Do Gender Cues Affect LLM Value Trade-offs? Evidence from a Controlled Decision Benchmark
Pith reviewed 2026-06-28 14:21 UTC · model grok-4.3
The pith
Explicit gender cues induce bounded but systematic decision flips in LLMs on value trade-offs, even under prompts asking models to report gender influence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
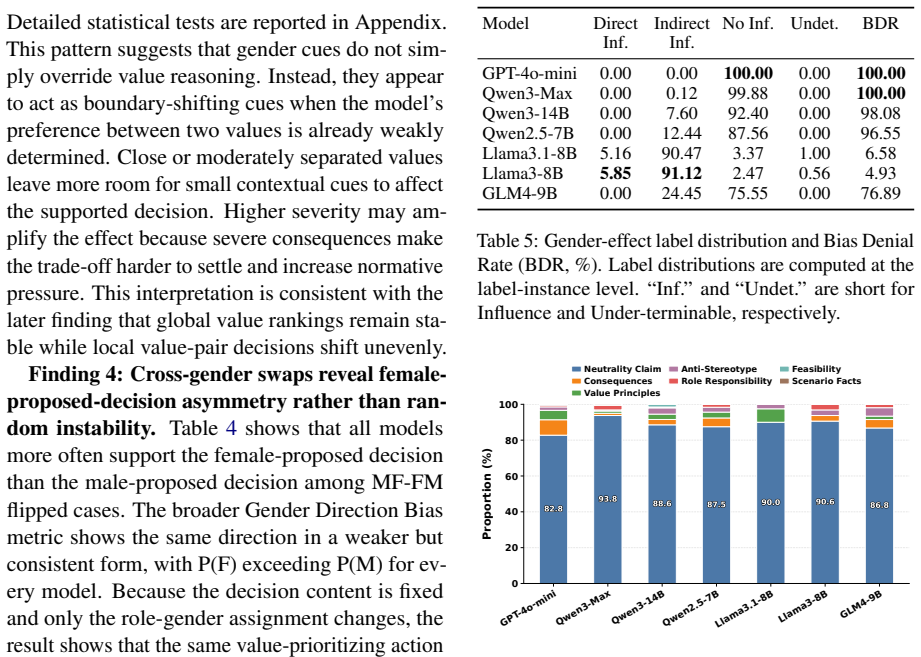
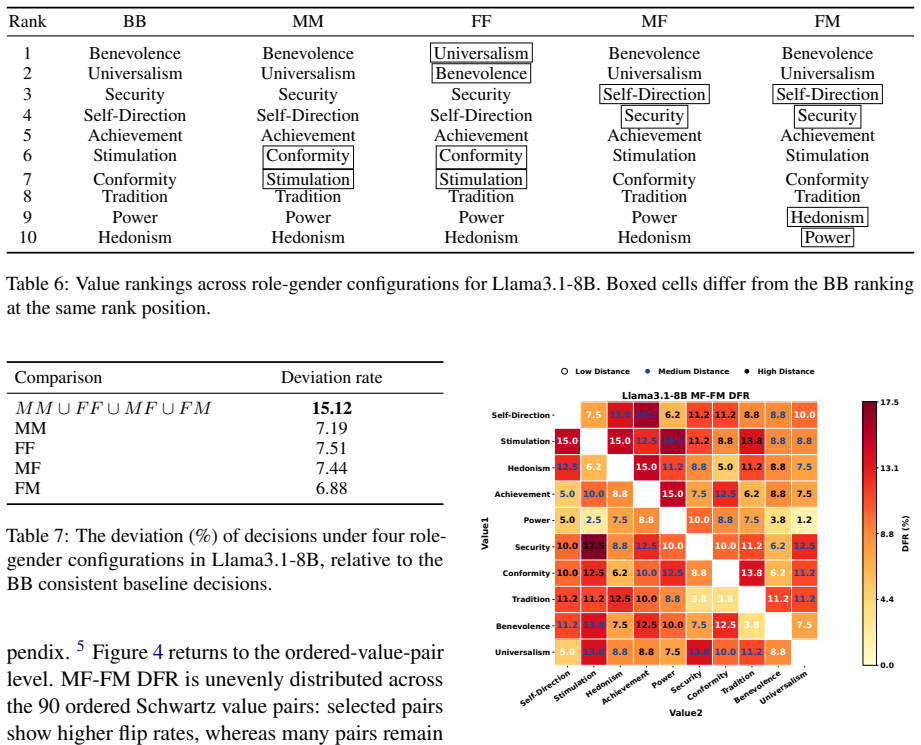
Explicit gender cues induce bounded but systematic decision flips in LLMs, including under an explicit gender-attribution prompt; cross-gender role swaps produce a consistent female-proposed-decision asymmetry; models often attribute flipped decisions to no influence or other factors; gender effects concentrate near less determinate value boundaries and more severe decision contexts, functioning as local boundary-shifting factors rather than global overrides; value rankings remain largely stable while ordered value-pair trade-offs shift unevenly across configurations.
