Synthetic Personalities: How Well Can LLMs Mimic Individual Respondents Using Socio-Economic Microdata?
Pith reviewed 2026-06-28 04:14 UTC · model grok-4.3
The pith
LLM-based individual twins from existing socio-economic panel data reach 78.8 percent accuracy on held-out questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
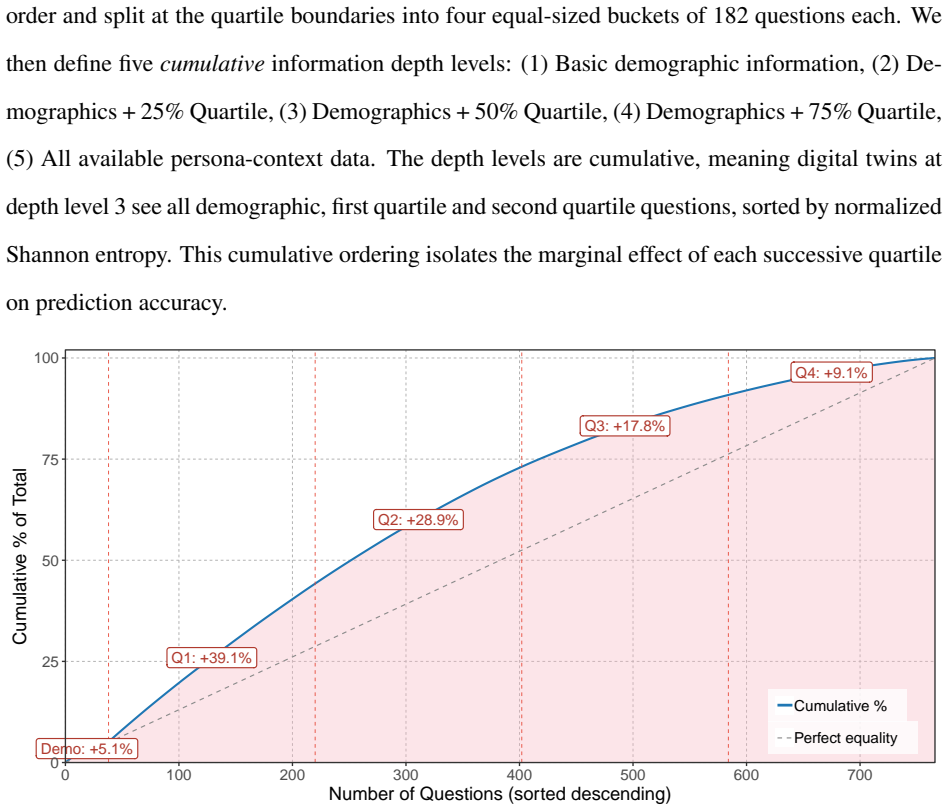
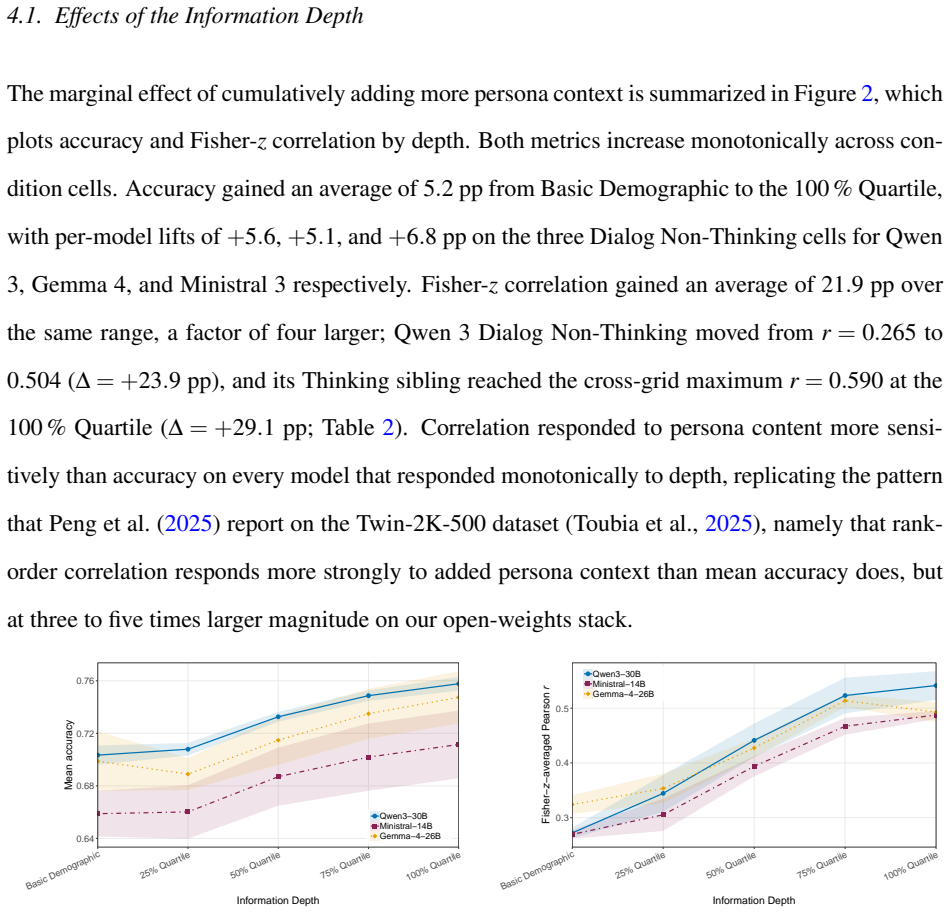
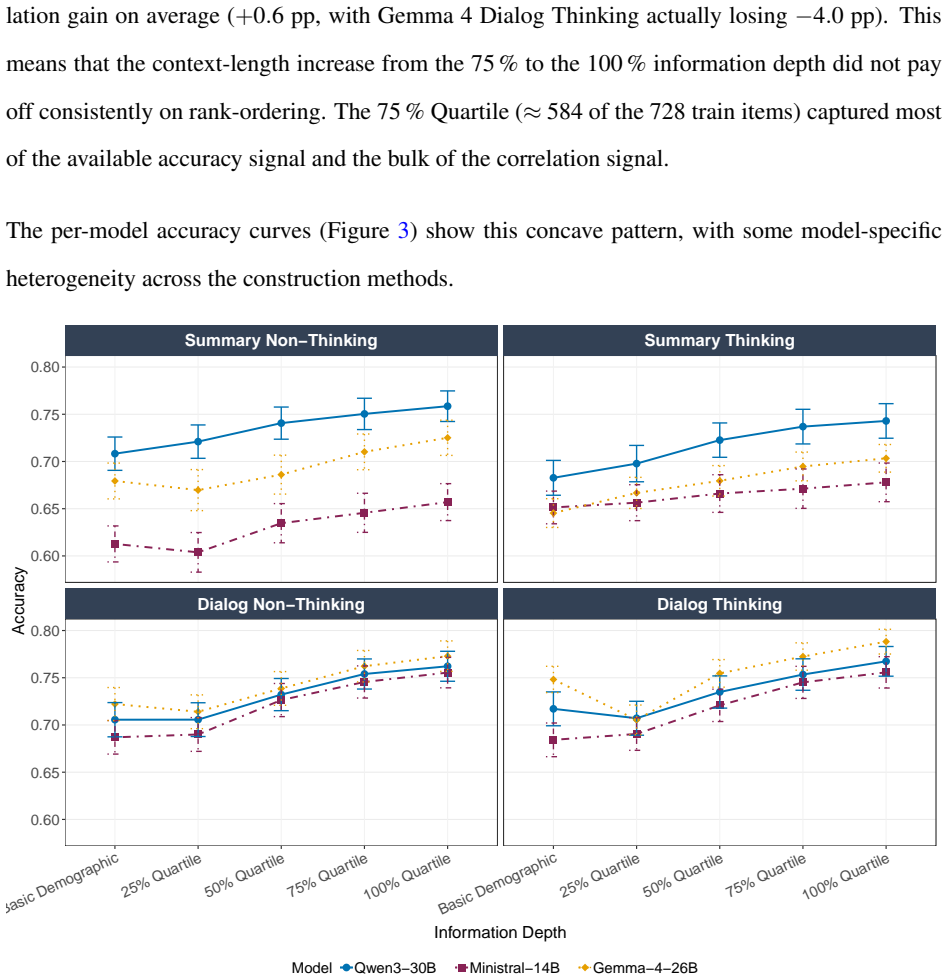
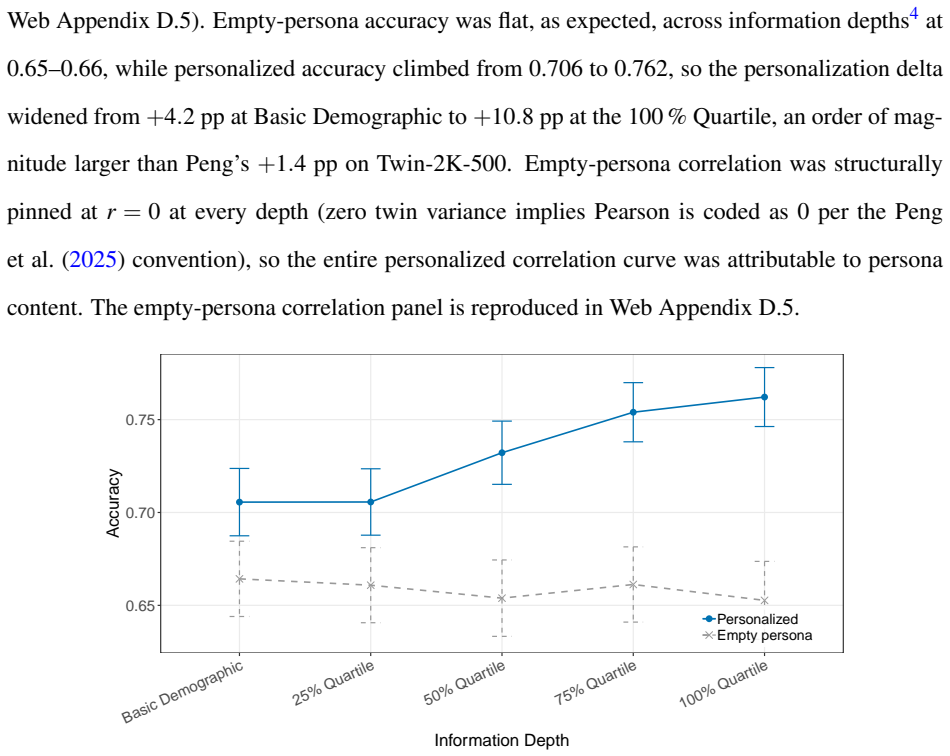
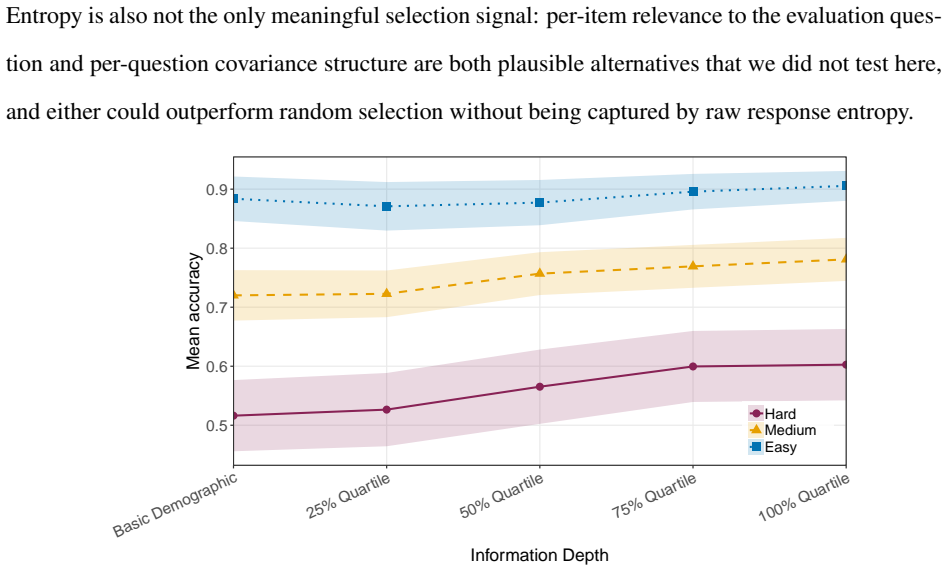
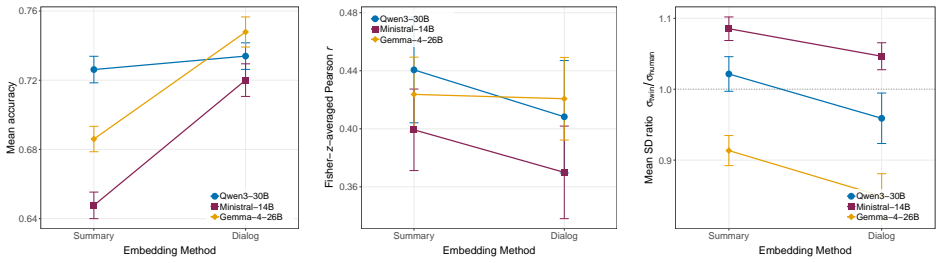
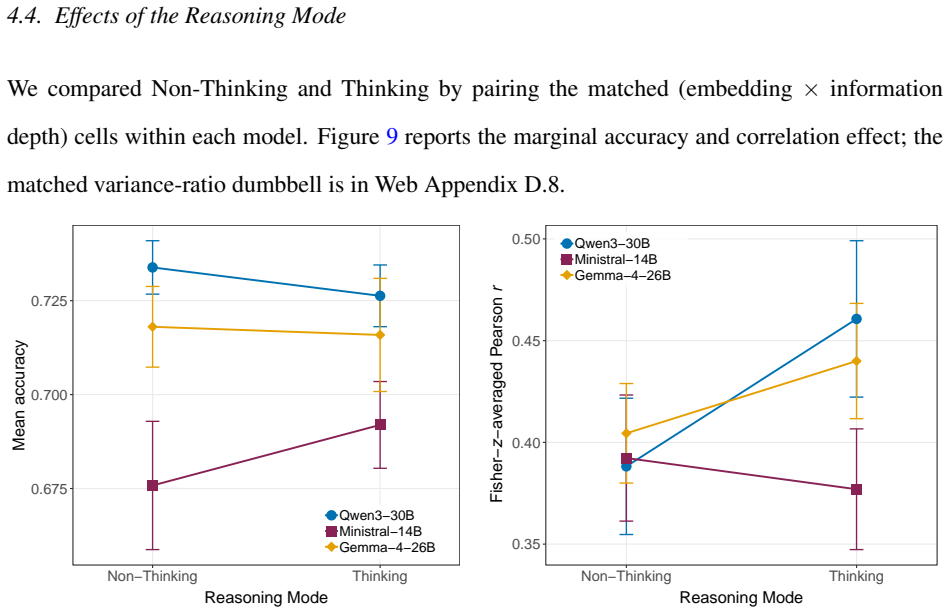
Detailed individual-level twins constructed from SOEP microdata achieve best-cell accuracy of 78.8 percent and Fisher-z