Creating and Evaluating K-12 GenAI Assessment Graders Through Context Engineering
Pith reviewed 2026-06-30 22:51 UTC · model grok-4.3
The pith
Context-engineered LLMs achieve substantial agreement with human raters on K-12 math and science assessments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying context and prompt engineering to commercially available foundation models, LLM-based graders can produce scores that align substantially with human raters on mathematics and science items from the MCAS, as measured by Quadratic Weighted Kappa and PRMSE, though results vary in ELA; the approach works without fine-tuning and supports hybrid human-AI assessment models.
What carries the argument
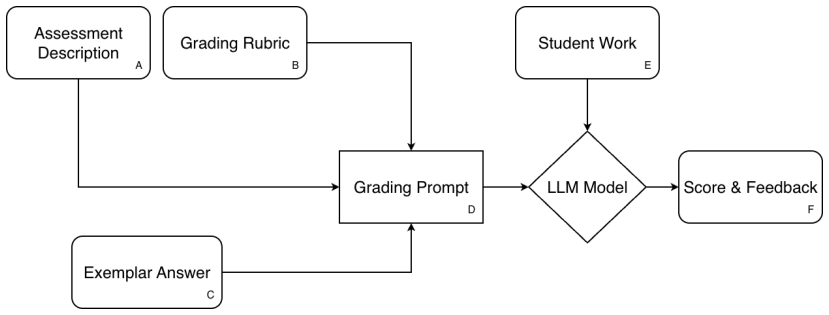
The context-engineered LLM grader that scores student responses against rubrics using foundation models such as Claude Sonnet 4 and GPT-5.
If this is right
- Larger-parameter models produce higher agreement with humans in mathematics and science.
- Agreement is lower and more variable in English language arts.
- Narrative feedback from the models receives stronger acceptance than numerical scores.
- Hybrid systems that combine LLM output with teacher review can reduce workload while preserving professional judgment.
Where Pith is reading between the lines
- The same context-engineering approach could be tested on other state assessments or classroom rubrics to check consistency.
- Over time, teacher time might shift from initial scoring to reviewing and interpreting AI-generated comments.
- Equity effects across different student populations remain untested in the reported data.
Load-bearing premise
That carefully designed prompts and context on generic foundation models produce consistent, reliable scores without subject-specific training data or fine-tuning.
What would settle it
A new study using different student responses or rubrics that reports low Quadratic Weighted Kappa values between the same LLM setup and human raters.
Figures
read the original abstract
The integration of large language models (LLMs) into educational assessment represents a transformative shift in classroom grading practices. While automated scoring systems and machine learning techniques have existed for decades, generative AI (GenAI) now enables educators to implement standards-based grading (SBG) with unprecedented efficiency and scale. This paper examines the theoretical foundations and evaluates an LLM grader that uses commercially available foundation models with context and prompt engineering to score student work against a rubric. Drawing on an empirical interrater agreement study using Massachusetts Comprehensive Assessment System (MCAS) data, we observed the Quadratic Weighted Kappa (QWK) and Proportional Reduction in Mean-Squared Error (PRMSE) across mathematics, science, and ELA, using Claude Sonnet 4, Haiku 4.5, GPT-5, and GPT-5 Mini. The results demonstrate that LLM graders, especially when based on foundational models with more parameters, achieve substantial agreement with human raters in mathematics and science assessments, while the performances vary in ELA, suggesting generic foundation models can be effective at scoring in given contexts. Additional analysis of teacher and student feedback reveals strong acceptance of AI-generated narrative feedback but skepticism toward numerical scores, suggesting that LLMs function most effectively as formative tools rather than summative evaluators. Our findings indicate that thoughtfully designed hybrid models that combine AI efficiency with teacher judgment can reduce workload, enhance feedback quality, and support equitable assessment practices without displacing professional expertise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that context- and prompt-engineered LLM graders built on commercial foundation models (Claude Sonnet 4, Haiku 4.5, GPT-5, GPT-5 Mini) achieve substantial agreement with human raters on MCAS K-12 items in mathematics and science, as measured by QWK and PRMSE, with more variable results in ELA. It further reports that teachers and students accept AI-generated narrative feedback but remain skeptical of numerical scores, concluding that such systems are best used as formative tools within hybrid human-AI assessment workflows.
