Evaluating Document-Tuned Transformer Representations for Person-level Mental Health Assessment
Pith reviewed 2026-06-26 14:20 UTC · model grok-4.3
The pith
Document-tuned transformers improve person-level mental health predictions from text by 13.4 percent over base models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
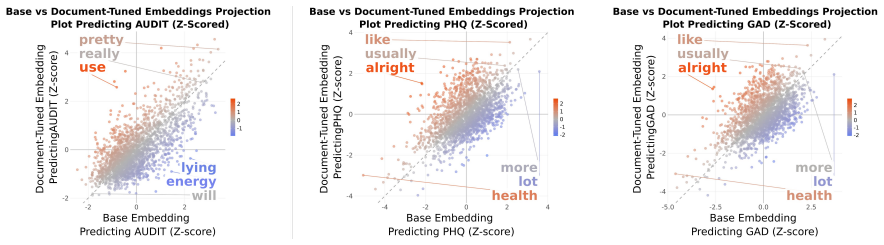
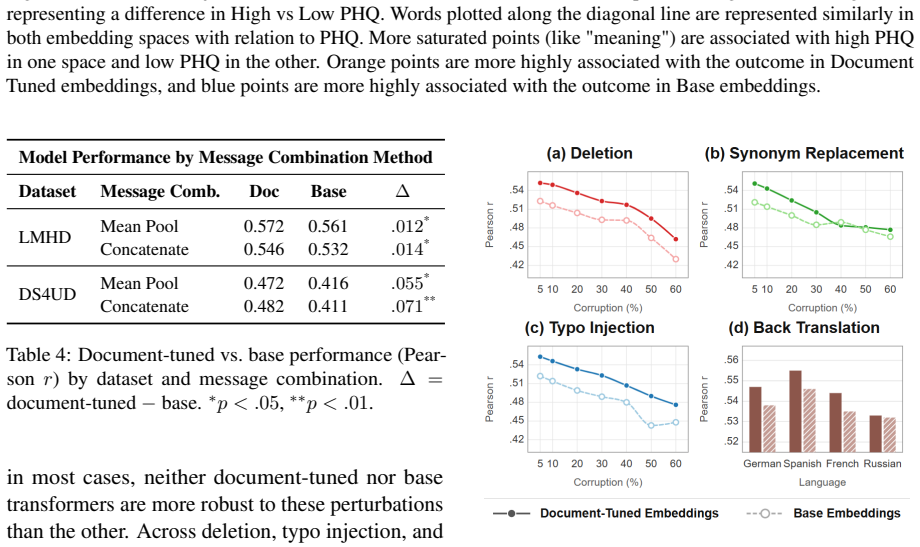
Architecturally matched document-tuned transformers, further contrastively fine-tuned at the document level, produce a 13.4 percent increase in Pearson r for person-level mental health outcomes compared with base transformers, while remaining more accurate under word deletion, synonym replacement, typo injection, and back translation; hedged language is more characteristic of outcomes captured by the document-tuned embeddings.
What carries the argument
Document-tuned transformers obtained through document-level contrastive fine-tuning, which explicitly train representations to aggregate meaning across multiple messages from one individual.
If this is right
- Prediction pipelines for longitudinal psychological data should prefer document-tuned embeddings when aggregation across an individual's messages is required.
- Document-tuned models may reduce sensitivity to common text noise such as typos or rephrasing in deployed mental health assessments.
- Hedged language markers become more predictive of outcomes when using document-tuned representations, altering which linguistic signals are attended to.
- Representation choice directly affects measured accuracy in person-level mental health tasks, so baseline comparisons should include document-tuned variants.
Where Pith is reading between the lines
- The same document-tuning approach could be tested on other tasks that require stable person-level profiles from repeated observations, such as user behavior modeling.
- If the robustness gains hold, document-tuned models might lower the data-cleaning burden in real-world text-based screening applications.
- Future experiments could isolate whether the benefit comes mainly from the contrastive objective or from the additional training steps on document pairs.
Load-bearing premise
Performance differences between the two model types arise from the document-level contrastive fine-tuning step rather than from uncontrolled differences in training data or hyperparameters.
What would settle it
A replication in which base and document-tuned models are trained on identical data with identical hyperparameters and the document-tuned versions show no accuracy gain or no robustness advantage under the same perturbations.
