Bridging the Gap Between Latent and Explicit Reasoning with Looped Transformers
Pith reviewed 2026-07-01 06:49 UTC · model grok-4.3
The pith
Looped transformers with parallel supervision on latent positions match explicit chain-of-thought performance at 3B scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
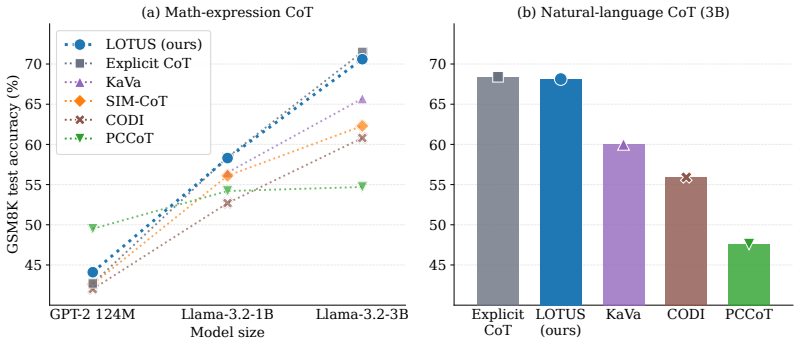
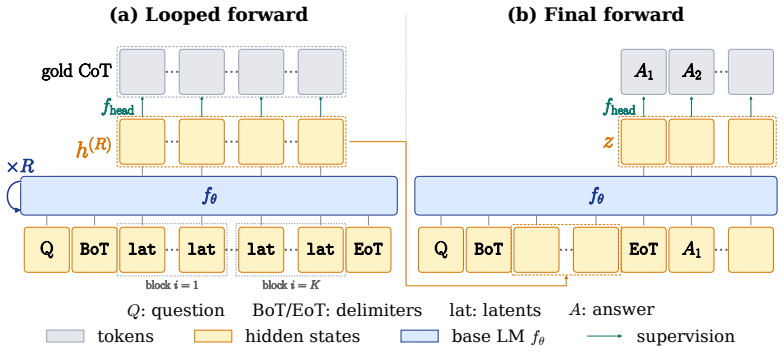
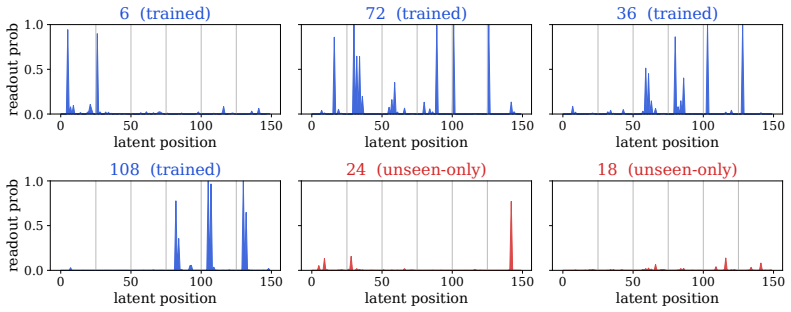
A looped padded Transformer that runs K latent blocks in parallel for R iterations, trained with cross-entropy loss on each latent position's corresponding gold CoT-step token, achieves explicit-CoT-level accuracy at the 3B scale while reducing thought-phase latency by 2.5x-6.9x. Projecting the final latent states through the base language-model head recovers the gold steps and can surface alternative valid intermediates, indicating that the latent space remains interpretable and aligned with explicit reasoning. Ablations show that both the looped backbone and the parallel gold-token supervision are required for the result.
What carries the argument
Looped padded Transformer with parallel cross-entropy supervision on gold CoT-step tokens for each of K latent blocks across R iterations, which reuses weights to increase effective depth while aligning hidden states to explicit reasoning steps.
If this is right
- Latent CoT can reach explicit CoT performance at 3B parameters instead of lagging behind as seen in prior methods.
- Thought-phase latency drops by factors between 2.5x and 6.9x when moving from compact math expressions to natural language outputs.
- The final latent representations remain decodable into explicit steps, preserving interpretability without extra training.
- Both the recurrent-depth structure and the parallel gold-token loss are necessary; removing either collapses the gains.