Significance. If the reported agreement metrics prove robust once anchored to human baselines and supplied with full methodological detail, the work would offer a practical demonstration that generic foundation models can support standards-based grading at scale without subject-specific fine-tuning. This could inform workload-reduction strategies in K-12 settings and contribute to discussions of equitable, hybrid assessment. The absence of a human-human reference and of basic statistical reporting currently limits the strength of that contribution.
major comments (2)
- [Abstract / Methodology] Abstract and methodology description: the claim that LLM graders achieve 'substantial agreement' with human raters cannot be evaluated without a human-human interrater QWK baseline computed on the identical MCAS items and rubrics. Without this ceiling, reported QWK values remain unanchored and the interpretation of 'substantial' is unsupported.
- [Results] Results section: the abstract states QWK and PRMSE values across subjects and models but supplies no sample sizes, exact prompts, data filtering rules, confidence intervals, or statistical tests. These omissions prevent assessment of the precision and replicability of the central empirical claims.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the number of student responses or items scored to convey study scale.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which identify key areas where additional context and transparency can strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Methodology] Abstract and methodology description: the claim that LLM graders achieve 'substantial agreement' with human raters cannot be evaluated without a human-human interrater QWK baseline computed on the identical MCAS items and rubrics. Without this ceiling, reported QWK values remain unanchored and the interpretation of 'substantial' is unsupported.
Authors: We agree that a human-human baseline would aid interpretation of the reported QWK values. However, the MCAS released items in our study follow standard operational scoring procedures that provide only a single human rater per response; we do not have access to multiple independent human ratings on the identical items and therefore cannot compute such a baseline. We will revise the manuscript to explicitly acknowledge this limitation, clarify that our QWK values measure agreement with the operational human scores rather than an empirical ceiling, and anchor the term 'substantial' to conventional benchmarks in the educational measurement literature (e.g., Landis & Koch). revision: partial
-
Referee: [Results] Results section: the abstract states QWK and PRMSE values across subjects and models but supplies no sample sizes, exact prompts, data filtering rules, confidence intervals, or statistical tests. These omissions prevent assessment of the precision and replicability of the central empirical claims.
Authors: We appreciate this observation. While the full methods and results sections contain sample sizes and basic methodological information, we acknowledge that the abstract and certain results subsections omit exact prompts, data filtering rules, confidence intervals, and statistical tests. We will revise to add these details: include sample sizes in the abstract or prominently in results, move the exact prompts to a new appendix, describe filtering rules explicitly, and report confidence intervals along with any applicable statistical tests. revision: yes
- Human-human interrater QWK baseline on the identical MCAS items (unavailable due to single-rater operational scoring)
Circularity Check
Empirical evaluation study with no derivation chain or self-referential elements
full rationale
The paper is a direct empirical comparison of LLM graders (via context engineering on foundation models) against human raters on MCAS items, reporting QWK and PRMSE values across subjects. No equations, parameter fitting, or predictive derivations are described; the central claim rests on observed agreement metrics rather than any reduction to self-defined inputs or self-citation chains. The study is self-contained against the external human rating benchmark and does not invoke uniqueness theorems, ansatzes, or renamings that collapse back to the paper's own choices.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, year =
