Regression Accumulation in Multi-Turn LLM Programming Conversations
Pith reviewed 2026-07-03 09:11 UTC · model grok-4.3
The pith
Verification Gate, which checks new code against prior tests and rolls back on failure, is the only strategy that consistently raises final-turn quality across all tested LLMs in multi-turn programming conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
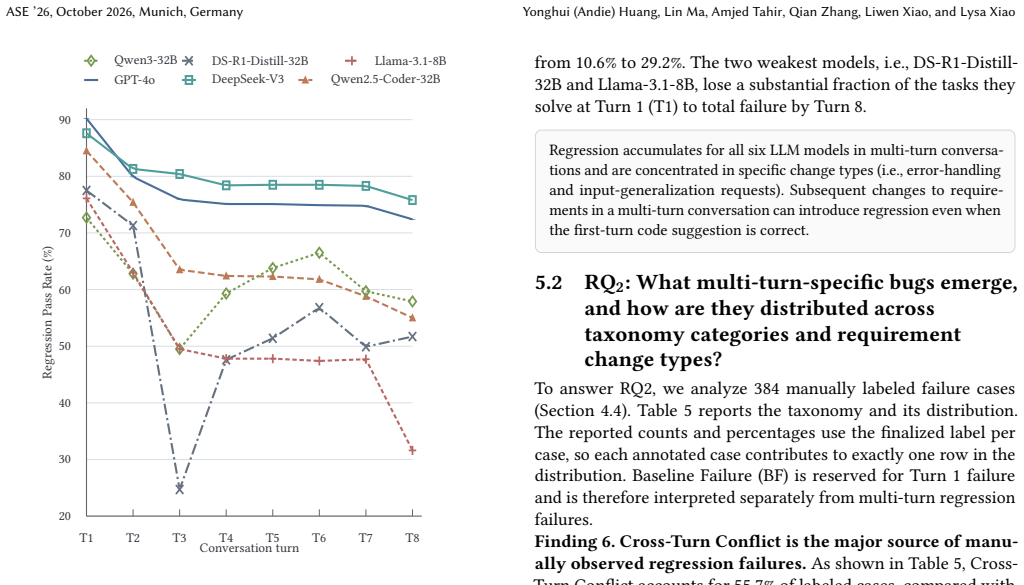
Regression accumulation occurs across all six evaluated LLMs, with 40 to 73 percent of tasks losing previously correct behavior over an 8-turn conversation. The dominant failure mode is Cross-Turn Conflict. The Verification Gate strategy, which tests new code against all prior tests and triggers rollback plus retry on any failure, is the only intervention that improves final-turn quality on every model.
What carries the argument
Verification Gate, a check that runs new code against the full set of tests accumulated from earlier turns and forces rollback on any regression.
If this is right
- Final-turn quality is lower than initial-turn quality for every model when later turns add input validation or broader input domains.
- Cross-Turn Conflict is the largest single failure class identified in the 384 manually labeled cases.
- Strong single-turn benchmark scores do not predict preservation of earlier requirements once the conversation continues.
- Evaluation protocols for LLM coding tools should measure whether later suggestions continue to satisfy all earlier tests.
Where Pith is reading between the lines
- Tool builders could embed Verification Gate checks directly into chat interfaces so that regressions are caught before the user sees the new code.
- Benchmark suites that remain static across turns will systematically underestimate the reliability gap between single-turn and iterative use.
- The same accumulation pattern may appear in other iterative LLM workflows, such as multi-turn data analysis or iterative document editing, where later changes can invalidate earlier outputs.
