Plan-and-Verify Video Reward Reasoning with Spatio-Temporal Scene Graph Grounding
Pith reviewed 2026-06-27 10:35 UTC · model grok-4.3
The pith
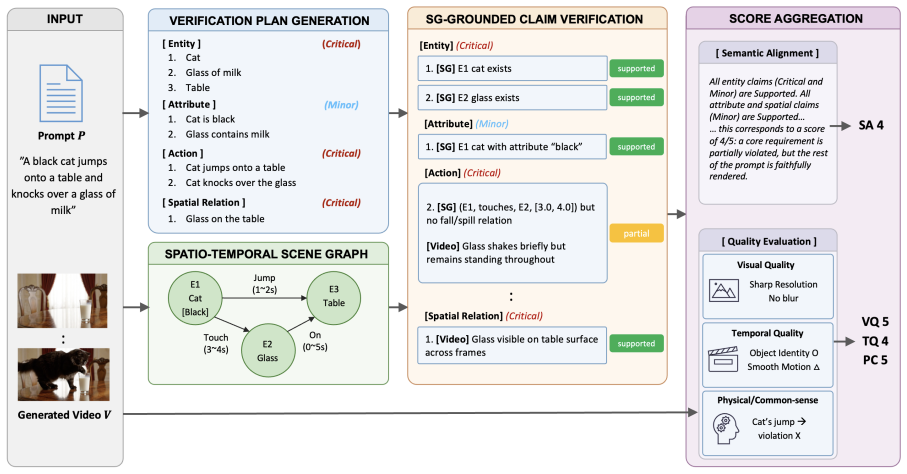
SG-PVR decomposes text prompts into atomic claims and verifies each against an explicit spatio-temporal scene graph extracted from the video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that plan-and-verify reasoning grounded in spatio-temporal scene graphs allows systematic verification of every prompt condition with explicit visual evidence, leading to improved semantic alignment in video reward models.
What carries the argument
Spatio-temporal scene graph that encodes entities, attributes, and temporally-grounded relations, used as a persistent visual reference for verifying atomic claims from the decomposed prompt.
If this is right
- Every requirement described in the prompt is checked rather than skipped.
- Each judgment is anchored in explicit visual evidence from both the video and the scene graph.
- Performance improves on semantic alignment tasks that include fine-grained temporal semantics.
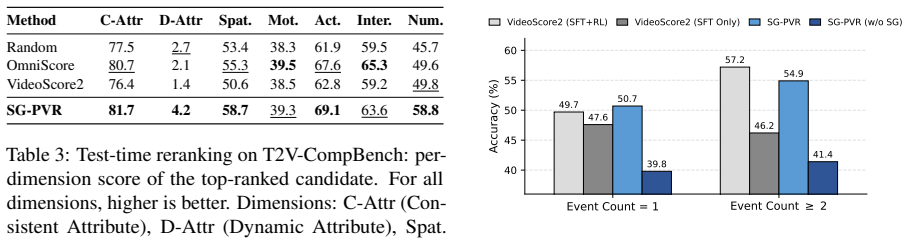
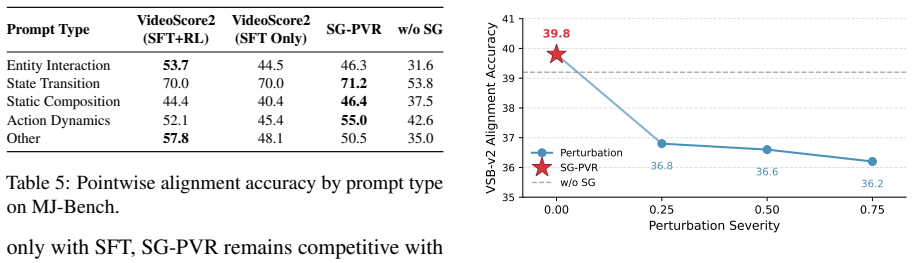
- Compositional alignment in text-to-video generation increases when SG-PVR is applied as a test-time reranker.
Where Pith is reading between the lines
- The method could make reward model decisions more traceable for debugging alignment failures.
- Similar plan-and-verify structures might extend to image or 3D generation tasks that require precise entity and relation checks.
- Improvements in scene graph extraction accuracy would directly raise the upper bound on verification reliability.
Load-bearing premise
Accurate and complete spatio-temporal scene graphs can be reliably extracted from generated videos and supply sufficient explicit evidence to verify every atomic claim without systematic omissions or extraction errors.
