PRISM: Feed-Forward Single-Image 3D Reconstruction via Geometric Warp-Residual Modeling
Pith reviewed 2026-06-25 20:52 UTC · model grok-4.3
The pith
PRISM reconstructs 3D scenes from one image by applying geometric forward warping as the main prior then learning only the compact residual correction, eliminating diffusion sampling at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
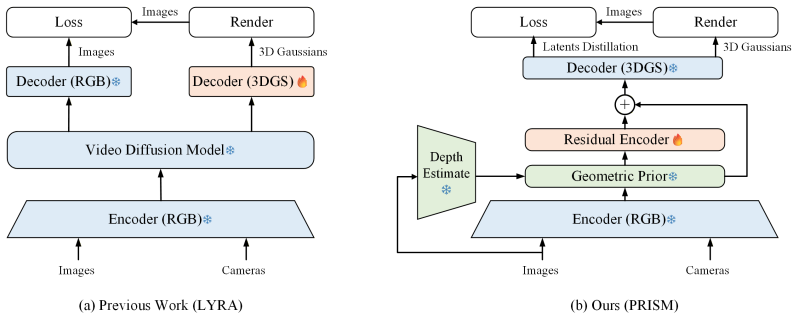
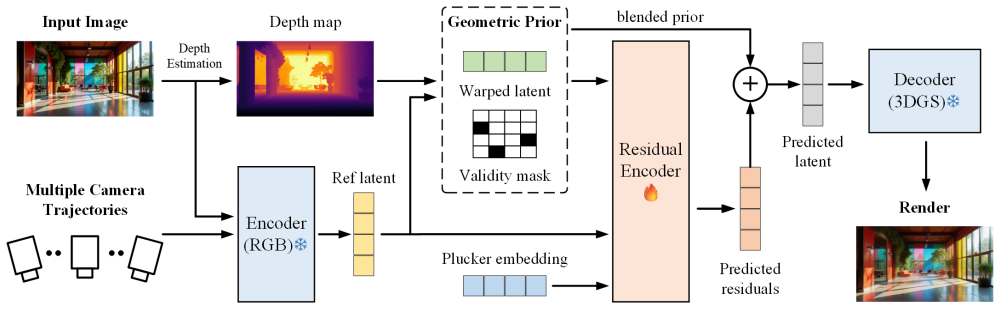
PRISM decomposes multi-view latent prediction into a parameter-free geometric forward warp from the input image plus a learned residual correction produced by an encoder, forming a fully feed-forward pipeline that requires no diffusion sampling at test time and generalizes from purely synthetic data through a two-stage training process of latent-supervised distillation followed by perceptual fine-tuning.
What carries the argument
Geometric warp-residual modeling, in which parameter-free forward warping supplies the dominant geometric prior and a compact learned residual encoder supplies only the remaining appearance and detail corrections for target views.
If this is right
- Reconstruction quality remains competitive with diffusion-based methods across three standard benchmarks.
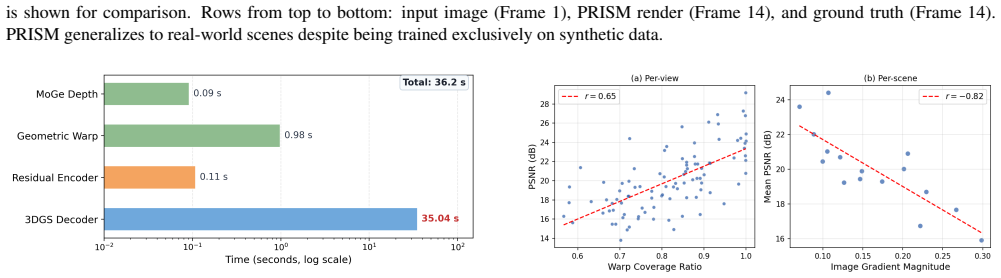
- Inference requires only 36 seconds per scene because no iterative diffusion sampling occurs.
- Training succeeds on purely synthetic data when the two-stage strategy of latent distillation then perceptual fine-tuning is used.
- The resulting feed-forward model supports applications in virtual reality, robotics, and content creation that need fast single-image 3D output.
Where Pith is reading between the lines
- The explicit separation of geometry and residual may allow targeted fixes for common failure modes such as specular highlights or thin structures without retraining the entire model.
- Because the warp step is parameter-free, the same decomposition could be tested on video input by propagating the warp across frames before applying residual correction.
- If the residual encoder stays small, the approach might be quantized or distilled further for deployment on mobile or embedded devices.
