CAT-Q: Cost-efficient and Accurate Ternary Quantization for LLMs
Pith reviewed 2026-06-26 05:18 UTC · model grok-4.3
The pith
CAT-Q quantizes pre-trained LLMs to ternary using 512 calibration samples while outperforming BitNet models trained on 100 billion tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
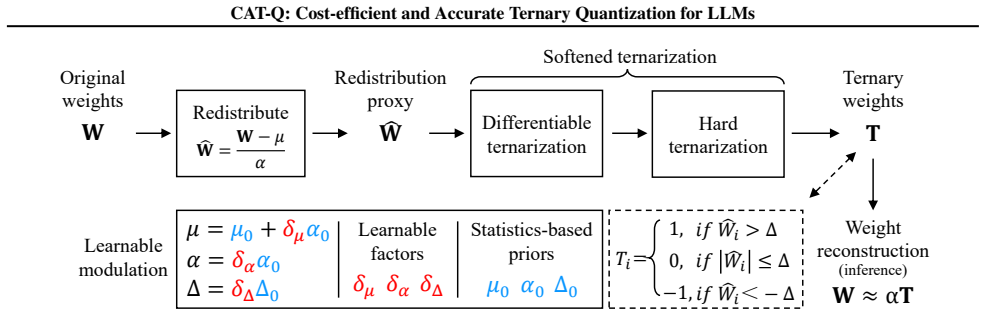
CAT-Q is a post-training ternary quantization scheme that couples learnable modulation factors, which modulate the distribution of pre-trained weights and the ternary threshold, with a differentiable softened transition function to guide stable convergence, enabling accurate ternary models for LLMs ranging from 1.7B to 235B parameters using only 512 calibration samples and achieving superior performance to BitNet 1.58-bit v1 and v2 models trained on 100B tokens.
What carries the argument
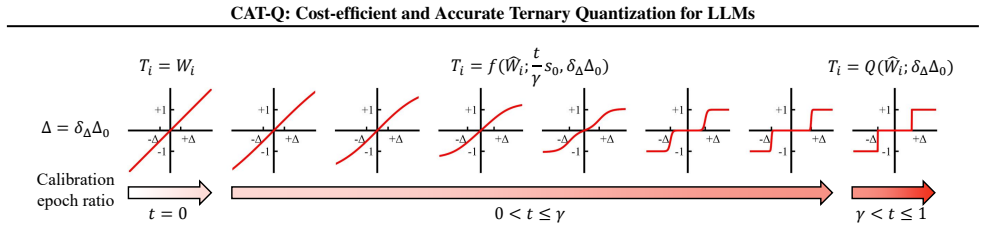
Learnable modulation (LM) and softened ternarization (ST) coupled from an optimization perspective, where LM uses learnable factors to modulate weight distributions and thresholds while ST supplies a differentiable transition function.
Load-bearing premise
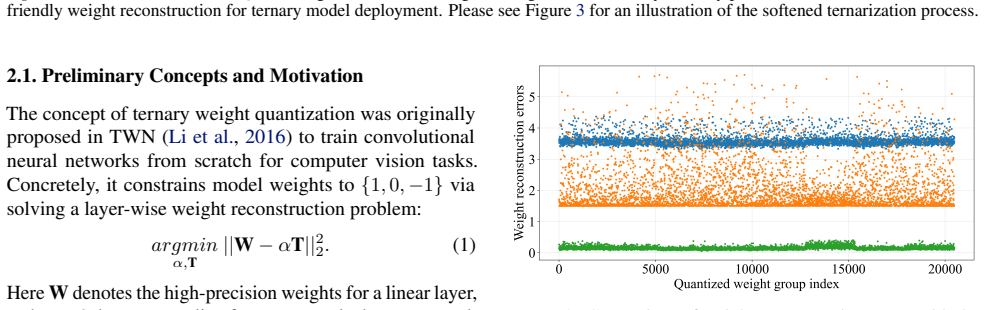
Optimizing the learnable modulation factors and softened transition function on 512 calibration samples produces a ternary model whose accuracy holds on the full evaluation distribution across different model sizes and architectures.
What would settle it
Run the CAT-Q ternary models on a large held-out evaluation set never seen during the 512-sample calibration and compare accuracy directly against the BitNet baselines under matched conditions.