correlation of r = 0.590 on a held-out set of 183 questions, with quality rising alongside information depth but exhibiting diminishing returns past the 75 percent entropy quartile that functions as a cost-efficient Pareto point relative to full-data cells; raw dialog-history embeddings outperform narrative summaries at full depth while explicit thinking improves rank-order correlation without raising accuracy.
What carries the argument
The 3 × 5 × 2 × 2 construction-method grid of three LLMs, five cumulative information depths ranked by normalized Shannon entropy, two embedding methods, and two reasoning modes.
If this is right
- Market researchers can construct detailed individual twins from existing panel, CRM, and loyalty data without designing new primary surveys.
- The 75 percent entropy quartile supplies a concrete stopping rule for data inclusion that preserves most performance at lower collection cost.
- Raw dialog-history embeddings raise hold-out accuracy across all tested models and reasoning modes at full information depth.
- Explicit chain-of-thought reasoning improves rank-order correlation between twin and human responses without increasing raw accuracy.
Where Pith is reading between the lines
- The same grid could be applied to commercial CRM datasets to test whether the entropy-quartile pattern and accuracy ceiling generalize beyond national panels.
- If the diminishing-returns curve holds, organizations could reduce new respondent recruitment by recycling historical response sequences for twin construction.
- The approach invites direct comparison of twin predictions against actual future behavior on the same individuals to measure predictive validity beyond cross-sectional hold-out accuracy.
Load-bearing premise
The 183 held-out questions are representative of the operational questions market researchers would actually pose to these individuals, and the SOEP microdata contain no systematic gaps or selection effects that would make the twins unrepresentative for new items.
What would settle it
Collect a fresh battery of 183 questions from the same 500 SOEP participants and test whether the reported accuracy and correlation levels hold for the best-performing twin configurations.
