Recognition: unknown
Vision-Language Foundation Models for Comprehensive Automated Pavement Condition Assessment
Pith reviewed 2026-05-10 17:25 UTC · model grok-4.3
The pith
Instruction tuning on a unified pavement dataset enables vision-language models to perform comprehensive assessments with over 20 percent gains and full standard compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
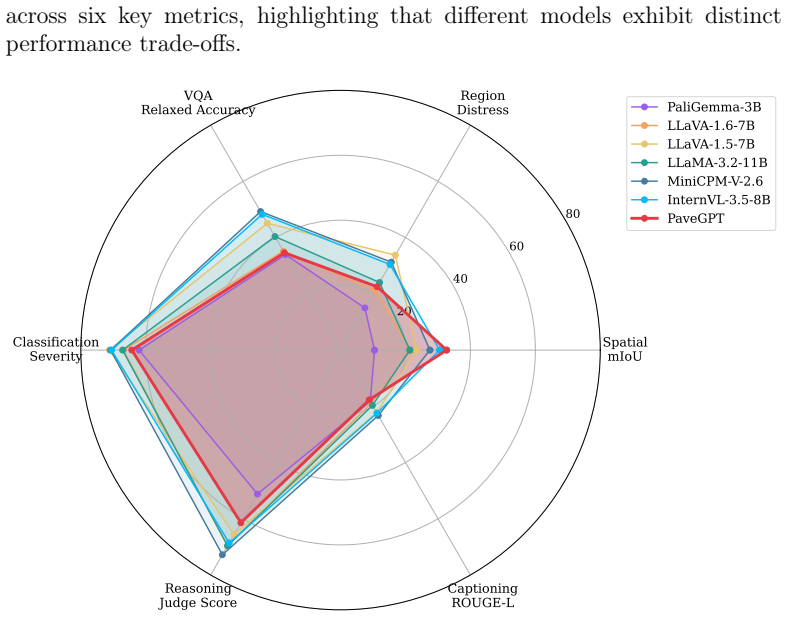
PaveGPT, the model trained on the PaveInstruct dataset, delivers improvements exceeding 20 percent in spatial grounding, reasoning, and generation tasks relative to state-of-the-art vision-language models and consistently produces outputs that satisfy ASTM D6433 pavement distress protocols.
What carries the argument
The PaveInstruct dataset, formed by unifying annotations across nine heterogeneous pavement collections into 278,889 image-instruction-response pairs spanning 32 task types, which supplies the targeted training signal for instruction tuning of vision-language models.
If this is right
- Transportation agencies could operate a single conversational system for all routine pavement inspections instead of maintaining separate specialized tools.
- Technical staff would require less domain expertise to obtain standardized condition ratings from image inputs.
- The same instruction-tuning recipe could be repeated for other infrastructure domains such as bridges or railways to create comparable unified assessment interfaces.
Where Pith is reading between the lines
- If the unification step succeeds, similar merged datasets could accelerate adaptation of vision-language models to other regulated inspection fields that currently lack large labeled corpora.
- The 32-task structure suggests the model may generalize to hybrid queries that combine perception with forward-looking maintenance recommendations, though this remains untested in the work.
- Deployment would still require ongoing validation against new distress types or climate-specific degradation patterns not captured in the original nine sources.
Load-bearing premise
Merging annotations from nine different pavement datasets yields a single training collection that is consistent, representative, and unbiased enough to support reliable performance on every real-world condition and all 32 task types.
What would settle it
A controlled test on a fresh, geographically distinct pavement dataset where the tuned model shows less than 10 percent improvement over untuned baselines or produces outputs that violate ASTM D6433 rating rules.