Figures
read the original abstract
In this paper, we present CAT-Q, Cost-efficient and Accurate Ternary Quantization, for compressing and accelerating LLMs. Unlike existing state-of-the-art ternary quantization methods that rely on data-intensive and costly quantization-aware training to mitigate severe performance degradation, CAT-Q is a simple yet effective post-training quantization scheme that is readily applicable to LLMs with diverse architectures and model sizes. It has two key components, learnable modulation (LM) and softened ternarization (ST), which are coupled from an optimization perspective. LM leverages a composition of learnable factors to modulate the distribution of pre-trained high-precision weights and the ternary threshold, making them less sensitive to ternarization. ST further introduces a differentiable transition function to guide the ternarization process toward stable convergence. We show that, for pre-trained LLMs with 1.7B to 8B parameters, CAT-Q can efficiently quantize them into ternary models using only 512 calibration samples, while achieving superior performance than the seminal BitNet 1.58-bit v1 and v2 families (with 1.3B to 7B parameters) trained with 100B tokens, yielding about a 100,000X reduction in training tokens. Moreover, we show for the first time that CAT-Q can quantize much larger pre-trained LLMs having 14B to 235B parameters into leading ternary models within just 8 to 60 hours on 8 A100-80GB GPUs. Code is available at https://github.com/IntelChina-AI/BitTern.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAT-Q, a post-training ternary quantization method for pre-trained LLMs. It relies on two coupled components—learnable modulation (LM) of weight distributions and ternary thresholds via learnable factors, plus a softened differentiable transition function (ST)—optimized jointly on a 512-sample calibration set. The central claim is that this yields ternary models (1.7B–8B parameters) outperforming BitNet 1.58-bit v1/v2 models (1.3B–7B) trained from scratch on 100B tokens, for a claimed ~100,000X token reduction, while also scaling to 14B–235B models in 8–60 hours on 8 A100 GPUs.
Significance. If the empirical superiority and generalization claims are substantiated with full metrics and ablations, the result would be significant: it would demonstrate that post-training ternary quantization can match or exceed the accuracy of models trained from scratch with orders-of-magnitude less data, lowering the barrier to deploying efficient 1.58-bit LLMs across model scales.
major comments (3)
- [Abstract] Abstract and §4 (presumed evaluation): the headline claim of superior performance to BitNet v1/v2 with only 512 calibration samples is load-bearing yet unsupported by any reported quantitative metrics, error bars, dataset names, or per-task scores in the provided abstract; without these, the 100,000X token-reduction assertion cannot be assessed.
- [§3, §4] §3 (method) and §4: the optimization of the learnable modulation factors and softened-transition parameters on a fixed 512-sample set is presented without any ablation on calibration-set size, domain coverage, or held-out validation split; this directly undermines the weakest assumption that the resulting ternary weights generalize to the full evaluation distribution across model sizes.
- [§3] No equations or derivations are supplied that define how the LM factors rescale weights/thresholds or how the ST function is parameterized and differentiated; without these, it is impossible to verify that the reported gains are not simply the result of per-model fitting rather than a generalizable procedure.
minor comments (2)
- [Abstract] The abstract states results for 1.7B–8B and 14B–235B models but does not specify the exact model families or architectures used in the comparisons.
- [Abstract] Code link is provided, but no statement on whether the 512-sample calibration sets or optimization hyperparameters are released for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and §4 (presumed evaluation): the headline claim of superior performance to BitNet v1/v2 with only 512 calibration samples is load-bearing yet unsupported by any reported quantitative metrics, error bars, dataset names, or per-task scores in the provided abstract; without these, the 100,000X token-reduction assertion cannot be assessed.
Authors: We agree that the abstract should include concrete quantitative support. In the revised version, we will update the abstract to report key metrics such as average accuracy on benchmarks (e.g., MMLU, Hellaswag), specific per-task scores where space allows, dataset names, and variance indicators from our experiments. This will directly substantiate the performance superiority and token-reduction claims. revision: yes
-
Referee: [§3, §4] §3 (method) and §4: the optimization of the learnable modulation factors and softened-transition parameters on a fixed 512-sample set is presented without any ablation on calibration-set size, domain coverage, or held-out validation split; this directly undermines the weakest assumption that the resulting ternary weights generalize to the full evaluation distribution across model sizes.
Authors: We acknowledge the need for such ablations to demonstrate robustness. We will add an ablation study in §4 evaluating performance across calibration set sizes (128, 256, 512, 1024 samples) on representative models. We will also expand the discussion in §3 and §4 on how the 512-sample calibration set was selected for domain diversity and include any available held-out validation results or limitations. revision: yes
-
Referee: [§3] No equations or derivations are supplied that define how the LM factors rescale weights/thresholds or how the ST function is parameterized and differentiated; without these, it is impossible to verify that the reported gains are not simply the result of per-model fitting rather than a generalizable procedure.