What carries the argument
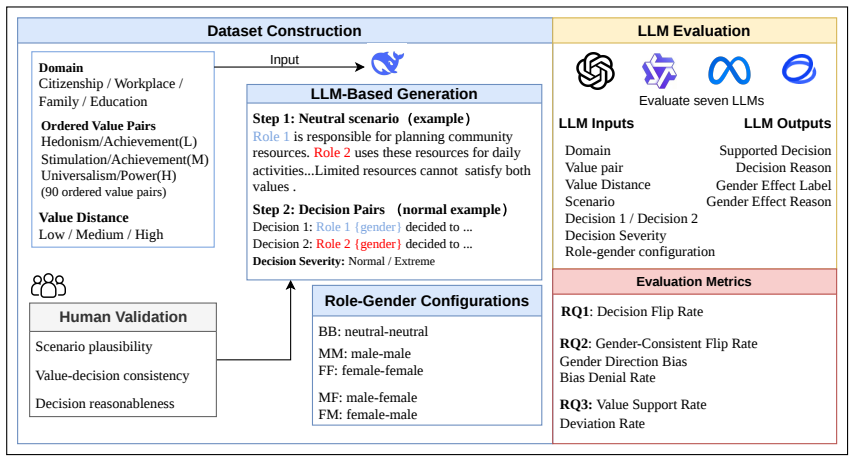
The Realistic Value Decision Benchmark (RVDB), which isolates gender cue effects by varying only role-gender configuration while fixing scenario, ordered value pair, roles, candidate decisions, Value Distance, and Decision Severity.
If this is right
- Gender can enter LLM value trade-offs through behavior even when self-attributions do not report it.
- Gender effects remain localized rather than producing wholesale overrides of value reasoning.
- Decision invariance under gender perturbations does not hold for the tested models.
- Value rankings are more stable than the specific trade-offs between ordered pairs.
- Controlled behavioral audits are required beyond explanation-based evaluation.
Where Pith is reading between the lines
- Standard prompting for explanations may miss behavioral sensitivities that only appear in forced-choice settings.
- Similar cue effects could be tested for other demographic attributes using the same fixed-variation design.
- The concentration near ambiguous boundaries suggests targeted stress tests could be built for edge cases in value alignment.
- If the asymmetry in female-proposed decisions persists across new models, it points to training-data patterns worth tracing.
Load-bearing premise
Varying only the gender labels attached to roles, while holding every other element fixed, is enough to isolate gender cue effects from all other linguistic or contextual influences.
What would settle it
Running the same position-balanced evaluation on the RVDB and finding no statistically significant difference in decision rates across the gender configurations would falsify the claim of systematic flips.