Figures
read the original abstract
LLM-based digital twins promise to scale and accelerate market research, but most published twins are either coarse persona bots conditioned on a few demographic questions or detailed individual-level twins built on purpose-collected surveys and interview transcripts. Neither setup speaks to the operationally most relevant case for marketing practice: building detailed individual twins from the pre-existing heterogeneous panel data that firms already accumulate through CRM systems, loyalty programs, and repeat surveys. We construct detailed individual-level twins from the German Socio-Economic Panel (SOEP) and evaluate them across a $3 \times 5 \times 2 \times 2$ construction-method grid that covers three open-weights LLMs, five cumulative information depths ranked by normalized Shannon entropy, two embedding methods, and two reasoning modes, scoring over 2.1 million twin responses on 500 participants and 183 held-out questions. Twin quality rises with information depth but with diminishing returns past the 75 percent entropy quartile, which acts as a cost-efficient Pareto point relative to the best-performing 100 percent cells. Switching the embedding from a narrative persona summary to a raw dialog history of past responses raises hold-out accuracy in every model-by-reasoning cell at the 100 percent depth, while an explicit thinking mode raises rank-order correlation without moving accuracy. Best-cell accuracy reaches 78.8 percent and Fisher-$z$ correlation reaches $r = 0.590$ on the SOEP held-out evaluation set. The findings suggest that twin-based market research is no longer gated by data design, but by item volume, model selection, and a small set of construction-level decisions that this paper now maps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
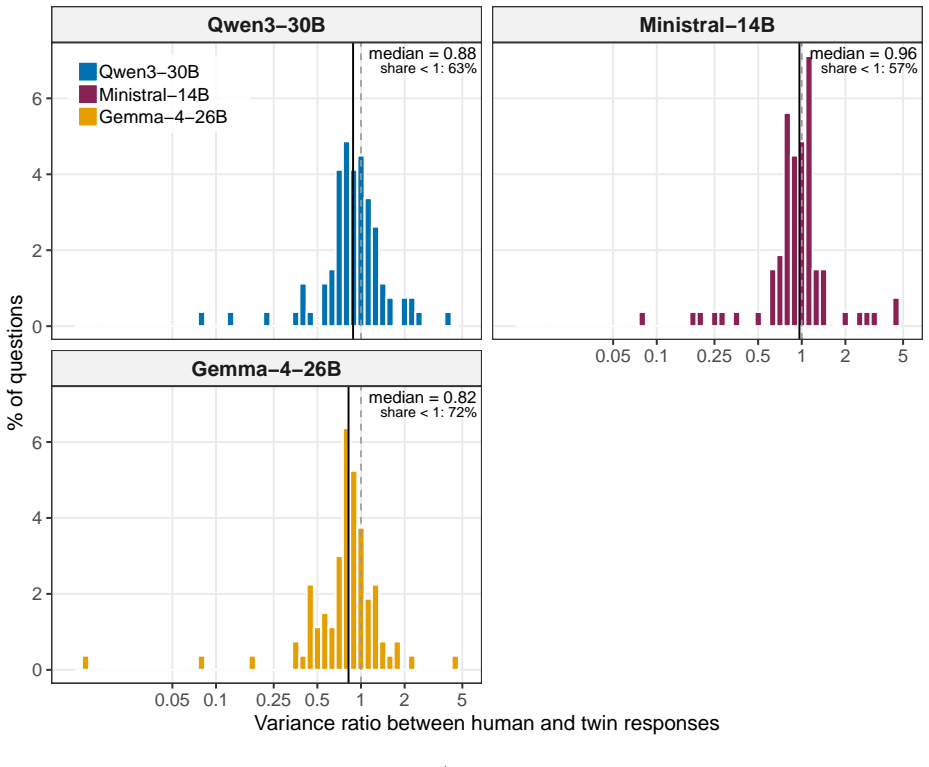
Summary. The paper constructs detailed LLM-based individual digital twins from German Socio-Economic Panel (SOEP) microdata for 500 participants. It evaluates them on 183 held-out SOEP questions across a 3×5×2×2 grid (three open-weight LLMs, five cumulative information depths by normalized Shannon entropy, two embedding methods, two reasoning modes), scoring over 2.1 million responses. Key findings are that quality rises with information depth but shows diminishing returns past the 75% entropy quartile (a proposed Pareto-efficient point), raw dialog-history embeddings outperform narrative summaries, explicit thinking improves rank-order correlation but not accuracy, and best-cell performance reaches 78.8% accuracy and Fisher-z r=0.590.
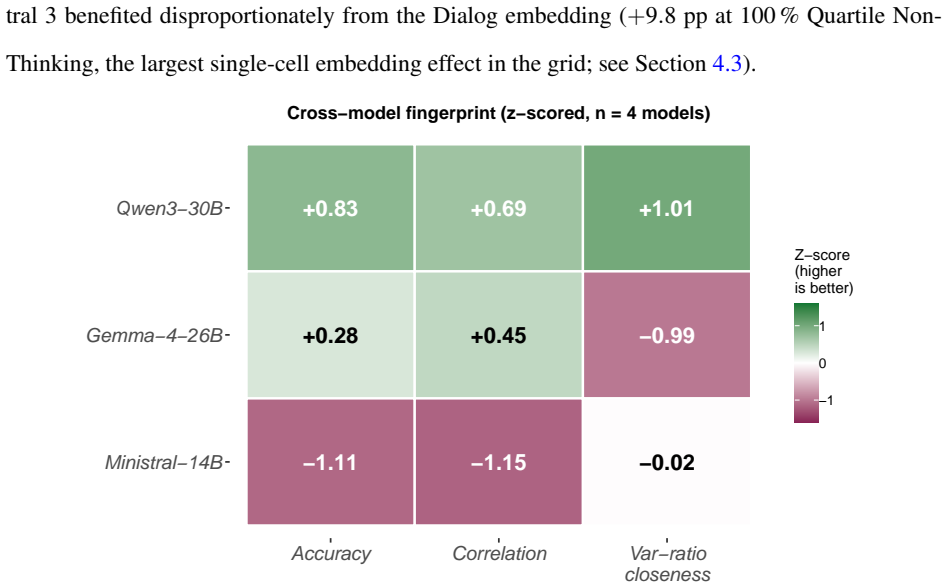
Significance. If the results hold, the systematic grid and large response volume provide a useful empirical map of construction choices for individual-level twins from pre-existing heterogeneous panel data, identifying an efficient information-depth threshold and embedding effects. This is a concrete contribution to the digital-twin literature. The evaluation remains internal to the SOEP instrument, however, so the abstract's claim that twin-based market research is now gated only by item volume, model choice, and construction decisions rests on an untested transfer assumption.
