Smoothed Score Queries and the Complexity of Sampling
Pith reviewed 2026-06-29 14:41 UTC · model grok-4.3
The pith
Smoothed-score queries allow Gaussian sampling with only logarithmic dependence on condition number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a Gaussian target with precision matrix Lambda, a smoothed-score query at noise level tau gives access to the resolvent (Lambda + tau^{-1} I)^{-1}. Combining geometrically spaced noise levels with sinc-quadrature rational approximation produces a sampler using q = O((log kappa + log(e sqrt(d) / delta_TV)) log(e sqrt(d) / delta_TV)) such queries to achieve total-variation error delta_TV. This replaces the square-root dependence of standard gradient oracles with logarithmic dependence on kappa. The same approach with coordinatewise quantization and dithering yields total communicated gradient information that is O(log^2 kappa) for fixed dimension and accuracy, while a reverse-Shannon conve
What carries the argument
Smoothed-score query at noise level tau, which returns the resolvent (Lambda + tau^{-1} I)^{-1} for Gaussian target with precision matrix Lambda.
If this is right
- The number of smoothed-score queries scales with the product of two logarithmic factors in kappa and accuracy rather than with the square root of kappa.
- Total communicated bits of gradient information can be reduced to O(log squared kappa) for fixed dimension and accuracy.
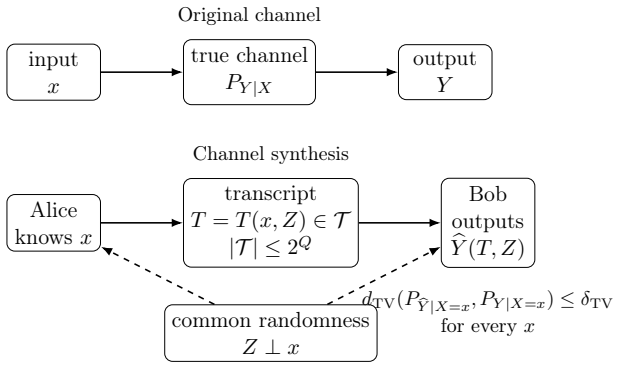
- An Omega(log kappa) lower bound on the required gradient information holds via the channel-synthesis technique.
- Smoothed scores form a strictly stronger oracle than exact gradients for the Gaussian sampling task.
Where Pith is reading between the lines
- Rational approximation of resolvents may reduce condition-number dependence in other matrix-function tasks that arise in sampling or integration.
- The channel-synthesis lower-bound technique could be applied to prove communication requirements for sampling from distributions that are only approximately Gaussian.
- If a target is close to Gaussian, the same geometrically spaced query schedule might still control total-variation error once the smoothing mismatch is bounded.
- Defining smoothed-score oracles for non-Gaussian targets would require showing that the resolvent-like information can be obtained or approximated without the exact Gaussian convolution.
Load-bearing premise
The target distribution is exactly Gaussian so that each smoothed-score query equals the resolvent exactly and the algorithm may freely select the noise levels.
What would settle it
Measure the number of smoothed-score queries needed to reach fixed total-variation error on a non-Gaussian target whose effective condition number is large; if the count still scales only logarithmically then the claim holds, otherwise the Gaussian assumption is necessary.
