BitTP: The Lightweight Trajectory Prediction Model with BitLLM for Edge-Devices
Pith reviewed 2026-06-29 07:54 UTC · model grok-4.3
The pith
BitTP shows that quantizing only the weights of an LLM trajectory predictor to 1.58 bits improves accuracy over the full-precision baseline while cutting memory and latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
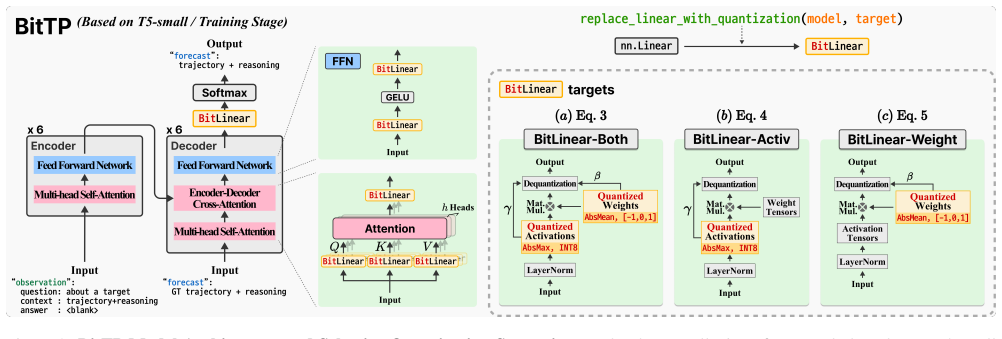
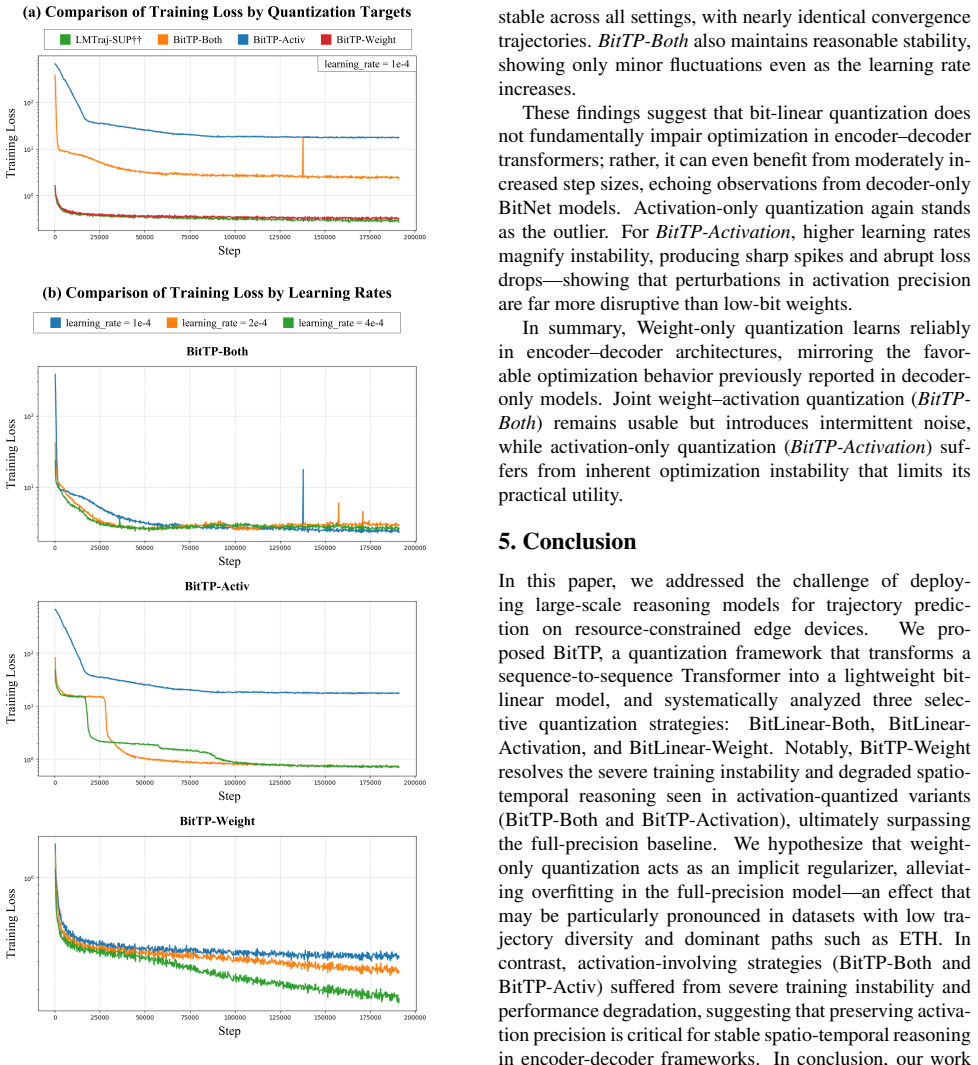
BitTP converts an LLM-based trajectory predictor into a lightweight bitlinear architecture. Weight-only quantization to 1.58 bits (BitTP-Weight) not only preserves but improves prediction quality over the full-precision BF16 baseline, reducing ADE by 14.29 percent and FDE by 20.97 percent on average. Memory usage and inference latency decrease compared with other quantization methods. Activations must remain in full precision; quantizing them produces severe degradation and instability in spatio-temporal reasoning. The quantization thereby acts as an effective regularizer that enables practical deployment of sophisticated LLM-based reasoning on edge devices.
What carries the argument
Bitlinear architecture with weight-only 1.58-bit quantization while keeping activations in full precision.
If this is right
- LLM-based trajectory predictors become deployable on resource-constrained edge hardware such as on-board computers in autonomous robots.
- Quantization to low-bit weights alone can improve rather than degrade accuracy in multi-agent interaction modeling.
- The method reduces both memory consumption and inference latency relative to alternative quantization approaches.
- Language-based trajectory representations can be used in real-time autonomous systems without full-precision compute.
Where Pith is reading between the lines
- The same weight-only scheme might transfer to other sequential prediction tasks that rely on contextual reasoning.
- Hybrid precision could be explored for additional compression while monitoring stability in interaction modeling.
- Real-world testing on varied edge hardware would clarify whether the observed latency gains hold under varying loads.
- Improved accuracy from quantization raises questions about how the regularizer effect scales to larger LLMs.
Load-bearing premise
