A French OSCE Dialogue Dataset and Controllable Virtual Patient System for Clinical Training
Pith reviewed 2026-06-30 01:27 UTC · model grok-4.3
The pith
A French dataset of 240 OSCE interactions supports a controllable LLM pipeline that generates virtual patients with improved fidelity for medical student training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
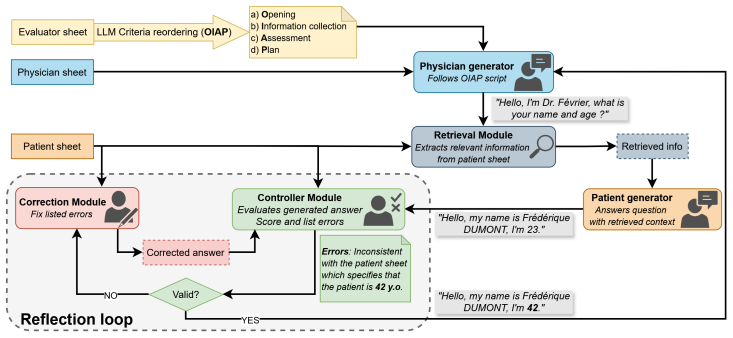
The authors present a French OSCE dialogue dataset of 240 interactions and a controllable pipeline that integrates retrieval-based grounding and a reflection loop to generate synthetic dialogues, showing through LLM-as-Judge evaluation that the controllability modules enhance patient fidelity and student evaluation consistency.
What carries the argument
A controllable LLM-based pipeline with retrieval-based grounding and reflection loop for ensuring patient fidelity in virtual OSCE simulations.
If this is right
- Students gain access to on-demand practice with virtual patients in French.
- Automated multi-level feedback becomes feasible for communication skills training.
- The approach can be extended to generate more diverse scenarios.
- Consistency in evaluations improves across simulated sessions.
Where Pith is reading between the lines
- This system could reduce reliance on human actors in medical education globally if adapted to other languages.
- Integration with real-time speech interfaces might create fully interactive training environments.
- The dataset could serve as a benchmark for other dialogue generation models in healthcare.
Load-bearing premise
The assumption that an LLM acting as a judge can reliably and accurately assess patient simulation quality and student performance without validation from human experts.
What would settle it
A study where human medical educators rate the same simulations and compare their scores to those from the LLM-as-a-Judge framework, checking for agreement.
Figures



read the original abstract
The clinical and communication skills of medical students are commonly assessed through Objective Structured Clinical Examinations (OSCEs), which consist of brief scenario-driven simulations of doctor-patient interactions. However, training is often limited by the low availability of human standardized patients, motivating the development of realistic virtual patients (VPs). To address this gap, we introduce a French OSCE dialogue dataset comprising 240 student-patient training interactions. We build upon it a controllable LLM-based pipeline to generate synthetic OSCE dialogues. The pipeline integrates modular components, such as retrieval-based grounding and a reflection loop, to ensure patient fidelity, coherence, and realism. Additionally, we propose a multi-level evaluation framework assessing patient simulation quality, student performance, and linguistic quality, using an LLM-as-a-Judge approach. Experiments suggest that controllability modules generally improve patient fidelity and student evaluation consistency. Finally, we implement an interactive prototype in which students can practice with a VP and receive automatic feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a French OSCE dialogue dataset of 240 student-patient training interactions and a controllable LLM-based pipeline for generating synthetic dialogues. The pipeline uses modular components such as retrieval-based grounding and a reflection loop to promote patient fidelity, coherence, and realism. It further proposes a multi-level LLM-as-a-Judge evaluation framework to assess patient simulation quality, student performance, and linguistic quality. Experiments indicate that the controllability modules improve patient fidelity and student evaluation consistency, and the work concludes with an interactive prototype allowing students to practice with virtual patients and receive automatic feedback.
