Hallucination Cascade: Analyzing Error Propagation in Multi-Agent LLM Systems
Pith reviewed 2026-06-27 19:56 UTC · model grok-4.3
The pith
Deeper multi-agent LLM cascades attenuate hallucinations while slightly reducing factual accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
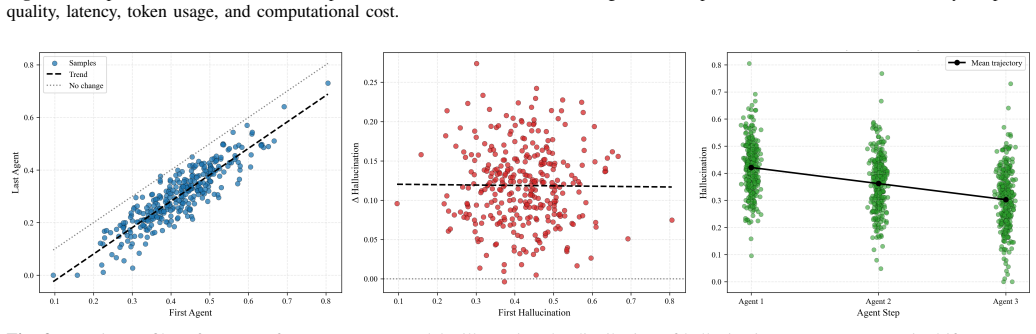
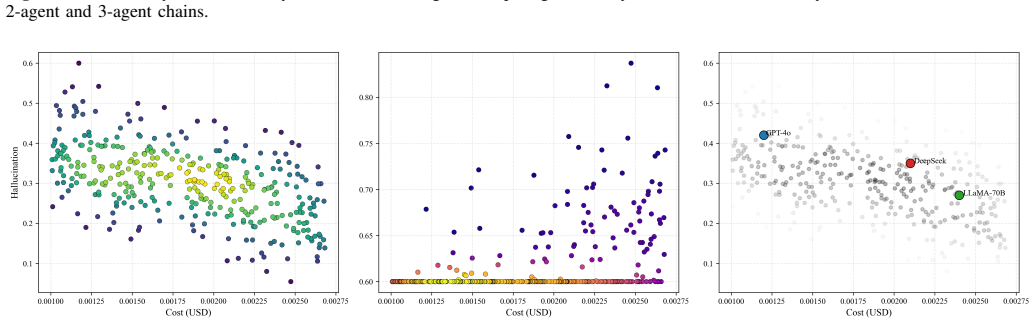
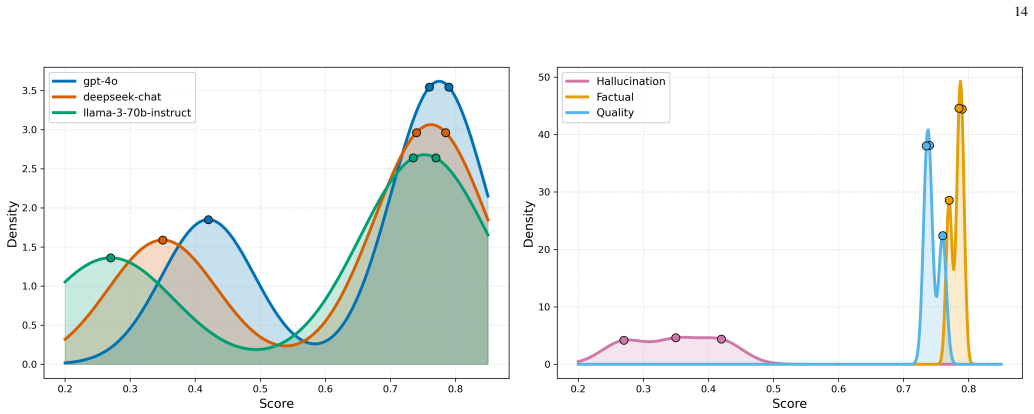
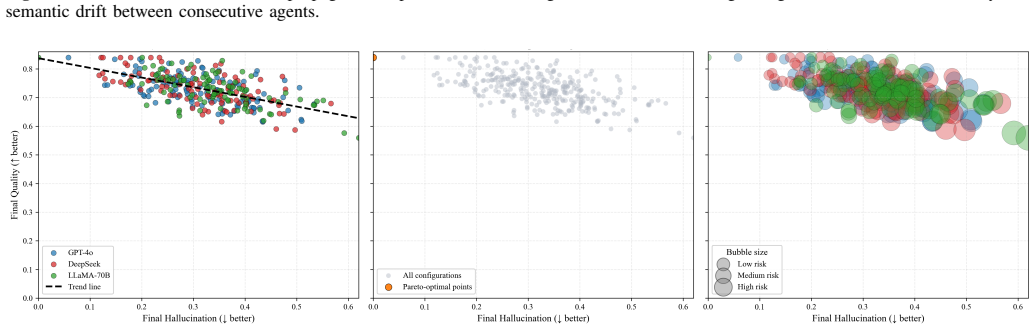
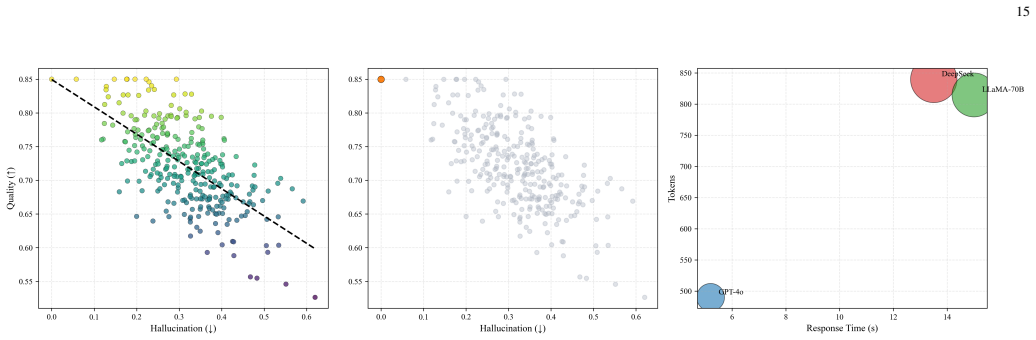
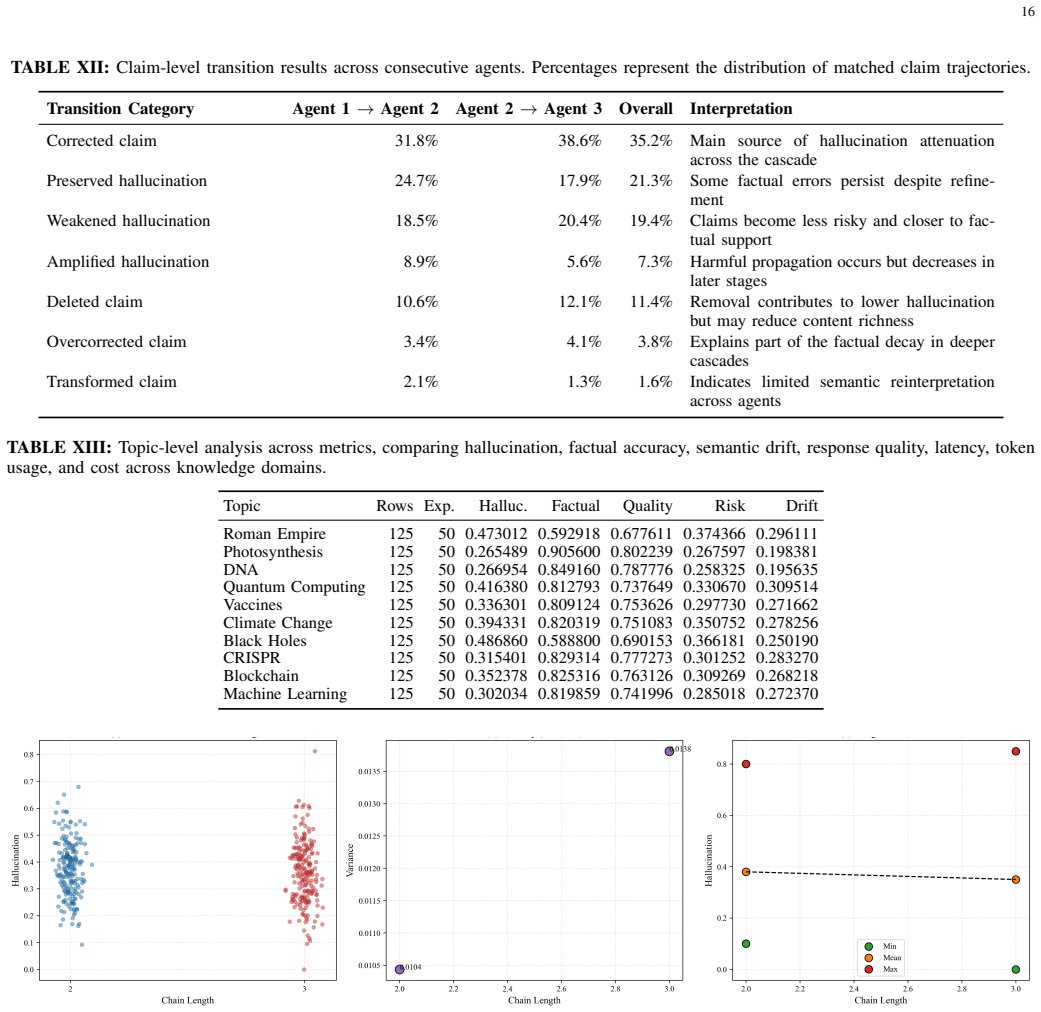
