Small LLMs: Pruning vs. Training from Scratch
Pith reviewed 2026-06-27 05:03 UTC · model grok-4.3
The pith
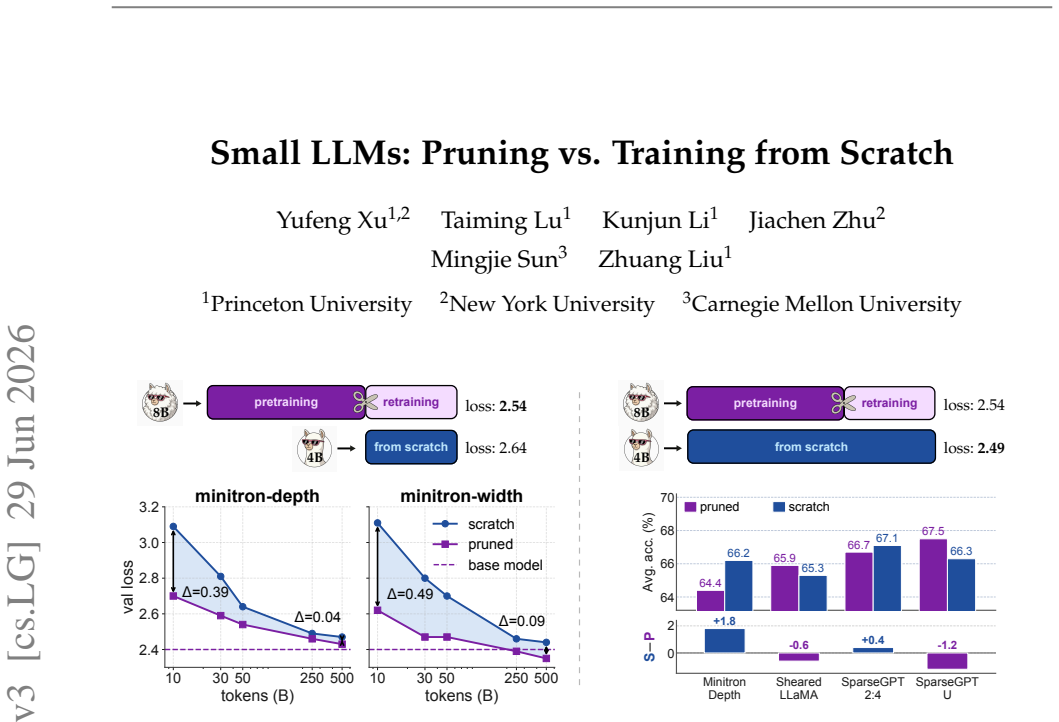
Pruning a large LLM to create small ones outperforms training from scratch when the training token budget is limited.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
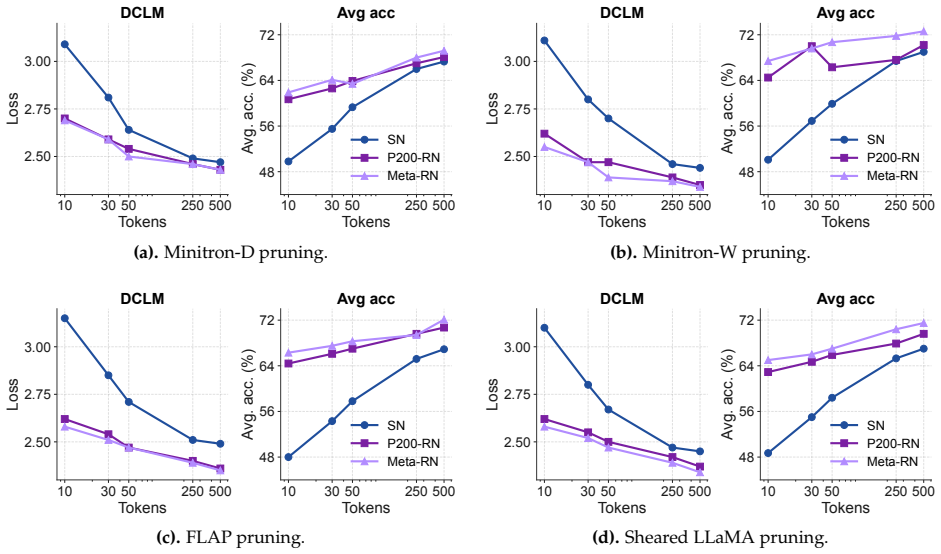
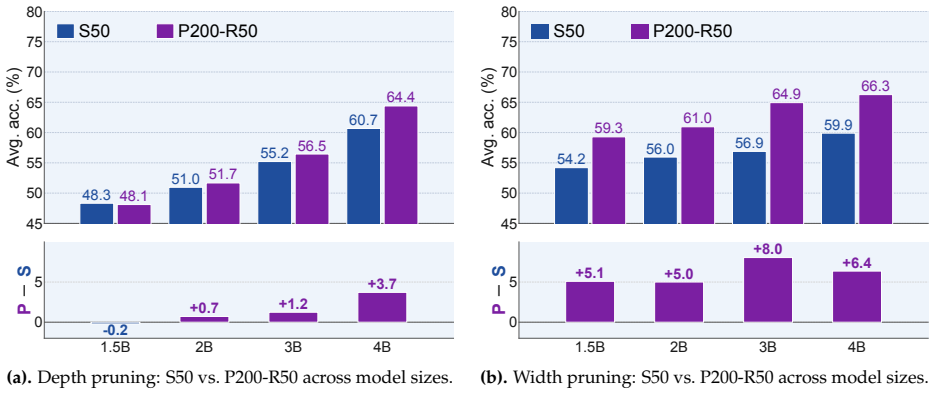
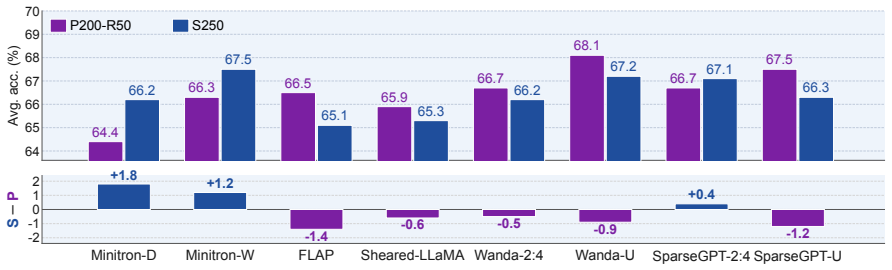
Under matched training token budgets, pruned initialization from the parent model consistently outperforms random initialization. When training from scratch is instead allotted the full token budget of the pruning pipeline, pruning at finer granularities retains an advantage while coarser structured pruning can be matched or surpassed. This indicates that the parent model transfers knowledge that additional training tokens alone cannot fully recover, but only when pruning operates at fine granularity.
What carries the argument
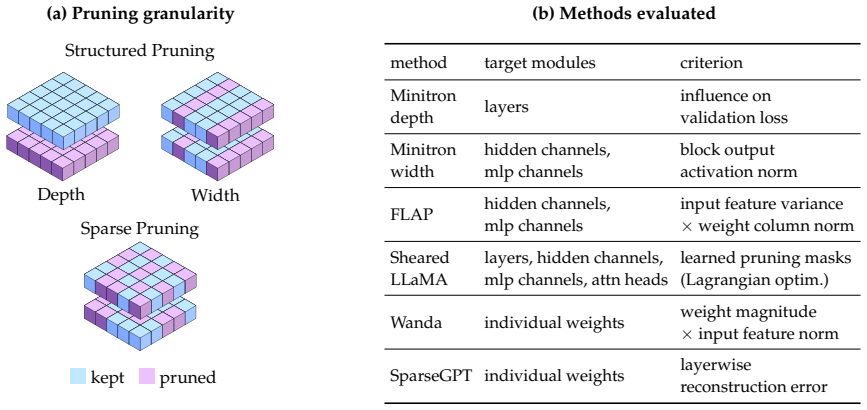
Token-matched experimental settings that isolate the effect of pruned initialization from a large parent versus random initialization across six pruning methods at ratios 0.5-0.8.
If this is right
- When training tokens are scarce, pruning a large parent is the stronger route to a small model.
- When training tokens are abundant, training from scratch becomes competitive for coarse structured pruning.
- The performance gap between pruned and random initialization narrows as the pruning ratio increases.
- Knowledge transferred from the parent model cannot be recovered by tokens alone when pruning is fine-grained.
- A large pretrained parent is not always required if the practitioner can afford a large training budget.
Where Pith is reading between the lines
- For extremely large future token budgets the marginal value of maintaining and pruning very large parent models may decline.
- Hardware or data-center operators who can allocate long training runs may safely skip the cost of keeping oversized parent models.