Figures
read the original abstract
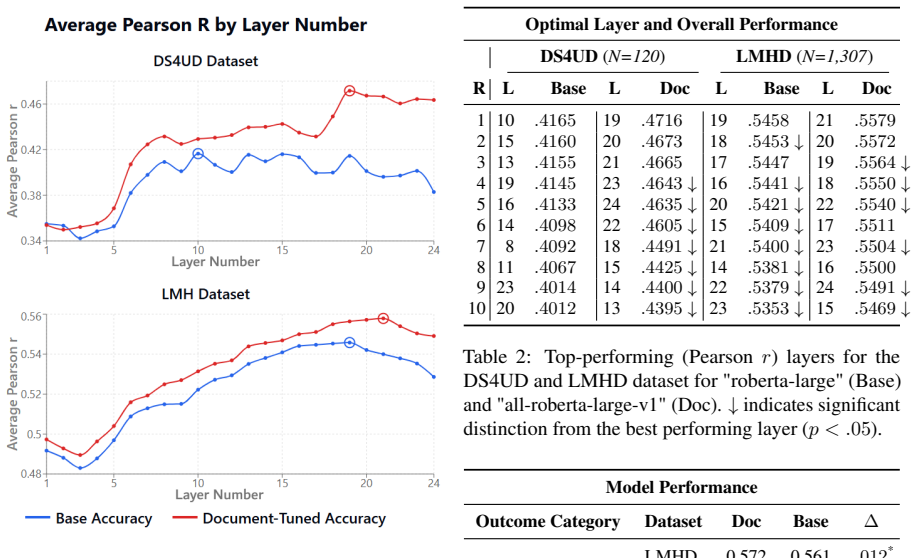
Person-level psychological assessment requires aggregating meaning across many messages from the same individual, a task that document-level training objectives were not explicitly designed for. We present a systematic, empirical comparison between architecturally matched traditional (a) base-transformers and (b) document-tuned-transformers (further contrastively fine-tuned at the document-level, sometimes referred to as "sentence transformers") under otherwise identical conditions. Comparing layer-wise and overall performance across two longitudinal mental health and psychological datasets, we find document-tuned models demonstrated a consistent improvement over base representations (increase in Pearson r of 13.4%, p=.015). Robustness analyses revealed document-tuned models remained more accurate under perturbations to word deletion, synonym replacement, typo injection, and back translation. Further, hedged language (e.g., `usually') was more characteristic of outcomes in document-tuned embeddings while abundance (e.g., `lot') was more characteristic of base-transformers, suggesting document-tuned models may better capture uncertainty. These results suggest representation choice impacts mental health prediction, document-tuned models often being more adept.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical comparison of architecturally matched base transformer representations versus document-tuned (contrastively fine-tuned) transformer representations for aggregating person-level mental health and psychological assessments from two longitudinal datasets. It reports a consistent 13.4% improvement in Pearson r (p=0.015) for document-tuned models, superior robustness under word deletion, synonym replacement, typo injection, and back-translation perturbations, and differential capture of hedged versus abundance language, concluding that representation choice impacts mental health prediction.
Significance. If the performance difference can be isolated to the document-level contrastive objective, the work provides evidence that sentence-transformer-style tuning can improve both accuracy and robustness in person-level mental health NLP tasks and may better encode uncertainty-related language. The perturbation analyses and post-hoc linguistic characterization add concrete value beyond the correlation metric.
major comments (1)
- [Methods] Methods section: the central attribution of the 13.4% Pearson r gain and robustness improvements to document-level contrastive fine-tuning rests on the claim of 'architecturally matched' models tested 'under otherwise identical conditions.' The manuscript does not demonstrate explicit controls ensuring the base models were retrained on identical corpora with matching optimization schedules (learning rate, batch size, epochs, random seeds), which is required to isolate the effect from potential differences in pretraining data or hyperparameters.
minor comments (2)
- [Abstract] Abstract and results: dataset sizes, exact number of documents per person, and the precise aggregation procedure from document embeddings to person-level scores are not stated, limiting reproducibility of the reported correlations.
- [Results] Results: the layer-wise analysis would benefit from reporting the specific layers compared and any statistical correction for multiple comparisons across layers.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need for greater methodological clarity. We address the single major comment below.
read point-by-point responses
-
Referee: [Methods] Methods section: the central attribution of the 13.4% Pearson r gain and robustness improvements to document-level contrastive fine-tuning rests on the claim of 'architecturally matched' models tested 'under otherwise identical conditions.' The manuscript does not demonstrate explicit controls ensuring the base models were retrained on identical corpora with matching optimization schedules (learning rate, batch size, epochs, random seeds), which is required to isolate the effect from potential differences in pretraining data or hyperparameters.
