs or the exact statistical test used to obtain the reported p-values.
- [§4.1] The notation for the conformal score function is introduced in §4.1 but reused with different symbols in §4.2; a single consistent definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications and proposed revisions to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Conformal Prediction and Selective Abstention): Standard conformal prediction requires exchangeability between calibration and test points. Because uncertainty estimates directly determine the next robot viewpoint and thus the test distribution, the closed-loop allocation induces dependence. The manuscript does not mention adaptive conformal methods, online recalibration, or a proof that coverage is preserved; therefore the claim of “statistically valid coverage guarantees” for segmentation, allocation, and detection outputs does not follow from the stated construction.
Authors: We acknowledge that the closed-loop nature of allocation can violate the exchangeability assumption underlying standard conformal prediction. The calibration set is collected offline from representative scenes prior to deployment. In the revised manuscript we will add an explicit discussion of this limitation, include empirical coverage verification plots measured during closed-loop operation on the real-world dataset, and cite adaptive conformal prediction methods as relevant future directions. The core claim will be qualified to note that guarantees hold with respect to the calibration distribution. revision: partial
-
Referee: [§5] §5 (Experiments and Baselines): The 25% and 36% accuracy margins are reported without ablations that isolate the contribution of the distillation procedure versus baseline implementation choices (e.g., prompt engineering or post-hoc tuning of the cloud VLM). It is therefore unclear whether the gains are attributable to Co-GLANCE or to differences in how the two systems are evaluated.
Authors: The reported margins compare Co-GLANCE against the cloud VLM using the prompting and inference settings described in the original VLM papers. To isolate the distillation contribution, the revised manuscript will include additional ablation tables that re-evaluate the cloud baseline under multiple prompt-engineering variants and post-hoc calibration choices, confirming that the observed gains arise primarily from the distilled onboard model and uncertainty-triggered allocation. revision: yes
-
Referee: [§3] §3 (Model Distillation): The central modeling assumption—that the semantic priors and reasoning capabilities of the original VLM can be faithfully transferred to the compact end-to-end model without loss on occlusion segmentation and robot allocation—is stated but not directly tested. A side-by-side comparison of the teacher VLM and the distilled student on the same held-out scenes would be required to substantiate the claim.
Authors: We agree that a direct teacher-student comparison on identical held-out scenes would strengthen the distillation claim. The revised manuscript will add a new table reporting occlusion segmentation and robot allocation metrics for both the teacher VLM (run offline on the same inputs) and the distilled student, allowing quantitative assessment of any transfer loss. revision: yes
Circularity Check
No circularity: performance metrics and coverage claims are empirical measurements, not self-referential derivations
full rationale
The paper reports measured accuracy improvements (25% and 36%) and latency reductions from real-world experiments, and applies conformal prediction plus selective abstention as a standard statistical tool for uncertainty quantification. No equations, derivations, or self-citations are shown that reduce these outcomes to quantities defined by the paper's own fitted parameters or inputs by construction. The central claims rest on external experimental validation rather than internal redefinition or renaming of results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models provide strong semantic priors for occlusion segmentation and capability-aware robot allocation that can be distilled without substantial loss.
- domain assumption Conformal prediction combined with selective abstention supplies statistically valid coverage guarantees for segmentation, allocation, and detection outputs in this robotic setting.