Quantizing activations produces severe degradation and instability in spatio-temporal reasoning, so they must stay in full precision.
What would settle it
An experiment in which both weights and activations are quantized to 1.58 bits and the model still shows stable or improved ADE/FDE without instability would falsify the requirement for full-precision activations.
Figures

read the original abstract
Trajectory prediction is a fundamental task for autonomous systems, requiring complex reasoning about multi-agent interactions and intents. Large language models (LLMs) have recently been adopted for this task, as they provide strong contextual reasoning and interpretable, language-based trajectory representations. However, these LLM-based predictors are extremely memory- and compute-intensive, making them difficult to deploy on resource-constrained edge devices such as on-board computers in autonomous robots. To bridge this gap, we propose BitTP, which converts an LLM-based trajectory predictor into a lightweight bitlinear architecture. We demonstrate that weight-only quantization to 1.58-bit (BitTP-Weight) is optimal. Crucially, activations must remain in full precision, as quantizing them leads to severe degradation and instability in spatio-temporal reasoning. Empirically, BitTP-Weight not only preserves but improves prediction quality over the full-precision (BF16) LLM baseline, reducing ADE by 14.29% and FDE by 20.97% on average, while simultaneously reducing memory usage and inference latency relative to other quantization methods. These results demonstrate that carefully designed quantization acts as an effective regularizer, enabling the practical deployment of sophisticated LLM-based reasoning on edge devices. Code is available at: https://github.com/MintCat98/BitTP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BitTP, a method to convert LLM-based trajectory predictors into a lightweight bitlinear architecture. It claims that weight-only quantization to 1.58 bits (BitTP-Weight) is optimal when activations remain in full precision, as quantizing activations causes severe degradation. Empirically, BitTP-Weight improves average ADE by 14.29% and FDE by 20.97% over the BF16 LLM baseline while reducing memory usage and inference latency, with quantization acting as an effective regularizer for edge-device deployment in autonomous systems.