major comments (1)
- Abstract: the concluding suggestion that twin-based market research is no longer gated by data design but by item volume, model selection, and construction decisions rests on accuracy and correlation measured exclusively on 183 held-out SOEP questions that share the same survey instrument, response scales, topic distribution, and selection process as the conditioning data. No experiment tests whether the same construction grid retains 78.8% accuracy or r=0.590 when target items are drawn from typical operational market-research instruments (brand preference, willingness-to-pay, ad recall). This directly affects transfer of the Pareto claim at the 75% entropy quartile.
minor comments (2)
- Abstract and methods: the reported metrics from 2.1 million responses lack error bars, exact prompting templates, participant selection details, and statistical tests on the diminishing-returns and Pareto claims.
- Notation: the abstract refers to 'Fisher-z correlation' without specifying the exact transformation or baseline used for the r=0.590 value.
Simulated Author's Rebuttal
We thank the referee for the detailed report and for identifying the scope limitation in our evaluation. We respond to the single major comment below and agree that a revision to the abstract is warranted.
read point-by-point responses
-
Referee: [—] Abstract: the concluding suggestion that twin-based market research is no longer gated by data design but by item volume, model selection, and construction decisions rests on accuracy and correlation measured exclusively on 183 held-out SOEP questions that share the same survey instrument, response scales, topic distribution, and selection process as the conditioning data. No experiment tests whether the same construction grid retains 78.8% accuracy or r=0.590 when target items are drawn from typical operational market-research instruments (brand preference, willingness-to-pay, ad recall). This directly affects transfer of the Pareto claim at the 75% entropy quartile.
Authors: We agree that the evaluation uses only held-out SOEP items and that no transfer experiments were performed on instruments containing brand preference, willingness-to-pay, or ad-recall questions. The abstract's suggestion therefore rests on the untested premise that performance patterns observed within the SOEP instrument will generalize to other survey-based market-research tasks. While SOEP covers a broad range of socio-economic topics that overlap with many market-research domains, this does not constitute direct evidence of transfer. We will revise the abstract to qualify the claim, making clear that the identified construction decisions and Pareto threshold apply to prediction within similar panel-survey instruments and that external validation on operational market-research items remains an open question for future work. revision: yes
Circularity Check
No significant circularity; evaluation uses external held-out benchmark
full rationale
The paper constructs LLM-based twins from SOEP microdata and measures performance via accuracy and Fisher-z correlation on 183 held-out questions from the same panel. These held-out responses constitute an external benchmark independent of any fitted parameters or construction choices inside the paper. No equations, self-citations, or ansatzes are shown to reduce the reported 78.8% accuracy or r=0.590 to quantities defined by the inputs themselves. The 3×5×2×2 grid varies construction methods but evaluates them against real respondent answers not used for conditioning, keeping the central claims falsifiable and non-circular by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Liebig, Stefan and Kroh, Martin and Richter, David and Schr
Goebel, Jan and Grabka, Markus M. and Liebig, Stefan and Kroh, Martin and Richter, David and Schr. The. Jahrb. 2019 , volume =
2019
-
[2]
2025 , doi =
Socio-Economic Panel (. 2025 , doi =
2025
-
[3]
European Sociological Review , volume=
Exploring integration and migration dynamics: the research potentials of a large-scale longitudinal household study of refugees in Germany , author=. European Sociological Review , volume=. 2026 , publisher=
2026
-
[4]
Schupp, J. and Gerlitz, J.-Y. Big Five Inventory-SOEP (BFI-S). 2008. doi:10.6102/zis54
-
[5]
, title =
Shannon, Claude E. , title =. The Bell System Technical Journal , year =
-
[6]
and Thomas, Joy A
Cover, Thomas M. and Thomas, Joy A. , title =. 2006 , isbn =
2006
-
[7]
