The Contagion Tensor: A Framework for Measuring Output-Distribution Coupling in Multi-Agent LLM Systems -- and Auditing the Claims It Enables
Pith reviewed 2026-06-30 10:11 UTC · model grok-4.3
The pith
The Contagion Tensor supplies a ratio metric to quantify output-distribution coupling across agents, modalities, and time steps in multi-agent LLM systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
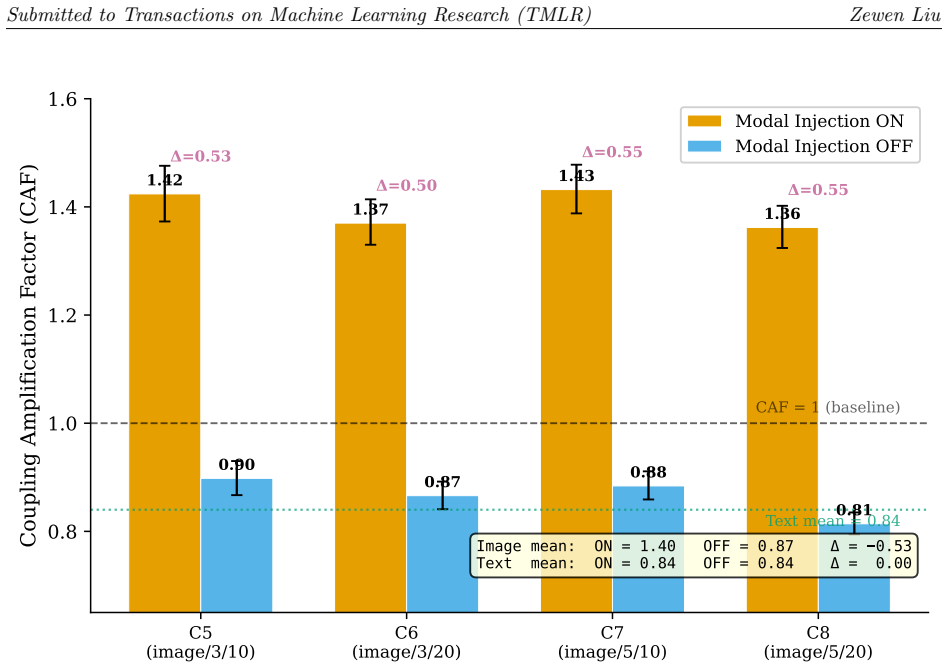
The central claim is that the Contagion Tensor framework makes output-distribution coupling in multi-agent LLM systems quantitatively falsifiable. The Coupling Amplification Factor is computed as E[T_condition] / E[T_baseline] and instantiated in four variants. In the complete 2x2x2 simulation with modality-specific ablation, disabling the image perturbation module shifts the image-condition CAF from 1.40 to 0.87 with no effect on text conditions. Real-API validation on GPT-4o-mini shows text CAF of 1.02 versus real-vision CAF of 1.72, and diverse personas produce CAF of 0.88 under both model families tested.
What carries the argument
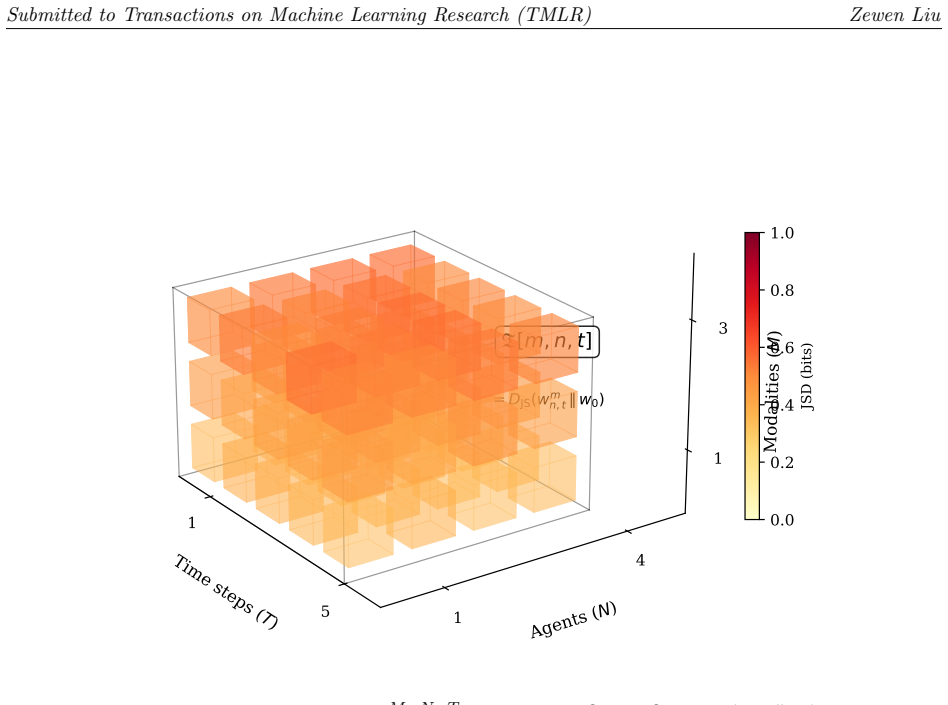
The Contagion Tensor, a structure that tracks output distributions across modalities, agents, and time steps, from which the Coupling Amplification Factor is derived as the ratio of conditional to baseline expectations.