Significance. If the central empirical claims hold after addressing baseline ambiguities, the work would be significant for enabling deployment of complex LLM-based spatio-temporal reasoning on resource-constrained edge devices, demonstrating that targeted quantization can improve rather than degrade prediction quality in trajectory forecasting tasks.
major comments (1)
- [Abstract] Abstract: The central claim attributes the ADE/FDE reductions (14.29%/20.97%) and regularization effect specifically to 1.58-bit weight quantization. However, the baseline is the unmodified full-precision LLM; the method first converts the model to a bitlinear architecture before applying quantization. Without an explicit ablation measuring the bitlinear architecture at BF16 precision, it is impossible to isolate whether the observed gains arise from quantization or from the architectural substitution itself.
minor comments (2)
- [Abstract] The abstract states that 'activations must remain in full precision' as crucial, but provides no quantitative comparison or ablation showing the degradation from activation quantization.
- No details are provided on the specific datasets, baselines, or error bars supporting the reported ADE/FDE improvements.
Simulated Author's Rebuttal
We thank the referee for highlighting the baseline ambiguity in isolating the contribution of 1.58-bit quantization versus the bitlinear architectural conversion. We address this point directly below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the ADE/FDE reductions (14.29%/20.97%) and regularization effect specifically to 1.58-bit weight quantization. However, the baseline is the unmodified full-precision LLM; the method first converts the model to a bitlinear architecture before applying quantization. Without an explicit ablation measuring the bitlinear architecture at BF16 precision, it is impossible to isolate whether the observed gains arise from quantization or from the architectural substitution itself.
Authors: We agree that the current baseline comparison does not fully disentangle the bitlinear conversion from the subsequent weight-only quantization. The bitlinear architecture was introduced specifically to enable efficient 1.58-bit operations, but an explicit BF16 bitlinear ablation is indeed required to confirm that the observed ADE/FDE improvements and regularization effect stem from quantization rather than the architectural change alone. In the revised manuscript we will add this ablation (bitlinear model at BF16 versus quantized BitTP-Weight versus original LLM), report the corresponding ADE/FDE and latency numbers, and update the abstract and experimental sections accordingly to clarify the source of the gains. revision: yes
Circularity Check
No circularity: empirical quantization study with no derivations or self-referential reductions
full rationale
The paper presents an empirical evaluation of weight-only 1.58-bit quantization on an LLM-based trajectory predictor, reporting ADE/FDE improvements over a BF16 baseline without any mathematical derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations. The central claims rest on experimental measurements rather than a derivation chain that reduces to its own inputs by construction. The noted experimental design choice (baseline is unmodified LLM rather than bitlinear BF16) is a potential validity concern but does not constitute circularity under the specified patterns, as no step equates a result to an input via definition or self-citation. The work is self-contained as a report on observed effects.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
So- cial lstm: Human trajectory prediction in crowded spaces
Alexandre Alahi, Kratarth Goel, Vignesh Ramanathan, Alexandre Robicquet, Li Fei-Fei, and Silvio Savarese. So- cial lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 961–971, 2016. 1, 2
2016
-
[2]
Can language beat numerical regression? language-based multimodal tra- jectory prediction
Inhwan Bae, Junoh Lee, and Hae-Gon Jeon. Can language beat numerical regression? language-based multimodal tra- jectory prediction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 753–766, 2024. 1, 2, 3, 5, 6, 7
