Multi-Task Crack Foundation Model for Engineering-Reliable Crack Representation and Topology Preservation in Civil Infrastructure
Pith reviewed 2026-06-28 02:25 UTC · model grok-4.3
The pith
CrackGeoFM adapts a frozen foundation model with three modules to deliver crack masks that preserve topology and include calibrated uncertainty estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
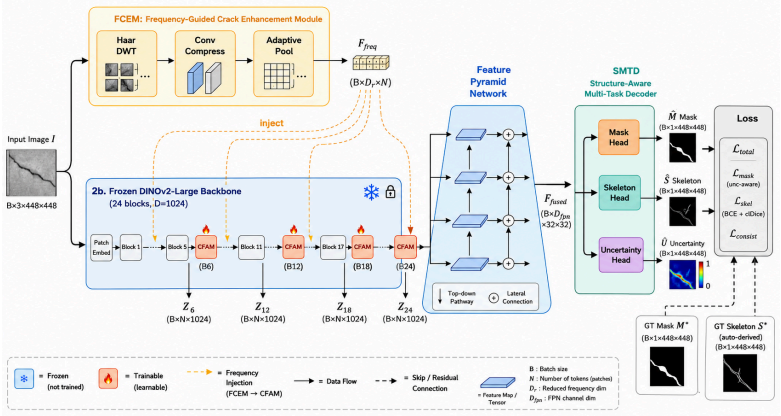
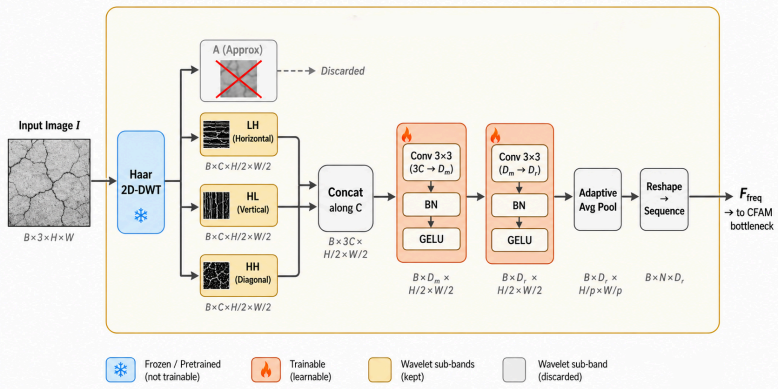
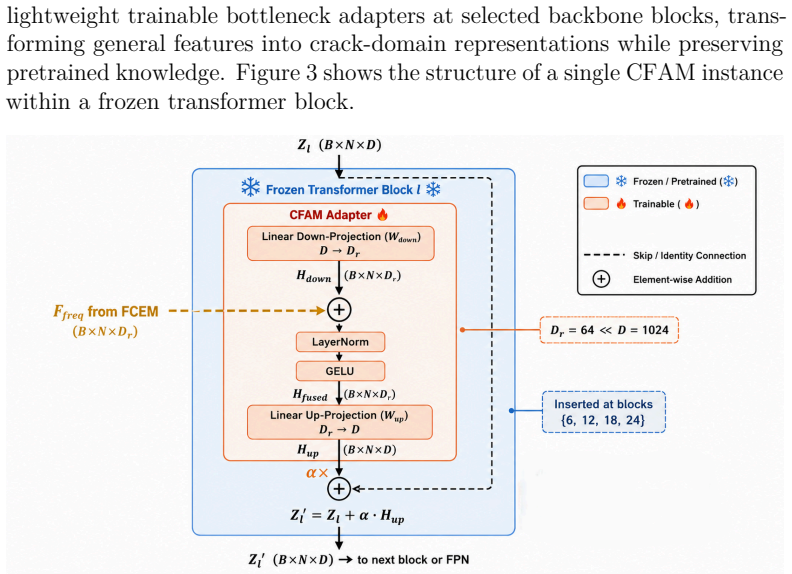
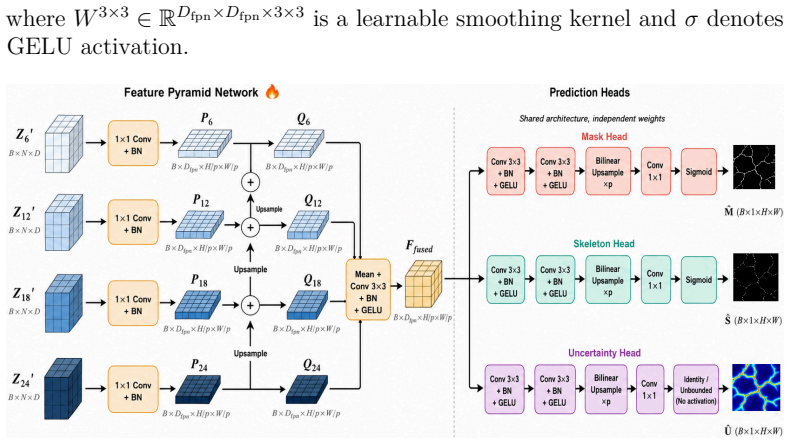
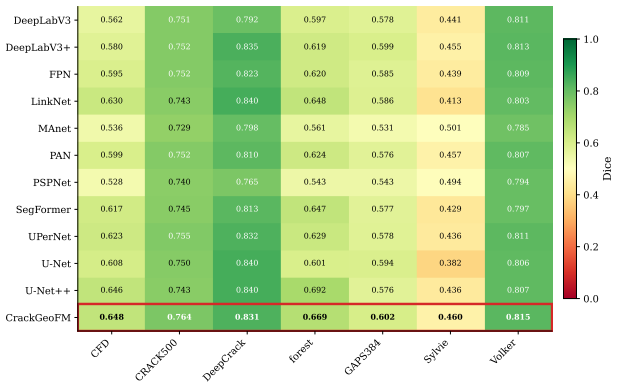
CrackGeoFM shows that a frozen visual foundation backbone can be paired with a Frequency-Guided Crack Enhancement Module, a Crack-Domain Feature Adaptation Module, and a Structure-Aware Multi-Task Decoder to produce masks, reconstructed skeletons, and uncertainty maps that are simultaneously more accurate, topologically connected, and better calibrated than prior single-task or non-adapted models across twenty crack datasets.
What carries the argument
CrackGeoFM framework that freezes a visual foundation backbone and routes its features through FCEM for high-frequency crack cues, CFAM for domain adaptation, and SMTD for joint mask-skeleton-uncertainty decoding.
If this is right
- Segmentation and skeleton outputs remain connected even on thin or branched cracks.
- Uncertainty maps stay reliable when the input domain shifts between datasets.
- Only five labeled images suffice for competitive few-shot performance on new crack collections.