Scheurman, Geoffrey and Newmann, Fred M. , year =. Authentic intellectual work in social studies:. Social Education , publisher =
-
[2]
and Bryk, Anthony S
Newmann, Fred M. and Bryk, Anthony S. and Nagaoka, Jenny K. , year =. Authentic
-
[3]
Nature Machine Intelligence , author =
Principles alone cannot guarantee ethical. Nature Machine Intelligence , author =. 2019 , keywords =. doi:10.1038/s42256-019-0114-4 , abstract =
-
[5]
International Journal of Medical Informatics , author =
Finding warning markers:. International Journal of Medical Informatics , author =. 2020 , keywords =. doi:10.1016/j.ijmedinf.2020.104137 , abstract =
-
[6]
, month = dec, year =
Gillies, Robyn M. , month = dec, year =. Enhancing
-
[7]
Smart Learning Environments , author =
Personalized adaptive learning: an emerging pedagogical approach enabled by a smart learning environment , volume =. Smart Learning Environments , author =. 2019 , keywords =. doi:10.1186/s40561-019-0089-y , abstract =
-
[8]
Alam, Ashraf , editor =. Harnessing the. Intelligent. 2023 , keywords =. doi:10.1007/978-981-99-1767-9_42 , abstract =
-
[9]
Journal of Educational Psychology , author =
Using adaptive learning technologies to personalize instruction to student interests:. Journal of Educational Psychology , author =. 2013 , keywords =. doi:10.1037/a0031882 , abstract =
-
[10]
IEEE Signal Processing Magazine , author =
Personalized. IEEE Signal Processing Magazine , author =. 2021 , pages =. doi:10.1109/MSP.2021.3055032 , abstract =
-
[12]
Makinae, Naomichi , editor =. The. Theory and. 2019 , keywords =. doi:10.1007/978-3-030-04031-4_9 , abstract =
-
[13]
Education and Information Technologies , author =
Large language models in education:. Education and Information Technologies , author =. 2023 , keywords =. doi:10.1007/s10639-023-11834-1 , abstract =
-
[14]
Studies in Educational Evaluation , author =
Classroom observation for evaluating and improving teaching:. Studies in Educational Evaluation , author =. 2016 , pages =
2016
-
[17]
Innovations in Education and Teaching International , author =
Overlooking the conceptual framework , volume =. Innovations in Education and Teaching International , author =. 2007 , pages =. doi:10.1080/14703290601081407 , language =
-
[18]
The. The School Review , author =. doi:10.1086/442404 , language =
-
[19]
Red teaming chatgpt via jailbreaking:
Zhuo, Terry Yue and Huang, Yujin and Chen, Chunyang and Xing, Zhenchang , year =. Red teaming chatgpt via jailbreaking:. arXiv preprint arXiv:2301.12867 , publisher =
-
[20]
and Rodríguez, Roberto J
Cardona, Miguel A. and Rodríguez, Roberto J. and Ishmael, Kristina , year =. Artificial
-
[21]
Language and Education , author =
An analysis of the forms of teacher-student dialogue that are most productive for learning , volume =. Language and Education , author =. 2023 , pages =. doi:10.1080/09500782.2021.1956943 , language =
-
[22]
Retrieved from Glossary of Artificial Intelligence Terms for Educators–CIRCLS , author =
Glossary of. Retrieved from Glossary of Artificial Intelligence Terms for Educators–CIRCLS , author =
-
[23]
Annual Review of Information Science and Technology (ARIST) , author =
Natural. Annual Review of Information Science and Technology (ARIST) , author =. 2003 , note =
2003
-
[24]
Technology, Knowledge and Learning , author =
Educational. Technology, Knowledge and Learning , author =. 2014 , file =. doi:10.1007/s10758-014-9223-7 , abstract =
-
[25]
and Elmore, Richard F
City, Elizabeth A. and Elmore, Richard F. and Fiarman, Sarah E. and Teitel, Lee , year =. Instructional rounds in education , volume =
-
[26]
Draft manuscript , author =
Improving the instructional core , url =. Draft manuscript , author =. 2008 , file =
2008
-
[27]
Scribner, Jay Paredes and Donaldson, Joe F. , month = dec, year =. The. Educational Administration Quarterly , publisher =. doi:10.1177/00131610121969442 , abstract =
-
[28]
Abrahamson, Dor and Sánchez-García, Raúl , month = apr, year =. Learning. Journal of the Learning Sciences , publisher =. doi:10.1080/10508406.2016.1143370 , abstract =
