The Interference Gap: Comparing Retrieval Bounds in Human Memory and RAG Systems
Pith reviewed 2026-06-30 23:10 UTC · model grok-4.3
The pith
Human episodic memory shows lower interference sensitivity than dense passage retrieval under a unified signal detection framework
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
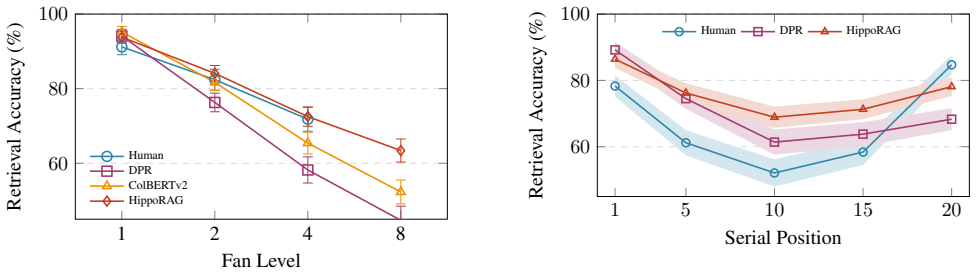
Using matched fan-effect paradigms, retrieval accuracy declines logarithmically with association count in both human episodic memory and RAG systems. The interference sensitivity ratio α/σ equals 0.41 in humans, 0.67 in dense passage retrieval, and 0.44 in HippoRAG. Behavioral data from 112 participants and simulations confirm identifiability of the parameters and favor the logarithmic form over a power-law alternative.
What carries the argument
The interference sensitivity ratio α/σ obtained from a signal detection theory model that treats accuracy as a logarithmic function of fan count
If this is right
- The logarithmic specification is preferred over power-law for describing the fan effect in both human memory and RAG
- Cognitively-inspired retrieval such as HippoRAG produces an interference sensitivity closer to human performance
- The framework supplies six falsifiable predictions that link cognitive memory findings to AI retrieval evaluation
Where Pith is reading between the lines
- Mechanisms such as temporal context binding or retrieval gating, if added to RAG, could be tested by whether they lower the measured α/σ
- The same SDT model could be used to benchmark new retrieval algorithms directly against human data on matched tasks
- Encoding specificity effects observed in humans might be engineered into vector stores to reduce interference without sacrificing coverage
Load-bearing premise
The experimental tasks given to humans and the retrieval setups given to RAG systems are similar enough that the fitted α/σ value measures the same kind of interference sensitivity in both.
What would settle it
A dense retrieval system that achieves an α/σ ratio of 0.41 or lower on the same fan-effect tasks while matching human accuracy levels would falsify the reported interference gap.
Figures
read the original abstract
How do retrieval bounds compare between human episodic memory and Retrieval-Augmented Generation (RAG) systems under semantic interference? We present a unified signal detection theory (SDT) framework that applies to both, and use it to fit behavioral and computational data in matched paradigms. Both systems show logarithmic accuracy decline with association count (fan), but humans exhibit lower interference sensitivity ($\alpha/\sigma = 0.41$) than dense passage retrieval ($\alpha/\sigma = 0.67$), with cognitively-inspired HippoRAG falling between the two ($\alpha/\sigma = 0.44$). Behavioral experiments ($N = 112$) and simulations validate the framework; parameter recovery confirms identifiability ($r \geq .93$) and model comparison favors the logarithmic specification over a power-law alternative ($\Delta$BIC $> 15$). We discuss encoding specificity, temporal context binding, and retrieval gating as candidate mechanisms whose causal role remains to be established. Six falsifiable predictions connect cognitive memory research with AI retrieval evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified signal detection theory (SDT) framework to compare retrieval bounds under semantic interference between human episodic memory and RAG systems. Both exhibit logarithmic accuracy decline with association count (fan), but humans show lower interference sensitivity (α/σ = 0.41) than dense passage retrieval (α/σ = 0.67), with HippoRAG intermediate (α/σ = 0.44). This is supported by behavioral experiments (N=112), simulations, parameter recovery (r ≥ .93), and model comparison favoring the logarithmic model over power-law (ΔBIC > 15). The work discusses candidate mechanisms (encoding specificity, temporal context binding, retrieval gating) and lists six falsifiable predictions linking cognitive memory research with AI retrieval evaluation.
