Sparsity-Inducing Divergence Losses for Biometric Verification
Pith reviewed 2026-07-01 06:05 UTC · model grok-4.3
The pith
Placing the margin penalty inside the reference measure of alpha-divergence losses improves biometric verification at low false acceptance rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
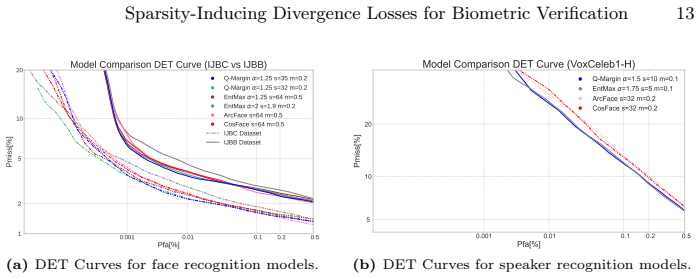
Q-Margin encodes the margin penalty directly into the reference measure of the alpha-divergence, thereby encouraging discriminative embeddings while preserving the sparsity properties of the divergence for alpha greater than one; under identical training recipes this yields competitive or better results than ArcFace and CosFace on the IJB-B and IJB-C benchmarks, with particular gains at low false acceptance rates, and comparable gains on VoxCeleb speaker verification, together with exact memory-efficient training enabled by the extreme sparsity of the resulting posteriors.
What carries the argument
Q-Margin, an alpha-divergence loss that encodes the margin penalty directly into the reference measure (prior probabilities) instead of the logits.
If this is right
- Q-Margin achieves competitive or superior performance on the IJB-B and IJB-C face verification benchmarks.
- Q-Margin improves results at low false acceptance rates relative to ArcFace and CosFace trained identically.
- The extreme sparsity of Q-Margin posteriors permits exact and memory-efficient training on datasets with millions of identities.
- Similar performance gains appear in speaker verification on VoxCeleb.
Where Pith is reading between the lines
- The same reference-measure construction could be tested on other divergence families to check whether the sparsity-plus-margin benefit generalizes.
- Because training becomes exact rather than approximate, the method may scale to identity counts far beyond current large-scale biometric sets without additional sampling tricks.
- The low-FAR emphasis suggests the loss could be combined with threshold-calibration techniques already used in deployed security systems.
Load-bearing premise
Encoding the margin penalty directly into the reference measure will preserve the sparsity properties of the alpha-divergence while producing more discriminative embeddings than standard geometric margins on logits.
What would settle it
A controlled experiment on IJB-C that trains ArcFace, CosFace, and Q-Margin under the identical recipe and finds no improvement or a degradation at low false acceptance rates for Q-Margin.
Figures

read the original abstract
Performance in face and speaker verification is largely driven by margin-penalty softmax losses such as CosFace and ArcFace. Recently introduced $\alpha$-divergence loss functions offer a compelling alternative, particularly due to their ability to induce sparse solutions (when $\alpha>1$). However, standard geometric margins are designed for the softmax function and do not naturally extend to this generalized probabilistic framework. In this paper we propose Q-Margin, a novel $\alpha$-divergence loss that introduces a principled probabilistic margin. Unlike conventional methods that apply geometric penalties to the logits (unnormalized log-likelihoods), Q-Margin encodes the margin penalty directly into the reference measure (prior probabilities). This formulation naturally encourages discriminative embeddings while preserving the beneficial sparsity properties of the $\alpha$-divergence. We demonstrate that Q-Margin achieves competitive or superior performance on the challenging IJB-B and IJB-C face verification benchmarks and similarly strong results in speaker verification on VoxCeleb. Crucially, against ArcFace and CosFace baselines trained under an identical recipe, Q-Margin consistently improves at low False Acceptance Rates (FARs), a capability critical for practical high-security applications. Finally, the extreme sparsity of the Q-Margin posteriors enables exact and memory-efficient training, offering a scalable solution for datasets with millions of identities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Q-Margin, a novel α-divergence loss for face and speaker verification. It encodes a probabilistic margin directly into the reference measure (prior probabilities) rather than applying geometric penalties to logits, claiming this yields more discriminative embeddings while preserving the sparsity-inducing properties of α-divergence losses (for α>1). Experiments on IJB-B, IJB-C, and VoxCeleb show competitive or superior verification performance versus ArcFace and CosFace baselines trained identically, with consistent gains at low FARs and extreme sparsity enabling memory-efficient training on large identity sets.