- Joint training of the three tasks improves each individual output compared with separate models.
Where Pith is reading between the lines
- The same frozen-backbone-plus-specialized-decoder pattern could be tested on other thin linear structures such as road networks or vessel segmentation.
- Calibrated uncertainty could be used to prioritize inspection resources toward high-uncertainty crack regions.
- The frequency-guided and structure-aware modules might transfer to medical imaging tasks where topology matters more than pixel overlap.
Load-bearing premise
The three new modules can be attached to a frozen backbone to raise segmentation accuracy, topology preservation, and uncertainty calibration together without hidden trade-offs or dataset-by-dataset retuning.
What would settle it
On a held-out crack dataset the model would need to show either lower topology scores than the prior best method or uncertainty estimates whose calibration error exceeds that of a strong baseline.
Figures
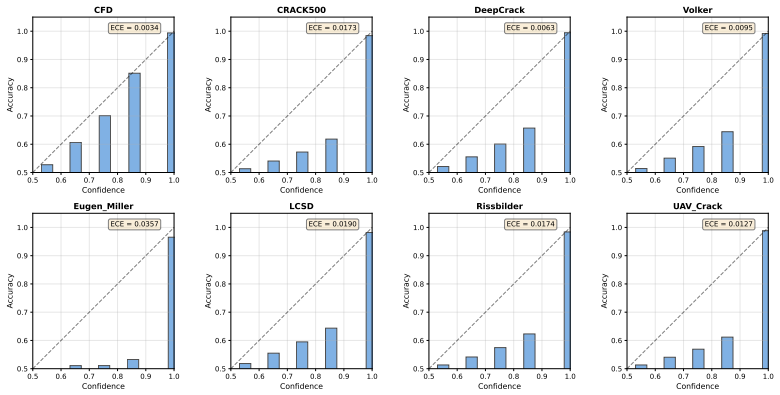
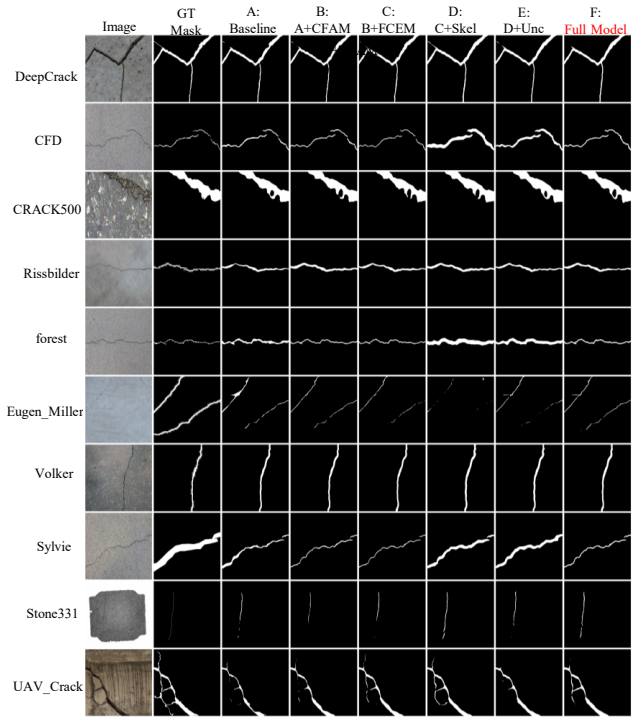

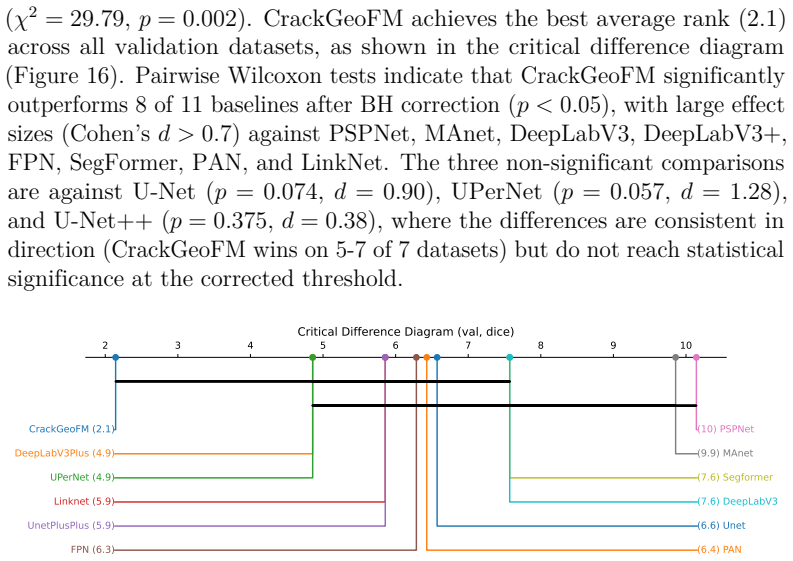
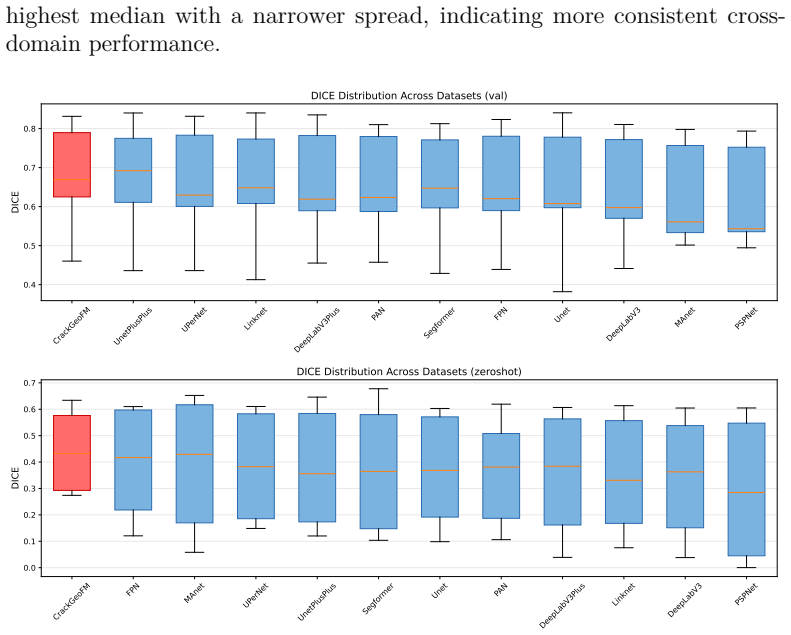
read the original abstract
Reliable crack assessment requires not only accurate pixel-level masks but also connected crack geometry and confidence estimates that remain stable under domain shift. However, existing segmentation models can achieve high overlap scores while fragmenting cracks, missing