Significance. If the central experimental claims hold after proper validation, the dataset and modular pipeline would provide a valuable resource for French-language medical communication training, addressing the scarcity of standardized patients. The controllable generation approach and multi-level evaluation framework could serve as a template for domain-specific dialogue systems. The absence of human-expert calibration for the LLM judge, however, substantially reduces the strength of the reported improvements.
major comments (2)
- [Evaluation Framework / Experiments] Evaluation Framework (described in the experiments and evaluation sections): The headline result that controllability modules improve patient fidelity and student evaluation consistency rests entirely on scores from the proposed multi-level LLM-as-a-Judge framework. No correlation, calibration, or agreement statistics with human medical experts are reported on the same criteria, making it impossible to determine whether the observed gains reflect genuine clinical realism or merely LLM-internal biases.
- [Dataset] Dataset section: The manuscript states that the dataset comprises 240 interactions but provides no quantitative statistics (e.g., distribution across scenarios, average dialogue length, inter-annotator agreement if any human labeling occurred) or details on collection protocol, participant recruitment, or ethical approval. These omissions are load-bearing for claims about the dataset's utility and the generalizability of the pipeline trained on it.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction would benefit from explicit forward references to the specific sections containing dataset statistics, experimental setup, and human-validation results (or their absence).
- [Pipeline Description] Notation for the controllability modules (retrieval grounding, reflection loop) should be defined consistently when first introduced and reused in the evaluation tables or figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation Framework / Experiments] Evaluation Framework (described in the experiments and evaluation sections): The headline result that controllability modules improve patient fidelity and student evaluation consistency rests entirely on scores from the proposed multi-level LLM-as-a-Judge framework. No correlation, calibration, or agreement statistics with human medical experts are reported on the same criteria, making it impossible to determine whether the observed gains reflect genuine clinical realism or merely LLM-internal biases.
Authors: We agree that the lack of human-expert calibration or agreement statistics for the LLM-as-Judge is a substantive limitation. The reported improvements in patient fidelity and evaluation consistency are based solely on the LLM judge outputs, and without external validation it is not possible to rule out model-specific biases. In the revised manuscript we will explicitly discuss this limitation in a dedicated subsection and add any available preliminary human agreement data if it can be obtained without new data collection; otherwise we will frame the LLM-as-Judge results as an internal consistency metric rather than a definitive clinical validation. revision: partial
-
Referee: [Dataset] Dataset section: The manuscript states that the dataset comprises 240 interactions but provides no quantitative statistics (e.g., distribution across scenarios, average dialogue length, inter-annotator agreement if any human labeling occurred) or details on collection protocol, participant recruitment, or ethical approval. These omissions are load-bearing for claims about the dataset's utility and the generalizability of the pipeline trained on it.
Authors: We acknowledge that the current manuscript lacks the requested quantitative and procedural details. The revised version will expand the Dataset section to include: scenario distribution, average and range of dialogue lengths, any inter-annotator statistics, a full description of the collection protocol, participant recruitment process, and confirmation of ethical approval and consent procedures. revision: yes
Circularity Check
No significant circularity; dataset curation and systems work is self-contained
full rationale
The paper introduces a French OSCE dialogue dataset of 240 interactions, constructs a modular LLM pipeline with retrieval grounding and reflection loop for synthetic dialogue generation, and proposes a multi-level LLM-as-a-Judge evaluation framework. No mathematical derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, uniqueness theorems, or ansatzes smuggled via citation are present. The experimental suggestion that controllability modules improve fidelity is an empirical observation from the proposed system and judge, not a reduction to inputs by construction. This matches the default expectation for non-circular systems/dataset papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-a-Judge provides a valid proxy for human evaluation of patient fidelity and student performance
Reference graph
Works this paper leans on
-
[1]
Chirkova, Nadezhda and Ajayi, Tunde Oluwaseyi and Aycock, Seth and Mujahid, Zain Muhammad and Perli. Proceedings of the. doi:10.18653/v1/2026.mme-main.7 , url =
-
[2]
The Innovation7(6), 101253 (2026)
Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and Wang, Saizhuo and Zhang, Kun and Lin, Zhouchi and Zhang, Bowen and Ni, Lionel and Gao, Wen and Wang, Yuanzhuo and Guo, Jian , year = 2026, month = jan, journal =. A Survey on. doi:10.1016/j.xin...