Significance. If the central construction is shown to preserve exact sparsity while improving tail behavior, the work would offer a principled route to margin penalties inside generalized divergence losses. This could matter for high-security biometric systems where low-FAR performance and scalable training on millions of identities are both required. The explicit contrast with identical-recipe ArcFace/CosFace baselines is a strength.
major comments (2)
- [Abstract] Abstract (and wherever the construction is defined): the assertion that encoding the margin into the reference measure 'naturally encourages discriminative embeddings while preserving the beneficial sparsity properties' is load-bearing for both the low-FAR claim and the memory-efficient training claim, yet the provided text supplies no derivation showing that the modified reference measure leaves the posterior support unchanged for α>1. Without this step, it is impossible to confirm that sparsity is retained exactly rather than approximately.
- [Abstract] The empirical claim of 'consistent improvements at low FARs' against identical-recipe baselines rests on the Q-Margin construction simultaneously achieving (a) retained sparsity and (b) better tail discrimination. If the reference-measure adjustment alters the mode or effective divergence, either property could be lost; a concrete check (e.g., support size of the posterior or an ablation isolating the margin term) is needed to secure this link.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for a formal derivation of sparsity preservation and additional empirical validation. We will revise the manuscript accordingly to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract (and wherever the construction is defined): the assertion that encoding the margin into the reference measure 'naturally encourages discriminative embeddings while preserving the beneficial sparsity properties' is load-bearing for both the low-FAR claim and the memory-efficient training claim, yet the provided text supplies no derivation showing that the modified reference measure leaves the posterior support unchanged for α>1. Without this step, it is impossible to confirm that sparsity is retained exactly rather than approximately.
Authors: We agree that an explicit derivation is required to rigorously establish that the modified reference measure leaves the posterior support unchanged for α>1. In the revised manuscript we will add a mathematical derivation in the section defining Q-Margin, proving that the support of the posterior remains identical to the standard α-divergence case and that sparsity is therefore retained exactly. revision: yes
-
Referee: [Abstract] The empirical claim of 'consistent improvements at low FARs' against identical-recipe baselines rests on the Q-Margin construction simultaneously achieving (a) retained sparsity and (b) better tail discrimination. If the reference-measure adjustment alters the mode or effective divergence, either property could be lost; a concrete check (e.g., support size of the posterior or an ablation isolating the margin term) is needed to secure this link.
Authors: We will add the requested concrete checks. The revised experiments section will include (i) measurements of posterior support size comparing Q-Margin to the baseline α-divergence loss across training runs and (ii) an ablation that isolates the margin-encoding term while holding all other factors fixed. These results will be reported on the same IJB-B/C and VoxCeleb protocols to directly link the construction to the observed low-FAR gains. revision: yes
Circularity Check
No circularity: novel construction with empirical support
full rationale
The paper proposes Q-Margin by directly modifying the reference measure of the α-divergence to incorporate a probabilistic margin, claiming this preserves sparsity for α>1 while improving discriminability. The abstract presents the construction as a new formulation and supports the central claim via direct comparisons to ArcFace/CosFace on IJB-B, IJB-C and VoxCeleb under identical training recipes. No equations, fitted parameters, or self-citations are shown that reduce the claimed performance gains or sparsity preservation to the inputs by construction. The derivation is therefore self-contained as an ansatz whose validity is tested externally rather than forced by prior definitions or self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
In: 2021 IEEE/CVF International Conference on Computer Vision Work- shops (ICCVW)
An, X., Zhu, X., Gao, Y., Xiao, Y., Zhao, Y., Feng, Z., Wu, L., Qin, B., Zhang, M., Zhang, D., Fu, Y.: Partial fc: Training 10 million identities on a single ma- chine. In: 2021 IEEE/CVF International Conference on Computer Vision Work- shops (ICCVW). pp. 1445–1449 (2021).https://doi.org/10.1109/ICCVW54120. 2021.00166
-
[3]
In: Chaudhuri, K., Sugiyama, M
Blondel,M.,Martins,A.,Niculae,V.:Learningclassifierswithfenchel-younglosses: Generalized entropies, margins, and algorithms. In: Chaudhuri, K., Sugiyama, M. (eds.) Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics. Proceedings of Machine Learning Research, vol. 89, pp. 606–615. PMLR (16–18 Apr 2019),https:...