Where Pith is reading between the lines
- If gold steps are available only for a subset of training data, the method might still transfer to new domains by mixing supervised and unsupervised loops.
- The ability to surface alternative valid steps suggests the latent space could support search or verification procedures that explicit decoding cannot easily do.
- Increasing R at inference time without retraining could provide a tunable accuracy-latency trade-off not available in standard Transformers.
Load-bearing premise
Gold chain-of-thought step tokens can be supplied at training time and this direct supervision is enough to make the looped latent states functionally equivalent to explicit token steps.
What would settle it
If the post-loop latent states, when passed through the base LM head, fail to recover the gold reasoning steps or produce valid alternative steps on a test set, or if end-task accuracy at 3B scale remains below explicit CoT.
Figures

read the original abstract
Language models typically reason via explicit chain-of-thought (CoT), generating intermediate steps token-by-token. Latent CoT offers an alternative: it performs multi-step reasoning in the model's hidden states, replacing decoded tokens with continuous representations for greater efficiency. However, existing latent CoT methods underperform explicit CoT beyond 1B parameters, and the gap widens with scale. Looped, or recurrent-depth, Transformers, which reuse their weights to increase computation depth without adding parameters, are a natural fit for latent reasoning. We therefore ask whether looped Transformers can bridge this gap. We answer affirmatively with a simple recipe: a looped padded Transformer that processes K latent blocks in parallel for R iterations, with a cross-entropy loss on each latent position's gold CoT-step token, similar to explicit CoT supervision. We instantiate it as LOTUS (Looped Transformers with parallel supervision on latents). LOTUS is, to our knowledge, the first latent-CoT method to bridge the gap to explicit CoT at the 3B scale, while cutting thought-phase latency by 2.5x-6.9x from compact math expressions to natural language. Projecting LOTUS's post-loop latents through the base LM head recovers the gold reasoning steps and even surfaces alternative valid intermediate steps, evidence that its latent space is interpretable and CoT-aligned. Ablations confirm that both the looped backbone and the parallel supervision on gold CoT tokens are essential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LOTUS, a looped padded Transformer that processes K latent blocks in parallel over R iterations while applying cross-entropy supervision on gold CoT-step tokens at each latent position. It claims this architecture is the first latent-CoT method to match explicit CoT performance at the 3B scale, reduces thought-phase latency by 2.5x–6.9x, and yields interpretable post-loop latents that recover gold reasoning steps (and valid alternatives) when projected through the base LM head. Ablations are said to show that both the recurrent-depth backbone and the parallel gold-token supervision are required.
Significance. If the empirical claims hold under rigorous controls, the result would be significant: it would demonstrate that recurrent-depth Transformers plus direct latent supervision can close the long-standing performance gap between latent and explicit reasoning at practical scales, while delivering measurable latency gains and partial interpretability of the latent states.
major comments (3)
- [Experiments] Experiments section (and associated tables/figures): the central claim that LOTUS bridges the gap at 3B scale requires explicit accuracy numbers, baseline comparisons (including prior latent-CoT methods), dataset sizes, number of runs, and error bars or statistical tests; the abstract states results and ablations but supplies none of these details, leaving the magnitude and reliability of the bridging effect unsupported.
- [Ablations] Ablation study (presumably §4 or §5): the claim that the looped backbone is essential (rather than the parallel gold-token supervision being the dominant driver) must be supported by a controlled ablation that removes the gold CoT-token loss while retaining the looped structure; if accuracy then falls to the level of prior latent-CoT methods, the bridging result is attributable to the supervision regime, not the recurrent-depth innovation.
- [Method] Method description (K and R): the architecture is parameterized by the number of latent blocks K and iterations R; the paper must report how these values were chosen, whether they are held constant across scales, and whether performance remains stable when they are varied, because the abstract presents them as free parameters without quantifying sensitivity.
minor comments (2)
- [Abstract] The abstract states latency reductions of 2.5x–6.9x “from compact math expressions to natural language” without defining the measurement protocol (wall-clock time, token count, or hardware); this should be clarified in the main text and figures.
- [Method] Notation for the parallel cross-entropy loss on latent positions is introduced only informally; an explicit equation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor where needed.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and associated tables/figures): the central claim that LOTUS bridges the gap at 3B scale requires explicit accuracy numbers, baseline comparisons (including prior latent-CoT methods), dataset sizes, number of runs, and error bars or statistical tests; the abstract states results and ablations but supplies none of these details, leaving the magnitude and reliability of the bridging effect unsupported.