-
[29]
Educational Technology Research and Development , author =
Technology enhanced feedback tools as a knowledge management mechanism for supporting professional growth and school reform , volume =. Educational Technology Research and Development , author =. 2011 , pages =. doi:10.1007/S11423-011-9201-X , abstract =
-
[30]
and Stoolmiller, Mike and Kennedy, Patrick C
Doabler, Christian T. and Stoolmiller, Mike and Kennedy, Patrick C. and Nelson, Nancy J. and Clarke, Ben and Gearin, Brian and Fien, Hank and Smolkowski, Keith and Baker, Scott K. , month = jun, year =. Do. Assessment for Effective Intervention , publisher =. doi:10.1177/1534508418758364 , abstract =
-
[31]
Journal of Research in Science Teaching , author =
Impact of project-based curriculum materials on student learning in science:. Journal of Research in Science Teaching , author =. 2015 , note =. doi:10.1002/tea.21263 , abstract =
-
[32]
Neuro‐linguistic programming as an innovation in education and teaching , volume =
Tosey, Paul and Mathison, Jane , month = aug, year =. Neuro‐linguistic programming as an innovation in education and teaching , volume =. Innovations in Education and Teaching International , publisher =. doi:10.1080/14703297.2010.498183 , abstract =
-
[33]
Studies in Philosophy and Education , author =
Deliberative. Studies in Philosophy and Education , author =. 2008 , keywords =. doi:10.1007/s11217-007-9071-1 , abstract =
-
[34]
Liu, Jing and Cohen, Julie , month = dec, year =. Measuring. Educational Evaluation and Policy Analysis , publisher =. doi:10.3102/01623737211009267 , abstract =
-
[35]
Danielson, Charlotte , year =
-
[36]
The framework for teaching evaluation instrument
Danielson, Charlotte , year =. The framework for teaching evaluation instrument. , url =
-
[37]
Yang, Xi and Zhang, Lishan and Yu, Shengquan , editor =. Can. Artificial. 2017 , note =. doi:10.1007/978-3-319-61425-0_72 , urldate =
-
[38]
Kakkonen, T. and Sutinen, E. , year =. Automatic assessment of the content of essays based on course materials , isbn =. doi:10.1109/ITRE.2004.1393660 , abstract =
-
[39]
Wang, Zining and Liu, Jianli and Dong, Ruihai , month = nov, year =. Intelligent. 2018 5th. doi:10.1109/CCIS.2018.8691244 , abstract =
-
[40]
Leading the instructional core , journal =
Elmore, Richard , year =. Leading the instructional core , journal =
-
[41]
Saito, Eisuke , month = nov, year =. Key issues of lesson study in. Professional Development in Education , publisher =. doi:10.1080/19415257.2012.668857 , abstract =
-
[42]
Promoting rich discussions in mathematics classrooms:
Jacobs, Jennifer and Scornavacco, Karla and Harty, Charis and Suresh, Abhijit and Lai, Vivian and Sumner, Tamara , year =. Promoting rich discussions in mathematics classrooms:. Teaching and Teacher Education , publisher =
-
[43]
Suresh, Abhijit and Jacobs, Jennifer and Harty, Charis and Perkoff, Margaret and Martin, James H and Sumner, Tamara , file =. The
-
[44]
and Sumner, Tamara , month = apr, year =
Suresh, Abhijit and Jacobs, Jennifer and Harty, Charis and Perkoff, Margaret and Martin, James H. and Sumner, Tamara , month = apr, year =. The. doi:10.48550/arXiv.2204.09652 , abstract =
-
[45]
Studies in Educational Evaluation , author =
Classroom observation for evaluating and improving teaching:. Studies in Educational Evaluation , author =. 2016 , keywords =. doi:10.1016/j.stueduc.2016.03.002 , abstract =
-
[46]
Education Policy Analysis Archives , author =
Using global observation protocols to inform research on teaching effectiveness and school improvement:. Education Policy Analysis Archives , author =. 2020 , keywords =. doi:10.14507/epaa.28.5012 , abstract =
-
[47]
Fine-tuning
Latif, Ehsan and Zhai, Xiaoming , month = dec, year =. Fine-tuning
-
[48]
and Demszky, Dorottya , month = jun, year =
Wang, Rose E. and Demszky, Dorottya , month = jun, year =. Is. doi:10.48550/arXiv.2306.03090 , abstract =
-
[49]
and Stone, Cathlyn and Kelly, Sean and Godley, Amanda and D'Mello, Sidney K
Jensen, Emily and Dale, Meghan and Donnelly, Patrick J. and Stone, Cathlyn and Kelly, Sean and Godley, Amanda and D'Mello, Sidney K. , month = apr, year =. Toward. Proceedings of the 2020. doi:10.1145/3313831.3376418 , abstract =