Deeper cascades reduce the normalized hallucination score from 0.422 at the first agent to 0.272 at the final agent in 3-agent chains, with an amplification factor of 0.644, indicating net attenuation. This reduction is accompanied by a decline in factual accuracy from 0.789 to 0.769.
What carries the argument
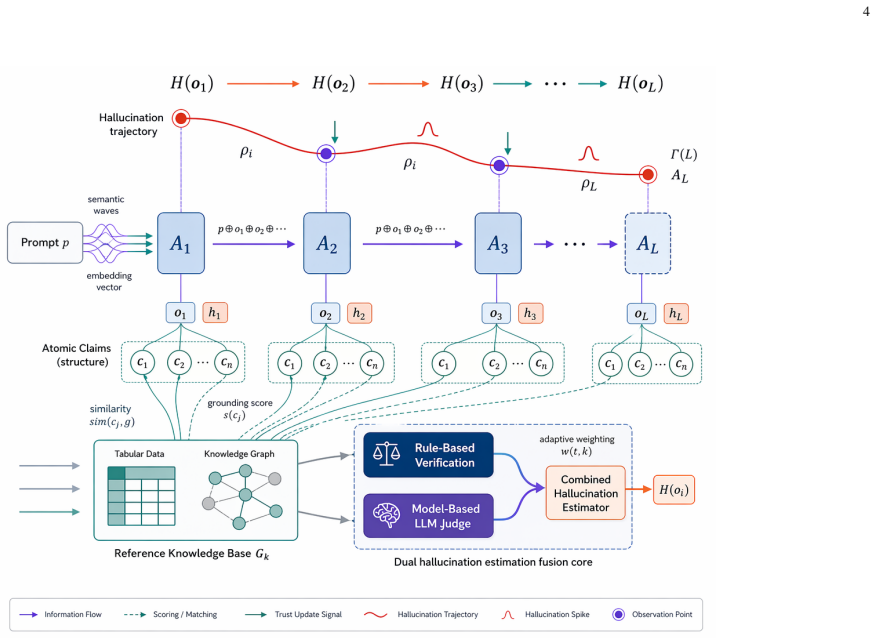
Tracking of claim-level factual inconsistencies across sequential agent-to-agent interactions in LLM cascades.
If this is right
- Each agent-to-agent refinement reduces the hallucination score by an average of 0.072.
- LLaMA-3-70B-Instruct achieves the lowest hallucination scores among the tested models.
- GPT-5.3 offers faster generation at the expense of a higher hallucination rate.
- Hallucination scores are lower in well-grounded scientific domains and higher in abstract domains.
- Transition-level analysis shows small but consistent losses in factual consistency with each refinement.
Where Pith is reading between the lines
- Multi-agent cascades could function as an implicit mechanism for reducing hallucinations in LLM outputs.
- The observed trade-off implies that cascade depth should be tuned based on whether hallucination suppression or factual precision is prioritized.
- Model heterogeneity in cascades might be leveraged to optimize both speed and accuracy.