Load-bearing premise
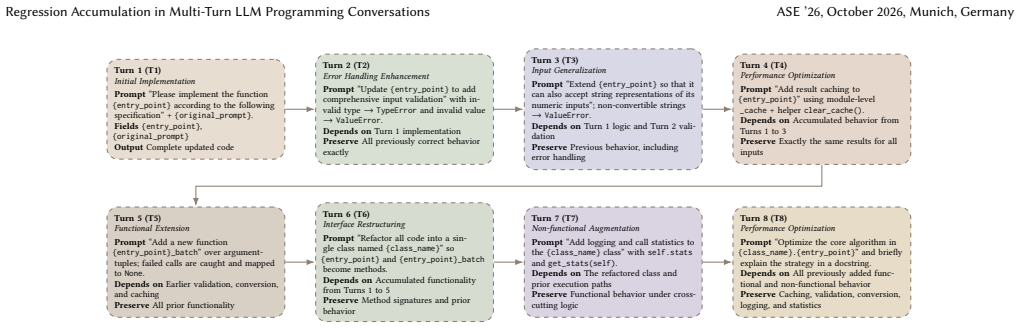
The manually extended 8-turn requirement-evolution chains built from HumanEval+ and MBPP+ tasks, together with their test suites, capture the kinds of requirement conflicts that occur in real multi-turn developer conversations.
What would settle it
Re-running the identical protocol on a corpus of logged, unscripted multi-turn coding sessions collected from actual developer tools or forums and checking whether regression rates and the relative benefit of Verification Gate remain comparable.
Figures
read the original abstract
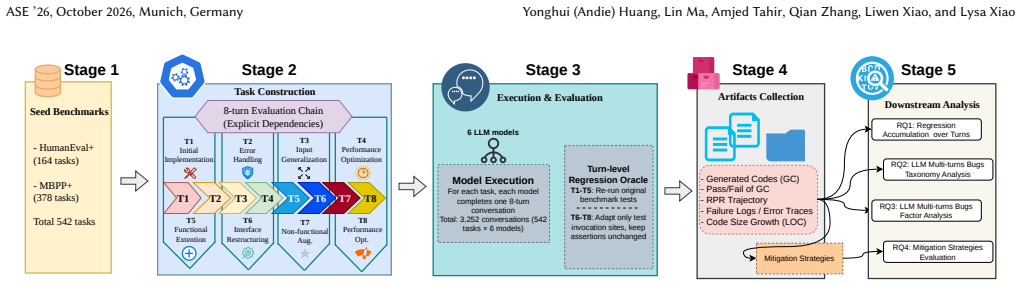
In LLM-assisted software development, coding is often iterative. We study regression accumulation in multi-turn LLM programming conversations, where later code suggestions may break requirements introduced in earlier turns. Reliability therefore depends not only on satisfying the current request, but also on preserving previously satisfied behavior. We construct 542 tasks from HumanEval+ and MBPP+ and extend each task into an 8-turn requirement-evolution chain. We evaluate six LLMs on 26,016 turn instances (542 x 6 x 8). At each turn, we test whether the current code still passes earlier benchmark tests. We also analyze 384 failure cases from the failure population and build a taxonomy of multi-turn regression bugs through independent four-annotator labeling. Our results show that regression accumulation appears across all six models: 40% to 73% of tasks lose previously correct behavior over the full conversation. Final-turn quality is lower than initial-turn quality across models, especially when later turns add input validation or broader input types. Manual analysis shows that Cross-Turn Conflict, where later code conflicts with earlier requirements, is the main failure class. We further find that Verification Gate, which checks new code against prior tests and triggers rollback and retry, is the only strategy that consistently improves all models, raising final-turn quality from 75.8% to 87.9% on DeepSeek-V3 and from 31.6% to 47.3% on Llama-3.1-8B. These findings suggest that strong single-turn performance can overestimate reliability in multi-turn coding conversations. Future evaluation and tool design should test whether later code suggestions preserve earlier requirements and should include Verification Gate mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that regression accumulation is common in multi-turn LLM programming conversations, with 40-73% of tasks losing previously correct behavior over 8 turns. Using 542 synthetically extended requirement chains from HumanEval+ and MBPP+, it evaluates six LLMs across 26,016 turn instances, derives a taxonomy from 384 failures showing Cross-Turn Conflict as dominant, and identifies Verification Gate (checking new code against prior tests with rollback/retry) as the only mitigation that consistently improves final-turn quality (e.g., 75.8%→87.9% on DeepSeek-V3; 31.6%→47.3% on Llama-3.1-8B). It concludes that single-turn metrics overestimate reliability and that future work should incorporate multi-turn preservation checks and Verification Gate mechanisms.