What would settle it
A controlled test showing that when scene graph extraction misses key temporal relations or entities in generated videos, the model's verification accuracy on corresponding prompt claims drops sharply.
Figures
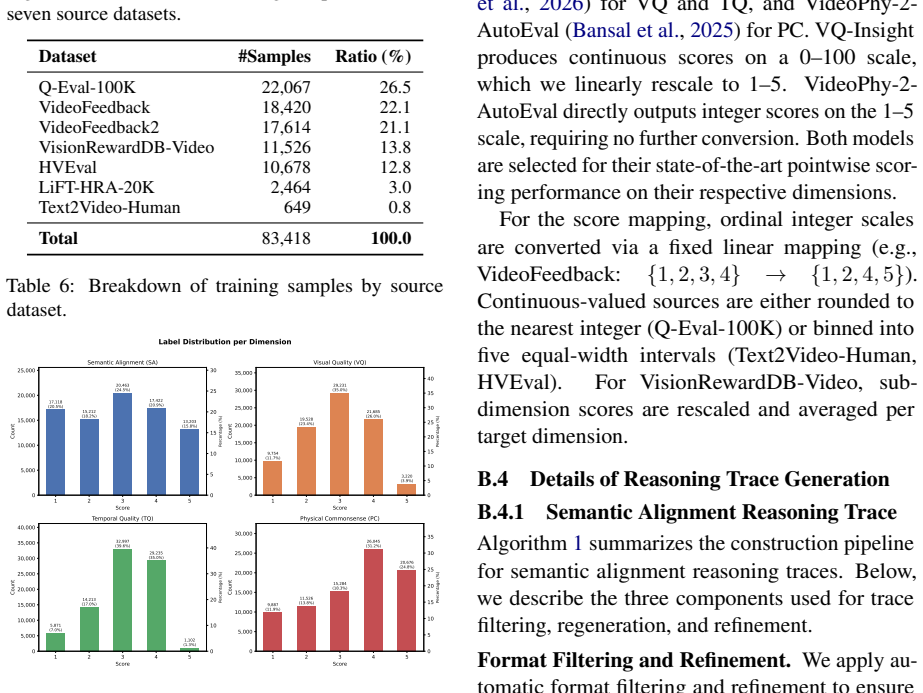


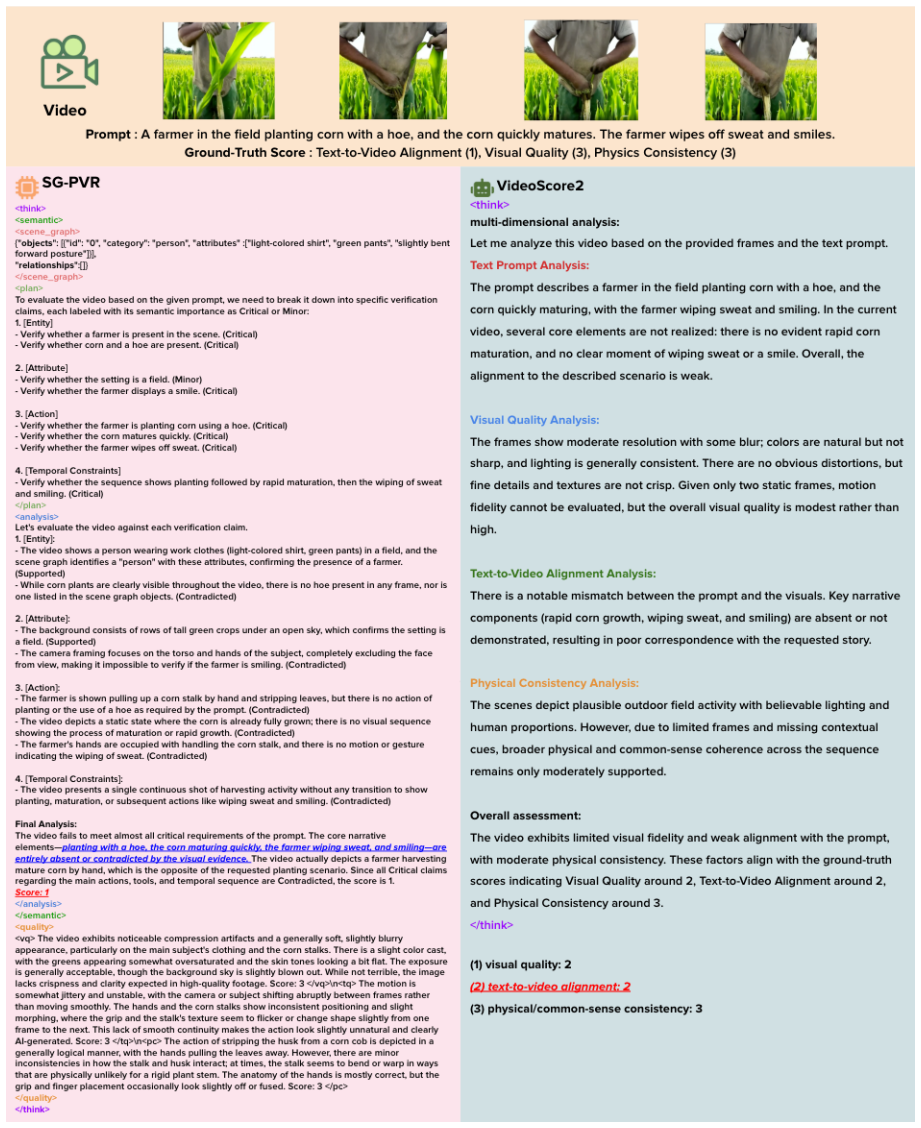

read the original abstract
Reward models for text-to-video (T2V) generation guide post-training but often fail at fine-grained semantic alignment. We trace this to two structural weaknesses in existing reasoning-based reward models: they do not systematically verify every condition described in the prompt, and the visual evidence supporting each judgment remains implicit in their free-form reasoning. We propose SG-PVR, a video reward model that addresses these limitations through plan-and-verify reasoning grounded in spatio-temporal scene graphs. The verification plan decomposes the prompt into atomic claims, ensuring every requirement is checked. The spatio-temporal scene graph, encoding entities, attributes, and temporally-grounded relations, is extracted from the video and maintained as a persistent structured visual reference throughout reasoning. Each claim is verified against both the video and the scene graph, anchoring judgments in explicit visual evidence. SG-PVR achieves strong performance on semantic alignment, including fine-grained temporal semantics. As a test-time reranker, it further enhances compositional alignment in T2V generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SG-PVR, a video reward model for text-to-video (T2V) generation that uses plan-and-verify reasoning grounded in spatio-temporal scene graphs. It decomposes prompts into atomic claims for systematic verification and extracts entities, attributes, and temporally-grounded relations from videos as explicit visual evidence, addressing implicit reasoning in prior models. The work claims strong performance on semantic alignment including fine-grained temporal semantics and further gains as a test-time reranker for compositional alignment.
Significance. If the central claims hold with supporting evidence, the structured grounding approach could improve reliability of reward models by replacing free-form reasoning with explicit, verifiable scene-graph references, potentially benefiting post-training and inference-time reranking in T2V systems.