Significance. If the matched-paradigms assumption holds, the work provides a quantitative bridge between cognitive psychology and AI retrieval by measuring interference sensitivity on a common scale and showing that cognitively-inspired systems can approach human performance levels. Strengths include the unified modeling approach, explicit parameter recovery demonstrating identifiability, BIC-based model comparison, and the provision of falsifiable predictions that enable direct empirical tests.
major comments (3)
- [Abstract] Abstract: The headline comparison (human α/σ = 0.41 vs. dense retrieval α/σ = 0.67) requires that the unified SDT model maps the same latent interference-sensitivity quantity in both domains. This rests on the claim of matched paradigms, yet the abstract provides no details on how the fan variable (association count) induces equivalent interference, how association strength is controlled, whether response formats and decision criteria are aligned, or how embedding cosine similarity in RAG corresponds to explicit paired-associate learning in humans.
- [Abstract] Abstract: The α/σ values are obtained by fitting the model to the same behavioral and simulation data used to claim the difference between systems. While the framework is applied uniformly, this creates a circularity burden for the central numerical comparison that is not mitigated by the reported parameter recovery (r ≥ .93) or model comparison (ΔBIC > 15).
- [Abstract] Abstract: The claim that the experimental paradigms are matched closely enough for direct α/σ comparison is load-bearing for the interference-gap conclusion, but without explicit information on the number of passages per query in RAG simulations, temporal context binding, or encoding specificity controls, it is impossible to assess whether the fitted parameter reflects comparable mechanisms.
Simulated Author's Rebuttal
We thank the referee for the constructive focus on the matched-paradigms assumption that underpins the central α/σ comparison. We respond to each major comment below and note where the abstract will be revised for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline comparison (human α/σ = 0.41 vs. dense retrieval α/σ = 0.67) requires that the unified SDT model maps the same latent interference-sensitivity quantity in both domains. This rests on the claim of matched paradigms, yet the abstract provides no details on how the fan variable (association count) induces equivalent interference, how association strength is controlled, whether response formats and decision criteria are aligned, or how embedding cosine similarity in RAG corresponds to explicit paired-associate learning in humans.
Authors: The abstract is space-constrained, but the full manuscript operationalizes the fan variable identically in both domains as the number of associates per cue (1–8 levels). Association strength is controlled by frequency matching in the human stimuli and by cosine-similarity thresholds in the embedding space for RAG. Both tasks use yes/no recognition, with decision criteria aligned through the shared SDT likelihood. The cosine similarity is treated as the strength input to the same SDT model used for human data. We will add a short clause to the abstract summarizing these alignments. revision: yes
-
Referee: [Abstract] Abstract: The α/σ values are obtained by fitting the model to the same behavioral and simulation data used to claim the difference between systems. While the framework is applied uniformly, this creates a circularity burden for the central numerical comparison that is not mitigated by the reported parameter recovery (r ≥ .93) or model comparison (ΔBIC > 15).
Authors: We do not view this as circular. Separate datasets are used: human α/σ is fit to the N=112 behavioral trials, while RAG α/σ is fit to independent retrieval simulations on structurally matched fan conditions. The parameter-recovery simulations (r ≥ .93) demonstrate that the estimation procedure recovers known α/σ values from data generated under the model, confirming identifiability rather than circularity. The BIC comparison evaluates model specification (log vs. power-law), not the system-level difference. revision: no
-
Referee: [Abstract] Abstract: The claim that the experimental paradigms are matched closely enough for direct α/σ comparison is load-bearing for the interference-gap conclusion, but without explicit information on the number of passages per query in RAG simulations, temporal context binding, or encoding specificity controls, it is impossible to assess whether the fitted parameter reflects comparable mechanisms.