Figures





















read the original abstract
General-purpose vision-language models demonstrate strong performance in everyday domains but struggle with specialized technical fields requiring precise terminology, structured reasoning, and adherence to engineering standards. This work addresses whether domain-specific instruction tuning can enable comprehensive pavement condition assessment through vision-language models. PaveInstruct, a dataset containing 278,889 image-instruction-response pairs spanning 32 task types, was created by unifying annotations from nine heterogeneous pavement datasets. PaveGPT, a pavement foundation model trained on this dataset, was evaluated against state-of-the-art vision-language models across perception, understanding, and reasoning tasks. Instruction tuning transformed model capabilities, achieving improvements exceeding 20% in spatial grounding, reasoning, and generation tasks while producing ASTM D6433-compliant outputs. These results enable transportation agencies to deploy unified conversational assessment tools that replace multiple specialized systems, simplifying workflows and reducing technical expertise requirements. The approach establishes a pathway for developing instruction-driven AI systems across infrastructure domains including bridge inspection, railway maintenance, and building condition assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PaveInstruct, a dataset of 278,889 image-instruction-response pairs spanning 32 task types created by unifying annotations from nine heterogeneous pavement datasets, and PaveGPT, a vision-language foundation model trained via instruction tuning on this data. It claims that this approach transforms general VLMs into capable pavement assessment systems, yielding improvements exceeding 20% in spatial grounding, reasoning, and generation tasks relative to state-of-the-art models while producing outputs compliant with the ASTM D6433 standard, thereby enabling unified conversational tools for transportation agencies.
Significance. If the reported performance gains and standard compliance prove robust, the work would be significant for extending vision-language models to specialized engineering domains. The scale of the unified dataset and the multi-task coverage (32 types) represent a concrete step toward practical deployment of conversational AI for infrastructure inspection, potentially simplifying workflows by replacing multiple specialized systems. The suggested generalization to bridge, railway, and building assessment further broadens its potential impact.
major comments (2)
- [Abstract] Abstract: The central claim that instruction tuning produces improvements exceeding 20% in spatial grounding, reasoning, and generation tasks is presented without any quantitative metrics, baseline model names, statistical significance tests, or error analysis. This absence leaves the performance transformation unsubstantiated and directly undermines verification of the primary result.
- [Dataset construction (PaveInstruct)] Dataset construction (PaveInstruct): Merging annotations from nine sources that differ in camera geometry, lighting conditions, distress taxonomies, and labeling protocols creates unaddressed risks of label noise, domain shift, and coverage gaps across the 278,889 pairs and 32 tasks. No harmonization protocol, cross-dataset validation splits, or diversity statistics are described, which threatens the reliability of both the claimed quantitative gains and the ASTM D6433 compliance.
minor comments (1)
- [Abstract] Abstract: The phrase 'state-of-the-art vision-language models' is used for comparison but no specific models or references are named, reducing clarity on the evaluation setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions to the manuscript will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that instruction tuning produces improvements exceeding 20% in spatial grounding, reasoning, and generation tasks is presented without any quantitative metrics, baseline model names, statistical significance tests, or error analysis. This absence leaves the performance transformation unsubstantiated and directly undermines verification of the primary result.
Authors: We agree that the abstract would be strengthened by including more specific quantitative information to support the central claim. The full manuscript provides detailed comparisons against state-of-the-art vision-language models in the experimental section, along with task-specific metrics and evaluation protocols. To directly address this point, we will revise the abstract to reference the primary baselines, include representative quantitative improvements, and note the evaluation methodology. revision: yes
-
Referee: [Dataset construction (PaveInstruct)] Dataset construction (PaveInstruct): Merging annotations from nine sources that differ in camera geometry, lighting conditions, distress taxonomies, and labeling protocols creates unaddressed risks of label noise, domain shift, and coverage gaps across the 278,889 pairs and 32 tasks. No harmonization protocol, cross-dataset validation splits, or diversity statistics are described, which threatens the reliability of both the claimed quantitative gains and the ASTM D6433 compliance.