Authors: The full manuscript (Sections 4–5 and associated tables) already reports explicit accuracy numbers for LOTUS versus explicit CoT and prior latent-CoT baselines at the 3B scale, dataset sizes, multiple runs, and error bars. However, we agree the abstract would be strengthened by surfacing key quantitative results. We will revise the abstract to include representative accuracy figures, baseline comparisons, and a note on statistical reliability, while ensuring all tables explicitly list run counts and error bars. revision: yes
-
Referee: [Ablations] Ablation study (presumably §4 or §5): the claim that the looped backbone is essential (rather than the parallel gold-token supervision being the dominant driver) must be supported by a controlled ablation that removes the gold CoT-token loss while retaining the looped structure; if accuracy then falls to the level of prior latent-CoT methods, the bridging result is attributable to the supervision regime, not the recurrent-depth innovation.
Authors: The existing ablations demonstrate necessity of both the looped backbone and parallel supervision. We acknowledge that an explicit controlled ablation removing only the gold CoT-token loss (while retaining the looped structure) would more cleanly isolate the recurrent-depth contribution. We will add this experiment to the revised manuscript. revision: yes
-
Referee: [Method] Method description (K and R): the architecture is parameterized by the number of latent blocks K and iterations R; the paper must report how these values were chosen, whether they are held constant across scales, and whether performance remains stable when they are varied, because the abstract presents them as free parameters without quantifying sensitivity.
Authors: We will expand the Method section to describe the selection criteria for K and R, confirm they are held fixed across scales in the reported experiments, and add a sensitivity analysis quantifying performance stability under reasonable variations of these hyperparameters. revision: yes
Circularity Check
No circularity: empirical architecture validated by ablations
full rationale
The paper describes LOTUS as a concrete training recipe (looped padded Transformer with parallel cross-entropy on gold CoT-step tokens) whose performance claims rest on scale-specific experiments and component ablations at 3B parameters. No equations are presented that define a quantity in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation chain or imported uniqueness theorem. The method is self-contained through direct empirical comparison to explicit CoT baselines rather than any derivation that collapses to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- K (latent blocks)
- R (iterations)
axioms (1)
- domain assumption Looped (recurrent-depth) Transformers increase effective computation depth without adding parameters.
Reference graph
Works this paper leans on
-
[2]
2026 , url=
Ayhan Suleymanzade and Halil Alperen Gozeten and Ismail Ilkan Ceylan and Jinwoo Kim , booktitle=. 2026 , url=
2026
-
[3]
KaVa: Latent Reasoning via Compressed
Anna Kuzina and Maciej Pi. KaVa: Latent Reasoning via Compressed. The Fourteenth International Conference on Learning Representations , year=
-
[4]
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation , url =
Ahmadreza Jeddi and Marco Ciccone and Babak Taati , booktitle =. LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation , url =
-
[6]
Lightweight Latent Reasoning for Narrative Tasks
Lightweight Latent Reasoning for Narrative Tasks , url =. arXiv , author =:2512.02240 , journal =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Neural Networks as Recognizers of Formal Languages , url =
Alexandra Butoi and Ghazal Khalighinejad and Anej Svete and Josef Valvoda and Ryan Cotterell and Brian DuSell , booktitle =. Training Neural Networks as Recognizers of Formal Languages , url =
-
[8]
Language Modeling with Learned Meta-Tokens , url =
Alok Shah and Khush Gupta and Keshav Ramji and Pratik Chaudhari , booktitle =. Language Modeling with Learned Meta-Tokens , url =
-
[9]