Authors: The base models are the standard pretrained checkpoints released by their original authors; the document-tuned models are initialized from exactly those same checkpoints and then further trained with the contrastive document-level objective. Architectural identity (model family, hidden size, tokenizer, layer count) is therefore guaranteed by construction. The phrase 'under otherwise identical conditions' refers to the downstream evaluation protocol, person-level aggregation method, datasets, and inference settings being held fixed. We did not retrain the base checkpoints on the contrastive corpora, as doing so would change the comparison from 'pretrained vs. document-tuned' to 'two differently fine-tuned models.' We will revise the Methods section to state the exact model versions and sources, to describe the fine-tuning procedure in full, and to note explicitly that the original pretraining corpora differ by design. revision: yes
Circularity Check
No circularity: empirical comparison with direct measurements
full rationale
The paper reports an empirical evaluation of model representations on mental health prediction tasks. It compares base transformers and document-tuned transformers under matched conditions, measuring Pearson r (13.4% increase, p=.015) and robustness under perturbations. No equations, derivations, or predictions are presented that reduce to fitted inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear. The central claims rest on observed performance differences rather than any self-referential reduction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
JMIR mental health , volume=
Large language models for mental health applications: systematic review , author=. JMIR mental health , volume=. 2024 , publisher=
2024
-
[9]
IEEE Access , volume=
Harnessing the power of hugging face transformers for predicting mental health disorders in social networks , author=. IEEE Access , volume=. 2024 , publisher=
2024
-
[10]
NPJ digital medicine , volume=
Natural language processing applied to mental illness detection: a narrative review , author=. NPJ digital medicine , volume=. 2022 , publisher=
2022
-
[11]
arXiv preprint arXiv:1907.11692 , year=
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
Pith/arXiv arXiv 1907
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[13]
arXiv preprint arXiv:1908.10084 , year=
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. arXiv preprint arXiv:1908.10084 , year=
Pith/arXiv arXiv 1908
-
[14]
Information , volume=
Detection of depression severity in social media text using transformer-based models , author=. Information , volume=. 2025 , publisher=
2025
-
[15]
Frontiers in Research Metrics and Analytics , volume=
Depression, anxiety, and burnout in academia: topic modeling of PubMed abstracts , author=. Frontiers in Research Metrics and Analytics , volume=. 2023 , publisher=
2023
-
[16]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[17]
2024 , url=
Open Source Strikes Bread - New Fluffy Embeddings Model , author=. 2024 , url=
2024
-
[18]
arXiv preprint arXiv:2309.12871 , year=
AnglE-optimized Text Embeddings , author=. arXiv preprint arXiv:2309.12871 , year=
-
[19]
Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology , pages=
Overview of the CLPsych 2022 shared task: Capturing moments of change in longitudinal user posts , author=. Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology , pages=
2022
-
[20]
Proceedings of the 10th Workshop on Computational Linguistics and Clinical Psychology (CLPsych 2025) , pages=
Overview of the clpsych 2025 shared task: Capturing mental health dynamics from social media timelines , author=. Proceedings of the 10th Workshop on Computational Linguistics and Clinical Psychology (CLPsych 2025) , pages=
2025
-
[21]
Big Data and Cognitive Computing , volume=
Sentiment Informed Sentence BERT-Ensemble Algorithm for Depression Detection , author=. Big Data and Cognitive Computing , volume=. 2024 , publisher=
2024
-
[22]
Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology , pages=
Detecting moments of change and suicidal risks in longitudinal user texts using multi-task learning , author=. Proceedings of the Eighth Workshop on Computational Linguistics and Clinical Psychology , pages=
-
[23]
Computer Science Review , volume=
A survey on detecting mental disorders with natural language processing: Literature review, trends and challenges , author=. Computer Science Review , volume=. 2024 , publisher=
2024
-
[24]
Archives of Computational Methods in Engineering , volume=
Mental health analysis in social media posts: a survey , author=. Archives of Computational Methods in Engineering , volume=
-
[25]
Plos one , volume=
Language-based EMA assessments help understand problematic alcohol consumption , author=. Plos one , volume=. 2024 , publisher=
2024
-
[26]
arXiv preprint arXiv:1905.05950 , year=
BERT rediscovers the classical NLP pipeline , author=. arXiv preprint arXiv:1905.05950 , year=
arXiv 1905
-
[27]
ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
What does BERT learn about the structure of language? , author=. ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
2019
-
[28]
arXiv preprint arXiv:1903.08855 , year=
Linguistic knowledge and transferability of contextual representations , author=. arXiv preprint arXiv:1903.08855 , year=