Marketing Science , volume=
Database report: Twin-2k-500: A data set for building digital twins of over 2,000 people based on their answers to over 500 questions , author=. Marketing Science , volume=. 2025 , publisher=
2025
-
[8]
Qwen3 Technical Report , year =. 2505.09388 , archiveprefix =
-
[9]
2023 , eprint=
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting , author=. 2023 , eprint=
2023
-
[10]
International Journal of Research in Marketing , year =
Peres, Renana and Schreier, Martin and Schweidel, David and Sorescu, Alina , title =. International Journal of Research in Marketing , year =
-
[11]
Journal of Marketing , year =
Arora, Neeraj and Chakraborty, Ishita and Nishimura, Yohei , title =. Journal of Marketing , year =
-
[12]
and Zhang, Heng , title =
Wang, Mengxin and Zhang, Dennis J. and Zhang, Heng , title =. Marketing Science , year =
-
[13]
Harvard Business School Marketing Unit Working Paper , number =
Brand, James and Israeli, Ayelet and Ngwe, Donald , title =. Harvard Business School Marketing Unit Working Paper , number =. 2023 , doi =
2023
-
[14]
Marketing Science , volume=
Frontiers: Can large language models capture human preferences? , author=. Marketing Science , volume=. 2024 , publisher=
2024
-
[15]
Marketing Science , year =
Li, Peiyao and Castelo, Noah and Katona, Zsolt and Sarvary, Miklos , title =. Marketing Science , year =
-
[16]
and Rau, Lea and Schmitt, Bernd , title =
Sarstedt, Marko and Adler, Susanne J. and Rau, Lea and Schmitt, Bernd , title =. Psychology & Marketing , year =
-
[17]
PLOS ONE , year =
Brucks, Melanie and Toubia, Olivier , title =. PLOS ONE , year =
-
[18]
, title =
Chakraborty, Ishita and Chiong, Khai and Dover, Howard and Sudhir, K. , title =. Marketing Science , year =
-
[19]
and Busby, Ethan C
Argyle, Lisa P. and Busby, Ethan C. and Fulda, Nancy and Gubler, Joshua R. and Rytting, Christopher and Wingate, David , title =. Political Analysis , year =
-
[20]
Proceedings of the International Conference on Machine Learning , pages =
Santurkar, Shibani and Durmus, Esin and Ladhak, Faisal and Lee, Cinoo and Liang, Percy and Hashimoto, Tatsunori , title =. Proceedings of the International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[21]
and Arriaga, Rosa I
Aher, Gati V. and Arriaga, Rosa I. and Kalai, Adam Tauman , title =. Proceedings of the International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[22]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Suh, Joseph and Jahanparast, Erfan and Moon, Suhong and Kang, Minwoo and Chang, Serina , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , doi =
2025
-
[23]
Preprint , year=
Predicting results of social science experiments using large language models , author=. Preprint , year=
-
[24]
Machine Bias: How Do Generative Language Models Answer Opinion Polls? , journal =
Boelaert, Julien and Coavoux, Samuel and Ollion,. Machine Bias: How Do Generative Language Models Answer Opinion Polls? , journal =. 2025 , volume =
2025
-
[25]
and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S
Park, Joon Sung and Popowski, Lindsay and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology , pages =. 2022 , doi =
2022
-
[26]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
-
[27]
2026 , eprint=
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals , author=. 2026 , eprint=
2026
-
[28]
Finetuning LLM s for Human Behavior Prediction in Social Science Experiments
Kolluri, Akaash and Wu, Shengguang and Park, Joon Sung and Bernstein, Michael S. Finetuning LLM s for Human Behavior Prediction in Social Science Experiments. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1530
-
[29]
Shaikh, Omar and Sapkota, Shardul and Rizvi, Shan and Horvitz, Eric and Park, Joon Sung and Yang, Diyi and Bernstein, Michael S. , title =. Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2025 , isbn =. doi:10.1145/3746059.3747722 , abstract =
-
[30]
URL https: //aclanthology.org/2025.acl-long.104/
Orlikowski, Matthias and Pei, Jiaxin and R. Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.104
-
[31]
and Liu, Ryan and Richardson, Sean M
Anthis, Jacy R. and Liu, Ryan and Richardson, Sean M. and Kozlowski, Austin C. and Koch, Bernard and Brynjolfsson, Erik and Evans, James and Bernstein, Michael S. , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[32]
and Evans, James , title =
Kozlowski, Austin C. and Evans, James , title =. Sociological Methods & Research , year =
-
[33]
2025 , eprint=
