Grouped Reverse Importance Sampling for the Partition Function
Pith reviewed 2026-06-26 02:58 UTC · model grok-4.3
The pith
Weight functions depending only on total group energy are sufficient for optimal grouped reverse importance sampling of partition functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
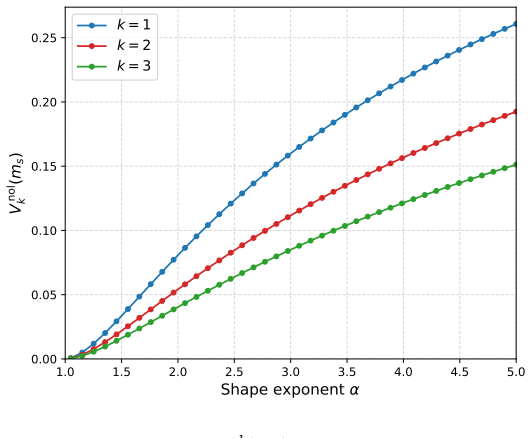
The central finding is that without loss of optimality, it is sufficient to seek weight functions that depend only on the total energy sum_i U(x_i) of the group. A simple identity relates the normalized MSE to the chi-squared divergence between the joint-weight distribution and the distribution of the k-fold sum of independent energies. For k=2 and k=3, the MSE associated with non-overlapping groups is reduced by 20--65% across three examples. Product-form weight functions always worsen the MSE.
What carries the argument
Group-energy weight functions, which assign a weight based only on the sum of energies within each group of k samples.
If this is right
- Any weight function that improves on ordinary single-sample RIS must couple the components of the group rather than using a product form.
- Non-overlapping grouped RIS with energy-sum weights reduces MSE by 20-65% for k=2 and k=3 in the tested cases.
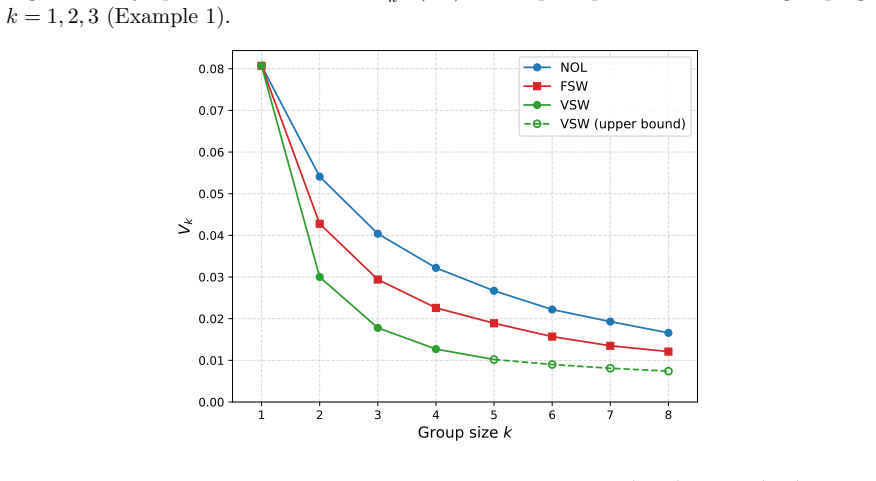
- Fixed-weight sliding window grouping improves on non-overlapping grouping.
- Variable-weight sliding window grouping improves even further than the fixed-weight version.
Where Pith is reading between the lines
- The energy-sum restriction may allow closed-form optimization of the weights for specific energy distributions.
- This grouping technique could be combined with other variance reduction methods in Monte Carlo sampling.
- Extensions to continuous state spaces or non-Boltzmann distributions might follow similar optimality arguments.
Load-bearing premise
The samples are independent draws from the Boltzmann distribution and a tractable joint weight function exists that can be optimized via chi-squared divergence to the k-fold energy sum distribution.
What would settle it
An explicit construction of a weight function that depends on individual energies or other features beyond their sum, yet yields a smaller chi-squared divergence and thus lower MSE than the best group-energy weight, would falsify the sufficiency claim.
Figures
read the original abstract
We introduce and analyze several grouped variants of the method of reverse importance sampling (RIS) for estimating a partition function from samples of the Boltzmann distribution $p(x)=e^{ \betaU(x)}/Z(\beta)$. Ordinary RIS weighs each sample separately. By contrast, our proposed grouped RIS (GRIS) methods are based on assigning the samples into groups (or batches) of size $k\ge 2$ and applying a joint weight function to each group. The focal point of the research is the quest for a tractable weight function that would yield the smallest possible mean squared error (MSE). A simple identity relates the normalized MSE to the chi-squared divergence between the joint-weight distribution and the distribution of the $k$-fold sum of independent energies. Our first theoretical finding is that any weight that improves on ordinary RIS ($k=1$) must couple the group components. In other words, it must not be a product-form function across those components, as product-form weight functions always worsen the MSE. Our second, and more important, finding is that, without loss of optimality, it is sufficient to seek weight functions that depend only on the total energy, $\sum_iU(x_i)$, of the group (group-energy weight functions); for the sliding-window variants, the analogous result is open. This finding simplifies both the theoretical analysis and the application of the method substantially. For $k=2$ and $k=3$, the MSE associated with non-overlapping (NOL) groups is reduced by $20$--$65\%$ across three examples. We then propose two additional variants of GRIS, both based on sliding-window grouping (as opposed to NOL grouping). The first applies a fixed weight sliding window (FSW) across all (cyclic) shifts of the sliding window, and the second allows a variable-weight sliding window (VSW). The FSW scheme improves on the NOL one, and the VSW improves even further, as will be demonstrated numerically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces grouped reverse importance sampling (GRIS) variants for estimating the partition function from i.i.d. Boltzmann samples. It establishes an identity relating normalized MSE to chi-squared divergence between the joint weight distribution and the k-fold energy sum distribution, proves that product-form weights worsen MSE, shows that weights depending only on the group energy sum suffice without loss of optimality for non-overlapping (NOL) groups, and reports 20-65% MSE reductions for k=2,3 in NOL across three examples, with further gains from fixed-weight (FSW) and variable-weight (VSW) sliding-window schemes.