Authors: The referee raises a valid concern about the challenges of unifying heterogeneous data sources. The manuscript describes the unification of annotations from nine pavement datasets into PaveInstruct and alignment with the ASTM D6433 standard, but we acknowledge that additional explicit details on the harmonization process would improve clarity and address potential risks of label noise or domain shift. We will expand the dataset construction section to include a description of the harmonization protocol, diversity statistics across the source datasets, and the approach to cross-dataset validation splits. revision: yes
Circularity Check
No circularity: empirical training and benchmarking on unified dataset
full rationale
The paper creates PaveInstruct by merging annotations from nine prior datasets into 278,889 pairs across 32 tasks, trains PaveGPT via instruction tuning, and reports >20% gains plus ASTM D6433 compliance by direct comparison to SOTA vision-language models. No equations, fitted parameters, or derivations are presented that reduce outputs to inputs by construction. Claims rest on standard empirical evaluation rather than self-definition, self-citation load-bearing uniqueness theorems, or renamed known results. The central results are falsifiable against external benchmarks and do not collapse into tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, J. Zhou, Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y. Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, J. Lin, Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, J. Lin, Qwen2.5-vl technical report, arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning (2023)
2023
-
[5]
H. Liu, C. Li, Y. Li, Y. J. Lee, Improved baselines with visual instruction tuning (2023)
2023
-
[6]
X. He, Y. Zhang, L. Mou, E. Xing, P. Xie, Pathvqa: 30 000+ questions for medical visual question answering, arXiv preprint arXiv:2003.10286 (2020). URLhttps://arxiv.org/abs/2003.10286
work page internal anchor Pith review arXiv 2003
-
[7]
J.Lau, Jason S.Gayen, A.BenAbacha, D.Demner-Fushman, Adataset of clinically generated visual questions and answers about radiology im- ages, Scientific Data 5 (1) (2018) 180251.doi:10.1038/sdata.2018. 251. URLhttps://www.nature.com/articles/sdata2018251 62
- [8]
-
[9]
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, H. Li, Drivelm: Driving with graph visual question answering, in: European Conference on Computer Vision (ECCV) 2024, 2024. URLhttps://www.ecva.net/papers/eccv_2024/papers_ECCV/ papers/06870.pdf
2024
-
[10]
J. Kim, A. Rohrbach, T. Darrell, J. Canny, Z. Akata, Textual explana- tions for self-driving vehicles, Proceedings of the European Conference on Computer Vision (ECCV) (2018)
2018
- [11]
-
[12]
arXiv preprint arXiv:2212.13138 , year=
K. Singhal, Y. Lu, C. Kahn, ..., Large language models encode clinical knowledge, arXiv preprint arXiv:2212.13138 (2022). URLhttps://arxiv.org/abs/2212.13138
-
[13]
LAION-5B: An open large-scale dataset for training next generation image-text models
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wight- man, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmar- czyk, J. Jitsev, Laion-5b: An open large-scale dataset for training next generation image-text models, arXiv preprint arXiv:2210.08402 (2022). URLhttps://arxiv.org/abs/2210.08402