Digital Twins as Funhouse Mirrors: Five Key Distortions , author=. 2025 , eprint=
2025
-
[34]
and Busby, Ethan C
Lyman, Alex and Hepner, Bryce and Argyle, Lisa P. and Busby, Ethan C. and Gubler, Joshua R. and Wingate, David , title =. Sociological Methods and Research , year =
-
[35]
LLM Generated Persona is a Promise with a Catch , url =
Li, Leon and Chen, Haozhe and Namkoong, Hongseok and Peng, Tianyi , booktitle =. LLM Generated Persona is a Promise with a Catch , url =
-
[36]
and Schoenegger, Philipp and Zhu, Chongyang , title =
Park, Peter S. and Schoenegger, Philipp and Zhu, Chongyang , title =. Behavior Research Methods , year =
-
[37]
and Dorff, Cassy and Kenkel, Brenton and Larson, Jennifer M
Bisbee, James and Clinton, Joshua D. and Dorff, Cassy and Kenkel, Brenton and Larson, Jennifer M. , title =. Political Analysis , year =
-
[38]
Questioning the Survey Responses of Large Language Models , url =
Dominguez-Olmedo, Ricardo and Hardt, Moritz and Mendler-D\". Questioning the Survey Responses of Large Language Models , url =. Advances in Neural Information Processing Systems , doi =
-
[39]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Wang, Xinpeng and Ma, Bolei and Hu, Chengzhi and Weber-Genzel, Leon and R. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , doi =
2024
-
[40]
and Subrahmanya, Shashanka and Sedoc, Jo
Salecha, Aadesh and Ireland, Molly E. and Subrahmanya, Shashanka and Sedoc, Jo. Large Language Models Display Human-Like Social Desirability Biases in. PNAS Nexus , year =
-
[41]
Public Choice , year =
Motoki, Fabio and Pinho Neto, Valdemar and Rodrigues, Victor , title =. Public Choice , year =
-
[42]
PLOS ONE , year =
Rozado, David , title =. PLOS ONE , year =
-
[43]
International Conference on Learning Representations , year=
Bias runs deep: Implicit reasoning biases in persona-assigned llms , author=. International Conference on Learning Representations , year=
-
[44]
2024 , eprint=
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis , author=. 2024 , eprint=
2024
-
[45]
and Wagner, Claudia and Rammstedt, Beatrice and Strohmaier, Markus , title =
Pellert, Max and Lechner, Clemens M. and Wagner, Claudia and Rammstedt, Beatrice and Strohmaier, Markus , title =. Perspectives on Psychological Science , year =
-
[46]
, title =
Westwood, Sean J. , title =. Proceedings of the National Academy of Sciences , year =
-
[47]
Proceedings of the National Academy of Sciences , year =
Gao, Yuan and Lee, Dokyun and Burtch, Gordon and Fazelpour, Sina , title =. Proceedings of the National Academy of Sciences , year =
-
[48]
Nature Computational Science , year =
Cui, Ziyan and Li, Ning and Zhou, Huaikang , title =. Nature Computational Science , year =
-
[49]
, title =
Mei, Qiaozhu and Xie, Yutong and Yuan, Walter and Jackson, Matthew O. , title =. Proceedings of the National Academy of Sciences , year =
-
[50]
and He, Lan and Xu, Xiao , title =
Wang, Yifan and Zhao, Jingjing and Ones, Deniz S. and He, Lan and Xu, Xiao , title =. Scientific Reports , year =
-
[51]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[52]
arXiv preprint arXiv:2408.03314 , year=
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[53]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[54]
arXiv preprint arXiv:2601.08584 , year=
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
-
[55]
Gemma-4-26B-A4B Model Card , year =
-
[56]
International Conference on Learning Representations , volume=
Livebench: A challenging, contamination-limited llm benchmark , author=. International Conference on Learning Representations , volume=
-
[57]
Nature , volume=
A foundation model to predict and capture human cognition , author=. Nature , volume=. 2025 , publisher=
2025
-
[58]
2026 , eprint=
Post-training makes large language models less human-like , author=. 2026 , eprint=
2026
-
[59]
Available at SSRN 4802019 , year=
Reducing Disparity Between LLMs and Humans: Optimal LLM Sample Calibration , author=. Available at SSRN 4802019 , year=
-
[60]
Journal of the Academy of Marketing Science , volume=
A whole new world, a new fantastic point of view: Charting unexplored territories in consumer research with generative artificial intelligence , author=. Journal of the Academy of Marketing Science , volume=. 2025 , publisher=
2025
-
[61]
Available at SSRN , year=
Blind Spots in Broad Strokes: Caveats for the Use of LLMs in Marketing Research , author=. Available at SSRN , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.