fine branches, and providing no calibrated uncertainty. To address this gap, this paper proposes CrackGeoFM, a multi-task framework that combines a frozen visual foundation backbone with crack-specific adaptation for mask prediction, skeleton reconstruction, and uncertainty estimation. The framework integrates a Frequency-Guided Crack Enhancement Module (FCEM) to enhance high-frequency crack cues, a Crack-Domain Feature Adaptation Module (CFAM) to adapt frozen backbone features to crack-domain patterns, and a Structure-Aware Multi-Task Decoder (SMTD) to jointly decode masks, skeletons, and uncertainty. Across 20 crack datasets, CrackGeoFM achieves state-of-the-art segmentation, improved topology preservation, calibrated uncertainty, and effective few-shot adaptation with only five labeled images. These results support reliable, generalizable, and engineering-oriented crack analysis for infrastructure assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CrackGeoFM, a multi-task framework that attaches three modules (FCEM for high-frequency crack cue enhancement, CFAM for adapting frozen backbone features to crack patterns, and SMTD for joint mask/skeleton/uncertainty decoding) to a frozen visual foundation backbone. It claims that this architecture delivers state-of-the-art segmentation, improved topology preservation, calibrated uncertainty, and effective five-shot adaptation across 20 crack datasets, thereby enabling engineering-reliable crack assessment in civil infrastructure.