work page internal anchor Pith review arXiv 2022
-
[14]
Sharma, N
P. Sharma, N. Ding, S. Goodman, R. Soricut, Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image cap- tioning, in: Proc. 56th Annual Meeting of the Association for Compu- tational Linguistics (ACL 2018), 2018. URLhttps://aclanthology.org/P18-1238/
2018
-
[15]
X. l. Chen, H. Fang, T.-Y. Lin, R. Vedantam, S. Gupta, P. Dollar, C. L. Zitnick, Microsoft coco captions: Data collection and evaluation server, 63 arXiv preprint arXiv:1504.00325 (2015). URLhttps://arxiv.org/abs/1504.00325
work page internal anchor Pith review arXiv 2015
-
[16]
Krishna, Y
R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, J.-L. Li, D. A. Shamma, M. Bernstein, L. Fei-Fei, Visual genome: Connecting language and vision using crowdsourced dense image annotations, International Journal of Computer Vision 123 (1) (2017) 32–73. URLhttps://link.springer.com/article/10.1007/ s11263-016-0981-7
2017
-
[17]
H. Liu, C. Li, Y. J. Lee, Llava-instruct 150 k: Visual instruction tuning for large-scale multimodal models, in: arXiv preprint arXiv:2310.03744, 2023. URLhttps://arxiv.org/abs/2310.03744
work page internal anchor Pith review arXiv 2023
-
[18]
S. Kulkarni, S. Singh, D. Balakrishnan, S. Sharma, S. Devunuri, S. C. R. Korlapati, Crackseg9k: A collection and benchmark for crack segmen- tation datasets and frameworks, in: ECCV 2022 Workshops, Springer, 2022, pp. 179–195.doi:10.1007/978-3-031-25082-8_12. URLhttps://arxiv.org/abs/2208.13054
-
[19]
Y. Liu, J. Yao, X. Lu, R. Xie, L. Li, Deepcrack: A deep hierarchical feature learning architecture for crack segmentation, Neurocomputing 338 (2019) 139–153.doi:10.1016/j.neucom.2019.01.036
-
[20]
Zhang, F
L. Zhang, F. Yang, Y. D. Zhang, Y. J. Zhu, Road crack detection using deep convolutional neural network, in: Image Processing (ICIP), 2016 IEEE International Conference on, IEEE, 2016, pp. 3708–3712
2016
- [21]
-
[22]
M. Ren, X. Zhang, X. Zhi, Y. Wei, Z. Feng, An annotated street view image dataset for automated road damage detection, Scientific Data 11 (1) (Apr. 2024).doi:10.1038/s41597-024-03263-7. URLhttp://dx.doi.org/10.1038/s41597-024-03263-7 64
-
[23]
Z. Liu, W. Wu, X. Gu, B. Cui, Pavedistress: A comprehensive dataset of pavement distresses detection, Data in Brief 57 (2024) 111111. doi:https://doi.org/10.1016/j.dib.2024.111111. URLhttps://www.sciencedirect.com/science/article/pii/ S2352340924010734
- [25]
-
[26]
Y. Zhang, C. Liu, Vision-enhanced multi-modal learning frame- work for non-destructive pavement damage detection, Au- tomation in Construction 177 (2025) 106389.doi:https: //doi.org/10.1016/j.autcon.2025.106389. URLhttps://www.sciencedirect.com/science/article/pii/ S0926580525004297
- [27]
-
[28]
u. F. Özgenel, Concrete crack images for classification (2019).doi: 10.17632/5Y9WDSG2ZT.2. URLhttps://data.mendeley.com/datasets/5y9wdsg2zt/2
-
[29]
S. Dorafshan, R. Thomas, M. Maguire, Sdnet2018: An annotated image dataset for non-contact concrete crack detection using deep convolu- tional neural networks, Data in Brief 21 (11 2018).doi:10.1016/j. dib.2018.11.015. 65
work page doi:10.1016/j 2018
-
[30]