-
[50]
and Jurafsky, Dan and Piech, Chris , month = may, year =
Demszky, Dorottya and Liu, Jing and Hill, Heather C. and Jurafsky, Dan and Piech, Chris , month = may, year =. Can. Educational Evaluation and Policy Analysis , publisher =. doi:10.3102/01623737231169270 , abstract =
-
[51]
Innovative language teaching and learning at university: enhancing participation and collaboration , isbn =
Goria, Cecilia and Speicher, Oranna and Stollhans, Sascha , month = jan, year =. Innovative language teaching and learning at university: enhancing participation and collaboration , isbn =
-
[52]
Opening-up classroom discourse to promote and enhance active, collaborative and cognitively-engaging student learning experiences , isbn =. 2016 , pages =. doi:10.14705/rpnet.2016.000400 , author =
-
[53]
Exploring
Mercer, Neil and Hodgkinson, Steve , month = sep, year =. Exploring
-
[54]
Exploring talk in school , author =
Culture, dialogue and learning:. Exploring talk in school , author =. 2008 , pages =
2008
-
[55]
and Borsheim-Black, Carlin and Caughlan, Samantha and Heintz, Anne , year =
Juzwik, Mary M. and Borsheim-Black, Carlin and Caughlan, Samantha and Heintz, Anne , year =. Inspiring dialogue:
-
[56]
International Journal of Educational Research , author =
What the discourse tells us:. International Journal of Educational Research , author =. 2008 , keywords =. doi:10.1016/j.ijer.2009.01.001 , abstract =
-
[57]
Manning, Christopher and Surdeanu, Mihai and Bauer, John and Finkel, Jenny and Bethard, Steven and McClosky, David , editor =. The. Proceedings of 52nd. 2014 , pages =. doi:10.3115/v1/P14-5010 , urldate =
-
[58]
Surdeanu, Mihai and Hicks, Tom and Valenzuela-Escárcega, Marco Antonio , editor =. Two. Proceedings of the 2015. 2015 , pages =. doi:10.3115/v1/N15-3001 , urldate =
-
[59]
Computers & Education , author =
Automatic classification of activities in classroom discourse , volume =. Computers & Education , author =. 2014 , keywords =. doi:10.1016/j.compedu.2014.05.010 , abstract =
-
[60]
and Bryk, Anthony S
Newmann, Fred M. and Bryk, Anthony S. and Nagaoka, Jenny K. , month = jan, year =. Authentic
-
[61]
and Donnelly, Patrick and Nystrand, Martin and D’Mello, Sidney K
Kelly, Sean and Olney, Andrew M. and Donnelly, Patrick and Nystrand, Martin and D’Mello, Sidney K. , month = oct, year =. Automatically. Educational Researcher , publisher =. doi:10.3102/0013189X18785613 , abstract =
-
[62]
Demszky, Dorottya and Hill, Heather , month = may, year =. The. doi:10.48550/arXiv.2211.11772 , abstract =
-
[63]
Ruiz-Rojas, Lena Ivannova and Acosta-Vargas, Patricia and De-Moreta-Llovet, Javier and Gonzalez-Rodriguez, Mario , month = jan, year =. Empowering. Sustainability , publisher =. doi:10.3390/su151511524 , abstract =
-
[64]
Predicting
Chen, Huanyi , month = jun, year =. Predicting
-
[65]
Wilson, Joseph and Pollard, Benjamin and Aiken, John M. and Caballero, Marcos D. and Lewandowski, H. J. , month = jun, year =. Classification of open-ended responses to a research-based assessment using natural language processing , volume =. Physical Review Physics Education Research , publisher =. doi:10.1103/PhysRevPhysEducRes.18.010141 , abstract =
-
[66]
World Journal of Surgery , author =
Leveraging. World Journal of Surgery , author =. 2023 , pages =. doi:10.1007/s00268-023-07167-2 , language =
-
[67]
Artificial Intelligence Review , author =
Intelligent tutoring systems: an overview , volume =. Artificial Intelligence Review , author =. 1990 , keywords =. doi:10.1007/BF00168958 , abstract =
-
[68]
Corbett, Albert T. and Koedinger, Kenneth R. and Anderson, John R. , editor =. Chapter 37 -. Handbook of. 1997 , pages =. doi:10.1016/B978-044481862-1.50103-5 , abstract =
-
[69]
Mousavinasab, Elham and Zarifsanaiey, Nahid and R. Niakan Kalhori, Sharareh and Rakhshan, Mahnaz and Keikha, Leila and Ghazi Saeedi, Marjan , month = jan, year =. Intelligent tutoring systems: a systematic review of characteristics, applications, and evaluation methods , volume =. Interactive Learning Environments , publisher =. doi:10.1080/10494820.2018....