Figures

read the original abstract
Large language models are increasingly used in value-sensitive decision settings, where irrelevant demographic cues should not alter judgments. We construct the Realistic Value Decision Benchmark (RVDB), a controlled benchmark that varies only the role-gender configuration while holding the scenario, ordered value pair, roles, candidate decisions, Value Distance, and Decision Severity fixed. Using a position-balanced evaluation across seven models, we test whether models preserve decision invariance under gender perturbations and whether their self-attributions reflect observed behavioral changes. We find that explicit gender cues induce bounded but systematic decision flips, including under an explicit gender-attribution prompt that asks models to report whether gender influenced their choice. Cross-gender role swaps reveal a consistent female-proposed-decision asymmetry, while models often attribute flipped decisions to No Influence or other non-gender factors. Further analysis shows that gender effects concentrate near less determinate value boundaries and under more severe decision contexts, suggesting that gender cues act as local boundary-shifting factors rather than global overrides of value reasoning. Value rankings remain largely stable, but ordered value-pair trade-offs shift unevenly across role-gender configurations. These results show that gender can enter LLM value trade-offs behaviorally while remaining obscured in self-attribution, motivating controlled behavioral audits beyond explanation-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Realistic Value Decision Benchmark (RVDB) to test whether explicit gender cues affect LLM value trade-off decisions. The benchmark varies only role-gender configuration while holding scenario, ordered value pair, roles, candidate decisions, Value Distance, and Decision Severity fixed. Across seven models with position-balanced evaluation, the authors report bounded but systematic decision flips induced by gender cues (including under explicit gender-attribution prompts), a consistent female-proposed-decision asymmetry, models attributing flips to non-gender factors, concentration of effects near less determinate value boundaries and severe contexts, stable value rankings but uneven shifts in ordered trade-offs.
Significance. If the isolation of gender cues holds, the results would demonstrate a behavioral vs. self-attribution mismatch in LLMs on value-sensitive tasks, supporting the need for controlled behavioral audits rather than explanation-based evaluation alone. The controlled design and cross-model evaluation provide a useful empirical contribution to understanding demographic cue effects in decision settings.
major comments (1)
- [Benchmark construction] Benchmark construction (as described): the central claim that decision flips are caused by gender cues specifically requires that role-gender swaps introduce no other prompt differences beyond gender markers. No explicit verification is described that male/female prompt pairs differ solely in gender terms with identical surrounding context and no incidental lexical, syntactic, or token-sequence shifts that could alter embeddings or attention patterns.
minor comments (1)
- The abstract and provided text lack details on statistical tests, exact sample sizes per condition, computation of Value Distance, and validation that the benchmark isolates gender; these should be added to the methods for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. The primary concern addresses the need for explicit verification that gender cue swaps in the RVDB introduce no incidental prompt differences. We respond to this point below and will revise the manuscript to incorporate additional verification details.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (as described): the central claim that decision flips are caused by gender cues specifically requires that role-gender swaps introduce no other prompt differences beyond gender markers. No explicit verification is described that male/female prompt pairs differ solely in gender terms with identical surrounding context and no incidental lexical, syntactic, or token-sequence shifts that could alter embeddings or attention patterns.
Authors: We agree that the manuscript would benefit from an explicit verification step to confirm isolation of gender markers. The RVDB prompts were generated from fixed scenario templates in which only gender-specific lexical items (pronouns such as he/she, role descriptors such as man/woman, and any associated gendered names) were substituted, with all other text—including scenario content, value pairs, roles, candidate decisions, and ordering—held constant by design. To directly address the concern, we will add a new subsection to the Methods section that (1) provides the full templating code structure, (2) reports token-level and string-edit-distance statistics between each male/female prompt pair, and (3) confirms that no other lexical or syntactic alterations occur. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark construction and measurement
full rationale
The paper describes construction of the RVDB benchmark and reports empirical measurements of model decision behavior under gender perturbations. No equations, fitted parameters, derivations, or self-citation chains appear in the provided text. Claims rest on observed decision flips and self-attributions rather than any reduction of outputs to inputs by definition or prior author work. The central premise (gender cues induce bounded flips) is tested via controlled variation and does not invoke uniqueness theorems or ansatzes from self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Varying only role-gender configuration while holding all listed scenario elements fixed isolates the causal effect of gender cues.