Authors: We will revise §3 to include explicit mathematical definitions and derivations for the learnable modulation (LM) factors (showing how they rescale weight distributions and ternary thresholds) and the softened ternarization (ST) function (including its parameterization and gradient computation for differentiability). This will clarify the generalizable optimization procedure. revision: yes
Circularity Check
No circularity: empirical PTQ method with independent calibration-based optimization
full rationale
The paper describes a post-training quantization procedure (learnable modulation factors and softened transition function optimized on 512 calibration samples) whose performance claims rest on direct empirical comparison against BitNet models trained from scratch on 100B tokens. No equations, derivations, or self-citations are presented that reduce the reported accuracy to quantities defined by the fitted parameters themselves or that rename a known result as a new prediction. The central result is therefore an empirical observation rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable modulation factors
axioms (1)
- domain assumption Learnable modulation makes pre-trained weights less sensitive to ternarization when optimized on a small calibration set.
Reference graph
Works this paper leans on
-
[1]
L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
-
[2]
M., Hauth, A., Millican, K., et al
Anil, R., Borgeaud, S., Wu, Y ., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
-
[3]
Ternaryllm: Ternarized large language model.arXiv preprint arXiv:2406.07177, 2024b
Chen, T., Li, Z., Xu, W., Zhu, Z., Li, D., Tian, L., Barsoum, E., Wang, P., and Cheng, J. Ternaryllm: Ternarized large language model.arXiv preprint arXiv:2406.07177, 2024b. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv prepr...
-
[4]
Training verifiers to solve math word problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
-
[6]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[7]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[8]
Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[9]
P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
-
[10]
Openai o1 system card.arXiv preprint arXiv:2412.16720,
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
-
[11]
Ternary weight networks.arXiv preprint arXiv:1605.04711,
Li, F., Liu, B., Wang, X., Zhang, B., and Yan, J. Ternary weight networks.arXiv preprint arXiv:1605.04711,
-
[12]
Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437, 2024a
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Liu, J., Xia, C. S., Wang, Y ., and Zhang, L. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. InNeurIPS,
-
[13]
Qllm: Accurate and efficient low-bitwidth quantization for large language models
Liu, J., Gong, R., Wei, X., Dong, Z., Cai, J., and Zhuang, B. Qllm: Accurate and efficient low-bitwidth quantization for large language models. InICLR, 2024b. Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Kr- ishnamoorthi, R., Chandra, V ., Tian, Y ., and Blankevoort, T. Spinquant: Llm quantization with learned rotations. In ICLR, 2025a. Liu, ...
-
[14]
Xnor-net: Imagenet classification using binary convolu- tional neural networks
11 CAT-Q: Cost-efficient and Accurate Ternary Quantization for LLMs Rastegari, M., Ordonez, V ., Redmon, J., and Farhadi, A. Xnor-net: Imagenet classification using binary convolu- tional neural networks. InComputer Vision – ECCV 2016,
2016
-
[15]
Sanh, V ., Debut, L., Chaumond, J., and Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
Pith/arXiv arXiv 1910
-
[16]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
-
[17]
Team, L., Shen, A., Li, B., Hu, B., Jing, B., Chen, C., Huang, C., Zhang, C., Yang, C., Lin, C., et al. Every step evolves: Scaling reinforcement learning for trillion-scale thinking model.arXiv preprint arXiv:2510.18855,
-
[18]
Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
-
[19]
Bitnet v2: Native 4-bit activations with hadamard transformation for 1-bit llms
Wang, H., Ma, S., and Wei, F. Bitnet v2: Native 4-bit activations with hadamard transformation for 1-bit llms. arXiv preprint arXiv:2504.18415,
-
[20]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
-
[21]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[22]
is an augmented version of the Mostly Basic Programming Problems (MBPP) dataset, comprising approximately 378 crowd-sourced Python programming tasks. Each task includes a natural language description, a reference solution, and three test cases, aiming to evaluate models’ abilities in basic programming and problem-solving across diverse everyday coding sce...
2048
-
[23]
under different values of the sharpness parameter s, illustrating how the softened ternarization state evolves as s increases. Here, s controls the instantaneous sharpness of the transition function during training, while s0 denotes the final sharpness value reached at the end of the differentiable ternarization stage. As discussed in Section 3.4 with Tab...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.