Significance. If the synthetic chains are representative, this 26k-instance measurement study with an independent four-annotator taxonomy provides concrete evidence that iterative LLM coding introduces systematic regression risks not captured by single-turn benchmarks. The explicit identification of Verification Gate as a consistent improver across models offers a falsifiable, actionable direction for tool design. The scale and failure taxonomy are strengths that could inform more robust evaluation protocols in LLM-assisted development.
major comments (3)
- [§3] §3 (Task Construction): The paper provides no details on the manual extension process for creating the 8-turn requirement-evolution chains (e.g., criteria for adding input validation or broader input types, or validation that added requirements are independent and produce realistic conflicts). This is load-bearing because the reported regression rates (40-73%), taxonomy, and Verification Gate gains are measured exclusively on these 542 chains; without evidence that they reproduce the frequency and structure of natural developer requests, generalization to 'actual multi-turn LLM programming conversations' is unsupported.
- [Results] Results (reported lifts for Verification Gate): The abstract and results state specific improvements (75.8% to 87.9% on DeepSeek-V3; 31.6% to 47.3% on Llama-3.1-8B) with no error bars, per-task variance, or statistical significance tests across the 542 tasks. This undermines the claim that Verification Gate 'consistently improves all models' because it is unclear whether the gains hold uniformly or are driven by subsets of the synthetic population.
- [§5] §5 (Mitigation Strategies): The evaluation of strategies lacks a baseline comparison for Verification Gate (e.g., against simple re-prompting without test checking or other rollback variants). The claim that it is 'the only strategy that consistently improves all models' therefore rests on an incomplete set of comparators, making it difficult to assess whether the reported lift is distinctive or incremental.
minor comments (2)
- [Abstract] Abstract: The number of models (six) and total turn instances (26,016) could be stated earlier for immediate clarity on scale.
- [Failure analysis] Failure analysis: The taxonomy section should explicitly state inter-annotator agreement metrics for the four-annotator labeling of the 384 cases.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [§3] §3 (Task Construction): The paper provides no details on the manual extension process for creating the 8-turn requirement-evolution chains (e.g., criteria for adding input validation or broader input types, or validation that added requirements are independent and produce realistic conflicts). This is load-bearing because the reported regression rates (40-73%), taxonomy, and Verification Gate gains are measured exclusively on these 542 chains; without evidence that they reproduce the frequency and structure of natural developer requests, generalization to 'actual multi-turn LLM programming conversations' is unsupported.
Authors: We agree that the current description of the manual extension process in §3 is insufficient. In the revised manuscript we will add a dedicated subsection detailing the criteria for evolving requirements (e.g., addition of input validation and broader input types), the steps taken to maintain independence between turns, and any internal validation performed for realism. We will also add an explicit limitations paragraph discussing the synthetic nature of the chains and the degree to which generalization to naturalistic developer conversations can be claimed. revision: yes
-
Referee: [Results] Results (reported lifts for Verification Gate): The abstract and results state specific improvements (75.8% to 87.9% on DeepSeek-V3; 31.6% to 47.3% on Llama-3.1-8B) with no error bars, per-task variance, or statistical significance tests across the 542 tasks. This undermines the claim that Verification Gate 'consistently improves all models' because it is unclear whether the gains hold uniformly or are driven by subsets of the synthetic population.
Authors: We concur that the absence of error bars, variance measures, and significance testing weakens the consistency claim. The revised results section will report standard errors, per-task variance, and appropriate statistical tests (paired tests across the 542 tasks) for the Verification Gate improvements on each model. These additions will clarify the uniformity of the observed gains. revision: yes
-
Referee: [§5] §5 (Mitigation Strategies): The evaluation of strategies lacks a baseline comparison for Verification Gate (e.g., against simple re-prompting without test checking or other rollback variants). The claim that it is 'the only strategy that consistently improves all models' therefore rests on an incomplete set of comparators, making it difficult to assess whether the reported lift is distinctive or incremental.