-
[3]
Zeng, Guangtao and Yang, Wenmian and Ju, Zeqian and Yang, Yue and Wang, Sicheng and Zhang, Ruisi and Zhou, Meng and Zeng, Jiaqi and Dong, Xiangyu and Zhang, Ruoyu and Fang, Hongchao and Zhu, Penghui and Chen, Shu and Xie, Pengtao , editor =. Proceedings of the 2020. doi:10.18653/v1/2020.emnlp-main.743 , url =
-
[4]
Proceedings of the 2024
Labrak, Yanis and Bazoge, Adrien and El Khettari, Oumaima and Rouvier, Mickael and Constant Dit Beaufils, Pacome and Grabar, Natalia and Daille, B. Proceedings of the 2024
2024
-
[5]
Semantic Similarity to Improve Question Understanding in a Virtual Patient , booktitle =
Laleye, Fr. Semantic Similarity to Improve Question Understanding in a Virtual Patient , booktitle =. doi:10.1145/3341105.3373936 , url =
-
[6]
Li, Tao and Li, Gang and Deng, Zhiwei and Wang, Bryan and Li, Yang , editor =. A. Findings of the. doi:10.18653/v1/2023.findings-emnlp.753 , url =
-
[7]
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and Mcleavey, Christine and Sutskever, Ilya , year = 2023, month = jul, pages =. Robust. Proceedings of the 40th
2023
-
[8]
Saley, Vishal Vivek and Saha, Goonjan and Das, Rocktim Jyoti and Raghu, Dinesh and ., Mausam , editor =. Proceedings of the 2024. doi:10.18653/v1/2024.emnlp-main.936 , url =
-
[10]
and Stoica, Ion , year = 2023, month = dec, journal =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , year = 2023, month = dec, journal =. Judging
2023
-
[11]
International Journal of Clinical Pharmacy , year =
Yusuf Alzahrani and Sarah Rehman and Ejaz Cheema , title =. International Journal of Clinical Pharmacy , year =. doi:10.1007/s11096-025-01876-5 , url =
-
[12]
2025 , eprint=
LLM-Powered Virtual Patient Agents for Interactive Clinical Skills Training with Automated Feedback , author=. 2025 , eprint=
2025
-
[13]
Gemini 3.1 Flash-Lite , year =
-
[14]
Towards A Deep Learning Question-Answering Specialized Chatbot for Objective Structured Clinical Examinations , year=
Zini, Julia El and Rizk, Yara and Awad, Mariette and Antoun, Jumana , booktitle=. Towards A Deep Learning Question-Answering Specialized Chatbot for Objective Structured Clinical Examinations , year=
-
[15]
Garc. Enhancing Clinical Reasoning with Virtual Patients: A Hybrid Systematic Review Combining Human Reviewers and ChatGPT , journal =. 2024 , volume =. doi:10.3390/healthcare12222241 , pmid =
-
[18]
Jepson, M. and Salisbury, C. and Ridd, M. J. and Metcalfe, C. and Garside, L. and Barnes, R. K. , title =. British Journal of General Practice , year =. doi:10.3399/bjgp17x690521 , url =
-
[19]
Wang, Junda and Yao, Zonghai and Yang, Zhichao and Zhou, Huixue and Li, Rumeng and Wang, Xun and Xu, Yucheng and Yu, Hong , year=. NoteChat: A Dataset of Synthetic Patient-Physician Conversations Conditioned on Clinical Notes , url=. doi:10.18653/v1/2024.findings-acl.901 , booktitle=
-
[20]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
Ben Abacha, Asma and Yim, Wen-wai and Fan, Yadan and Lin, Thomas. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023
2023
-
[21]
Laleye, Fréjus A. A. and de Chalendar, Gaël and Blanié, Antonia and Brouquet, Antoine and Behnamou, Dan , month = may, year =. A. Proceedings of
-
[22]
Favre, Benoit and Cheung, Kyla and Kazemian, Siavash and Lee, Adam and Liu, Yang and Munteanu, Cosmin and Nenkova, Ani and Ochei, Dennis and Penn, Gerald and Tratz, Stephen and Voss, Clare and Zeller, Frauke , year =
-
[23]
2021 , eprint=
Rethinking Evaluation in ASR: Are Our Models Robust Enough? , author=. 2021 , eprint=
2021
-
[25]
Enabling Trait-based Personality Simulation in Conversational LLM Agents: Case Study of Customer Assistance in F rench
Njifenjou, Ahmed and Sucal, Virgile and Jabaian, Bassam and Lef \`e vre, Fabrice. Enabling Trait-based Personality Simulation in Conversational LLM Agents: Case Study of Customer Assistance in F rench. Proceedings of the 15th International Workshop on Spoken Dialogue Systems Technology. 2025
2025
-
[26]
2024 , eprint=
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation , author=. 2024 , eprint=
2024
-
[27]
2004 , month =
From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition , author =. 2004 , month =
2004
-
[28]
M ed D ialog- FR : A F rench Version of the M ed D ialog Corpus for Multi-label Classification and Response Generation Related to Women ' s Intimate Health
Liu, Xingyu and Segonne, Vincent and Mannion, Aidan and Schwab, Didier and Goeuriot, Lorraine and Portet, Fran c ois. M ed D ialog- FR : A F rench Version of the M ed D ialog Corpus for Multi-label Classification and Response Generation Related to Women ' s Intimate Health. Proceedings of the First Workshop on Patient-Oriented Language Processing (CL4Heal...