Figures
read the original abstract
We study the query complexity of sampling from high-dimensional Gaussian distributions using gradient information. In the standard oracle model, exact gradients expose only matrix-vector products with the precision matrix, leading to polynomial approximation barriers and a characteristic \(\sqrt{\kappa}\) dependence on the condition number. We show that this barrier disappears when the sampler is allowed to query \emph{smoothed scores}, namely gradients of the logarithms of the Gaussian-convolved densities. For a Gaussian target with precision matrix \(\Lambda\), a smoothed-score query at noise level \(\tau\) gives access to the resolvent \((\Lambda+\tau^{-1}I)^{-1}\). Combining geometrically spaced noise levels with sinc-quadrature rational approximation, we obtain a sampler with $q=O\!\left(\bigl(\log\kappa+\log(e\sqrt d/\delta_{\rm TV})\bigr)\log(e\sqrt d/\delta_{\rm TV})\right)$ smoothed-score queries for total variation error \(\delta_{\rm TV}\), improving the condition-number dependence from \(\sqrt{\kappa}\) to logarithmic. We also study finite-bit gradient oracles. Using coordinatewise quantization of the transformed smoothed-score answers and a final dithering step, we obtain a sampling scheme whose total communicated gradient information is polylogarithmic in \(\kappa\); in particular, for fixed dimension and accuracy, the bit complexity is \(O(\log^2\kappa)\). To complement these upper bounds, we introduce a channel-synthesis, or reverse-Shannon, converse technique for sampling lower bounds. This converts total-variation simulation guarantees into communication requirements and yields an \(\Omega(\log\kappa)\) lower bound on the required gradient information. Together, these results identify smoothed scores as a provably more informative oracle for sampling and give nearly matching upper and lower bounds for its finite-bit complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that smoothed-score queries (gradients of log-densities after Gaussian convolution) provide access to resolvents (Λ + τ^{-1}I)^{-1} for a Gaussian target with precision matrix Λ. By combining geometrically spaced noise levels τ with sinc-quadrature rational approximation, it obtains an algorithm using q = O((log κ + log(e√d/δ_TV)) log(e√d/δ_TV)) such queries to achieve total-variation error δ_TV, replacing the classic √κ dependence with logarithmic. It further gives a finite-bit variant whose communicated gradient information is O(log² κ) for fixed d and accuracy, and proves an Ω(log κ) lower bound on gradient information via a channel-synthesis (reverse-Shannon) converse that converts TV simulation guarantees into communication requirements.
Significance. If correct, the result establishes smoothed scores as a provably stronger oracle for exact Gaussian sampling, with nearly matching upper and lower bounds on query and bit complexity. Credit is due for the explicit reduction to standard resolvent approximation via sinc quadrature (which yields the logarithmic κ dependence without hidden constants or post-hoc tuning) and for introducing the channel-synthesis technique to obtain the matching Ω(log κ) lower bound. The bounds are parameter-free in the stated sense and directly falsifiable via the explicit construction.
minor comments (2)
- [Abstract] Abstract: the notation δ_TV is introduced without an explicit forward reference to its definition in the main text; a parenthetical “(see §2)” would improve readability.
- The finite-bit section states that coordinatewise quantization plus dithering yields polylogarithmic communication, but does not explicitly bound the bit length per coordinate; adding a short sentence with the per-coordinate bit cost would clarify the O(log² κ) claim.
Simulated Author's Rebuttal
We thank the referee for their thorough summary of the manuscript and for the positive recommendation to accept. The report accurately captures the main contributions, including the resolvent reduction via smoothed scores, the sinc-quadrature construction yielding the logarithmic condition-number dependence, the finite-bit variant, and the channel-synthesis lower bound.
Circularity Check
No significant circularity; derivation relies on external resolvent identities and approximation theory
full rationale
The paper derives its query-complexity upper bound by invoking the exact identity that a smoothed-score query at level τ equals the resolvent (Λ + τ^{-1}I)^{-1} for a Gaussian target, then applies geometrically spaced τ values together with standard sinc-quadrature rational approximation. Both the resolvent identity and the quadrature technique are standard facts from linear algebra and approximation theory, independent of any quantities defined or fitted inside the paper. The matching Ω(log κ) lower bound is obtained via a channel-synthesis converse that converts total-variation simulation guarantees into communication requirements; this is likewise an external information-theoretic argument. No equation reduces by construction to a fitted parameter, no uniqueness theorem is imported from the authors' prior work, and no self-citation is load-bearing for the central claim. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math For a Gaussian with precision matrix Λ, the gradient of the log-density after convolution with N(0,τI) equals (Λ + τ^{-1}I)^{-1} applied to the query point.