2019
-
[4]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Boutros, F., Damer, N., Kirchbuchner, F., Kuijper, A.: Elasticface: Elastic margin loss for deep face recognition. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 1577–1586 (2021).https:// doi.org/10.1109/CVPRW56347.2022.00164
-
[5]
In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018)
Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A.: VGGFace2: A Dataset for Recognising Faces across Pose and Age . In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). pp. 67–74. IEEE Computer Society, Los Alamitos, CA, USA (May 2018).https://doi.org/ 10.1109/FG.2018.00020,https://doi.ieeecomputersociety.org...
-
[6]
In: 2020 25th International Conference on Pattern Recognition (ICPR)
Chan, C.H., Kittler, J.: Angular sparsemax for face recognition. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 10473–10479. IEEE (2021)
2020
-
[7]
In: Chinese conference on biometric recognition
Chen, S., Liu, Y., Gao, X., Han, Z.: Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In: Chinese conference on biometric recognition. pp. 428–438. Springer (2018)
2018
-
[8]
In: Proc
Chung, J.S., Nagrani, A., Zisserman, A.: VoxCeleb2: Deep speaker recognition. In: Proc. Interspeech. pp. 1086–1090 (2018)
2018
-
[9]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Dan, J., Liu, Y., Deng, J., Xie, H., Li, S., Sun, B., Luo, S.: Topofr: A closer look at topology alignment on face recognition. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Informa- tion Processing Systems. vol. 37, pp. 37213–37240. Curran Associates, Inc. (2024). https://doi.org/10.522...
-
[10]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4685–4694 (2019).https://doi.org/10.1109/ CVPR.2019.00482
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) Sparsity-Inducing Divergence Losses for Biometric Verification 17
2016
-
[12]
Huang, G.B., Mattar, M., Berg, T., Learned-Miller, E.: Labeled faces in the wild: A databaseforstudyingfacerecognitioninunconstrainedenvironments.In:Workshop on faces in’Real-Life’Images: detection, alignment, and recognition (2008)
2008
-
[13]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Huang, Y., Wang, Y., Tai, Y., Liu, X., Shen, P., Li, S., Li, J., Huang, F.: Curricular- face: adaptive curriculum learning loss for deep face recognition. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5901– 5910 (2020)
2020
-
[14]
Huh, J., Chung, J.S., Nagrani, A., Brown, A., Jung, J.w., Garcia-Romero, D., Zisserman, A.: The VoxCeleb speaker recognition challenge: A retrospective. IEEE/ACM Transactions on Audio, Speech, and Language Processing32, 3850– 3866 (2024).https://doi.org/10.1109/TASLP.2024.3444456
-
[15]
In: Conference on Computer Vision and Pattern Recognition (CVPR)
Kim,M.,Jain,A.K.,Liu,X.:Adaface:Qualityadaptivemarginforfacerecognition. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18729–18738 (2022).https://doi.org/10.1109/CVPR52688.2022. 01819
-
[16]
Kim, M., Liu, F., Jain, A.K., Liu, X.: Cluster and aggregate: Face recognition with large probe set. vol. 35, pp. 36054–36066 (2022)