Significance. If the empirical claims are substantiated with proper controls, the work would address a genuine gap between pixel-overlap metrics and topology/uncertainty requirements in infrastructure inspection. The frozen-backbone design and explicit topology objective are practically attractive; however, the absence of any quantitative results, ablations, or loss formulations in the manuscript prevents evaluation of whether the claimed simultaneous gains are achievable.
major comments (2)
- Abstract: the central claim that FCEM+CFAM+SMTD jointly deliver SOTA segmentation, topology preservation, and calibrated uncertainty without task interference is unsupported by any tables, baseline comparisons, ablation results, or numerical metrics; the manuscript therefore provides no evidence that the multi-task objectives can be optimized simultaneously across 20 datasets.
- Abstract (SMTD description): no loss formulation, task-weighting scheme, or training procedure is supplied for the joint decoding of masks, skeletons, and uncertainty; without these details it is impossible to assess whether the claimed absence of trade-offs holds or whether per-dataset retuning was required.
minor comments (1)
- Abstract: the phrase 'engineering-oriented crack analysis' is used without defining the concrete engineering requirements (e.g., minimum topology metric thresholds or uncertainty calibration targets) that the model is asserted to satisfy.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract claims require explicit empirical support and that the SMTD module description needs additional methodological details to allow proper evaluation. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim that FCEM+CFAM+SMTD jointly deliver SOTA segmentation, topology preservation, and calibrated uncertainty without task interference is unsupported by any tables, baseline comparisons, ablation results, or numerical metrics; the manuscript therefore provides no evidence that the multi-task objectives can be optimized simultaneously across 20 datasets.
Authors: We acknowledge that the abstract presents high-level claims without direct numerical support. The full manuscript contains Section 4 with quantitative results across all 20 datasets (including mIoU, F1, topology connectivity scores, and uncertainty calibration metrics such as ECE), Table 1 for baseline comparisons, and Table 3 for module ablations demonstrating simultaneous improvements without task interference. To address the concern, we will incorporate key numerical highlights and a brief reference to these results directly into the abstract. revision: yes
-
Referee: Abstract (SMTD description): no loss formulation, task-weighting scheme, or training procedure is supplied for the joint decoding of masks, skeletons, and uncertainty; without these details it is impossible to assess whether the claimed absence of trade-offs holds or whether per-dataset retuning was required.
Authors: We agree these implementation details are necessary for assessing the multi-task setup. Section 3.3 describes the SMTD architecture, but we will expand the revision to explicitly include the joint loss formulation (combined Dice+BCE for masks, topology-aware loss for skeletons, and variance-based uncertainty loss), the task-weighting scheme (fixed weights with optional learned balancing), and the end-to-end training procedure with the frozen backbone. This will clarify that no per-dataset retuning was performed beyond the reported five-shot protocol. revision: yes
Circularity Check
No circularity: empirical performance claims with no derivation chain or self-referential reductions
full rationale
The paper proposes modules (FCEM, CFAM, SMTD) integrated with a frozen backbone and reports empirical SOTA results across 20 datasets for segmentation, topology, uncertainty, and few-shot adaptation. No mathematical derivation, equations, or loss formulations are presented that could reduce to inputs by construction. Claims rest on experimental outcomes rather than fitted parameters renamed as predictions or self-citation chains. The absence of a derivation chain means no load-bearing steps qualify as circular under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Yuan, Y. Shi, M. Li, A review of computer vision-based crack detection methods in civil infrastructure: Progress and challenges, Remote Sensing 16 (16) (2024) 2910.doi:10.3390/rs16162910
-
[2]