If this is right
- Text-only communication under uniform personas produces CAF approximately 1.0 in both DeepSeek-Chat and GPT-4o-mini.
- Diverse personas produce convergence with CAF of 0.88.
- Real vision input on GPT-4o-mini produces CAF of 1.72, a within-model delta of +0.70 over text.
- Disabling the image perturbation module in simulation collapses apparent super-linear coupling to sub-linear (0.87) while leaving text conditions unchanged.
- The ablation protocol can be adopted by any modular multi-agent simulator to distinguish genuine coupling from design artifacts.
Where Pith is reading between the lines
- The same ablation protocol could be applied to other modular components to test whether additional apparent coupling effects arise from simulation design choices.
- The ratio form of CAF allows direct numerical comparison of coupling strength across entirely different model families or task domains.
- Extending the tensor to record per-agent divergence at each time step would make dynamic evolution of coupling observable rather than summarized only at the end state.
Load-bearing premise
The 2x2x2 block-orthogonal simulation design with modality-specific ablation isolates genuine coupling effects from design artifacts without the ablation itself altering baseline text conditions or introducing new biases.
What would settle it
Re-running the GPT-4o-mini real-vision condition and finding that its CAF confidence interval overlaps the text-only interval around 1.02 would falsify the reported super-linear image effect.
Figures
read the original abstract
We introduce the Contagion Tensor, a measurement framework for quantifying how large language model (LLM) output distributions couple across modalities, agents, and time steps. From the tensor we derive the Coupling Amplification Factor (CAF), a family of ratio-based metrics sharing the form CAF = E[T_condition] / E[T_baseline], providing unitless, baseline-referenced measurement with bootstrap confidence intervals. We instantiate CAF in four variants and evaluate the strongest in a complete 2x2x2 block-orthogonal simulation design with modality-specific ablation. The ablation reveals that an apparent image-condition super-linear effect (CAF = 1.40) collapses to sub-linear (CAF = 0.87) when the image perturbation module is disabled, a shift of -0.53 with zero effect on text conditions. We supplement with real-API experiments across two model families: DeepSeek-Chat (R=30) and GPT-4o-mini (R=15, real vision). Under uniform personas, text-only communication produces CAF approx 1.0 in both models. Diverse personas drive convergence (CAF = 0.88). A within-model comparison on GPT-4o-mini reveals: C3 (text) CAF = 1.02 vs. C5 (real vision, R=30) CAF = 1.72 [1.700, 1.733], delta = +0.70, validating the simulation's super-linear image-condition prediction. Of 11 conditions, 5 have been tested on real APIs and 6 remain unverified. Our contribution is two-layered: (1) a measurement instrument that makes output-distribution coupling quantitatively falsifiable; and (2) a transferable ablation protocol that any modular multi-agent simulator can adopt to distinguish genuine coupling from design artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Contagion Tensor framework and derives the Coupling Amplification Factor (CAF = E[T_condition]/E[T_baseline]) to quantify output-distribution coupling in multi-agent LLM systems across modalities. It reports a 2x2x2 block-orthogonal simulation with modality-specific ablation showing an image-condition CAF of 1.40 collapsing to 0.87 (shift of -0.53) when the image perturbation module is disabled, with zero effect on text conditions; real-API experiments on GPT-4o-mini and DeepSeek-Chat show text-only CAF near 1.0, diverse personas at 0.88, and a within-model GPT-4o-mini vision effect of CAF=1.72 [1.700, 1.733] vs text 1.02 (delta +0.70). Of 11 conditions, 5 are real-API verified. The contribution is framed as a falsifiable measurement instrument plus transferable ablation protocol.