2024
-
[29]
2024 , eprint=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. 2024 , eprint=
2024
-
[30]
Journal of Medical Systems / Elsevier (ScienceDirect) , year=
Large Language Model–Based Virtual Patient Systems for History-Taking in Medical Education: Comprehensive Systematic Review , author=. Journal of Medical Systems / Elsevier (ScienceDirect) , year=. doi:S2291969426000013 , url=
-
[31]
2024 , eprint=
Synthetic Patient-Physician Dialogue Generation from Clinical Notes Using LLM , author=. 2024 , eprint=
2024
-
[32]
Journal of Medical Internet Research , volume=
Virtual Patients Using Large Language Models: Scalable, Contextualized Simulation of Clinician-Patient Dialogue With Feedback , author=. Journal of Medical Internet Research , volume=. 2025 , publisher=. doi:10.2196/68486 , url=
-
[33]
2026 , edition =
SOAP Notes , author =. 2026 , edition =
2026
-
[34]
Discover Artificial Intelligence , volume=
Applying state-of-the-art artificial intelligence to grading in simulation-based education: assessment, feedback, and ROI , author=. Discover Artificial Intelligence , volume=. 2025 , doi=
2025
-
[35]
Computational and Structural Biotechnology Journal , volume=
Integrating large language model-based agents into a virtual patient chatbot for clinical anamnesis training , author=. Computational and Structural Biotechnology Journal , volume=. 2025 , publisher=. doi:10.1016/j.csbj.2025.05.025 , url=
-
[36]
arXiv preprint arXiv:2305.13614 , year=
LLM-empowered Chatbots for Psychiatrist and Patient Simulation: Application and Evaluation , author=. arXiv preprint arXiv:2305.13614 , year=
-
[37]
and Zhi, Jiayin and Eack, Shaun M
Wang, Ruiyi and Milani, Stephanie and Chiu, Jamie C. and Zhi, Jiayin and Eack, Shaun M. and Labrum, Travis and Murphy, Samuel M and Jones, Nev and Hardy, Kate V and Shen, Hong and Fang, Fei and Chen, Zhiyu. PATIENT - : Using Large Language Models to Simulate Patients for Training Mental Health Professionals. Proceedings of the 2024 Conference on Empirical...