Probability Distributions Computed by Autoregressive Transformers , url =
Andy Yang and Anej Svete and Jiaoda Li and Anthony Widjaja Lin and Jonathan Rawski and Ryan Cotterell and David Chiang , booktitle =. Probability Distributions Computed by Autoregressive Transformers , url =
-
[10]
The Transformer Cookbook , url =
Andy Yang and Christopher Watson and Anton Xue and Satwik Bhattamishra and Jose Llarena and William Merrill and Emile Dos Santos Ferreira and Anej Svete and David Chiang , issn =. The Transformer Cookbook , url =. Transactions on Machine Learning Research , note =
-
[11]
On the Reasoning Abilities of Masked Diffusion Language Models , url =
Anej Svete and Ashish Sabharwal , booktitle =. On the Reasoning Abilities of Masked Diffusion Language Models , url =
-
[13]
Limits of Continuous Chain-of-Thought in Multi-Step and Multi-Chain Reasoning , url =
Ayhan Suleymanzade and Andreas Bergmeister and Stefanie Jegelka , booktitle =. Limits of Continuous Chain-of-Thought in Multi-Step and Multi-Chain Reasoning , url =
-
[15]
Boyi Zeng and Shixiang Song and Siyuan Huang and Yixuan Wang and He Li and Ziwei He and Xinbing Wang and Zhiyu li and Zhouhan Lin , booktitle =. Ponder
-
[16]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters , url =. arXiv , author =:2408.03314 , journal =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning , url =
DiJia Su and Hanlin Zhu and Yingchen Xu and Jiantao Jiao and Yuandong Tian and Qinqing Zheng , booktitle =. Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning , url =
-
[21]
and Papailiopoulos, Dimitris , booktitle =
Giannou, Angeliki and Rajput, Shashank and Sohn, Jy-Yong and Lee, Kangwook and Lee, Jason D. and Papailiopoulos, Dimitris , booktitle =. Looped Transformers as Programmable Computers , url =
-
[22]
Neural Networks and the Chomsky Hierarchy , url =
Gregoire Deletang and Anian Ruoss and Jordi Grau-Moya and Tim Genewein and Li Kevin Wenliang and Elliot Catt and Chris Cundy and Marcus Hutter and Shane Legg and Joel Veness and Pedro A Ortega , booktitle =. Neural Networks and the Chomsky Hierarchy , url =
-
[23]
arXiv , author =:2502.12214 , journal =
Zero Token-Driven Deep Thinking in LLMs: Unlocking the Full Potential of Existing Parameters via Cyclic Refinement , url =. arXiv , author =:2502.12214 , journal =
-
[25]
Continuous Chain of Thought Enables Parallel Exploration and Reasoning , url =
Halil Alperen Gozeten and Muhammed Emrullah Ildiz and Xuechen Zhang and Hrayr Harutyunyan and Ankit Singh Rawat and Samet Oymak , booktitle =. Continuous Chain of Thought Enables Parallel Exploration and Reasoning , url =
-
[26]
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , url =
Hanlin Zhu and Shibo Hao and Zhiting Hu and Jiantao Jiao and Stuart Russell and Yuandong Tian , booktitle =. Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , url =
-
[27]
LaDiR: Latent Diffusion Enhances
Haoqiang Kang and Yizhe Zhang and Nikki Lijing Kuang and Nicklas Majamaki and Navdeep Jaitly and Yian Ma and Lianhui Qin , booktitle =. LaDiR: Latent Diffusion Enhances
-
[32]
Let's Verify Step by Step , url =. arXiv , author =:2305.20050 , journal =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv , author =:2604.02051 , journal =
Ouroboros: Dynamic Weight Generation for Recursive Transformers via Input-Conditioned LoRA Modulation , url =. arXiv , author =:2604.02051 , journal =
-
[36]
Bowman , booktitle =
Jacob Pfau and William Merrill and Samuel R. Bowman , booktitle =. Let
-
[38]
Unique Hard Attention: A Tale of Two Sides , url =
Jerad, Selim and Svete, Anej and Li, Jiaoda and Cotterell, Ryan , booktitle =. Unique Hard Attention: A Tale of Two Sides , url =. doi:10.18653/v1/2025.acl-short.76 , editor =
-
[44]
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connections to Diffusion Language Models , url =
Jonas Geiping and Xinyu Yang and Guinan Su , booktitle =. Efficient Parallel Samplers for Recurrent-Depth Models and Their Connections to Diffusion Language Models , url =
-
[49]
A Formal Comparison Between Chain-of-Thought and Latent Thought , url =
Kevin Xu and Issei Sato , journal =. A Formal Comparison Between Chain-of-Thought and Latent Thought , url =