major comments (2)
- [Abstract] Abstract: The central claim that SG-PVR 'achieves strong performance on semantic alignment' and 'further enhances compositional alignment' as a reranker is unsupported by any metrics, baselines, ablation results, or experimental details, preventing verification of the performance assertions.
- [Abstract] Method description (implied in abstract): The verification claims rest on the precondition that spatio-temporal scene graphs are accurately and completely extracted from generated videos without systematic omissions or errors on entities, attributes, or temporally-grounded relations; no quantitative validation (e.g., precision/recall or temporal grounding accuracy) of the extractor on T2V outputs is referenced, which is load-bearing for the plan-and-verify loop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the grounding assumptions. We address each major comment below, clarifying the experimental support present in the full manuscript and outlining targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SG-PVR 'achieves strong performance on semantic alignment' and 'further enhances compositional alignment' as a reranker is unsupported by any metrics, baselines, ablation results, or experimental details, preventing verification of the performance assertions.
Authors: The full manuscript contains a dedicated Experiments section with quantitative results on semantic alignment (including fine-grained temporal metrics), baseline comparisons, ablations, and test-time reranking gains on compositional alignment. These results directly support the abstract claims. We agree the abstract would be stronger if it referenced key metrics; we will revise it to include concise performance highlights (e.g., accuracy improvements and reranking gains) while remaining within length limits. revision: yes
-
Referee: [Abstract] Method description (implied in abstract): The verification claims rest on the precondition that spatio-temporal scene graphs are accurately and completely extracted from generated videos without systematic omissions or errors on entities, attributes, or temporally-grounded relations; no quantitative validation (e.g., precision/recall or temporal grounding accuracy) of the extractor on T2V outputs is referenced, which is load-bearing for the plan-and-verify loop.