X. Yang, H. Li, Y. Yu, X. Luo, T. Huang, X. Yang, Automatic pixel- level crack detection and measurement using fully convolutional network, Computer-Aided Civil and Infrastructure Engineering 33 (12) (2018) 1090--1109.doi:10.1111/mice.12412
-
[3]
C. V. Dung, L. D. Anh, Autonomous concrete crack detection using deep fully convolutional neural network, Automation in Construction 99 (2019) 52--58.doi:10.1016/j.autcon.2018.11.028
- [4]
-
[5]
Z. Liu, Y. Cao, Y. Wang, W. Wang, Computer vision-based concrete crack detection using u-net fully convolutional networks, Automation in Construction 104 (2019) 129--139. doi:10.1016/j.autcon.2019.04. 005
-
[6]
N. J. Owora, Y. Adu-Gyamfi, A. Aboah, M. Amo-Boateng, Pavesam: Segment anything for pavement distress, Road Materials and Pavement Design 26 (3) (2025) 593--617.doi:10.1080/14680629.2024.2374863
-
[7]
A. Ji, X. Xue, Y. Wang, X. Luo, W. Xue, An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement, Automation in Construction 114 (2020) 103176. doi:10. 1016/j.autcon.2020.103176
arXiv 2020
-
[8]
Y.-C. Chen, R.-T. Wu, A. Puranam, Multi-task deep learning for crack segmentation and quantification in rc structures, Automation in Con- struction 166 (2024) 105599.doi:10.1016/j.autcon.2024.105599
-
[9]
Q. Zou, Y. Cao, Q. Li, Q. Mao, S. Wang, CrackTree: Automatic crack detection from pavement images, Pattern Recognition Letters 33 (3) (2012) 227--238.doi:10.1016/j.patrec.2011.11.004. 52
-
[10]
A. Dontoh, L. Sirbaugh, A. Danyo, S. Ivey, B. A. Kyem, A. Aboah, J. Dontoh, An enhanced lightweight model for real-time pavement con- dition index prediction, in: 2025 IEEE International Conference on Future Machine Learning and Data Science (FMLDS), 2025, pp. 273-- 278.doi:10.1109/FMLDS67896.2025.00053
-
[11]
B. A. Kyem, J. K. Asamoah, A. Dontoh, A. Danyo, E. K. O. Denteh, A. Aboah, Pavesync: A unified and comprehensive dataset for pavement distress analysis and classification, 2025 IEEE International Conference on Future Machine Learning and Data Science (FMLDS) (2025) 495-- 500. URLhttps://api.semanticscholar.org/CorpusID:284132439
2025
-
[12]
Q. Zou, Z. Zhang, Q. Li, X. Qi, Q. Wang, S. Wang, DeepCrack: Learning hierarchical convolutional features for crack detection, IEEE Transactions on Image Processing 28 (3) (2019) 1498--1512. doi:10.1109/TIP.2018. 2878966
-
[14]
B. A. Kyem, N. J. Owor, A. Danyo, J. K. Asamoah, E. Denteh, T. Mu- turi, A. Dontoh, Y. Adu-Gyamfi, A. Aboah, Task-specific dual-model framework for comprehensive traffic safety video description and analysis, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025, pp. 5384--5392
2025
-
[15]
J. M. Goo, X. Milidonis, A. Artusi, J. Boehm, C. Ciliberto, Hybrid- segmentor: Hybrid approach for automated fine-grained crack segmen- tation in civil infrastructure, Automation in Construction 170 (2025) 105960.doi:10.1016/j.autcon.2024.105960
- [16]
-
[17]
B. A. Kyem, J. K. Asamoah, T. Addai, E. Denteh, A. Danyo, A. Aboah, A big data approach to pavement distress detection, in: 2025 10th International Conference on Big Data Analytics (ICBDA), 2025, pp. 1--10.doi:10.1109/ICBDA65366.2025.11211362
-
[18]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollar, R. Girshick, Segment anything, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015--4026. doi:10.1109/ ICCV51070.2023.00371
arXiv 2023
-
[19]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V. Vo, M. Szafraniec, V. Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y. Huang, S.-W. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. La- batut, A. Joulin, P. Bojanowski, Dinov2: Learning robust visual features without superv...
2024
-
[20]
Vision-Language Foundation Models for Comprehensive Automated Pavement Condition Assessment
B. Agyei Kyem, J. Kofi Asamoah, A. Dontoh, A. Aboah, Vision-Language Foundation Models for Comprehensive Automated Pavement Condition Assessment, arXiv e-prints (2026) arXiv:2604.08212 arXiv:2604.08212, doi:10.48550/arXiv.2604.08212
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.08212 2026
-
[21]
K. Ge, C. Wang, Y. Guo, Y. Tang, Z. Hu, H. Chen, Fine-tuning vision foundation model for crack segmentation in civil infrastruc- tures, Construction and Building Materials 431 (2024) 136573. doi: 10.1016/j.conbuildmat.2024.136573
-
[23]
J. K. Asamoah, B. Agyei Kyem, N. D. Obeng-Amoako, A. Aboah, Saam-reflectnet: Sign-aware attention-based multitasking frame- work for integrated traffic sign detection and retroreflectivity estimation, Expert Systems with Applications 286 (2025) 128003. doi:https://doi.org/10.1016/j.eswa.2025.128003. 54 URL https://www.sciencedirect.com/science/article/pii...