-
[52]
Deliberation in Latent Space via Differentiable Cache Augmentation , url =
Luyang Liu and Jonas Pfeiffer and Jiaxing Wu and Jun Xie and Arthur Szlam , booktitle =. Deliberation in Latent Space via Differentiable Cache Augmentation , url =
-
[54]
Dynamic Parameter Reuse Augments Reasoning via Latent Chain of Thought , url =
Maile, Kaitlin and Sacramento, João , booktitle =. Dynamic Parameter Reuse Augments Reasoning via Latent Chain of Thought , url =
-
[55]
The Illusion of Superposition in Latent CoT via Soft Thinking , url =
Michael Rizvi-Martel and Marius Mosbach , booktitle =. The Illusion of Superposition in Latent CoT via Soft Thinking , url =
-
[57]
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages , year =
Nadav Borenstein and Anej Svete and Robin Chan and Josef Valvoda and Franz Nowak and Isabelle Augenstein and Eleanor Chodroff and Ryan Cotterell , month = aug, publisher =. What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages , year =
-
[58]
s1: Simple test-time scaling , url =. arXiv , author =:2501.19393 , journal =
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Reddi , booktitle =
Nikunj Saunshi and Nishanth Dikkala and Zhiyuan Li and Sanjiv Kumar and Sashank J. Reddi , booktitle =. Reasoning with Latent Thoughts: On the Power of Looped Transformers , url =
-
[62]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , title =
R. The Thirty-ninth Annual Conference on Neural Information Processing Systems , title =
-
[63]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , title =
R. The Thirty-eighth Annual Conference on Neural Information Processing Systems , title =
-
[65]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , title =
Robin Chan and Reda Boumasmoud and Anej Svete and Yuxin Ren and Qipeng Guo and Zhijing Jin and Shauli Ravfogel and Mrinmaya Sachan and Bernhard Sch. The Thirty-eighth Annual Conference on Neural Information Processing Systems , title =
-
[69]
arXiv , author =:2311.04329 , primaryclass =
Formal Aspects of Language Modeling , url =. arXiv , author =:2311.04329 , primaryclass =
-
[70]
Think before you speak: Training Language Models With Pause Tokens , url =
Sachin Goyal and Ziwei Ji and Ankit Singh Rawat and Aditya Krishna Menon and Sanjiv Kumar and Vaishnavh Nagarajan , booktitle =. Think before you speak: Training Language Models With Pause Tokens , url =
-
[71]
Clair and Paul Fodor and Chihiro Shibata and Jeffrey Heinz , journal =
Sam van der Poel and Dakotah Lambert and Kalina Kostyszyn and Tiantian Gao and Rahul Verma and Derek Andersen and Joanne Chau and Emily Peterson and Cody St. Clair and Paul Fodor and Chihiro Shibata and Jeffrey Heinz , journal =. MLRegTest: A Benchmark for the Machine Learning of Regular Languages , url =
-
[72]
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise Lo
Sangmin Bae and Adam Fisch and Hrayr Harutyunyan and Ziwei Ji and Seungyeon Kim and Tal Schuster , booktitle =. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise Lo
-
[73]
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation , url =
Sangmin Bae and Yujin Kim and Reza Bayat and Sungnyun Kim and Jiyoun Ha and Tal Schuster and Adam Fisch and Hrayr Harutyunyan and Ziwei Ji and Aaron Courville and Se-Young Yun , booktitle =. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation , url =
-
[77]
Training Large Language Models to Reason in a Continuous Latent Space , url =
Shibo Hao and Sainbayar Sukhbaatar and DiJia Su and Xian Li and Zhiting Hu and Jason E Weston and Yuandong Tian , booktitle =. Training Large Language Models to Reason in a Continuous Latent Space , url =
-
[80]
Targeted Syntactic Evaluation on the
Someya, Taiga and Yoshida, Ryo and Oseki, Yohei , booktitle =. Targeted Syntactic Evaluation on the
-
[81]
What Formal Languages Can Transformers Express? A Survey , url =
Strobl, Lena and Merrill, William and Weiss, Gail and Chiang, David and Angluin, Dana , doi =. What Formal Languages Can Transformers Express? A Survey , url =. Transactions of the Association for Computational Linguistics , pages =
-