Authors: The extractor is a fixed off-the-shelf spatio-temporal scene graph model whose outputs serve as an explicit, auditable reference rather than an implicit assumption of perfection. The plan-and-verify loop cross-checks claims against both the raw video and the graph, providing robustness to extraction noise. We acknowledge that explicit validation on T2V-generated videos is absent from the current version and will add a new evaluation subsection reporting precision, recall, and temporal accuracy on a held-out set of generated videos to quantify this component. revision: yes
Circularity Check
No circularity: method relies on external extraction without self-referential reductions
full rationale
The paper describes SG-PVR as a plan-and-verify reward model that decomposes prompts into atomic claims and verifies them against extracted spatio-temporal scene graphs. No equations, fitted parameters, predictions of derived quantities, or self-citations are referenced in the provided text. The core mechanism is framed as depending on an external scene-graph extractor rather than any internal derivation that reduces to its own inputs by construction. Performance claims are presented as empirical outcomes, not tautological results. This is the common case of a self-contained proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video-of-thought: Step-by-step video reason- ing from perception to cognition.arXiv preprint arXiv:2501.03230. Ziqi Gao, Jieyu Zhang, Wisdom Oluchi Ikezogwo, Jae Sung Park, Tario G You, Daniel Ogbu, Chenhao Zheng, Weikai Huang, Yinuo Yang, Winson Han, and 1 others. 2026. Synthetic visual genome 2: Extract- ing large-scale spatio-temporal scene graphs from...
arXiv 2026
-
[2]
InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 21299–21309
Etva: Evaluation of text-to-video alignment via fine-grained question generation and answering. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 21299–21309. Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, and 1 others. 2025. Videoscore2: Think before you sco...
arXiv 2025
-
[3]
a toddler plays around the grass field be- fore he picks up a water bottle and drinks
Timeblind: A spatio-temporal composition- ality benchmark for video llms.arXiv preprint arXiv:2602.00288. Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Ji- aheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. 2025a. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470. Jie Liu, Gongye Liu, Jiajun Liang, Ziy...
arXiv 2024
-
[4]
All VQA inference uses Qwen3.5-VL as the fixed backbone, following VBench-2.0’s video-based multi-question answer- ing pipeline
and TimeBlind (Li et al., 2026) onto three of its temporal controllability dimensions: Dynamic Attribute, Dynamic Spatial Relationship, and Mo- tion Order Understanding. All VQA inference uses Qwen3.5-VL as the fixed backbone, following VBench-2.0’s video-based multi-question answer- ing pipeline. Vinoground.Vinoground’s category labels are coarse and do ...
2026
-
[5]
Identify only the Criteria that are necessary for evaluat- ing the Prompt
-
[6]
Decompose the Prompt into atomic Verification Claims under those Criteria
-
[7]
Verify whether
Assign exactly one semantic importance label to each claim: Critical or Minor - Critical: main subjects, primary actions/events, key attributes, key spatial relations, temporal order, or causal/event structure. - Minor: background details, secondary objects, light- ing, style, camera angle, or other non-essential visual details. [Criteria] - Entity: subje...
-
[8]
(Critical) - Verify whether
[Criterion Name] - Verify whether ... (Critical) - Verify whether ... (Minor)
-
[9]
(Critical) E.1.2 Semantic Reasoning Trace Generation
[Criterion Name] - Verify whether ... (Critical) E.1.2 Semantic Reasoning Trace Generation. System Prompt for Semantic Alignment Rea- soning Generation You are an expert Video Semantic Alignment Evaluator. Your task is to evaluate whether the video and video scene graph satisfy the semantic requirements of the original Prompt by strictly following the Ver...
-
[10]
the original generation prompt
-
[11]
Each subject/object ID in the relationship scene graph refers to the corresponding object ID in the object scene graph
a video scene graph The video scene graph consists of an object scene graph and a relationship scene graph. Each subject/object ID in the relationship scene graph refers to the corresponding object ID in the object scene graph. If object_id is -1, it indicates None. [Tasks] Before writing, carefully inspect the video and video scene graph in full. Do not ...