M. Eisenbach, R. Stricker, D. Seichter, K. Amende, K. Debes, M. Sessel- mann, D. Ebersbach, U. Stoeckert, H.-M. Gross, How to get pavement distress detection ready for deep learning? a systematic approach, in: 2017 International Joint Conference on Neural Networks (IJCNN), 2017, pp. 2039–2047.doi:10.1109/IJCNN.2017.7966101
-
[31]
R. Stricker, M. Eisenbach, M. Sesselmann, K. Debes, H.-M. Gross, Im- proving visual road condition assessment by extensive experiments on the extended gaps dataset, in: 2019 International Joint Conference on Neural Networks (IJCNN), 2019, pp. 1–8.doi:10.1109/IJCNN.2019. 8852257
-
[32]
Maeda, Y
H. Maeda, Y. Sekimoto, T. Seto, T. Kashiyama, H. Omata, Road dam- age detection and classification using deep neural networks with smart- phone images: Road damage detection and classification, Computer- Aided Civil and Infrastructure Engineering 33 (06 2018).doi:10.1111/ mice.12387
2018
- [33]
-
[34]
H. Yang, J. Cao, J. Wan, Q. Gao, C. Liu, M. Fischer, Y. Du, Y. Li, P. Jain, D. Wu, A large-scale image repository for automated pavement distress analysis and degradation trend prediction, Scientific Data 12 (1) (Aug. 2025).doi:10.1038/s41597-025-05748-5. URLhttp://dx.doi.org/10.1038/s41597-025-05748-5
-
[35]
Q. Zou, Y. Cao, Q. Li, Q. Mao, S. Wang, Cracktree: Automatic crack detection from pavement images, Pattern Recognition Letters 33 (3) (2012) 227–238
2012
-
[36]
Y. Shi, L. Cui, Z. Qi, F. Meng, Z. Chen, Automatic road crack detec- tion using random structured forests, IEEE Transactions on Intelligent Transportation Systems 17 (12) (2016) 3434–3445
2016
-
[37]
Q. Zou, Z. Zhang, Q. Li, X. Qi, Q. Wang, S. Wang, Deepcrack: Learning hierarchical convolutional features for crack detection, IEEE Transac- tions on Image Processing 28 (3) (2019) 1498–1512. 66
2019
-
[38]
Kulkarni, S
S. Kulkarni, S. Singh, D. Balakrishnan, S. Sharma, S. Devunuri, S. C. R. Korlapati, Crackseg9k: a collection and benchmark for crack segmenta- tion datasets and frameworks, in: European Conference on Computer Vision, Springer, 2022, pp. 179–195
2022
-
[39]
S. Han, I.-H. Chung, Y. Jiang, B. Uwakweh, Pcier: Pavement condition evaluation using aerial imagery and deep learning, Geographies 3 (1) (2023) 132–142.doi:10.3390/geographies3010008. URLhttps://www.mdpi.com/2673-7086/3/1/8
-
[40]
Adu-Gyamfi, B
Y. Adu-Gyamfi, B. Buttlar, E. Dave, D. Mensching, H. Majidifard, DSPS — dsps-1e998.web.app,https://dsps-1e998.web.app/data, [Accessed 09-02-2025]
2025
-
[41]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning (2023).arXiv: 2304.08485. URLhttps://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[42]
L. Chen, J. Li, X. Dong, P. Zhang, C. He, J. Wang, F. Zhao, D. Lin, Sharegpt4v: Improving large multi-modal models with better captions (2023).arXiv:2311.12793. URLhttps://arxiv.org/abs/2311.12793
work page internal anchor Pith review arXiv 2023
- [43]
-
[44]
M. Moor, Q. Huang, S. Wu, M. Yasunaga, Y. Dalmia, J. Leskovec, C. Zakka, E. P. Reis, P. Rajpurkar, Med-flamingo: a multimodal med- ical few-shot learner, in: S. Hegselmann, A. Parziale, D. Shanmugam, S. Tang, M. N. Asiedu, S. Chang, T. Hartvigsen, H. Singh (Eds.), Pro- ceedings of the 3rd Machine Learning for Health Symposium, Vol. 225 of Proceedings of M...