Significance. If the central identity and sufficiency result hold, the work supplies a principled, symmetry-based simplification for optimizing RIS estimators via grouping, with the chi-squared objective providing a concrete minimization target and the NOL group-energy restriction reducing the search space. The reported numerical improvements and the extension to sliding-window variants indicate practical value for variance reduction in partition function estimation.
minor comments (2)
- [Numerical experiments section] The abstract and numerical results refer to 'three examples' without naming the underlying models (e.g., specific Ising or other spin systems) or providing the exact parameter settings used for the reported 20-65% reductions; this should be added for reproducibility.
- [Numerical experiments section] Error bars, standard deviations, or number of independent trials are not mentioned for the MSE reduction percentages; including these would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We are pleased that the central identity, the necessity of coupling in weights, and the sufficiency of group-energy dependence for NOL groups are viewed as providing a principled simplification for RIS optimization.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives its key claims from an identity linking normalized MSE to chi-squared divergence between the joint-weight distribution and the k-fold energy sum, combined with i.i.d. sampling symmetry under permutation of group components. The result that weight functions of the total energy sum suffice without loss of optimality is a direct mathematical consequence of this setup and does not reduce to any fitted parameter, self-referential definition, or load-bearing self-citation. Numerical MSE improvements are reported as empirical outcomes on specific examples rather than predictions forced by construction. The overall derivation is self-contained against the stated assumptions of independent Boltzmann samples and existence of a tractable joint weight function.
Axiom & Free-Parameter Ledger
free parameters (1)
- group size k
axioms (1)
- domain assumption Samples are i.i.d. draws from p(x) = exp(β U(x)) / Z(β)
Reference graph
Works this paper leans on
-
[1]
M. A. Newton and A. E. Raftery, Approximate Bayesian inference with the weighted likelihood bootstrap,J. R. Stat. Soc. Ser. B, 56(1):3–48, 1994
1994
-
[2]
Simulating ratios of normalizing constants via a simple identity,
X.-L. Meng and W. H. Wong, “Simulating ratios of normalizing constants via a simple identity,”Statistica Sinica, 6(4):831–860, 1996
1996
-
[3]
Estimating the partition function by discriminance sampling,
Q. Liu, J. Peng, A. Ihler, and J. Fisher III, “Estimating the partition function by discriminance sampling,” inProc. UAI, pp. 514–522, 2015
2015
-
[4]
R. M. Neal, Annealed importance sampling,Stat. Comput., 11(2):125–139, 2001
2001
-
[5]
Importance Weighted Autoencoders
Y. Burda, R. Grosse, and R. Salakhutdinov, inProc. 4th Intl. Conf. on Learning Representations (ICLR 2016), San Juan, Puerto Rico, May 2016 (arXiv:1509.00519)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Gelman and X.-L
A. Gelman and X.-L. Meng, Simulating normalizing constants: from importance sampling to bridge sampling to path sampling,Statist. Sci., 13(2):163–185, 1998
1998
-
[7]
Del Moral, A
P. Del Moral, A. Doucet, and A. Jasra, Sequential Monte Carlo samplers,J. R. Stat. Soc. Ser. B, 68(3):411–436, 2006
2006
-
[8]
A. B. Owen and Y. Zhou, Safe and effective importance sampling,J. Amer. Statist. Assoc., 95(449):135–143, 2000
2000
-
[9]
C. P. Robert and G. Casella,Monte Carlo Statistical Methods, 2nd ed., Springer, New York, 2004
2004
-
[10]
N. Branchini and V. Elvira, Generalizing self-normalized importance sampling with couplings, arXiv:2406.19974, 2024
-
[11]
Veach and L
E. Veach and L. J. Guibas, Optimally combining sampling techniques for Monte Carlo rendering, inProc. SIGGRAPH, pp. 419–428, 1995
1995
-
[12]
Elvira, L
V. Elvira, L. Martino, D. Luengo, and M. F. Bugallo, Generalized multiple importance sampling,Stat. Sci., 34(1):129–155, 2019
2019
-
[13]
A. W. van der Vaart,Asymptotic Statistics, Cambridge University Press, Cambridge, 1998
1998
-
[14]
J. M. Hammersley and K. W. Morton, A new Monte Carlo technique: antithetic variates, Math. Proc. Camb. Phil. Soc., 52(3):449–475, 1956
1956
-
[15]
Huang,Statistical Mechanics, 2nd ed., Wiley, New York, 1987
K. Huang,Statistical Mechanics, 2nd ed., Wiley, New York, 1987
1987
-
[16]
R. K. Pathria and P. D. Beale,Statistical Mechanics, 3rd ed., Elsevier, Oxford, 2011. 35
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.