-
[25]
Y.-J. Cha, W. Choi, O. Büyüköztürk, Deep learning-based crack damage detection using convolutional neural networks, Computer-Aided Civil and Infrastructure Engineering 32 (5) (2017) 361--378. doi:10.1111/ mice.12263
2017
-
[26]
K. Gopalakrishnan, S. K. Khaitan, A. Choudhary, A. Agrawal, Deep convolutional neural networks with transfer learning for computer vision- based data-driven pavement distress detection, Construction and Build- ing Materials 157 (2017) 322--330. doi:10.1016/j.conbuildmat.2017. 09.110
-
[27]
J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431--3440. doi: 10.1109/CVPR.2015.7298965
-
[28]
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Intervention, Springer, 2015, pp. 234--241. doi: 10.1007/978-3-319-24574-4_28
-
[29]
S. Dorafshan, R. J. Thomas, M. Maguire, Comparison of deep convolu- tional neural networks and edge detectors for image-based crack detection in concrete, Construction and Building Materials 186 (2018) 1031--1045. doi:10.1016/j.conbuildmat.2018.08.011
-
[30]
L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder- decoder with atrous separable convolution for semantic image segmenta- tion, in: Proceedings of the European Conference on Computer Vision, Springer, 2018, pp. 833--851.doi:10.1007/978-3-030-01234-2_49
-
[31]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with 55 transformers, in: Advances in Neural Information Processing Systems, Vol. 34, 2021, pp. 12077--12090
2021
-
[32]
A ConvNet for the 2020s , booktitle =
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, R. Girdhar, Masked- attention mask transformer for universal image segmentation, in: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2022, pp. 1280--1289. doi:10.1109/CVPR52688.2022. 00135
-
[33]
Y. Liu, J. Yao, X. Lu, R. Xie, L. Li, DeepCrack: A deep hierarchical feature learning architecture for crack segmentation, Neurocomputing 338 (2019) 139--153.doi:10.1016/j.neucom.2019.01.036
-
[34]
F. Yang, L. Zhang, S. Yu, D. Prokhorov, X. Mei, H. Ling, Feature pyramid and hierarchical boosting network for pavement crack detection, IEEE Transactions on Intelligent Transportation Systems 21 (4) (2020) 1525--1535.doi:10.1109/TITS.2019.2910595
-
[35]
Z. Fan, C. Li, Y. Chen, P. Di Mascio, X. Chen, G. Zhu, G. Loprencipe, Ensemble of deep convolutional neural networks for automatic pavement crack detection and measurement, Coatings 10 (2) (2020) 152. doi: 10.3390/coatings10020152
-
[36]
B. Agyei Kyem, J. K. Asamoah, A. Aboah, Context-cracknet: A context-aware framework for precise segmentation of tiny cracks in pave- ment images, Construction and Building Materials 484 (2025) 141583. doi:https://doi.org/10.1016/j.conbuildmat.2025.141583. URL https://www.sciencedirect.com/science/article/pii/ S0950061825017337
-
[37]
T. Chen, Z. Cai, X. Zhao, C. Chen, X. Liang, T. Zou, P. Wang, Pavement crack detection and recognition using the architecture of segnet, Journal of Industrial Information Integration 18 (2020) 100144. doi:10.1016/j. jii.2020.100144
work page doi:10.1016/j 2020
-
[38]
W. Wang, C. Su, Automatic concrete crack segmentation model based on transformer, Automation in Construction 139 (2022) 104275. doi: 10.1016/j.autcon.2022.104275
-
[39]
E. A. Shamsabadi, C. Xu, A. S. Rao, T. Nguyen, T. Ngo, D. Dias-da Costa, Vision transformer-based autonomous crack detection on asphalt 56 and concrete surfaces, Automation in Construction 140 (2022) 104316. doi:10.1016/j.autcon.2022.104316
-
[40]
H. Li, H. Zhang, H. Zhu, K. Gao, H. Liang, J. Yang, Automatic crack detection on concrete and asphalt surfaces using semantic segmentation network with hierarchical transformer, Engineering Structures 307 (2024) 117903.doi:10.1016/j.engstruct.2024.117903
-
[42]
Y. Song, J. Kang, Y. Su, S. Zhang, Q. Zhang, Y. Yu, Z. Zhan, W. Zhang, Mambafuse: Cross-scale state space fusion for crack seg- mentation, Developments in the Built Environment (2025) 100751 doi: 10.1016/j.dibe.2025.100751
-
[43]
B. Agyei Kyem, J. K. Asamoah, E. Denteh, A. Danyo, A. Aboah, Self-supervised multi-scale transformer with attention-guided fusion for efficient crack detection, Automation in Construction 181 (2026) 106591. doi:https://doi.org/10.1016/j.autcon.2025.106591. URL https://www.sciencedirect.com/science/article/pii/ S0926580525006314