Authors: The original §5 compared Verification Gate to several mitigation approaches, yet we acknowledge that explicit simple re-prompting baselines without test checking were not presented in sufficient detail. The revision will add these direct baseline comparisons together with additional rollback variants and will report the results showing that Verification Gate yields distinctive gains over the expanded set of comparators. revision: yes
Circularity Check
No circularity: purely empirical measurement with no derivations or fitted reductions
full rationale
The paper constructs 542 extended tasks from HumanEval+ and MBPP+, runs direct evaluations on 26,016 turn instances across six LLMs, measures regression rates (40-73%), and reports empirical gains from Verification Gate (e.g., 75.8% to 87.9% on DeepSeek-V3). No equations, parameters, predictions, or derivations appear that reduce reported percentages to quantities defined by the authors' own prior choices. Failure taxonomy is derived from independent annotation of observed cases. The study is self-contained against external benchmarks with no load-bearing self-citations or self-definitional steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 8-turn requirement-evolution chains constructed from HumanEval+ and MBPP+ tasks accurately model real multi-turn conversations and that benchmark tests cover the requirements introduced at each turn.
Reference graph
Works this paper leans on
-
[1]
Altaf Allah Abbassi, Leuson Da Silva, Amin Nikanjam, and Foutse Khomh. 2025. A Taxonomy of Inefficiencies in LLM-Generated Python Code. In2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 393–404
2025
-
[2]
Davide Arcelli, Vittorio Cortellessa, and Catia Trubiani. 2012. Antipattern-based model refactoring for software performance improvement. InProceedings of the 8th international ACM SIGSOFT conference on Quality of Software Architectures. 33–42
2012
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Peter Bambazek, Iris Groher, and Norbert Seyff. 2023. Requirements engineering for sustainable software systems: a systematic mapping study.Requirements Engineering28, 3 (2023), 481–505
2023
-
[5]
Belady and Meir M Lehman
Laszlo A. Belady and Meir M Lehman. 1976. A model of large program develop- ment.IBM Systems journal15, 3 (1976), 225–252
1976
-
[6]
Shawn A Bohner. 2002. Software change impacts-an evolving perspective. In International Conference on Software Maintenance, 2002. Proceedings.IEEE, 263– 272
2002
-
[7]
Ned Chapin, Joanne E Hale, Khaled Md Khan, Juan F Ramil, and Wui-Gee Tan
-
[8]
Types of software evolution and software maintenance.Journal of software maintenance and evolution: Research and Practice13, 1 (2001), 3–30
2001
-
[9]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Xinyun Chen, Maxwell Lin, Nathanael Schaerli, and Denny Zhou. 2024. Teaching Large Language Models to Self-Debug. InInternational Conference on Learning Representations, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (Eds.). 8746–8825
2024
-
[11]
William G Cochran. 1977. Sampling techniques.Johan Wiley & Sons Inc(1977)
1977
-
[12]
Daniela S Cruzes and Tore Dyba. 2011. Recommended steps for thematic synthesis in software engineering. In2011 international symposium on empirical software engineering and measurement. IEEE, 275–284
2011
- [13]
-
[14]
Beat Fluri, Michael Wursch, Martin PInzger, and Harald Gall. 2007. Change distilling: Tree differencing for fine-grained source code change extraction.IEEE Transactions on software engineering33, 11 (2007), 725–743
2007
-
[15]
Cuiyun Gao, Xing Hu, Shan Gao, Xin Xia, and Zhi Jin. 2025. The current chal- lenges of software engineering in the era of large language models.ACM Trans- actions on Software Engineering and Methodology34, 5 (2025), 1–30
2025
-
[16]
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Taco Cohen, and Gabriel Synnaeve. 2025. RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning. InICML
2025
-
[17]
Ángel González-Prieto, Jorge Perez, Jessica Diaz, and Daniel López-Fernández
-
[18]
Reliability in software engineering qualitative research through Inter-Coder Agreement.Journal of Systems and Software202 (2023), 111707
2023
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models
2024
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Huizi Hao, Kazi Amit Hasan, Hong Qin, Marcos Macedo, Yuan Tian, Steven HH Ding, and Ahmed E Hassan. 2024. An empirical study on developers’ shared conversations with ChatGPT in GitHub pull requests and issues.Empirical Software Engineering29, 6 (2024), 150