- The granularity dependence suggests that hybrid pipelines mixing coarse structured pruning with later fine unstructured pruning deserve direct comparison.
Load-bearing premise
The token budgets are accurately matched between the pruning-plus-retraining pipeline and the pure from-scratch condition, and the six tested pruning methods are representative of the broader space of possible techniques.
What would settle it
A controlled replication in which training from scratch with the full pipeline token budget matches or exceeds every pruned model at every granularity and every ratio would falsify the retained advantage of fine-grained pruning.
Figures
read the original abstract
Pruning promises a shortcut to strong small language models. In this work, we examine this promise by pruning Llama-3.1-8B at pruning ratios of 0.5--0.8 with six methods spanning depth, width, and sparse granularities, under two controlled token-matched settings. (1) With the same training token budget, pruned initialization consistently outperforms random initialization. This shows that the parent model provides a strong starting point, although the advantage narrows as the training token budget grows and as the pruning ratio rises, nearly vanishing at the highest pruning ratio we study. (2) When training from scratch is instead given the full token budget consumed by the whole pipeline, pruning at finer granularities still retains an advantage, while coarser structured pruning can be matched or surpassed. This suggests that the parent model transfers knowledge that additional training tokens alone cannot fully recover, but only at fine granularity. Taken together, our results yield a clear recommendation: with a large pretrained model in hand and a limited training token budget, pruning is better than training from scratch; when the training budget is not limited, training from scratch can be competitive for coarser pruning, so a large pretrained parent is not always necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares pruning Llama-3.1-8B at ratios 0.5-0.8 using six methods (depth, width, sparse) against training from scratch, under two controlled token-matched settings. Setting (1) uses the same post-pruning training tokens and finds pruned init outperforms random init, with the gap narrowing at higher budgets/ratios. Setting (2) gives scratch training the full pipeline token count and finds finer pruning retains advantage while coarser structured pruning can be matched or surpassed. The recommendation is that pruning is preferable with limited budgets but a large parent is not always necessary for coarser pruning with unlimited budgets.
Significance. If the token budgets are verifiably matched and the six methods representative, the work supplies practical guidance on when pretrained knowledge via pruning cannot be recovered by extra tokens alone. The two-setting design with held-out performance measurement is a positive feature for an empirical study in this area.
major comments (1)
- [Abstract] Abstract: the central recommendation rests on the two settings being 'token-matched,' yet the abstract provides no explicit accounting of how pretraining tokens are included in the full pipeline budget, how epochs/sequence lengths are normalized across conditions, or whether batch sizes and optimizer steps are identical. This equivalence is load-bearing for the claim that pruning's advantage at limited budgets is due to initialization rather than budget mismatch.
minor comments (2)
- [Abstract] Abstract: the six pruning methods are described only at the level of 'spanning depth, width, and sparse granularities' without names or citations; the main text should list them explicitly with references for reproducibility.
- [Abstract] Abstract: directional trends are reported without mention of error bars, number of runs, or statistical tests; these should be added to the results sections to allow assessment of the reported narrowing of advantages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's description of the token-matching procedure. The concern is well-taken, as precise budget accounting is central to the claims. We address the point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central recommendation rests on the two settings being 'token-matched,' yet the abstract provides no explicit accounting of how pretraining tokens are included in the full pipeline budget, how epochs/sequence lengths are normalized across conditions, or whether batch sizes and optimizer steps are identical. This equivalence is load-bearing for the claim that pruning's advantage at limited budgets is due to initialization rather than budget mismatch.
Authors: We agree the abstract would benefit from greater precision on these points. In the revised version we will add a concise clause clarifying that (i) Setting (2) assigns the scratch model the sum of the parent model's original pretraining tokens plus the post-pruning training tokens, (ii) all runs use identical batch size, sequence length, and optimizer hyperparameters, and (iii) the number of optimizer steps is therefore matched once sequence length and batch size are fixed. The full experimental protocol, including these normalizations, is already detailed in Section 3; the abstract revision will simply surface the key equivalences without lengthening the summary excessively. revision: yes
Circularity Check
No circularity: purely empirical comparison with independent measurements
full rationale
The paper conducts controlled experiments comparing pruned initializations against random initialization and full-pipeline token budgets, reporting held-out performance metrics. No equations, fitted parameters, uniqueness theorems, or self-citations are used to derive the central claims; the token-matching conditions are stated as experimental controls rather than definitions, and results are falsifiable against external benchmarks. This is a standard empirical study with no load-bearing reductions to inputs by construction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.