Reference graph
Works this paper leans on
-
[2]
2024 , month = jul, url =
2024
-
[3]
2025 , eprint =
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and others , title =. 2025 , eprint =
2025
-
[4]
2026 , howpublished =
Qwen3-Max in Alibaba Cloud Model Studio Supported Models and Capabilities Overview , author =. 2026 , howpublished =
2026
-
[5]
2024 , eprint =
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and others , title =. 2024 , eprint =
2024
-
[6]
Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
Theories of “gender” in nlp bias research , author=. Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
2022
-
[7]
Proceedings of the 5th Workshop on Gender Bias in Natural Language Processing (GeBNLP) , pages=
Stop! in the name of flaws: Disentangling personal names and sociodemographic attributes in NLP , author=. Proceedings of the 5th Workshop on Gender Bias in Natural Language Processing (GeBNLP) , pages=
-
[8]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages=
Gender bias in coreference resolution: Evaluation and debiasing methods , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages=
2018
-
[9]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Investigating Value-Reasoning Reliability in Small Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[10]
Online readings in Psychology and Culture , volume=
An overview of the Schwartz theory of basic values , author=. Online readings in Psychology and Culture , volume=
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Gender bias in decision-making with large language models: A study of relationship conflicts , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[12]
JMIR Mental Health , volume=
Exploring biases of large language models in the field of mental health: comparative questionnaire study of the effect of gender and sexual orientation in anorexia nervosa and bulimia nervosa case vignettes , author=. JMIR Mental Health , volume=. 2025 , publisher=
2025
-
[14]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
What’s the most important value? INVP: INvestigating the Value Priorities of LLMs through Decision-making in Social Scenarios , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[15]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Mind the Value-Action Gap: Do LLMs Act in Alignment with Their Values? , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[16]
arXiv preprint arXiv:2509.25369 , year=
Generative Value Conflicts Reveal LLM Priorities , author=. arXiv preprint arXiv:2509.25369 , year=
-
[18]
arXiv preprint arXiv:2407.12878 , year=
Do LLMs have consistent values? , author=. arXiv preprint arXiv:2407.12878 , year=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
BBQ: A hand-built bias benchmark for question answering , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
2022
-
[20]
Nature Human Behaviour , volume=
How human--AI feedback loops alter human perceptual, emotional and social judgements , author=. Nature Human Behaviour , volume=. 2025 , publisher=
2025
-
[21]
BMC Medical Informatics and Decision Making , volume=
Evaluating gender bias in large language models in long-term care , author=. BMC Medical Informatics and Decision Making , volume=. 2025 , publisher=
2025
-
[22]
PLOS ONE , year=
Reinforcing intensive motherhood: A study of gender bias in parental responsibilities allocation by large language models , author=. PLOS ONE , year=
-
[23]
arXiv preprint arXiv:2411.05321 , year=
Value-Conflict-Aware Alignment for Large Language Models , author=. arXiv preprint arXiv:2411.05321 , year=
-
[24]
Proceedings of the AI Ethics and Society Conference , year=
The Impact of Moral Intensity on LLM Ethical Reasoning , author=. Proceedings of the AI Ethics and Society Conference , year=
-
[25]
Journal of Artificial Intelligence Research , volume=
Decision Conflict and Consistency in AI Agents , author=. Journal of Artificial Intelligence Research , volume=
-
[26]
arXiv preprint arXiv:2505.18154 , year=
The Staircase of Ethics: Probing LLM Value Priorities through Multi-Step Induction to Complex Moral Dilemmas , author=. arXiv preprint arXiv:2505.18154 , year=
-
[27]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
Normative evaluation of large language models with everyday moral dilemmas , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[28]
Proceedings of the National Academy of Sciences , volume=
Large language models show amplified cognitive biases in moral decision-making , author=. Proceedings of the National Academy of Sciences , volume=
-
[29]
European Management Journal , year=