Pith/arXiv arXiv 1903
-
[29]
Transactions of the association for computational linguistics , volume=
A primer in BERTology: What we know about how BERT works , author=. Transactions of the association for computational linguistics , volume=
-
[30]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Systematic Evaluation of Auto-Encoding and Large Language Model Representations for Capturing Author States and Traits , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[31]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[32]
sentence-transformers/all-roberta-large-v1 , author =
-
[33]
PLoS one , volume=
The ‘Maltreatment and Abuse Chronology of Exposure’(MACE) scale for the retrospective assessment of abuse and neglect during development , author=. PLoS one , volume=. 2015 , publisher=
2015
-
[34]
Journal of general internal medicine , volume=
The PHQ-9: validity of a brief depression severity measure , author=. Journal of general internal medicine , volume=. 2001 , publisher=
2001
-
[35]
, author=
Development and validation of brief measures of positive and negative affect: the PANAS scales. , author=. Journal of personality and social psychology , volume=. 1988 , publisher=
1988
-
[36]
Addiction , volume=
Development of the alcohol use disorders identification test (AUDIT): WHO collaborative project on early detection of persons with harmful alcohol consumption-II , author=. Addiction , volume=. 1993 , publisher=
1993
-
[37]
Archives of internal medicine , volume=
A brief measure for assessing generalized anxiety disorder: the GAD-7 , author=. Archives of internal medicine , volume=. 2006 , publisher=
2006
-
[38]
, author=
Development and validation of the Inventory of Depression and Anxiety Symptoms (IDAS). , author=. Psychological assessment , volume=. 2007 , publisher=
2007
-
[39]
Journal of health and social behavior , pages=
A global measure of perceived stress , author=. Journal of health and social behavior , pages=. 1983 , publisher=
1983
-
[40]
Journal of personality assessment , volume=
The satisfaction with life scale , author=. Journal of personality assessment , volume=. 1985 , publisher=
1985
-
[41]
2010 , publisher=
Measuring health and disability: Manual for WHO disability assessment schedule WHODAS 2.0 , author=. 2010 , publisher=
2010
-
[42]
Social Indicators Research , volume=
The harmony in life scale complements the satisfaction with life scale: Expanding the conceptualization of the cognitive component of subjective well-being , author=. Social Indicators Research , volume=. 2016 , publisher=
2016
-
[43]
, author=
The next Big Five Inventory (BFI-2): Developing and assessing a hierarchical model with 15 facets to enhance bandwidth, fidelity, and predictive power. , author=. Journal of personality and social psychology , volume=. 2017 , publisher=
2017
-
[44]
European addiction research , volume=
Evaluation of the Drug Use Disorders Identification Test (DUDIT) in criminal justice and detoxification settings and in a Swedish population sample , author=. European addiction research , volume=. 2004 , publisher=
2004
-
[45]
, author=
Reexamining the circumplex model of affect. , author=. Journal of personality and social psychology , volume=. 2000 , publisher=
2000
-
[46]
Journal of cross-cultural psychology , volume=
Development and validation of an internationally reliable short-form of the positive and negative affect schedule (PANAS) , author=. Journal of cross-cultural psychology , volume=. 2007 , publisher=
2007
-
[47]
Alahmari et al
Large language models robustness against perturbation: S. Alahmari et al. , author=. Scientific Reports , year=
-
[48]
, author=
The text-package: An R-package for analyzing and visualizing human language using natural language processing and transformers. , author=. Psychological methods , volume=. 2023 , publisher=
2023
-
[49]
Ethayarajh, Kawin. How Contextual are Contextualized Word Representations? C omparing the Geometry of BERT , ELM o, and GPT -2 Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1006
-
[50]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
Isotropic representation can improve dense retrieval , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2023 , organization=
2023
-
[51]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi. S im CSE : Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.552
-
[52]
Proceedings of the sixth workshop on computational linguistics and clinical psychology , pages=
CLPsych 2019 shared task: Predicting the degree of suicide risk in Reddit posts , author=. Proceedings of the sixth workshop on computational linguistics and clinical psychology , pages=
2019
-
[53]
Assessment , pages=
Natural language response formats for assessing depression and worry with large language models: A sequential evaluation with model pre-registration , author=. Assessment , pages=. 2025 , publisher=
2025
-
[54]
Proceedings of the 10th Workshop on Computational Linguistics and Clinical Psychology (CLPsych 2025) , pages=
Linking language-based distortion detection to mental health outcomes , author=. Proceedings of the 10th Workshop on Computational Linguistics and Clinical Psychology (CLPsych 2025) , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.