2024
-
[38]
2026 , url=
Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alex Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , booktitle=. 2026 , url=
2026
-
[39]
2025 , eprint=
CUB: Benchmarking Context Utilisation Techniques for Language Models , author=. 2025 , eprint=
2025
-
[40]
2024 , eprint=
Large Language Models for Medical OSCE Assessment: A Novel Approach to Transcript Analysis , author=. 2024 , eprint=
2024
-
[41]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[42]
2025 , url =
Claude Haiku 4.5 System Card , author =. 2025 , url =
2025
-
[43]
arXiv preprint arXiv:2601.08584 , year=
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
-
[44]
Proceedings of the 15th International Conference on Language Resources and Evaluation (LREC 2026) , year =
LLM-Based Data Generation and Clinical Skills Evaluation for Low-Resource French OSCEs , author =. Proceedings of the 15th International Conference on Language Resources and Evaluation (LREC 2026) , year =
2026
-
[45]
2024 , eprint=
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data , author=. 2024 , eprint=
2024
-
[46]
Journal of Chiropractic Medicine , volume=
A guideline of selecting and reporting intraclass correlation coefficients for reliability research , author=. Journal of Chiropractic Medicine , volume=. 2016 , doi=
2016
-
[47]
Frontiers in Virtual Reality , volume=
Embodied virtual patients as a simulation-based framework for training clinician-patient communication skills: An overview of their use in psychiatric and geriatric care , author=. Frontiers in Virtual Reality , volume=. 2022 , publisher=
2022
-
[48]
fr\_core\_news\_md: spaCy French model , year =
-
[49]
2024 , url =
Jitsi , title =. 2024 , url =
2024
-
[50]
2024 , url =
PyAnnoteAI , title =. 2024 , url =
2024
-
[51]
2024 , url =
OpenAI , title =. 2024 , url =
2024
-
[52]
Advances in Simulation , volume =
The Association of Standardized Patient Educators (ASPE) Standards of Best Practice , author =. Advances in Simulation , volume =. 2017 , doi =
2017
-
[53]
McNeill, Matthew and Levitan, Rivka , month = aug, year =. An. doi:10.21437/Interspeech.2023-2525 , abstract =
-
[55]
and Cortes, Ariel and Pomares, Alexandra and Delgadillo, Vivian and Yepes, Francisco J
Gorbanev, Iouri and Agudelo-Londoño, Sandra and González, Rafael A. and Cortes, Ariel and Pomares, Alexandra and Delgadillo, Vivian and Yepes, Francisco J. and Muñoz, Óscar , month = jan, year =. A systematic review of serious games in medical education: quality of evidence and pedagogical strategy , copyright =. Medical Education Online , publisher =
-
[56]
JMIR Serious Games , month = jan, year =
Developing. JMIR Serious Games , month = jan, year =. doi:10.2196/11565 , abstract =
-
[57]
Huang, Yining and Tang, Keke and Chen, Meilian and Wang, Boyuan , month = may, year =. A. doi:10.48550/arXiv.2404.15777 , abstract =
-
[58]
Ye, Qinyuan and Axmed, Maxamed and Pryzant, Reid and Khani, Fereshte , month = jul, year =. Prompt. doi:10.48550/arXiv.2311.05661 , abstract =
-
[59]
Li, Wenwu and Wang, Xiangfeng and Li, Wenhao and Jin, Bo , month = feb, year =. A. doi:10.48550/arXiv.2502.11560 , abstract =
-
[60]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , month = feb, year =. doi:10.48...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457
-
[61]
doi:10.48550/arXiv.2506.09147 , abstract =
Chirkova, Nadezhda and Ajayi, Tunde Oluwaseyi and Aycock, Seth and Mujahid, Zain Muhammad and Perlić, Vladana and Borisova, Ekaterina and Vartampetian, Markarit , month = dec, year =. doi:10.48550/arXiv.2506.09147 , abstract =
-
[62]
Li, Tao and Li, Gang and Deng, Zhiwei and Wang, Bryan and Li, Yang , month = oct, year =. A. doi:10.48550/arXiv.2310.08740 , abstract =
-
[63]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , month = jan, year =. Chain-of-. doi:10.48550/arXiv.2201.11903 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[64]
Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, S. Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and Payne, Perry and Seneviratne, Martin and Gamble, Paul and Kelly, Chris and Scharli, Nathaneal and Chowdhery, Aakanksha and Mansfield, Philip and Arcas, Blaise Aguera y ...