-
[71]
doi:10.48550/arXiv.2309.03241 , abstract =
Yang, Zhen and Ding, Ming and Lv, Qingsong and Jiang, Zhihuan and He, Zehai and Guo, Yuyi and Bai, Jinfeng and Tang, Jie , month = sep, year =. doi:10.48550/arXiv.2309.03241 , abstract =
-
[72]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , month = may, year =. doi:10.48550/arXiv.1810.04805 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805
-
[73]
Wang, Yidong and Yu, Zhuohao and Zeng, Zhengran and Yang, Linyi and Wang, Cunxiang and Chen, Hao and Jiang, Chaoya and Xie, Rui and Wang, Jindong and Xie, Xing and Ye, Wei and Zhang, Shikun and Zhang, Yue , month = jun, year =. doi:10.48550/arXiv.2306.05087 , abstract =
-
[74]
Cochran, Keith and Cohn, Clayton and Rouet, Jean Francois and Hastings, Peter , editor =. Improving. Artificial. 2023 , keywords =. doi:10.1007/978-3-031-36272-9_18 , abstract =
-
[75]
Citizenship and
Torney-Purta, Judith and Lehmann, Rainer and Oswald, Hans and Schulz, Wolfram , year =. Citizenship and
-
[76]
Read, Tony , month = jul, year =. Where
-
[77]
Content. AERA Open , author =. 2020 , pages =. doi:10.1177/2332858420940312 , abstract =
-
[78]
Open educational resources: education for the world? , volume =
Richter, Thomas and McPherson, Maggie , month = aug, year =. Open educational resources: education for the world? , volume =. Distance Education , publisher =. doi:10.1080/01587919.2012.692068 , abstract =
-
[79]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , month = jul, year =. doi:10.48550/arXiv.1907.11692 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.11692 1907
-
[80]
Gozalo-Brizuela, Roberto and Garrido-Merchan, Eduardo C. , month = jan, year =. doi:10.48550/arXiv.2301.04655 , abstract =
-
[81]
Galactica: A Large Language Model for Science
Taylor, Ross and Kardas, Marcin and Cucurull, Guillem and Scialom, Thomas and Hartshorn, Anthony and Saravia, Elvis and Poulton, Andrew and Kerkez, Viktor and Stojnic, Robert , month = nov, year =. Galactica:. doi:10.48550/arXiv.2211.09085 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09085
-
[82]
Zhang, Chaoning and Zhang, Chenshuang and Li, Chenghao and Qiao, Yu and Zheng, Sheng and Dam, Sumit Kumar and Zhang, Mengchun and Kim, Jung Uk and Kim, Seong Tae and Choi, Jinwoo and Park, Gyeong-Moon and Bae, Sung-Ho and Lee, Lik-Hang and Hui, Pan and Kweon, In So and Hong, Choong Seon , month = apr, year =. One. doi:10.48550/arXiv.2304.06488 , abstract =
-
[83]
Borji, Ali , month = apr, year =. A. doi:10.48550/arXiv.2302.03494 , abstract =
-
[84]
Extracting
Carlini, Nicholas and Tramèr, Florian and Wallace, Eric and Jagielski, Matthew and Herbert-Voss, Ariel and Lee, Katherine and Roberts, Adam and Brown, Tom and Song, Dawn and Erlingsson, Úlfar and Oprea, Alina and Raffel, Colin , year =. Extracting
-
[85]
Ethical and social risks of harm from Language Models
Weidinger, Laura and Mellor, John and Rauh, Maribeth and Griffin, Conor and Uesato, Jonathan and Huang, Po-Sen and Cheng, Myra and Glaese, Mia and Balle, Borja and Kasirzadeh, Atoosa and Kenton, Zac and Brown, Sasha and Hawkins, Will and Stepleton, Tom and Biles, Courtney and Birhane, Abeba and Haas, Julia and Rimell, Laura and Hendricks, Lisa Anne and Is...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.04359
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.