Significance. If the ablation orthogonality holds and the real-API results replicate, the framework supplies a unitless, baseline-referenced metric with bootstrap intervals that makes coupling claims quantitatively testable, plus an ablation protocol usable by other modular simulators. These elements directly address the need for auditing tools in multi-agent LLM systems and could support falsifiable predictions about modality effects.
major comments (3)
- [Abstract and simulation description paragraph] Abstract and simulation description paragraph: the claim that disabling the image perturbation module produces 'zero effect on text conditions' is load-bearing for attributing the CAF drop from 1.40 to 0.87 to genuine coupling rather than baseline variance or shared state; the manuscript supplies neither the exact disable implementation nor post-ablation text-condition statistics or variance comparisons.
- [Abstract] Abstract: the CAF ratio form E[T_condition]/E[T_baseline] is presented without derivation showing independence from baseline choice or that results do not reduce by construction; no sensitivity analysis to the expectation estimator E[T] is given despite this being central to all reported numerical claims.
- [Abstract] Abstract: the headline within-model GPT-4o-mini result (C3 text CAF=1.02 vs C5 real-vision CAF=1.72, delta +0.70) rests on R=15/R=30 runs with only 5 of 11 conditions real-API tested; absence of full methods, error analysis, or raw data prevents assessment of whether the reported confidence interval and ablation outcome support the super-linear image prediction.
minor comments (2)
- Abstract uses undefined shorthand (C3, C5, R=30) and 'approx 1.0' without listing the four CAF variants or the precise 2x2x2 factor definitions.
- Notation for model families and repetition counts could be introduced earlier for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments on the Contagion Tensor framework. We address each of the major comments below and outline the revisions we will make to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [Abstract and simulation description paragraph] the claim that disabling the image perturbation module produces 'zero effect on text conditions' is load-bearing for attributing the CAF drop from 1.40 to 0.87 to genuine coupling rather than baseline variance or shared state; the manuscript supplies neither the exact disable implementation nor post-ablation text-condition statistics or variance comparisons.
Authors: We agree this detail is essential for validating the ablation's specificity. The revised manuscript will include the exact implementation of disabling the image perturbation module and report the post-ablation CAF values along with variance statistics for the text conditions to confirm no effect. revision: yes
-
Referee: [Abstract] the CAF ratio form E[T_condition]/E[T_baseline] is presented without derivation showing independence from baseline choice or that results do not reduce by construction; no sensitivity analysis to the expectation estimator E[T] is given despite this being central to all reported numerical claims.
Authors: While the ratio form is chosen for its interpretability as a normalized amplification factor, we acknowledge the absence of a formal derivation and sensitivity analysis in the current version. We will add a derivation section demonstrating the properties of CAF and perform sensitivity analyses on the choice of E[T] estimator in the revision. revision: yes
-
Referee: [Abstract] the headline within-model GPT-4o-mini result (C3 text CAF=1.02 vs C5 real-vision CAF=1.72, delta +0.70) rests on R=15/R=30 runs with only 5 of 11 conditions real-API tested; absence of full methods, error analysis, or raw data prevents assessment of whether the reported confidence interval and ablation outcome support the super-linear image prediction.
Authors: The manuscript already specifies the run counts (R=15 for GPT-4o-mini text, R=30 for vision) and provides bootstrap intervals. To address the lack of full methods and error analysis, the revision will expand these sections substantially. We will also make the raw data available in a supplementary repository to allow independent verification of the results. revision: yes
Circularity Check
No significant circularity; CAF is an explicitly defined ratio metric with independent empirical content from simulation and API experiments
full rationale
The paper defines the Contagion Tensor and derives CAF explicitly as the ratio CAF = E[T_condition] / E[T_baseline] (abstract). It then applies this metric to a 2x2x2 block-orthogonal simulation with ablation and to real-API runs on GPT-4o-mini and DeepSeek-Chat, reporting concrete values (e.g., text CAF ≈ 1.0, vision CAF = 1.72 [1.700, 1.733]). The ablation result (1.40 → 0.87 with stated zero effect on text) is presented as an observed outcome of the design, not as a quantity forced by the definition or by any fitted parameter renamed as prediction. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The derivation chain therefore remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM output distributions can be meaningfully represented and compared across modalities, agents, and time steps using a tensor structure.