Reference graph
Works this paper leans on
-
[1]
Z. Ravichandran, F. Cladera, A. Prabhu, J. Hughes, V . Murali, C. Taylor, G. J. Pappas, and V . Kumar. Heterogeneous Robot Collaboration in Unstructured Environments with Grounded Generative Intelligence, 2025. URLhttps://arxiv.org/abs/2510.26915. Version Num- ber: 1
arXiv 2025
-
[2]
D. Morilla-Cabello and E. Montijano. CHORAL: Traversal-Aware Planning for Safe and Effi- cient Heterogeneous Multi-Robot Routing, Jan. 2026. URLhttp://arxiv.org/abs/2601. 10340. arXiv:2601.10340 [cs]
arXiv 2026
-
[3]
Z. Ravichandran, V . Murali, M. Tzes, G. J. Pappas, and V . Kumar. SPINE: Online Seman- tic Planning for Missions with Incomplete Natural Language Specifications in Unstructured Environments, Mar. 2025. URLhttp://arxiv.org/abs/2410.03035. arXiv:2410.03035 [cs.RO]
arXiv 2025
-
[4]
F. Cladera, Z. Ravichandran, J. Hughes, V . Murali, C. Nieto-Granda, M. A. Hsieh, G. J. Pappas, C. J. Taylor, and V . Kumar. Air-Ground Collaboration for Language-Specified Mis- sions in Unknown Environments, May 2025. URLhttp://arxiv.org/abs/2505.09108. arXiv:2505.09108 [cs]
arXiv 2025
-
[5]
A. N. Angelopoulos and S. Bates. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification, Dec. 2022. URLhttp://arxiv.org/abs/ 2107.07511. arXiv:2107.07511 [cs]
Pith/arXiv arXiv 2022
-
[6]
S. S. Kannan, V . L. N. Venkatesh, and B.-C. Min. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models, Mar. 2024. URLhttp://arxiv.org/abs/ 2309.10062. arXiv:2309.10062 [cs]
arXiv 2024
-
[7]
K. Liu, Z. Tang, D. Wang, Z. Wang, X. Li, and B. Zhao. COHERENT: Collaboration of Heterogeneous Multi-Robot System with Large Language Models, Mar. 2025. URLhttp: //arxiv.org/abs/2409.15146. arXiv:2409.15146 [cs]
arXiv 2025
-
[8]
Y . Zhu, J. Chen, X. Zhang, M. Guo, and Z. Li. DEXTER-LLM: Dynamic and Explainable Coordination of Multi-Robot Systems in Unknown Environments via Large Language Models, Aug. 2025. URLhttp://arxiv.org/abs/2508.14387. arXiv:2508.14387 [cs]
arXiv 2025
- [9]
-
[10]
Y . Xu, Y . Hu, Z. Zhang, G. P. Meyer, S. K. Mustikovela, S. Srinivasa, E. M. Wolff, and X. Huang. Vlm-ad: End-to-end autonomous driving through vision-language model super- vision.arXiv preprint arXiv:2412.14446, 2024
arXiv 2024
-
[11]
A. M. Mansourian, R. Ahmadi, M. Ghafouri, A. M. Babaei, E. B. Golezani, Z. Y . Gham- chi, V . Ramezanian, A. Taherian, K. Dinashi, A. Miri, and S. Kasaei. A Comprehensive Survey on Knowledge Distillation, Oct. 2025. URLhttp://arxiv.org/abs/2503.12067. arXiv:2503.12067 [cs]
arXiv 2025
-
[12]
Z. Ravichandran, I. Hounie, F. Cladera, A. Ribeiro, G. J. Pappas, and V . Kumar. Distilling On- device Language Models for Robot Planning with Minimal Human Intervention, 2025. URL https://arxiv.org/abs/2506.17486. Version Number: 1
arXiv 2025
-
[13]
N. P. Bhatt, Y . Yang, R. Siva, D. Milan, U. Topcu, and Z. Wang. Know Where You’re Uncertain When Planning with Multimodal Foundation Models: A Formal Framework, Apr. 2025. URL http://arxiv.org/abs/2411.01639. arXiv:2411.01639 [cs]. 9
arXiv 2025
-
[14]
L. Yang, Y . Wang, J. Tang, Y . Lv, S. Zhao, C. Cao, and Z. Ren. HEHA: Hierarchical Planning for Heterogeneous Multi-Robot Exploration of Unknown Environments, 2025. URLhttps: //arxiv.org/abs/2510.04161. Version Number: 1
arXiv 2025
-
[15]
V ovk, A