2024
-
[22]
Kim Herzig, Sascha Just, Andreas Rau, and Andreas Zeller. 2013. Predicting defects using change genealogies. In2013 IEEE 24th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 118–127
2013
-
[23]
Soodeh Hosseini and Mohammad Abdollahi Azgomi. 2008. UML model refactor- ing with emphasis on behavior preservation. In2008 2nd IFIP/IEEE International Symposium on Theoretical Aspects of Software Engineering. IEEE, 125–128
2008
-
[24]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[25]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Arnav Kumar Jain, Gonzalo Gonzalez-Pumariega, Wayne Chen, Alexander M Rush, Wenting Zhao, and Sanjiban Choudhury. 2025. Multi-Turn Code Genera- tion Through Single-Step Rewards. In42nd International Conference on Machine Learning
2025
-
[27]
Yiyang Jin, Kunzhao Xu, Hang Li, Xueting Han, Yanmin Zhou, Cheng Li, and Jing Bai. 2026. ReVeal: Self-Evolving Code Agents via Reliable Self-Verification. InThe 14th International Conference on Learning Representations
2026
-
[28]
Gregor Kiczales, John Lamping, Anurag Mendhekar, Chris Maeda, Cristina Lopes, Jean-Marc Loingtier, and John Irwin. 1997. Aspect-oriented programming. In European conference on object-oriented programming. Springer, 220–242
1997
-
[29]
Myeongsoo Kim, Shweta Garg, Baishakhi Ray, Varun Kumar, and Anoop Deoras
-
[30]
CodeAssistBench (CAB): Dataset & benchmarking for multi-turn chat-based code assistance.Advances in Neural Information Processing Systems38
-
[31]
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. 2025. Training Language Models to Self-Correct via Reinforcement Learning. InThe 13t...
2025
-
[32]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles. 611–626
2023
-
[33]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2025. Llms get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
-
[35]
1980.Software maintenance management
Bennett P Lientz and E Burton Swanson. 1980.Software maintenance management. Addison-Wesley Longman Publishing Co., Inc
1980
-
[36]
Burton Swanson, and Gail E Tompkins
Bennet P Lientz, E. Burton Swanson, and Gail E Tompkins. 1978. Characteristics of application software maintenance.Commun. ACM21, 6 (1978), 466–471. ASE ’26, October 2026, Munich, Germany Yonghui (Andie) Huang, Lin Ma, Amjed Tahir, Qian Zhang, Liwen Xiao, and Lysa Xiao
1978
-
[37]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in neural information processing systems 36, 21558–21572
2023
-
[39]
Robert Miller and Anand Tripathi. 1997. Issues with exception handling in object-oriented systems. InEuropean Conference on Object-Oriented Programming. Springer, 85–103
1997
-
[40]
Nachiappan Nagappan and Thomas Ball. 2005. Use of relative code churn mea- sures to predict system defect density. InProceedings of the 27th international conference on Software engineering. 284–292
2005
-
[41]
OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/. Official model announcement
2024
- [42]
-
[43]
Carolyn B. Seaman. 1999. Qualitative methods in empirical studies of software engineering.IEEE Transactions on software engineering25, 4 (1999), 557–572
1999
-
[44]
Yuling Shi, Songsong Wang, Chengcheng Wan, Min Wang, and Xiaodong Gu
-
[45]
From code to correctness: Closing the last mile of code generation with hierarchical debugging
-
[46]
Klaas-Jan Stol, Paul Ralph, and Brian Fitzgerald. 2016. Grounded theory in software engineering research: a critical review and guidelines. InProceedings of the 38th International conference on software engineering. 120–131
2016
- [47]
-
[48]
Sizhe Wang, Zhengren Wang, Dongsheng Ma, Yongan Yu, Rui Ling, Zhiyu Li, Feiyu Xiong, and Wentao Zhang. 2026. Codeflowbench: A multi-turn, iterative benchmark for complex code generation. (2026), 4369–4402
2026
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Stephen S Yau, James S Collofello, and T MacGregor. 1978. Ripple effect analysis of software maintenance. InThe IEEE Computer Society’s Second International Computer Software and Applications Conference, 1978. COMPSAC’78.IEEE, 60–65
1978
-
[51]
Shin Yoo and Mark Harman. 2012. Regression testing minimization, selection and prioritization: a survey.Software testing, verification and reliability22, 2 (2012), 67–120
2012
-
[52]
Pamela Zave. 1993. Feature interactions and formal specifications in telecommu- nications.Computer26, 8 (1993), 20–28
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.