[83]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Łukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[84]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , booktitle =. Chain-of-thought prompting elicits reasoning in large language models , year =
-
[85]
Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization , url =
Wengao Ye and Yan Liang and Lianlei Shan , booktitle =. Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization , url =
-
[86]
Think Silently, Think Fast: Dynamic Latent Compression of
Wenhui Tan and Jiaze Li and Jianzhong Ju and Zhenbo Luo and Ruihua Song and Jian Luan , booktitle =. Think Silently, Think Fast: Dynamic Latent Compression of
-
[87]
A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers , url =
William Merrill and Ashish Sabharwal , booktitle =. A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers , url =
-
[88]
Exact Expressive Power of Transformers with Padding , url =
William Merrill and Ashish Sabharwal , booktitle =. Exact Expressive Power of Transformers with Padding , url =
-
[89]
The Expressive Power of Transformers with Chain of Thought , url =
William Merrill and Ashish Sabharwal , booktitle =. The Expressive Power of Transformers with Chain of Thought , url =
-
[94]
Guiding Language Model Reasoning with Planning Tokens , url =
Xinyi Wang and Lucas Caccia and Oleksiy Ostapenko and Xingdi Yuan and William Yang Wang and Alessandro Sordoni , booktitle =. Guiding Language Model Reasoning with Planning Tokens , url =
-
[97]
AlgoFormer: An Efficient Transformer Framework with Algorithmic Structures , url =
Yihang Gao and Chuanyang Zheng and Enze Xie and Han Shi and Tianyang Hu and Yu Li and Michael Ng and Zhenguo Li and Zhaoqiang Liu , issn =. AlgoFormer: An Efficient Transformer Framework with Algorithmic Structures , url =. Transactions on Machine Learning Research , note =
-
[98]
Evaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
Evaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy , url =. arXiv , author =:2604.02709 , journal =
work page internal anchor Pith review Pith/arXiv arXiv
-
[99]
Looped Transformers for Length Generalization , url =
Ying Fan and Yilun Du and Kannan Ramchandran and Kangwook Lee , booktitle =. Looped Transformers for Length Generalization , url =
-
[101]
SemCoT: Accelerating Chain-of-Thought Reasoning through Semantically-Aligned Implicit Tokens , url =
Yinhan He and Wendy Zheng and Yaochen Zhu and Zaiyi Zheng and Lin Su and Sriram Vasudevan and Qi Guo and Liangjie Hong and Jundong Li , booktitle =. SemCoT: Accelerating Chain-of-Thought Reasoning through Semantically-Aligned Implicit Tokens , url =
-
[102]
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning , url =
Yu, Qifan and He, Zhenyu and Li, Sijie and Xun, Zhou and Zhang, Jun and Xu, Jingjing and He, Di , booktitle =. Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning , url =. doi:10.18653/v1/2026.eacl-long.97 , editor =
-
[106]
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , url =
Zhiyuan Li and Hong Liu and Denny Zhou and Tengyu Ma , booktitle =. Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , url =
-
[107]
Language models are unsupervised multitask learners , author=
-
[109]
Unlocking out-of-distribution generalization in transformers via recursive latent space reasoning
Awni Altabaa, Siyu Chen, John Lafferty, and Zhuoran Yang. Unlocking out-of-distribution generalization in transformers via recursive latent space reasoning. arXiv preprint arXiv:2510.14095, 2025. URL https://arxiv.org/abs/2510.14095
-
[110]
Latent reasoning with supervised thinking states
Ido Amos, Avi Caciularu, Mor Geva, Amir Globerson, Jonathan Herzig, Lior Shani, and Idan Szpektor. Latent reasoning with supervised thinking states. arXiv preprint arXiv:2602.08332, 2026. URL https://arxiv.org/abs/2602.08332
-
[111]
Relaxed recursive transformers: Effective parameter sharing with layer-wise lo RA
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lo RA . In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=WwpYSOkkCt
2025
-
[112]
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b . URL https://openreview...