-
[44]
H. Liu, X. Miao, C. Mertz, C. Xu, H. Kong, CrackFormer: Trans- former network for fine-grained crack detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3783--3792.doi:10.1109/ICCV48922.2021.00376
-
[45]
X. Zuo, Y. Sheng, J. Shen, Y. Shan, Topology-aware mamba for crack segmentation in structures, Automation in Construction 168 (2024) 105845.doi:10.1016/j.autcon.2024.105845
-
[46]
S. Zhou, C. Canchila, W. Song, Deep learning-based crack segmentation for civil infrastructure: Data types, architectures, and benchmarked performance, Automation in Construction 146 (2023) 104678. doi: 10.1016/j.autcon.2022.104678. 57
-
[47]
X. Weng, Y. Huang, Y. Li, H. Yang, S. Yu, Unsupervised domain adaptation for crack detection, Automation in Construction 153 (2023) 104939.doi:10.1016/j.autcon.2023.104939
-
[48]
F. Deng, S. Yang, B. Wang, X. Dong, S. Tian, Ucrack-da: A multi-scale unsupervised domain adaptation method for surface crack segmentation, Remote Sensing 17 (12) (2025) 2101.doi:10.3390/rs17122101
-
[49]
H. Zhang, J. Feng, C. Dai, Z. Tong, Pavement crack segmentation based on synthetic data sets and unsupervised domain adaptation, Journal of Computing in Civil Engineering 39 (6) (2025). doi:10.1061/JCCEE5. CPENG-6675
-
[50]
B. A. Kyem, E. Denteh, J. K. Asamoah, D. Tolliver, A. Aboah, Pavecap: A multimodal framework for comprehensive pavement condition assess- ment with dense captioning and pci estimation, Journal of Transportation Engineering, Part B: Pavements 152 (2) (2026) 04026010. arXiv: https://ascelibrary.org/doi/pdf/10.1061/JPEODX.PVENG-1945, doi:10.1061/JPEODX.PVENG...
-
[51]
Y. Guo, Y. Xu, H. Cui, M. Dang, S. Li, Segment anything model- based crack segmentation using low-rank adaption fine-tuning, Structural Health Monitoring 24 (4) (2025).doi:10.1177/14759217241261089
-
[52]
Z. Ye, L. J. Lovell, A. Faramarzi, J. Ninic, SAM-based instance segmentation models for the automation of structural damage de- tection, Advanced Engineering Informatics 62 (2024) 102826. doi: 10.1016/j.aei.2024.102826
-
[53]
Z. Zhou, W. Hu, G. Xu, Y. Dong, Self-evolving prompting segment anything model for crack segmentation through data-driven cyclic conversations, Advanced Engineering Informatics 66 (2025) 103626. doi:10.1016/j.aei.2025.103626
-
[54]
S. Shit, J. C. Paetzold, A. Sekuboyina, I. Ezhov, A. Unger, A. Zhylka, J. P. W. Pluim, U. Bauer, B. H. Menze, cldice: A novel topology- preserving loss function for tubular structure segmentation, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern 58 Recognition, 2021, pp. 16560--16569. doi:10.1109/CVPR46437.2021. 01629
-
[55]
X. Li, S. Yu, S. Xiao, X. Lin, Z. Zhao, A topology-aware segment anything model for domain-invariant crack segmentation, Engineering Applications of Artificial Intelligence 166 (2026) 113688. doi:10.1016/ j.engappai.2025.113688
arXiv 2026
-
[56]
R. Rathnakumar, Y. Pang, Y. Liu, Epistemic and aleatoric uncertainty quantification for crack detection using a bayesian boundary aware convolutional network, Reliability Engineering and System Safety 240 (2023) 109547.doi:10.1016/j.ress.2023.109547
-
[57]
K. R. M. dos Santos, A. G. J. Chassignet, B. G. Pantoja-Rosero, A. Rezaie, O. J. Savary, K. Beyer, Uncertainty quantification for a deep learning models for image-based crack segmentation, Jour- nal of Civil Structural Health Monitoring 15 (4) (2025) 1231--1269. doi:10.1007/s13349-024-00879-6
-
[58]
B. A. Kyem, J. K. Asamoah, Y. Huang, A. Aboah, Weather-adaptive syn- thetic data generation for enhanced power line inspection using stargan, IEEE Access 12 (2024) 193882--193901. doi:10.1109/ACCESS.2024. 3520120
-
[59]
C. Han, H. Yang, T. Ma, S. Wang, C. Zhao, Y. Yang, Crackdiffusion: A two-stage semantic segmentation framework for pavement crack combin- ing unsupervised and supervised processes, Automation in Construction 160 (2024) 105332.doi:10.1016/j.autcon.2024.105332
-
[60]
M. Denny, C. Rea, W. Punch, Skeleton-based noise removal algorithm for binary concrete crack image segmentation, Automation in Construction 151 (2023) 104879.doi:10.1016/j.autcon.2023.104879
-
[61]