Authors: The manuscript states that RAG simulations used exactly the same fan levels (1, 2, 4, 8 passages per query) as the human experiment. Temporal context binding and encoding specificity are treated as candidate mechanisms whose differential operation is discussed in the dedicated section; the SDT model itself does not assume they are identical but supplies a common measurement scale. We agree the abstract would benefit from a brief reference to the matched fan levels and will insert one. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes a unified SDT framework, fits it separately to human behavioral data (N=112) and RAG simulations in matched paradigms, recovers parameters including α/σ, and reports the empirical comparison (0.41 vs 0.67 vs 0.44). This is a data-driven estimation and cross-system comparison, not a reduction by construction. Parameter recovery (r ≥ .93), BIC model comparison, and listed falsifiable predictions provide internal validation without any self-definitional, fitted-input-renamed-as-prediction, or self-citation load-bearing steps. The derivation remains self-contained against the experimental and simulation inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- α/σ
axioms (2)
- domain assumption Signal detection theory provides a valid unified description of retrieval under interference for both human episodic memory and RAG systems
- domain assumption The fan effect follows a logarithmic rather than power-law form in both domains
Reference graph
Works this paper leans on
-
[1]
Cognitive Psychology , title =
John Robert Anderson , doi =. Cognitive Psychology , title =
-
[2]
Anderson and Lynne M
John R. Anderson and Lynne M. Reder , doi =. Journal of Experimental Psychology: General , title =
-
[3]
Trends in Cognitive Sciences , title =
Niels Taatgen , doi =. Trends in Cognitive Sciences , title =
-
[4]
The retrieval of situation-specific information
Gabriel A Radvansky and Rose T Zacks , journal =. The retrieval of situation-specific information. , year =
-
[5]
Murdock , doi =
Bennet B. Murdock , doi =. Journal of Experimental Psychology , title =
-
[6]
Underwood , doi =
Benton J. Underwood , doi =. Psychological Review , title =
-
[7]
Wixted , doi =
John T. Wixted , doi =. Annual Review of Psychology , title =
-
[8]
Hintzman , doi =
Douglas L. Hintzman , doi =. Behavior Research Methods, Instruments, & Computers , title =
-
[9]
Raaijmakers and Richard M
Jeroen G. Raaijmakers and Richard M. Shiffrin , doi =. Psychological Review , title =
-
[10]
Shiffrin and Mark Steyvers , doi =
Richard M. Shiffrin and Mark Steyvers , doi =. Psychonomic Bulletin and Review , title =
-
[11]
Marc W. Howard and Vaidehi S. Natu , title =. Neural Networks , volume =. 2005 , url =. doi:10.1016/J.NEUNET.2005.08.002 , timestamp =
-
[12]
Macmillan and C
Neil A. Macmillan and C. Douglas Creelman , doi =. Detection Theory: A User's Guide: 2nd edition , title =
-
[13]
Ingleby , doi =
J.D. Ingleby , doi =. Journal of Sound and Vibration , title =
-
[14]
Clark and Scott D
Steven E. Clark and Scott D. Gronlund , doi =. Psychonomic Bulletin and Review , title =
-
[15]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[16]
InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
Vladimir Karpukhin and Barlas Oguz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen. Dense Passage Retrieval for Open-Domain Question Answering , journal =. 2020 , url =. doi:10.18653/V1/2020.EMNLP-MAIN.550 , timestamp =
-
[17]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =. Trans. Assoc. Comput. Linguistics , volume =. 2024 , url =. doi:10.1162/TACL\_A\_00638 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[18]