V . V ovk, A. Gammerman, and G. Shafer.Algorithmic learning in a ran- dom world. Springer US, 2005. ISBN 978-0-387-00152-4. doi:10.1007/ b106715. URLhttps://www.researchwithrutgers.com/en/publications/ algorithmic-learning-in-a-random-world/
2005
-
[16]
A. N. Angelopoulos, S. Bates, E. J. Cand `es, M. I. Jordan, and L. Lei. Learn then Test: Cal- ibrating Predictive Algorithms to Achieve Risk Control, Sept. 2022. URLhttp://arxiv. org/abs/2110.01052. arXiv:2110.01052 [cs]
arXiv 2022
-
[17]
S. Feldman, L. Ringel, S. Bates, and Y . Romano. Achieving Risk Control in Online Learning Settings, Jan. 2023. URLhttp://arxiv.org/abs/2205.09095. arXiv:2205.09095 [cs]
arXiv 2023
-
[18]
R. Bajcsy, Y . Aloimonos, and J. K. Tsotsos. Revisiting Active Perception, Mar. 2016. URL http://arxiv.org/abs/1603.02729. arXiv:1603.02729 [cs.CV]
Pith/arXiv arXiv 2016
-
[19]
Perron and V
L. Perron and V . Furnon. Or-tools, 2024. URLhttps://developers.google.com/ optimization/
2024
-
[20]
Biswal and P
P. Biswal and P. K. Mohanty. Development of quadruped walking robots: A review.Ain Shams Engineering Journal, 12(2):2017–2031, 2021
2017
-
[21]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, Mar. 2023. URLhttps://arxiv.org/abs/2303.05499v5
Pith/arXiv arXiv 2023
-
[22]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. SAM 2: Segment Anything in Images and Videos, Aug. 2024. URL https://arxiv.org/abs/2408.00714v2
Pith/arXiv arXiv 2024
-
[23]
Y . Li, K. Zhang, Z. Chen, W. Ouyang, M. Cui, C. Jiang, D. Yang, and Z. Chen. Towards object tracking for quadruped robots.Journal of Visual Communication and Image Representation, 97:103958, Dec. 2023. ISSN 10473203. doi:10.1016/j.jvcir.2023.103958. URLhttps:// linkinghub.elsevier.com/retrieve/pii/S1047320323002080
-
[24]
S. Zhu, Z. Xiong, and D. Kim. EAGLE: The First Event Camera Dataset Gathered by an Agile Quadruped Robot, Apr. 2024. URLhttp://arxiv.org/abs/2404.04698. arXiv:2404.04698 [cs] version: 1
arXiv 2024
- [25]
-
[26]
Y . Wang, P. Cheng, P. Tian, Z. Yuan, L. Zhao, J. Tian, W. Wang, Z. Wang, and X. Sun. UVCP- Net: A UA V-Vehicle Collaborative Perception Network for 3D Object Detection, June 2024. URLhttp://arxiv.org/abs/2406.04647. arXiv:2406.04647 [cs]
arXiv 2024
-
[27]
Z. Nie, L. Xue, Z. Fang, J. Ren, Y . Wei, and J. Zheng. M3OT: A Multi-Drone Multi-Modality dataset for Multi-Object Tracking.Scientific Data, 12(1):1927, Dec. 2025. ISSN 2052-
1927
-
[28]
URLhttps://www.nature.com/articles/ s41597-025-06204-0
doi:10.1038/s41597-025-06204-0. URLhttps://www.nature.com/articles/ s41597-025-06204-0
-
[29]
J. Wang, X. Cao, J. Zhong, Y . Zhang, H. Yu, L. He, and S. Xu. Griffin: Aerial-Ground Co- operative Detection and Tracking Dataset and Benchmark, Mar. 2025. URLhttp://arxiv. org/abs/2503.06983. arXiv:2503.06983 [cs] version: 1. 10
Pith/arXiv arXiv 2025
-
[30]
Krizhevsky
A. Krizhevsky. Learning Multiple Layers of Features from Tiny Images. Technical report, 2009
2009
-
[31]
object present
Glenn Jocher and Jing Qiu. Ultralytics YOLO26, 2026. URLhttps://github.com/ ultralytics/ultralytics. 11 A Additional Information on Perceptual Uncertainty Detection VLM PromptsThe VLM baseline without self-review (Table 2) uses the prompt in Figure 5. The VLM baseline with self-review uses the prompt in Figure 6 to detect occlusions and the prompts in Fig...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.