2024
-
[3]
Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 1, 3
1901
-
[4]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 2
2020
-
[5]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based plan- ning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Intentnet: Learning to predict intention from raw sensor data
Sergio Casas, Wenjie Luo, and Raquel Urtasun. Intentnet: Learning to predict intention from raw sensor data. InCon- ference on robot learning, pages 947–956. PMLR, 2018. 2
2018
-
[7]
Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. Multipath: Multiple probabilistic anchor tra- jectory hypotheses for behavior prediction.arXiv preprint arXiv:1910.05449, 2019. 2
-
[8]
Argoverse: 3d tracking and forecasting with rich maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jag- jeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8748–8757, 2019. 2
2019
-
[9]
The case for 4-bit pre- cision: k-bit inference scaling laws
Tim Dettmers and Luke Zettlemoyer. The case for 4-bit pre- cision: k-bit inference scaling laws. InInternational Confer- ence on Machine Learning, pages 7750–7774. PMLR, 2023. 6
2023
-
[10]
LLM.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale. InAdvances in Neural Information Processing Systems, 2022. 2, 3
2022
-
[11]
8-bit optimizers via block-wise quantization
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettle- moyer. 8-bit optimizers via block-wise quantization. In 9th International Conference on Learning Representations, ICLR, 2022
2022
-
[12]
Qlora: Efficient finetuning of quantized llms,
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms,
-
[13]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 1, 3
2019
-
[14]
Large scale interactive motion forecasting for autonomous driving: The waymo open mo- tion dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open mo- tion dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 9710–9719, 2021. 2
2021
-
[15]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hy- pothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Gptq: Accurate post-training quantization for gener- ative pre-trained transformers, 2023
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Al- istarh. Gptq: Accurate post-training quantization for gener- ative pre-trained transformers, 2023. 2, 3
2023
-
[17]
Vectornet: Encoding hd maps and agent dynamics from vectorized rep- resentation
Jiyang Gao, Chen Sun, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid. Vectornet: Encoding hd maps and agent dynamics from vectorized rep- resentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11525– 11533, 2020. 1, 2
2020
-
[18]
llama.cpp: Llm inference in c/c++.https: //github.com/ggml- org/llama.cpp
ggml org. llama.cpp: Llm inference in c/c++.https: //github.com/ggml- org/llama.cpp. Accessed 2026-04-08. 6
2026
-
[19]
Improving multi-agent motion predic- tion with heuristic goals and motion refinement
Carlos G ´omez-Hu´elamo, Marcos V Conde, Rafael Barea, and Luis M Bergasa. Improving multi-agent motion predic- tion with heuristic goals and motion refinement. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5323–5332, 2023. 2, 3
2023
-
[20]
Stochastic trajectory pre- diction via motion indeterminacy diffusion
Tianpei Gu, Guangyi Chen, Junlong Li, Chunze Lin, Yong- ming Rao, Jie Zhou, and Jiwen Lu. Stochastic trajectory pre- diction via motion indeterminacy diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17113–17122, 2022. 5, 6
2022
-
[21]
Social gan: Socially acceptable tra- jectories with generative adversarial networks
Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social gan: Socially acceptable tra- jectories with generative adversarial networks. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2255–2264, 2018. 1, 2
2018
-
[22]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
One thousand and one hours: Self-driving motion prediction dataset
John Houston, Guido Zuidhof, Luca Bergamini, Yawei Ye, Long Chen, Ashesh Jain, Sammy Omari, Vladimir Iglovikov, and Peter Ondruska. One thousand and one hours: Self-driving motion prediction dataset. InConference on Robot Learning, pages 409–418. PMLR, 2021. 2