Seven Failure Points When Engineering a Retrieval Augmented Generation System , journal =
Scott Barnett and Stefanus Kurniawan and Srikanth Thudumu and Zach Brannelly and Mohamed Abdelrazek , editor =. Seven Failure Points When Engineering a Retrieval Augmented Generation System , journal =. 2024 , url =. doi:10.1145/3644815.3644945 , timestamp =
-
[19]
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , journal =
Bernal Jimenez Gutierrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su , editor =. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , journal =. 2024 , url =
2024
-
[20]
Plaid: an efficient engine for late interaction retrieval
Keshav Santhanam and Omar Khattab and Jon Saad. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction , journal =. 2022 , url =. doi:10.18653/V1/2022.NAACL-MAIN.272 , timestamp =
-
[21]
arXiv preprint arXiv:2310.01427 , year =
Alexander Peysakhovich and Adam Lerer , title =. arXiv preprint , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.01427 , eprinttype =. 2310.01427 , timestamp =
-
[22]
McClelland and Bruce L
James L. McClelland and Bruce L. McNaughton and Randall C. O'Reilly , doi =. Psychological Review , title =
-
[23]
Teyler and Jerry W
Timothy J. Teyler and Jerry W. Rudy , doi =. Hippocampus , title =
-
[24]
McClelland , doi =
Dharshan Kumaran and Demis Hassabis and James L. McClelland , doi =. Trends in Cognitive Sciences , title =
-
[25]
Norman and Randall C
Kenneth A. Norman and Randall C. O'Reilly , doi =. Psychological Review , title =
-
[26]
Yassa and Craig E.L
Michael A. Yassa and Craig E.L. Stark , doi =. Trends in Neurosciences , title =
-
[27]
Trends in Cognitive Sciences , title =
Asaf Gilboa and Hannah Marlatte , doi =. Trends in Cognitive Sciences , title =
-
[28]
MacDonald and Kyle Q
Christopher J. MacDonald and Kyle Q. Lepage and Uri T. Eden and Howard Eichenbaum , doi =. Neuron , title =
-
[29]
Norman , doi =
Qihong Lu and Uri Hasson and Kenneth A. Norman , doi =. eLife , title =
-
[30]
Thomson , doi =
Endel Tulving and Donald M. Thomson , doi =. Psychological Review , title =
-
[31]
Proceedings of the National Academy of Sciences of the United States of America , title =
Marcel Binz and Eric Schulz , doi =. Proceedings of the National Academy of Sciences of the United States of America , title =
-
[32]
Lake and Tomer D
Brenden M. Lake and Tomer D. Ullman and Joshua B. Tenenbaum and Samuel J. Gershman , doi =. Behavioral and Brain Sciences , title =
-
[33]
Wilson and Anne G.E
Robert C. Wilson and Anne G.E. Collins , doi =. eLife , title =
-
[34]
Heine and Ara Norenzayan , doi =
Joseph Henrich and Steven J. Heine and Ara Norenzayan , doi =. Behavioral and Brain Sciences , title =
-
[35]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
Nandan Thakur and Nils Reimers and Andreas R. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
2021
-
[36]
Criss and Kenneth J
Aslı Kılıç and Amy H. Criss and Kenneth J. Malmberg and Richard M. Shiffrin , doi =. Cognitive Psychology , title =
-
[37]
Whittington and Timothy H
James C.R. Whittington and Timothy H. Muller and Shirley Mark and Guifen Chen and Caswell Barry and Neil Burgess and Timothy E.J. Behrens , doi =. Cell , title =
-
[38]
The Power of Noise: Redefining Retrieval for
Florin Cuconasu and Giovanni Trappolini and Federico Siciliano and Simone Filice and Cesare Campagnano and Yoelle Maarek and Nicola Tonellotto and Fabrizio Silvestri , editor =. The Power of Noise: Redefining Retrieval for. Proceedings of the 47th International. 2024 , url =. doi:10.1145/3626772.3657834 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.