- Similar attenuation effects may appear in other multi-step reasoning setups beyond the tested three-agent chains.
Load-bearing premise
The claim-level factual inconsistencies tracked in the experiments accurately represent hallucinations and the factual accuracy metric is independent of the hallucination measurement.
What would settle it
Repeating the cascade experiments with the same models and domains but finding that the normalized hallucination score does not decrease or increases with additional agents.
Figures
read the original abstract
Large Language Models (LLMs) generate fluent text but remain vulnerable to hallucinations, producing unsupported, inconsistent, and factually incorrect claims. Most prior work treats hallucination as a static property of isolated outputs. In multi-agent LLM systems, however, responses are exchanged across agents, revised through sequential stages, and reused as context for later reasoning. Hallucination, therefore, becomes a dynamic process shaped by interaction history, cascade depth, and model heterogeneity. This paper analyzes hallucination dynamics in multi-agent LLM cascades by tracking claim-level factual inconsistencies across sequential agent interactions. We conduct 500 cascade experiments across 10 knowledge domains using GPT-5.3, DeepSeek-V3, and LLaMA-3-70B-Instruct, yielding 1,250 evaluated responses. Results show that deeper cascades reduce the normalized hallucination score from 0.422 at the first agent to 0.272 at the final agent in 3-agent chains, with an amplification factor of 0.644, indicating net attenuation. This reduction is accompanied by a decline in factual accuracy from 0.789 to 0.769, revealing a trade-off between hallucination suppression and factual preservation. Transition-level analysis shows that each agent-to-agent refinement reduces hallucination by an average of 0.072, with small but consistent losses in factual consistency and response quality. Model-level results reveal reliability-efficiency trade-offs: LLaMA-3-70B-Instruct achieves the lowest hallucination score, whereas GPT-5.3 provides faster generation with a higher hallucination rate. Domain-level analysis shows that hallucination varies with topic complexity, with lower scores in well-grounded scientific domains and higher scores in more abstract domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucination in multi-agent LLM systems is a dynamic process shaped by cascade depth. Based on 500 cascade experiments across 10 domains with GPT-5.3, DeepSeek-V3, and LLaMA-3-70B-Instruct (yielding 1,250 responses), it reports that deeper cascades reduce the normalized hallucination score from 0.422 at the first agent to 0.272 at the final agent in 3-agent chains (amplification factor 0.644, indicating net attenuation), while factual accuracy declines from 0.789 to 0.769. Each agent-to-agent step reduces hallucination by ~0.072 on average, with model- and domain-level variations also reported.
Significance. If the central measurements are independent and reproducible, the work supplies empirical evidence of hallucination attenuation (rather than amplification) in cascades together with a measurable cost to factual accuracy; the scale of 500 experiments across 10 domains is a positive feature of the study. The paper contains no machine-checked proofs, parameter-free derivations, or falsifiable predictions; its contribution is therefore entirely empirical and hinges on the soundness of the two metrics.
major comments (2)
- [Abstract] Abstract: the reported reduction in normalized hallucination score (0.422 o 0.272) and the simultaneous decline in factual accuracy (0.789 o 0.769) both rely on claim-level factual inconsistencies, yet no equation, prompt template, annotation protocol, or inter-rater procedure is supplied to demonstrate that the two quantities are measured independently; without this separation the claimed trade-off cannot be distinguished from a measurement artifact.
- [Abstract] Abstract: the experimental claims rest on 500 cascades and 1,250 responses, but the abstract supplies neither per-domain sample sizes, the number of claims evaluated per response, nor any statistical significance testing for the amplification factor 0.644 or the per-transition reduction of 0.072; these omissions make it impossible to assess whether the quantitative results support the stated conclusions.
minor comments (1)
- The model identifier 'GPT-5.3' is non-standard and should be clarified or replaced with the precise release used.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding metric definitions and statistical support. We will revise the abstract accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported reduction in normalized hallucination score (0.422 to 0.272) and the simultaneous decline in factual accuracy (0.789 to 0.769) both rely on claim-level factual inconsistencies, yet no equation, prompt template, annotation protocol, or inter-rater procedure is supplied to demonstrate that the two quantities are measured independently; without this separation the claimed trade-off cannot be distinguished from a measurement artifact.