2023
-
[45]
Deruyttere, S
T. Deruyttere, S. Vandenhende, D. Grujicic, L. Van Gool, M. F. Moens, Talk2car: Taking control of your self-driving car, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Process- ing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 2088–2098. 67
2019
-
[46]
X. Tian, J. Gu, B. Li, Y. Liu, Y. Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, H. Zhao, Drivevlm: The convergence of autonomous driving and large vision-language models (2024).arXiv:2402.12289. URLhttps://arxiv.org/abs/2402.12289
work page internal anchor Pith review arXiv 2024
-
[47]
S. Lobry, D. Marcos, J. Murray, D. Tuia, Rsvqa: Visual question an- swering for remote sensing data, IEEE Transactions on Geoscience and Remote Sensing 58 (12) (2020) 8555–8566.doi:10.1109/TGRS.2020. 2988782
-
[48]
P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Tafjord, P. Clark, A. Kalyan, Learn to explain: Multimodal reasoning via thought chains for science question answering, in: The 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[49]
A Diagram Is Worth A Dozen Images
A. Kembhavi, M. Salvato, E. Kolve, M. Seo, H. Hajishirzi, A. Farhadi, A diagram is worth a dozen images (2016).arXiv:1603.07396
work page Pith review arXiv 2016
-
[50]
Docvqa: A dataset for vqa on document images
M. Mathew, D. Karatzas, C. V. Jawahar, Docvqa: A dataset for vqa on document images (2021).arXiv:2007.00398. URLhttps://arxiv.org/abs/2007.00398
- [51]
-
[52]
H. Majidifard, P. Jin, Y. Adu-Gyamfi, W. G. Buttlar, Pavement image datasets: A new benchmark dataset to classify and densify pavement distresses, Transportation Research Record 2674 (2) (2020) 328–339. arXiv:https://doi.org/10.1177/0361198120907283,doi:10.1177/ 0361198120907283. URLhttps://doi.org/10.1177/0361198120907283
-
[53]
J. Zhu, J. Zhong, T. Ma, X. Huang, W. Zhang, Y. Zhou, Pavement distress detection using convolutional neural networks with images captured via uav, Automation in Construction 133 (2022) 103991. doi:https://doi.org/10.1016/j.autcon.2021.103991. URLhttps://www.sciencedirect.com/science/article/pii/ S0926580521004428 68
-
[54]
H. Yan, J. Zhang, Uav-pdd2023: A benchmark dataset for pavement distress detection based on uav images, Data in Brief 51 (2023) 109692. doi:https://doi.org/10.1016/j.dib.2023.109692. URLhttps://www.sciencedirect.com/science/article/pii/ S2352340923007710
-
[55]
M. Sharif, G. Han, W. Liu, X. Huang, Cultivating multidisciplinary research and education on gpu infrastructure for mid-south institutions at the university of memphis: Practice and challenge (2025).arXiv: 2504.14786. URLhttps://arxiv.org/abs/2504.14786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Everingham, L
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, A. Zisser- man, The PASCAL visual object classes (VOC) challenge, International Journal of Computer Vision 88 (2) (2010) 303–338
2010
-
[57]
D. M. W. Powers, Evaluation: From precision, recall and F-measure to ROC, informedness, markedness & correlation, Journal of Machine Learning Technologies 2 (1) (2011) 37–63
2011
-
[58]
V. I. Levenshtein, Binary codes capable of correcting deletions, inser- tions and reversals, Soviet Physics Doklady 10 (8) (1966) 707–710
1966
-
[59]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, I. Sto- ica, Judging LLM-as-a-judge with MT-bench and chatbot arenaNeurIPS 2023 Datasets and Benchmarks Track (2023).arXiv:2306.05685, doi:10.48550/arXiv.2306.05685. URLhttps://arxiv.org/abs/2306.05685
work page internal anchor Pith review doi:10.48550/arxiv.2306.05685 2023
-
[60]
B leu: a method for automatic evaluation of machine translation
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, BLEU: a method for au- tomatic evaluation of machine translation, in: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Asso- ciationforComputationalLinguistics, Philadelphia, Pennsylvania, USA, 2002, pp. 311–318.doi:10.3115/1073083.1073135. URLhttps://aclanthology.org/P02-1040/
-
[61]
Lin, ROUGE: A package for automatic evaluation of summaries, in: Text Summarization Branches Out, Association for Computational 69 Linguistics, Barcelona, Spain, 2004, pp
C.-Y. Lin, ROUGE: A package for automatic evaluation of summaries, in: Text Summarization Branches Out, Association for Computational 69 Linguistics, Barcelona, Spain, 2004, pp. 74–81. URLhttps://aclanthology.org/W04-1013/
2004
-
[62]
Vedantam, C
R. Vedantam, C. L. Zitnick, D. Parikh, CIDEr: Consensus-based image description evaluation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 4566–4575. URLhttps://openaccess.thecvf.com/content_cvpr_2015/html/ Vedantam_CIDEr_Consensus-Based_Image_2015_CVPR_paper.html 70
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.