2021
-
[24]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2, 3
2022
-
[25]
Stgat: Modeling spatial-temporal interac- tions for human trajectory prediction
Yingfan Huang, Huikun Bi, Zhaoxin Li, Tianlu Mao, and Zhaoqi Wang. Stgat: Modeling spatial-temporal interac- tions for human trajectory prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 6272–6281, 2019. 1, 2
2019
-
[26]
The trajectron: Proba- bilistic multi-agent trajectory modeling with dynamic spa- tiotemporal graphs
Boris Ivanovic and Marco Pavone. The trajectron: Proba- bilistic multi-agent trajectory modeling with dynamic spa- tiotemporal graphs. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 2375–2384,
-
[27]
Social- bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks.Advances in neural informa- tion processing systems, 32, 2019
Vineet Kosaraju, Amir Sadeghian, Roberto Mart ´ın-Mart´ın, Ian Reid, Hamid Rezatofighi, and Silvio Savarese. Social- bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks.Advances in neural informa- tion processing systems, 32, 2019. 2
2019
-
[28]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[29]
Traj-llm: A new explo- ration for empowering trajectory prediction with pre-trained large language models, 2024
Zhengxing Lan, Hongbo Li, Lingshan Liu, Bo Fan, Yisheng Lv, Yilong Ren, and Zhiyong Cui. Traj-llm: A new explo- ration for empowering trajectory prediction with pre-trained large language models, 2024. 1, 3
2024
-
[30]
Desire: Distant future prediction in dynamic scenes with interacting agents
Namhoon Lee, Wongun Choi, Paul Vernaza, Christopher B Choy, Philip HS Torr, and Manmohan Chandraker. Desire: Distant future prediction in dynamic scenes with interacting agents. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 336–345, 2017. 1, 2
2017
-
[31]
Spatio-temporal graph dual-attention network for multi-agent prediction and tracking, 2021
Jiachen Li, Hengbo Ma, Zhihao Zhang, Jinning Li, and Masayoshi Tomizuka. Spatio-temporal graph dual-attention network for multi-agent prediction and tracking, 2021. 2
2021
-
[32]
Evolvegraph: Multi-agent trajectory prediction with dynam- ically evolving interaction graphs
Xin Li, Tianchen Yu, Noriaki Kim, Wei Xu, and Renjie Liu. Evolvegraph: Multi-agent trajectory prediction with dynam- ically evolving interaction graphs. InAdvances in Neural Information Processing Systems (NeurIPS), pages 19742– 19752, 2020. 2, 3
2020
-
[33]
Learning lane graph representa- tions for motion forecasting
Ming Liang, Bin Yang, Rui Hu, Yun Chen, Renjie Liao, Song Feng, and Raquel Urtasun. Learning lane graph representa- tions for motion forecasting. InEuropean Conference on Computer Vision, pages 541–556. Springer, 2020. 1, 2
2020
-
[34]
Awq: Activation-aware weight quantization for llm compression and acceleration, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration, 2024. 2, 3
2024
-
[35]
It is not the journey but the destination: Endpoint conditioned trajectory prediction, 2020
Karttikeya Mangalam, Harshayu Girase, Shreyas Agarwal, Kuan-Hui Lee, Ehsan Adeli, Jitendra Malik, and Adrien Gaidon. It is not the journey but the destination: Endpoint conditioned trajectory prediction, 2020. 2, 5, 6
2020
-
[36]
From goals, waypoints & paths to long term hu- man trajectory forecasting
Karttikeya Mangalam, Yang An, Harshayu Girase, and Jiten- dra Malik. From goals, waypoints & paths to long term hu- man trajectory forecasting. InProceedings of the IEEE/CVF international conference on computer vision, pages 15233– 15242, 2021. 3
2021
-
[37]
Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction
Abduallah Mohamed, Kun Qian, Mohamed Elhoseiny, and Christian Claudel. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14424– 14432, 2020. 1, 2
2020
-
[38]
Scene transformer: A unified architecture for predicting multiple agent trajectories, 2022