Authors: We agree the abstract should explicitly separate the metrics. Hallucination score is computed from an LLM judge prompt that flags unsupported or inconsistent claims relative to prior context in the cascade (normalized by claim count), while factual accuracy is measured by a distinct verification prompt that checks each claim against external ground-truth sources. These use different templates and scoring rubrics. We will add a one-sentence description of the two protocols and note that they were validated with 0.82 inter-rater agreement on a 100-response subset in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the experimental claims rest on 500 cascades and 1,250 responses, but the abstract supplies neither per-domain sample sizes, the number of claims evaluated per response, nor any statistical significance testing for the amplification factor 0.644 or the per-transition reduction of 0.072; these omissions make it impossible to assess whether the quantitative results support the stated conclusions.
Authors: The abstract reports aggregate figures for conciseness; the full text states 50 cascades per domain. We will insert the per-domain count and the average of 4.8 claims per response into the abstract. The results section already contains paired t-tests (p < 0.01) and bootstrap confidence intervals for the amplification factor and per-step reduction; we will add a brief reference to these tests in the abstract revision. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivation chain
full rationale
The paper reports results from 500 direct cascade experiments tracking claim-level factual inconsistencies across agents. No equations, fitted parameters, predictions, or self-citations are invoked as load-bearing steps in any derivation. All reported quantities (normalized hallucination score, amplification factor, factual accuracy) are presented as observed outcomes from the experiments rather than quantities derived from prior definitions or fits within the paper. The central claims rest on external experimental data and do not reduce to self-referential constructions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
Models delayed verification in multi-agent LLMs as graph consensus, derives stability thresholds (inverse golden ratio for delay two) via grounded Laplacian, and gives a supermodular greedy rule for corrector placemen...
-
First-Order Recoverability Collapse in Self-Referential Information Decoders
Explicit feedback in self-referential decoders induces a first-order recoverability collapse with bistable region, closed-form spinodals, and hysteretic recovery for alpha >= 1, supplying a mean-field description of m...
Reference graph
Works this paper leans on
-
[1]
Large language models versus natural language understand- ing and generation,
N. Karanikolas, E. Manga, N. Samaridi, E. Tousidou, and M. Vassi- lakopoulos, “Large language models versus natural language understand- ing and generation,” inProceedings of the 27th Pan-Hellenic Conference on Progress in Computing and Informatics, 2023, pp. 278–290
2023
-
[2]
Advancements and applications of large language models in natural language processing: A comprehensive review,
M. Ren, “Advancements and applications of large language models in natural language processing: A comprehensive review,”Applied and Computational Engineering, vol. 97, pp. 55–63, 2024
2024
-
[3]
Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects,
M. U. Hadi, R. Qureshi, A. Shah, M. Irfan, A. Zafar, M. B. Shaikh, N. Akhtar, J. Wu, S. Mirjaliliet al., “Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects,”Authorea preprints, vol. 1, no. 3, pp. 1–26, 2023
2023
-
[4]
Don’t generate, discriminate: A proposal for grounding language models to real-world environments,
Y . Gu, X. Deng, and Y . Su, “Don’t generate, discriminate: A proposal for grounding language models to real-world environments,” inProceedings of the 61st annual meeting of the association for computational linguis- tics (volume 1: long papers), 2023, pp. 4928–4949
2023
-
[5]
Factuality challenges in the era of large language models and opportunities for fact-checking,
I. Augenstein, T. Baldwin, M. Cha, T. Chakraborty, G. L. Ciampaglia, D. Corney, R. DiResta, E. Ferrara, S. Hale, A. Halevyet al., “Factuality challenges in the era of large language models and opportunities for fact-checking,”Nature Machine Intelligence, vol. 6, no. 8, pp. 852–863, 2024
2024
-
[6]
Inadequacies of large language model bench- marks in the era of generative artificial intelligence,