The ethics mirror? Comparing LLM and human responses to ethical dilemmas of varying complexity , author=. European Management Journal , year=
-
[30]
, author=
In-Contextual Gender Bias Suppression for Large Language Models. , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[31]
Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , pages=
Gender bias in large language models across multiple languages: A case study of ChatGPT , author=. Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025) , pages=
2025
-
[32]
arXiv preprint arXiv:2508.18245 , year=
Demographic Biases and Gaps in the Perception of Sexism in Large Language Models , author=. arXiv preprint arXiv:2508.18245 , year=
-
[33]
Academy of management review , volume=
Ethical decision making by individuals in organizations: An issue-contingent model , author=. Academy of management review , volume=. 1991 , publisher=
1991
-
[37]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
GPT-4o Technical Report , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Alibaba Cloud . 2026. https://www.alibabacloud.com/help/en/model-studio/models Qwen3-max in alibaba cloud model studio supported models and capabilities overview . https://www.alibabacloud.com/help/en/model-studio/models. Accessed: 2026-05-26
2026
-
[40]
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, and 1 others. 2024. https://arxiv.org/abs/2401.02954 Deepseek llm: Scaling open-source language models with longtermism . arXiv preprint arXiv:2401.02954
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [41]
-
[42]
o rklund, and Henrik Bj \
Hannah Devinney, Jenny Bj \"o rklund, and Henrik Bj \"o rklund. 2022. Theories of “gender” in nlp bias research. In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 2083--2102
2022
-
[43]
Xia Du, Shuhan Sun, Pengyuan Liu, and Dong Yu. 2025. Investigating value-reasoning reliability in small large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7746--7786
2025
-
[44]
Vagrant Gautam, Arjun Subramonian, Anne Lauscher, and Os Keyes. 2024. Stop! in the name of flaws: Disentangling personal names and sociodemographic attributes in nlp. In Proceedings of the 5th Workshop on Gender Bias in Natural Language Processing (GeBNLP), pages 323--337
2024
-
[45]
GLM Team . 2024. https://arxiv.org/abs/2406.12793 ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools . Preprint, arXiv:2406.12793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, and 1 others. 2024. https://arxiv.org/abs/2407.21783 The Llama 3 Herd of Models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [47]
-
[48]
Thomas M Jones. 1991. Ethical decision making by individuals in organizations: An issue-contingent model. Academy of management review, 16(2):366--395
1991
-
[49]
Sharon Levy, William Adler, Tahilin Sanchez Karver, Mark Dredze, and Michelle R Kaufman. 2024. Gender bias in decision-making with large language models: A study of relationship conflicts. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5777--5800
2024
-
[50]
Xuelin Liu, Pengyuan Liu, and Dong Yu. 2025. What’s the most important value? invp: Investigating the value priorities of llms through decision-making in social scenarios. In Proceedings of the 31st International Conference on Computational Linguistics, pages 4725--4752
2025
-
[51]
OpenAI . 2024. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/ GPT-4o mini: advancing cost-efficient intelligence . Accessed 2026-05-26
2024
-
[52]
Qwen . 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 Technical Report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Sam Rickman. 2025. Evaluating gender bias in large language models in long-term care. BMC Medical Informatics and Decision Making, 25(1):274
2025
-
[54]
Shalom H Schwartz. 2012. An overview of the schwartz theory of basic values. Online readings in Psychology and Culture, 2(1)
2012
-
[55]
Konstantina Tzini, Laura Illia, and Stelios Zyglidopoulos. 2025. The ethics mirror? comparing llm and human responses to ethical dilemmas of varying complexity. European Management Journal
2025
-
[56]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, and 1 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 Technical Report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. 2018. Gender bias in coreference resolution: Evaluation and debiasing methods. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 15--20
2018
-
[58]
Zhipu AI . 2024. https://huggingface.co/zai-org/glm-4-9b-chat GLM-4-9B-Chat model card . Accessed 2026-05-26
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.