2025
-
[113]
Thinking deeper, not longer: Depth-recurrent transformers for compositional generalization
Hung-Hsuan Chen. Thinking deeper, not longer: Depth-recurrent transformers for compositional generalization. arXiv preprint arXiv:2603.21676, 2026. URL https://arxiv.org/abs/2603.21676
-
[114]
arXiv preprint arXiv:2505.16782 (2025)
Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Hanlin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, and Xiaoyu Shen. Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning. arXiv preprint arXiv:2505.16782, 2025 a . URL https://arxiv.org/abs/2505.16782
-
[115]
Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking
Yilong Chen, Junyuan Shang, Zhenyu Zhang, Yanxi Xie, Jiawei Sheng, Tingwen Liu, Shuohuan Wang, Yu Sun, Hua Wu, and Haifeng Wang. Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting o...
-
[116]
Think consistently, reason efficiently: Energy-based calibration for implicit chain-of-thought
Zhikang Chen, Sen Cui, Deheng Ye, Yu Zhang, Yatao Bian, and Tingting Zhu. Think consistently, reason efficiently: Energy-based calibration for implicit chain-of-thought. arXiv preprint arXiv:2511.07124, 2025 c . URL https://arxiv.org/abs/2511.07124
-
[117]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Jeffrey Cheng and Benjamin Van Durme. Compressed chain of thought: Efficient reasoning through dense representations. arXiv preprint arXiv:2412.13171, 2024. URL https://arxiv.org/abs/2412.13171
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[118]
Yunlong Chu, Minglai Shao, Yuhang Liu, Bing Hao, Yumeng Lin, Jialu Wang, and Ruijie Wang. Spot: Span-level pause-of-thought for efficient and interpretable latent reasoning in large language models. arXiv preprint arXiv:2603.06222, 2026. URL https://arxiv.org/abs/2603.06222
-
[119]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[120]
Mo EUT : Mixture-of-experts universal transformers
R \'o bert Csord \'a s, Kazuki Irie, J \"u rgen Schmidhuber, Christopher Potts, and Christopher D Manning. Mo EUT : Mixture-of-experts universal transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ZxVrkm7Bjl
2024
-
[121]
Do language models use their depth efficiently? In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
R \'o bert Csord \'a s, Christopher D Manning, and Christopher Potts. Do language models use their depth efficiently? In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=Kz6eUL86XP
2025
-
[122]
Yingqian Cui, Zhenwei Dai, Bing He, Zhan Shi, Hui Liu, Rui Sun, Zhiji Liu, Yue Xing, Jiliang Tang, and Benoit Dumoulin. How do latent reasoning methods perform under weak and strong supervision? arXiv preprint arXiv:2602.22441, 2026. URL https://arxiv.org/abs/2602.22441
-
[123]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
DeepSeek-AI. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645 0 (8081): 0 633--638, Sep 2025. ISSN 1476-4687. doi:10.1038/s41586-025-09422-z. URL https://doi.org/10.1038/s41586-025-09422-z
-
[124]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2019. URL https://arxiv.org/abs/1807.03819
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[125]
Llm latent reasoning as chain of superposition
Jingcheng Deng, Liang Pang, Zihao Wei, Shicheng Xu, Zenghao Duan, Kun Xu, Yang Song, Huawei Shen, and Xueqi Cheng. Llm latent reasoning as chain of superposition. arXiv preprint arXiv:2510.15522, 2026. URL https://arxiv.org/abs/2510.15522
-
[126]
Implicit chain of thought reasoning via knowledge distillation
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation. arXiv preprint arXiv:2311.01460, 2023
-
[127]
Looped transformers for length generalization
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=2edigk8yoU
2025
-
[128]
Efficient reasoning models: A survey
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient reasoning models: A survey. arXiv preprint arXiv:2504.10903, 2025. URL https://arxiv.org/abs/2504.10903
-
[129]
SeLaR: Selective Latent Reasoning in Large Language Models
Renyu Fu and Guibo Luo. Selar: Selective latent reasoning in large language models. arXiv preprint arXiv:2604.08299, 2026. URL https://arxiv.org/abs/2604.08299
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[130]
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Tianyu Fu, Yichen You, Zekai Chen, Guohao Dai, Huazhong Yang, and Yu Wang. Think-at-hard: Selective latent iterations to improve reasoning language models. arXiv preprint arXiv:2511.08577, 2025. URL https://arxiv.org/abs/2511.08577
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[131]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025 a . URL https://arxiv.org/abs/2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.