2022
-
[17]
Advances in neural information processing systems29(2016)
Li, Y., Turner, R.E.: Rényi divergence variational inference. Advances in neural information processing systems29(2016)
2016
-
[18]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B., Song, L.: Sphereface: Deep hypersphere embedding for face recognition. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6738–6746 (2017).https://doi.org/10. 1109/CVPR.2017.713
2017
-
[19]
In: Proceedings of the 33rd International Conference on Inter- national Conference on Machine Learning - Volume 48
Liu, W., Wen, Y., Yu, Z., Yang, M.: Large-margin softmax loss for convolutional neural networks. In: Proceedings of the 33rd International Conference on Inter- national Conference on Machine Learning - Volume 48. p. 507–516. ICML’16, JMLR.org (2016)
2016
-
[20]
In: Balcan, M.F., Weinberger, K.Q
Martins, A., Astudillo, R.: From softmax to sparsemax: A sparse model of attention and multi-label classification. In: Balcan, M.F., Weinberger, K.Q. (eds.) Proceed- ings of The 33rd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 48, pp. 1614–1623. PMLR, New York, New York, USA (20–22 Jun 2016),https://proceed...
2016
-
[21]
In: 2018 international conference on biometrics (ICB)
Maze, B., Adams, J., Duncan, J.A., Kalka, N., Miller, T., Otto, C., Jain, A.K., Niggel, W.T., Anderson, J., Cheney, J., et al.: Iarpa janus benchmark-c: Face dataset and protocol. In: 2018 international conference on biometrics (ICB). pp. 158–165. IEEE (2018)
2018
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Meng, Q., Zhao, S., Huang, Z., Zhou, F.: Magface: A universal representation for face recognition and quality assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14225– 14234 (June 2021)
2021
-
[23]
In: proceedings of the IEEE conference on computer vision and pattern recognition workshops
Moschoglou, S., Papaioannou, A., Sagonas, C., Deng, J., Kotsia, I., Zafeiriou, S.: Agedb: the first manually collected, in-the-wild age database. In: proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 51–59 (2017)
2017
-
[24]
In: Proceedings of the 41st International Conference on Machine Learning
Novello, N., Tonello, A.M.: f-divergence based classification: beyond the use of cross-entropy. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[25]
Le, B., Woo, S.S.: Kappaface: Adaptive additive angular margin loss for deep face recognition
Oinar, C., M. Le, B., Woo, S.S.: Kappaface: Adaptive additive angular margin loss for deep face recognition. IEEE Access11, 137138–137150 (2023).https: //doi.org/10.1109/ACCESS.2023.3338648 18 D. Koutsianos et al
-
[26]
In: Korhonen, A., Traum, D., Màrquez, L
Peters, B., Niculae, V., Martins, A.F.T.: Sparse sequence-to-sequence models. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th An- nual Meeting of the Association for Computational Linguistics. pp. 1504–1519. Association for Computational Linguistics, Florence, Italy (Jul 2019).https: //doi.org/10.18653/v1/P19-1146,https://aclanthol...