B. G. Pantoja-Rosero, K. R. M. dos Santos, K. Beyer, An imple- mentation of the crack topology score with extensions, arXiv preprint arXiv:2601.10762 (2026)
arXiv 2026
-
[62]
T. Y. Zhang, C. Y. Suen, A fast parallel algorithm for thinning digital patterns, Communications of the ACM 27 (3) (1984) 236--239. doi: 10.1145/357994.358023. 59
-
[63]
Z. Li, T. Zhang, Y. Miao, J. Zhang, M. E. Torbaghan, Y. He, J. Dai, Automated quantification of crack length and width in asphalt pavements, Computer-Aided Civil and Infrastructure Engineering 39 (21) (2024) 3317--3336.doi:10.1111/mice.13344
-
[64]
Y. Shi, L. Cui, Z. Qi, F. Meng, Z. Chen, Automatic road crack de- tection using random structured forests, IEEE Transactions on In- telligent Transportation Systems 17 (12) (2016) 3434--3445. doi: 10.1109/TITS.2016.2552248
-
[65]
L. Zhang, F. Yang, Y. D. Zhang, Y. J. Zhu, Road crack detection using deep convolutional neural network, in: Proceedings of the IEEE International Conference on Image Processing, IEEE, 2016, pp. 3708-- 3712.doi:10.1109/ICIP.2016.7533052
-
[66]
M. Eisenbach, R. Stricker, D. Seichter, K. Amende, K. Debes, M. Sessel- mann, D. Ebersbach, U. Stoeckert, H.-M. Gross, How to get pavement distress detection ready for deep learning? A systematic approach, in: International Joint Conference on Neural Networks, IEEE, 2017, pp. 2039--2047.doi:10.1109/IJCNN.2017.7966101
-
[67]
R. Amhaz, S. Chambon, J. Idier, V. Baltazart, Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection, IEEE Transactions on Intelligent Transportation Systems 17 (10) (2016) 2718--2729.doi:10.1109/TITS.2015.2477675
-
[68]
Q. Mei, M. Gül, M. R. Azim, Densely connected deep neural network considering connectivity of pixels for automatic crack detection, Automa- tion in Construction 110 (2020) 103018. doi:10.1016/j.autcon.2019. 103018
-
[69]
M. Saghafi, S. M. Asgharzadeh, A. Fathi, A. Hosseini, SUT-Crack: A comprehensive dataset for pavement crack detection across all methods, Data in Brief 50 (2023) 109607.doi:10.1016/j.dib.2023.109607
-
[70]
Ç. F. Özgenel, Concrete crack segmentation dataset (2019). doi:10. 17632/jwsn7tfbrp.1
2019
-
[71]
D. Liang, X. Kong, J. Liu, X. He, Y. Zhang, X. Xue, L. Xu, Pave- Crack1300: A UAV-acquired pavement crack segmentation dataset (2026).doi:10.17632/8b27pdcxv7.1. 60
-
[72]
Z. Yao, J. Xu, S. Hou, M. C. Chuah, CrackNex: A few-shot low-light crack segmentation model based on Retinex theory for UAV inspections, in: Proceedings of the IEEE International Conference on Robotics and Automation, IEEE, 2024, pp. 17244--17251. doi:10.1109/ICRA57147. 2024.10610210
-
[73]
Ziya07, UAV-based crack detection dataset, Kaggle, avail- able at: https://www.kaggle.com/datasets/ziya07/ uav-based-crack-detection-dataset(2023)
2023
-
[74]
Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, J. Liang, UNet++: A nested U-Net architecture for medical image segmentation, in: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, 2018, pp. 3--11. doi:10.1007/ 978-3-030-00889-5_1
2018
-
[75]
L.-C. Chen, G. Papandreou, F. Schroff, H. Adam, Rethinking atrous convolution for semantic image segmentation, arXiv preprint arXiv:1706.05587 (2017)
Pith/arXiv arXiv 2017
-
[76]
H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2881--2890.doi:10.1109/CVPR.2017.660
-
[77]
T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117--2125.doi:10.1109/CVPR.2017.106
-
[78]
A. Chaurasia, E. Culurciello, LinkNet: Exploiting encoder representa- tions for efficient semantic segmentation, in: IEEE Visual Communica- tions and Image Processing, IEEE, 2017, pp. 1--4. doi:10.1109/VCIP. 2017.8305148
-
[79]
H. Li, P. Xiong, J. An, L. Wang, Pyramid attention network for semantic segmentation, in: Proceedings of the British Machine Vision Conference, 2018
2018
-
[80]
T. Fan, G. Wang, Y. Li, H. Wang, MA-Net: A multi-scale attention network for liver and tumor segmentation, IEEE Access 8 (2020) 179656- -179665.doi:10.1109/ACCESS.2020.3025372. 61
-
[81]
T. Xiao, Y. Liu, B. Zhou, Y. Jiang, J. Sun, Unified perceptual pars- ing for scene understanding, in: Proceedings of the European Confer- ence on Computer Vision, Springer, 2018, pp. 418--434. doi:10.1007/ 978-3-030-01228-1_26. 62
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.