-
[65]
and Xiong, Caiming and Joty, Shafiq and Wu, Chien-Sheng , month = may, year =
Laban, Philippe and Kryściński, Wojciech and Agarwal, Divyansh and Fabbri, Alexander R. and Xiong, Caiming and Joty, Shafiq and Wu, Chien-Sheng , month = may, year =. doi:10.48550/arXiv.2305.14540 , abstract =
-
[66]
Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and Wang, Saizhuo and Zhang, Kun and Wang, Yuanzhuo and Gao, Wen and Ni, Lionel and Guo, Jian , month = mar, year =. A. doi:10.48550/arXiv.2411.15594 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594
-
[67]
Lu, Christina and Gallagher, Jack and Michala, Jonathan and Fish, Kyle and Lindsey, Jack , month = jan, year =. The. doi:10.48550/arXiv.2601.10387 , abstract =
-
[68]
Lee, Seungbeen and Lim, Seungwon and Han, Seungju and Oh, Giyeong and Chae, Hyungjoo and Chung, Jiwan and Kim, Minju and Kwak, Beong-woo and Lee, Yeonsoo and Lee, Dongha and Yeo, Jinyoung and Yu, Youngjae , month = mar, year =. Do. doi:10.48550/arXiv.2406.14703 , abstract =
-
[69]
Learning emotions latent representation with. Neural Networks , author =. 2021 , keywords =. doi:10.1016/j.neunet.2021.04.021 , abstract =
-
[70]
Keshtkar, Leila and Madigan, Claire D. and Ward, Andy and Ahmed, Sarah and Tanna, Vinay and Rahman, Ismail and Bostock, Jennifer and Nockels, Keith and Wang, Wen and Gillies, Clare L. and Howick, Jeremy , month = feb, year =. The. Annals of Internal Medicine , publisher =. doi:10.7326/M23-2168 , abstract =
-
[71]
Sutcliffe, Richard , month = dec, year =. A. doi:10.48550/arXiv.2401.00609 , abstract =
-
[72]
Effectiveness of empathy in general practice: a systematic review , volume =. The British Journal of General Practice: The Journal of the Royal College of General Practitioners , author =. 2013 , keywords =. doi:10.3399/bjgp13X660814 , abstract =
-
[73]
Krook, Joshua , month = feb, year =. Manipulation and the. doi:10.2139/ssrn.4719835 , abstract =
-
[74]
Natural Language Engineering , author =
Designing a virtual patient dialogue system based on terminology-rich resources:. Natural Language Engineering , author =. 2020 , pages =. doi:10.1017/S1351324919000329 , abstract =
-
[75]
IEEE Transactions on Cognitive and Developmental Systems , author =
Dialogue. IEEE Transactions on Cognitive and Developmental Systems , author =. 2022 , pages =. doi:10.1109/TCDS.2021.3086565 , abstract =
-
[76]
Mao, Shengyu and Wang, Xiaohan and Wang, Mengru and Jiang, Yong and Xie, Pengjun and Huang, Fei and Zhang, Ningyu , month = sep, year =. Editing. doi:10.48550/arXiv.2310.02168 , abstract =
-
[77]
Annales Médico-psychologiques, revue psychiatrique , author =
Histoire des «. Annales Médico-psychologiques, revue psychiatrique , author =. 2010 , pages =. doi:10.1016/j.amp.2009.04.016 , abstract =
-
[78]
Personality engineering:. Advances in. 1995 , pages =. doi:10.1016/S0921-2647(06)80262-5 , abstract =
-
[79]
Galland, Lucie , month = oct, year =
-
[80]
Kerz, E., Qiao, Y ., Zanwar, S., and Wiechmann, D
Jiang, Hang and Zhang, Xiajie and Cao, Xubo and Breazeal, Cynthia and Roy, Deb and Kabbara, Jad , month = apr, year =. doi:10.48550/arXiv.2305.02547 , abstract =
-
[81]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
Personalized. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2023 , note =. doi:10.1609/aaai.v37i11.26518 , abstract =
-
[82]
Galland, Lucie and Pelachaud, Catherine and Pecune, Florian , month = jul, year =. Tailored. doi:10.48550/arXiv.2506.19652 , abstract =
-
[83]
Fire, Michael and Elbazis, Yitzhak and Wasenstein, Adi and Rokach, Lior , month = may, year =. Dark. doi:10.48550/arXiv.2505.10066 , abstract =
-
[84]
Computers in Human Behavior , author =
Exploring relationship development with social chatbots:. Computers in Human Behavior , author =. 2023 , keywords =. doi:10.1016/j.chb.2022.107600 , abstract =
-
[85]
Kovacevic, Nikola and Holz, Christian and Gross, Markus and Wampfler, Rafael , month = oct, year =. A. Proceedings of the 25th. doi:10.1145/3717511.3747070 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.