-
[12]
Identify what the claim requires
-
[13]
Inspect the video and video scene graph and find specific verifiable evidence related to the claim
-
[14]
Decide whether the evidence supports, partially sup- ports, or contradicts the claim
-
[15]
After evaluating all claims, write a concise Final Analysis explaining the final score based on the distribution of Critical/Minor claims and their judgments
Write one concise bullet point that first states the spe- cific evidence and briefly explains why it justifies the judgment, then ends with the Judgment label in parenthe- ses. After evaluating all claims, write a concise Final Analysis explaining the final score based on the distribution of Critical/Minor claims and their judgments. Finally, assign one f...
-
[16]
Do not rewrite, quote, or summarize the claim itself
-
[17]
Do not merge multiple claims into one bullet
Evaluate each claim independently. Do not merge multiple claims into one bullet
-
[18]
Use the exact criterion headings from the Verification Plan and preserve their order
-
[19]
State what is actually observed or stated, not what should be present
Evidence must be grounded in the video and video scene graph. State what is actually observed or stated, not what should be present
-
[20]
Evidence from either the video or the scene graph is sufficient to support a claim
-
[21]
If an element required by the claim is completely missing from the video and video scene graph, label the judgment as Contradicted
-
[22]
If the main requirement is present but a secondary detail is missing, incomplete, or ambiguous, label the judgment as Partially Supported
-
[23]
Each evaluation bullet must end with exactly one judgment label in this parentheses: (Supported), (Partially Supported), or (Contradicted)
-
[24]
Evidence:
Do not use field headers such as “Evidence:”, “Rea- 20 soning:”, or “Judgment:” inside the evaluation bullets
-
[25]
[Score Definition] - 5 (Excellent): ALL claims, both Critical and Minor, are Supported
Output ONLY the specified format. [Score Definition] - 5 (Excellent): ALL claims, both Critical and Minor, are Supported. - 4 (Good): All Critical claims are Supported, or only 1–2 Critical claims are Partially Supported. At most 1–2 Minor claims are Contradicted. - 3 (Fair): 1–2 Critical claims are Contradicted, such as a missing specific event or object...
-
[26]
[Criterion Name in Verification Plan] - [Specific evidence from the video and video scene graph and brief reasoning explaining why the evidence justifies the judgment.] [Supported / Partially Supported / Contra- dicted] - [Specific evidence from the video and video scene graph and brief reasoning explaining why the evidence justi- fies the judgment.] [Sup...
-
[27]
[Criterion Name in Verification Plan] - [Specific evidence from the video and video scene graph and brief reasoning explaining why the evidence justifies the judgment.] [Supported / Partially Supported / Contra- dicted] - [Specific evidence from the video and video scene graph and brief reasoning explaining why the evidence justi- fies the judgment.] [Sup...
-
[28]
Identify the key entities with their categories and at- tributes
-
[29]
Identify the important relationships and events with temporal ranges
-
[30]
objects": [{
Emit the result as a single JSON object inside <scene_graph>with: { "objects": [{"id": "<id>", "category": "<noun>", "attributes": ["<adj>", ...]}], "relationships": [["<subj_id>", "<predicate>", "<obj_id>", [[<start>, <end>], ...], "<type>"], ...] } Rules: - Object IDs are unique strings starting from "0". Use "-1" to represent the camera. - Relations mu...
-
[31]
For each claim, assign a semantic importance label: (Critical/Mi- nor)
In <plan>...</plan>, decompose the prompt into atomic Verification Claims covering explicit and clearly implied semantic requirements: Entity, Attribute, Action, Spatial Relation, and Temporal Constraints. For each claim, assign a semantic importance label: (Critical/Mi- nor)
-
[32]
For each claim, write one bullet with specific evidence and brief reasoning, ending with the Judgment label in parentheses: (Supported/Partially Supported/Contradicted)
Using the video and scene graph as evidence, evaluate each claim in the Verification Plan in order. For each claim, write one bullet with specific evidence and brief reasoning, ending with the Judgment label in parentheses: (Supported/Partially Supported/Contradicted)
-
[33]
Score:<1-5>
After evaluating all claims, write ‘Final Analysis:’ to summarize the distribution of claim judgments, while considering the semantic importance labels assigned in <plan>, then end withSemantic Score: <1-5>. Rules: - Do not introduce or evaluate claims outside<plan>. - Do not quote or rewrite the full claim in the evaluation bullets. - Evidence must be gr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.