invented entities (2)
-
Contagion Tensor
no independent evidence
-
Coupling Amplification Factor (CAF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior. InUIST, 2023
2023
-
[2]
Lianget al.Holistic evaluation of language models.TMLR, 2023
P. Lianget al.Holistic evaluation of language models.TMLR, 2023
2023
-
[3]
Y. Du, S. Li, A. Torralba, J. Tenenbaum, and I. Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
-
[5]
Parrishet al.BBQ: A hand-built bias benchmark for question answering
A. Parrishet al.BBQ: A hand-built bias benchmark for question answering. InFindings of ACL, 2022
2022
-
[6]
Nangia, C
N. Nangia, C. Vania, R. Bhalerao, and S. R. Bowman. CrowS-Pairs: A challenge dataset for measuring social biases. InEMNLP, 2020
2020
-
[7]
Rudinger, J
R. Rudinger, J. Naradowsky, B. Leonard, and B. Van Durme. Gender bias in coreference resolution. InNAACL, 2018
2018
-
[8]
Tevet and J
G. Tevet and J. Berant. Evaluating the evaluation of diversity in natural language generation. InEACL, 2021
2021
-
[9]
R. G. Sargent. Verification and validation of simulation models.Journal of Simulation, 7(1):12– 24, 2013. Submitted to Transactions on Machine Learning Research (TMLR) Zewen Liu
2013
-
[10]
J. M. Gal´ anet al.Errors and artefacts in agent-based modelling.JASSS, 12(1):1, 2009
2009
-
[11]
S. F. Railsback and V. Grimm.Agent-Based and Individual-Based Modeling: A Practical Introduction. Princeton University Press, 2nd edition, 2019
2019
-
[12]
Grimmet al.The ODD protocol: A review and first update.Ecological Modelling, 221(23):2760–2768, 2010
V. Grimmet al.The ODD protocol: A review and first update.Ecological Modelling, 221(23):2760–2768, 2010
2010
-
[13]
Centola and M
D. Centola and M. Macy. Complex contagions and the weakness of long ties.American Journal of Sociology, 113(3):702–734, 2007
2007
-
[14]
Chakrabarti, Y
D. Chakrabarti, Y. Wang, C. Wang, J. Leskovec, and C. Faloutsos. Epidemic thresholds in real networks.ACM TISSEC, 10(4):1–26, 2008
2008
-
[15]
D. M. Endres and J. E. Schindelin. A new metric for probability distributions.IEEE Trans. Info. Theory, 49(7):1858–1860, 2003
2003
-
[16]
K. Venkatesh, J. Isbarov, S. Amin, M. Kantarcioglu, and J. Cui. CASPIAN: Online detec- tion and attribution of cascade attacks in LLM multi-agent systems via cross-channel causal monitoring. arXiv:2605.19240, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
C. Riedl. Emergent coordination in multi-agent language models. InICLR, 2026. arXiv:2510.05174
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Bridgeford and H
E. Bridgeford and H. Helm. Detecting perspective shifts in multi-agent systems. InICML,
-
[19]
K. Zhu, H. Du, Z. Hong, X. Yang, S. Guo, Z. Wang, Z. Wang, C. Qian, X. Tang, H. Ji, and J. You. MultiAgentBench: Evaluating the collaboration and competition of LLM agents. In ACL, 2025
2025
-
[20]
Zhang, M
G. Zhang, M. Fu, K. Wang, F. Wan, M. Yu, and S. Yan. G-Memory: Tracing hierarchical memory for multi-agent systems. InNeurIPS, 2025
2025
-
[21]
X. Mou, C. Qian, W. Liu, L. Yan, Y. Hu, X. Huang, and Z. Wei. EcoLANG: Efficient and effective agent communication language induction for social simulation. InFindings of EMNLP, 2025
2025
-
[22]
M. Larooij and P. T¨ ornberg. Do large language models solve the problems of agent-based modeling? A critical review of generative social simulations.arXiv:2504.03274, 2025
-
[23]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Honget al.MetaGPT: Meta programming for a multi-agent collaborative framework. arXiv:2308.00352, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Liet al.CAMEL: Communicative agents for “mind” exploration of large language model society
G. Liet al.CAMEL: Communicative agents for “mind” exploration of large language model society. InNeurIPS, 2023
2023
-
[25]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wuet al.AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv:2308.08155, 2023. Submitted to Transactions on Machine Learning Research (TMLR) Zewen Liu A K-Sensitivity of CAF Table 19 reports CAFbase for all eight conditions acrossK∈ {3,5,10,20}. The modality bifurcation (image super-linear, text sub-linear) emerges clearly at...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.