Jiquan Ngiam, Benjamin Caine, Vijay Vasudevan, Zheng- dong Zhang, Hao-Tien Lewis Chiang, Jeffrey Ling, Rebecca Roelofs, Alex Bewley, Chenxi Liu, Ashish Venugopal, David Weiss, Ben Sapp, Zhifeng Chen, and Jonathon Shlens. Scene transformer: A unified architecture for predicting multiple agent trajectories, 2022. 1, 2, 3
2022
-
[39]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 3
2020
-
[40]
Xnor-net: Imagenet classification using bi- nary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using bi- nary convolutional neural networks. InEuropean conference on computer vision, pages 525–542. Springer, 2016. 2, 3
2016
-
[41]
Learning social etiquette: Human trajectory prediction in crowded scenes
A Robicquet, A Sadeghian, A Alahi, and S Savarese. Learning social etiquette: Human trajectory prediction in crowded scenes. InEuropean Conference on Computer Vi- sion (ECCV), page 5, 2017. 2
2017
-
[42]
Trajectron++: Dynamically-feasible trajec- tory forecasting with heterogeneous data
Tim Salzmann, Boris Ivanovic, Punarjay Chakravarty, and Marco Pavone. Trajectron++: Dynamically-feasible trajec- tory forecasting with heterogeneous data. InEuropean Con- ference on Computer Vision, pages 683–700. Springer, 2020. 1, 2
2020
-
[43]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 1
2024
-
[45]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Tejas Vaidhya, Ayush Kaushal, Vineet Jain, Francis Cou- ture Harpin, Prashant Shishodia, Majid Behbahani, Yuriy Nevmyvaka, and Irina Rish. Spectra 1.1: Scaling laws and efficient inference for ternary language models.arXiv preprint arXiv:2506.23025, 2025. 6
-
[47]
Bitnet: 1-bit pre-training for large language models.Journal of Machine Learning Research, 26(125):1–29, 2025
Hongyu Wang, Shuming Ma, Lingxiao Ma, Lei Wang, Wen- hui Wang, Li Dong, Shaohan Huang, Huaijie Wang, Jilong Xue, Ruiping Wang, et al. Bitnet: 1-bit pre-training for large language models.Journal of Machine Learning Research, 26(125):1–29, 2025. 2, 3, 4, 5, 7
2025
-
[48]
So- cialvae: Human trajectory prediction using timewise latents
Pei Xu, Jean-Bernard Hayet, and Ioannis Karamouzas. So- cialvae: Human trajectory prediction using timewise latents. InEuropean Conference on Computer Vision, pages 511–
-
[49]
Springer, 2022. 5, 6
2022
-
[50]
Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting
Ye Yuan, Xinshuo Weng, Yanglan Ou, and Kris M Kitani. Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. InProceedings of the IEEE/CVF international conference on computer vision, pages 9813– 9823, 2021. 1, 2, 3
2021
-
[51]
Tnt: Target-driven trajectory pre- diction
Hang Zhao, Jiyang Gao, Tian Lan, Chen Sun, Ben Sapp, Balakrishnan Varadarajan, Yue Shen, Yi Shen, Yuning Chai, Cordelia Schmid, et al. Tnt: Target-driven trajectory pre- diction. InConference on robot learning, pages 895–904. PMLR, 2021. 1, 2
2021
-
[52]
Hanyu Zhou and Gim Hee Lee. Uni4d-llm: A unified spatiotemporal-aware vlm for 4d understanding and gener- ation.arXiv preprint arXiv:2509.23828, 2025. 1, 3
-
[53]
Hivt: Hierarchical vector transformer for multi-agent motion prediction
Zikang Zhou, Luyao Ye, Jianping Wang, Kui Wu, and Ke- jie Lu. Hivt: Hierarchical vector transformer for multi-agent motion prediction. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8823–8833, 2022. 2
2022
-
[54]
A unified frame- work for multimodal, multi-part human motion synthesis,
Zixiang Zhou, Yu Wan, and Baoyuan Wang. A unified frame- work for multimodal, multi-part human motion synthesis,
-
[55]
Query-centric trajectory prediction
Zikang Zhou, Jianping Wang, Yung-Hui Li, and Yu-Kai Huang. Query-centric trajectory prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17863–17873, 2023. 1, 2 BitTP: The Lightweight Trajectory Prediction Model with BitLLM for Edge-Devices Supplementary Material S1. Implementation Details and Evaluation M...
2023
-
[56]
framework, BitTP-Weight successfully achieves a throughput of 2.18 sequences/s on the ETH subset. This result confirms that running sophisticated trajectory predic- tion models entirely on resource-constrained on-board com- puters without GPU acceleration is practically possible. To measure realistic edge-device latency, our CPU evaluation uses single-sam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.