Reference graph
Works this paper leans on
-
[1]
Aune, E., Eidsvik, J., and Pokern, Y. (2013). Iterative numerical methods for sampling from high dimensional Gaussian distributions.Statistics and Computing, 23(4):501–521
2013
-
[2]
H., Devetak, I., Harrow, A
Bennett, C. H., Devetak, I., Harrow, A. W., Shor, P. W., and Winter, A. (2014). The quantum reverse Shannon theorem and resource tradeoffs for simulating quantum channels.IEEE Transactions on Information Theory, 60(5):2926–2959
2014
-
[3]
H., Shor, P
Bennett, C. H., Shor, P. W., Smolin, J. A., and Thapliyal, A. V. (2002). Entanglement-assisted ca- pacity of a quantum channel and the reverse Shannon theorem.IEEE Transactions on Information Theory, 48(10):2637–2655
2002
-
[4]
Berta, M., Christandl, M., and Renner, R. (2011). The quantum reverse Shannon theorem based on one-shot information theory.Communications in Mathematical Physics, 306(3):579–615
2011
-
[5]
Chen, F., Chewi, S., Daskalakis, C., and Rakhlin, A. (2026). High-accuracy sampling for diffusion models and log-concave distributions.arXiv preprint arXiv:2602.01338
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
Chen, T., Greenbaum, A., Musco, C., and Musco, C. (2022). Error bounds for Lanczos-based matrix function approximation.SIAM Journal on Matrix Analysis and Applications, 43(2):787–811
2022
- [8]
- [9]
-
[10]
R., Lu, C., Le Gouic, T., and Rigollet, P
Chewi, S., Gerber, P. R., Lu, C., Le Gouic, T., and Rigollet, P. (2022). The query complexity of sampling from strongly log-concave distributions in one dimension. InProceedings of the Thirty Fifth Conference on Learning Theory, volume 178 ofProceedings of Machine Learning Research, pages 2041–2059. PMLR
2022
-
[11]
and Saad, Y
Chow, E. and Saad, Y. (2014). Preconditioned Krylov subspace methods for sampling multivariate Gaussian distributions.SIAM Journal on Scientific Computing, 36(2):A588–A608
2014
-
[12]
Cuff, P. (2013). Distributed channel synthesis.IEEE Transactions on Information Theory, 59(11):7071–7096
2013
-
[13]
Gallager, R. G. (1968).Information Theory and Reliable Communication. John Wiley & Sons, New York
1968
-
[14]
Gao, X. and Zhu, L. (2025). Convergence analysis for general probability-flow ODEs of diffusion models in wasserstein distances. InInternational Conference on Artificial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Research, pages 1009–1017. arXiv:2401.17958
-
[15]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851
2020
- [16]
- [17]
-
[18]
(2017).Eγ-resolvability.IEEE Transactions on Information Theory, 63(5):2629–2658
Liu, J., Cuff, P., and Verdú, S. (2017).Eγ-resolvability.IEEE Transactions on Information Theory, 63(5):2629–2658
2017
-
[19]
and Verdú, S
Liu, J. and Verdú, S. (2018). Rejection sampling and noncausal sampling under moment constraints. In2018 IEEE International Symposium on Information Theory (ISIT), pages 1565–1569
2018
-
[20]
(2023).Upper and Lower Bounds for Sampling
Lu, C. (2023).Upper and Lower Bounds for Sampling. PhD thesis, Massachusetts Institute of Technology
2023
-
[21]
Mahajan, J., Zhang, K., Liang, F., and Liu, J. (2025). The Picard-Lagrange framework for higher- order Langevin Monte Carlo.arXiv preprint arXiv:2510.18242. 34
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Musco, C., Musco, C., and Sidford, A. (2018). Stability of the Lanczos method for matrix function approximation. InProceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1605–1624
2018
-
[23]
Neal, R. M. (2001). Annealed importance sampling.Statistics and Computing, 11(2):125–139
2001
-
[24]
Okayama, T., Matsuo, T., and Sugihara, M. (2013). Error estimates with explicit constants for sinc approximation, sinc quadrature and sinc indefinite integration.Numerische Mathematik, 124(2):361–394
2013
-
[25]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2021). Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations
2021
-
[26]
(1993).Numerical Methods Based on Sinc and Analytic Functions, volume 20 ofSpringer Series in Computational Mathematics
Stenger, F. (1993).Numerical Methods Based on Sinc and Analytic Functions, volume 20 ofSpringer Series in Computational Mathematics. Springer
1993
-
[27]
Trefethen, L. N. and Weideman, J. A. C. (2014). The exponentially convergent trapezoidal rule. SIAM Review, 56(3):385–458
2014
-
[28]
(2018).High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47 ofCambridge Series in Statistical and Probabilistic Mathematics
Vershynin, R. (2018).High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47 ofCambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press
2018
-
[29]
Query Lower Bounds for Diffusion Sampling
Xun, Z. and Price, E. (2026). Query lower bounds for diffusion sampling.arXiv preprint arXiv:2604.10857
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
S., Huan, S., Huang, J., Boffi, N
Zhang, M. S., Huan, S., Huang, J., Boffi, N. M., Chen, S., and Chewi, S. (2025). Sublinear iterations can suffice even for DDPMs.arXiv preprint arXiv:2511.04844. 35
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.