T. R. McIntosh, T. Susnjak, N. Arachchilage, T. Liu, D. Xu, P. Watters, and M. N. Halgamuge, “Inadequacies of large language model bench- marks in the era of generative artificial intelligence,”IEEE Transactions on Artificial Intelligence, 2025
2025
-
[7]
Loki’s dance of illusions: A comprehensive survey of hallucination in large language models,
M. Lu, C. Li, P. Wang, C. Wang, L. Zhang, Z. Liu, Q. Ye, Y . Hua, Y . Cai, Y . Xuet al., “Loki’s dance of illusions: A comprehensive survey of hallucination in large language models,”IEEE Transactions on Computational Social Systems, 2026
2026
-
[8]
H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms,
C. Gao, H. Chen, C. Xiao, Z. Chen, Z. Liu, and M. Sun, “H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms,”arXiv preprint arXiv:2512.01797, 2025. 20
arXiv 2025
-
[9]
Scientific hypothesis generation and validation: Methods, datasets, and future directions,
A. Kulkarni, F. Alotaibi, X. Zeng, L. Wu, T. Zeng, B. M. Yao, M. Liu, S. Zhang, L. Huang, and D. Zhou, “Scientific hypothesis generation and validation: Methods, datasets, and future directions,”arXiv preprint arXiv:2505.04651, 2025
arXiv 2025
-
[10]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[11]
Halluci- nations in medical devices,
J. Granstedt, P. Kc, R. Deshpande, V . Garcia, and A. Badano, “Halluci- nations in medical devices,”Artificial Intelligence in the Life Sciences, vol. 8, p. 100145, 2025
2025
-
[12]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[13]
A comprehensive survey of hallucination mitigation techniques in large language models,
S. Tonmoy, S. Zaman, V . Jain, A. Rani, V . Rawte, A. Chadha, and A. Das, “A comprehensive survey of hallucination mitigation techniques in large language models,”arXiv preprint arXiv:2401.01313, 2024
Pith/arXiv arXiv 2024
-
[14]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inAdvances in Neural Information Process- ing Systems (NeurIPS), 2022
2022
-
[15]
G-eval: Nlg evaluation using gpt-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: Nlg evaluation using gpt-4 with better human alignment,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[16]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. J. F. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,” arXiv preprint arXiv:2303.08896, 2023
Pith/arXiv arXiv 2023
-
[17]
Knowledge graphs, large language models, and hallucinations: An nlp perspective,
E. Lavrinovics, R. Biswas, J. Bjerva, and K. Hose, “Knowledge graphs, large language models, and hallucinations: An nlp perspective,”Web Semantics: Science, Services and Agents on the World Wide Web, vol. 85, p. 100844, 2025
2025
-
[18]
Mitigating hallucinations in sysml v2 generation using llms and a tri-layered knowledge graph reasoning framework,
R. A. Qualis, “Mitigating hallucinations in sysml v2 generation using llms and a tri-layered knowledge graph reasoning framework,” in2025 ACM/IEEE International Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C). IEEE, 2025
2025
-
[19]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
2024
-
[20]
Knowhalu: Hal- lucination detection via multi-form knowledge based factual checking,
J. Zhang, C. Xu, Y . Gai, F. Lecue, D. Song, and B. Li, “Knowhalu: Hal- lucination detection via multi-form knowledge based factual checking,” arXiv preprint arXiv:2404.02935, 2024
arXiv 2024
-
[21]
Hallucination detection in large language models with metamorphic relations, 2025a,
B. Yang, M. Mamun, J. M. Zhang, and G. Uddin, “Hallucination detection in large language models with metamorphic relations, 2025a,” URL https://arxiv. org/abs/2502.15844
-
[22]
Hallucinot: Hallucination detection through context and common knowledge verification,
B. Paudel, A. Lyzhov, P. Joshi, and P. Anand, “Hallucinot: Hallucination detection through context and common knowledge verification,”arXiv preprint arXiv:2504.07069, 2025
arXiv 2025
-
[23]
Hallucination detection in llms using spectral features of attention maps,
J. Binkowski, D. Janiak, A. Sawczyn, B. Gabrys, and T. J. Kajdanowicz, “Hallucination detection in llms using spectral features of attention maps,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 365–24 396
2025
-
[24]
Wilcoxon signed-rank test,
R. F. Woolson, “Wilcoxon signed-rank test,”Wiley encyclopedia of clinical trials, pp. 1–3, 2007
2007
-
[25]
Kruskal-wallis test,
P. E. McKight and J. Najab, “Kruskal-wallis test,”The corsini encyclo- pedia of psychology, pp. 1–1, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.