-
[27]
In: Proceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: con- tributions to the theory of statistics
Rényi, A.: On measures of entropy and information. In: Proceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: con- tributions to the theory of statistics. vol. 4, pp. 547–562. University of California Press (1961)
1961
-
[28]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=V1YfPJDliw
Roulet, V., Liu, T., Vieillard, N., Sander, M.E., Blondel, M.: Loss functions and operators generated by f-divergences. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=V1YfPJDliw
2025
-
[29]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Saadabadi, M.S.E., Malakshan, S.R., Zafari, A., Mostofa, M., Nasrabadi, N.M.: A quality aware sample-to-sample comparison for face recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6129–6138 (2023)
2023
-
[30]
In: 2016 IEEE winter conference on applications of computer vision (WACV)
Sengupta, S., Chen, J.C., Castillo, C., Patel, V.M., Chellappa, R., Jacobs, D.W.: Frontal to profile face verification in the wild. In: 2016 IEEE winter conference on applications of computer vision (WACV). pp. 1–9. IEEE (2016)
2016
-
[31]
Thienpondt, J., Desplanques, B., Demuynck, K.: The IdLab VoxSRC-20 sub- mission: Large margin fine-tuning and quality-aware score calibration in DNN based speaker verification. In: ICASSP 2021 - 2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). pp. 5814–5818 (2021). https://doi.org/10.1109/ICASSP39728.2021.9414600
-
[32]
In: The Twelfth International Conference on Learning Representations (2024),https: //openreview.net/forum?id=2cRzmWXK9N
Wang, C., Jiang, Y., Yang, C., Liu, H., Chen, Y.: Beyond reverse KL: Gen- eralizing direct preference optimization with diverse divergence constraints. In: The Twelfth International Conference on Learning Representations (2024),https: //openreview.net/forum?id=2cRzmWXK9N
2024
-
[33]
In: 2018 IEEE/CVF Conference onComputerVisionandPatternRecognition.pp.5265–5274(2018).https://doi
Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z., Liu, W.: Cosface: Large margin cosine loss for deep face recognition. In: 2018 IEEE/CVF Conference onComputerVisionandPatternRecognition.pp.5265–5274(2018).https://doi. org/10.1109/CVPR.2018.00552
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Wang, K., Wang, S., Zhang, P., Zhou, Z., Zhu, Z., Wang, X., Peng, X., Sun, B., Li, H., You, Y.: An efficient training approach for very large scale face recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 4083–4092 (2022)
2022
-
[35]
Speech Communication162, 103104 (2024)
Wang, S., Chen, Z., Han, B., Wang, H., Liang, C., Zhang, B., Xiang, X., Ding, W., Rohdin, J., Silnova, A., et al.: Advancing speaker embedding learning: Wespeaker toolkit for research and production. Speech Communication162, 103104 (2024)
2024
-
[36]
In: proceedings of the IEEE conference on computer vision and pattern recognition workshops
Whitelam, C., Taborsky, E., Blanton, A., Maze, B., Adams, J., Miller, T., Kalka, N., Jain, A.K., Duncan, J.A., Allen, K., et al.: Iarpa janus benchmark-b face dataset. In: proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 90–98 (2017)
2017
-
[37]
In: 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP)
Wuerkaixi, A., Yan, K., Zhang, Y., Duan, Z., Zhang, C.: Dyvise: Dynamic vision- guided speaker embedding for audio-visual speaker diarization. In: 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP). pp. 1–6. IEEE (2022)
2022
-
[38]
Xiang, X., Wang, S., Huang, H., Qian, Y., Yu, K.: Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition. In: 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Sparsity-Inducing Divergence Losses for Biometric Verification 19 Conference (APSIPA ASC). pp. 1652–1656 (2019).https://d...
-
[39]
Beijing University of Posts and Telecommu- nications, Tech
Zheng, T., Deng, W.: Cross-pose lfw: A database for studying cross-pose face recog- nition in unconstrained environments. Beijing University of Posts and Telecommu- nications, Tech. Rep5(7), 5 (2018)
2018
-
[40]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
Zheng, T., Deng, W., Hu, J.: Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arXiv preprint arXiv:1708.08197 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Zhou, J., Jia, X., Li, Q., Shen, L., Duan, J.: Uniface: Unified cross-entropy loss for deep face recognition. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 20673–20682 (2023).https://doi.org/10.1109/ICCV51070. 2023.01895
-
[42]
Zhu, Z., Huang, G., Deng, J., Ye, Y., Huang, J., Chen, X., Zhu, J., Yang, T., Du, D., Lu, J., Zhou, J.: Webface260m: A benchmark for million-scale deep face recog- nition. IEEE Transactions on Pattern Analysis and Machine Intelligence45(2), 2627–2644 (2023).https://doi.org/10.1109/TPAMI.2022.3169734
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.