Load-bearing premise
Geometric forward warping from the single input image already covers the majority of each target view, leaving only a small residual that the model must learn to correct.
What would settle it
A direct comparison showing that PRISM's rendered views lose substantially more detail than diffusion baselines on real-world scenes containing large occlusions or strong viewpoint changes would falsify the claim that warping covers the majority.
Figures




read the original abstract
Reconstructing 3D scenes from a single image is a fundamental challenge in computer vision, with broad applications in virtual reality, robotics, and content creation. Recent methods achieve outstanding performance by leveraging camera-controlled video diffusion models, but rely on iterative diffusion sampling, which greatly limits their practical deployment. We observe that geometric forward warping alone can cover the majority of a target view directly from the input image, with only a compact residual left for the encoder to correct. Motivated by this observation, we propose PRISM, a feed-forward framework that decomposes multi-view latent prediction into a parameter-free geometric prior and a learned residual correction, with no diffusion sampling required at inference. To enable generalization from purely synthetic training data, we devise a two-stage training strategy combining latents supervised distillation for geometric generalization and perceptual fine-tuning for appearance quality optimization. Extensive experiments on three benchmarks demonstrate that PRISM achieves competitive reconstruction quality compared with diffusion-based methods, while reducing inference time dramatically to only 36 seconds per scene.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, a feed-forward single-image 3D reconstruction framework that decomposes multi-view latent prediction into a parameter-free geometric forward warping prior plus a learned residual correction. It introduces a two-stage training strategy (latents supervised distillation followed by perceptual fine-tuning) to generalize from synthetic data and claims competitive reconstruction quality versus diffusion-based methods with a 36-second inference time per scene on three benchmarks.
Significance. If the central claims hold with supporting evidence, the work would be significant for enabling practical deployment of single-image 3D reconstruction in VR, robotics, and content creation by eliminating iterative diffusion sampling while preserving quality.
major comments (2)
- [Abstract] Abstract: The central claim that PRISM achieves competitive reconstruction quality compared with diffusion-based methods is unsupported, as the manuscript provides no quantitative results, error metrics, tables, or experimental details to substantiate performance on the three benchmarks.
- [Training strategy description] The two-stage training strategy is described only at a high level with no specifics on loss functions, hyperparameters, distillation targets, or how the stages enable generalization from synthetic data, which is load-bearing for the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of results and training details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that PRISM achieves competitive reconstruction quality compared with diffusion-based methods is unsupported, as the manuscript provides no quantitative results, error metrics, tables, or experimental details to substantiate performance on the three benchmarks.
Authors: We agree that the abstract's claim requires explicit supporting evidence to be fully substantiated. The current manuscript text focuses on the high-level description and does not include the quantitative tables or metrics in the provided sections. In the revision, we will add a dedicated results section with error metrics (e.g., PSNR, SSIM, LPIPS), comparison tables against diffusion-based baselines on the three benchmarks, and direct references from the abstract to these tables. This will make the competitive quality claim verifiable. revision: yes
-
Referee: [Training strategy description] The two-stage training strategy is described only at a high level with no specifics on loss functions, hyperparameters, distillation targets, or how the stages enable generalization from synthetic data, which is load-bearing for the generalization claim.
Authors: We acknowledge that the description in the manuscript is high-level and lacks the requested specifics, which weakens the generalization claim. In the revised version, we will expand the relevant section to detail the loss functions (supervised L1 distillation on latents in stage one, combined with perceptual and adversarial losses in stage two), specific hyperparameters, distillation targets (rendered multi-view latents from synthetic scenes), and the mechanism by which stage one promotes geometric invariance while stage two refines appearance. We will also add ablations demonstrating the contribution of each stage to generalization. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core claim rests on an empirical observation that geometric forward warping covers most of a target view, leaving a compact residual for learned correction. This is presented as a parameter-free prior, with the residual handled by a separate encoder trained in two stages (distillation then perceptual fine-tuning). No equations, predictions, or uniqueness claims reduce to self-definition, fitted inputs renamed as outputs, or load-bearing self-citations. The geometric component is explicitly non-learned, and training generalizes from synthetic data without internal fitting loops. This matches the default expectation of non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LYRA: Gen- erative 3D scene reconstruction via video diffusion model self-distillation, 2025
Sherwin Bahmani, Tianchang Shen, Jiawei Ren, Jiahui Huang, Yifeng Jiang, Haithem Turki, Andrea Tagliasacchi, David B Lindell, Zan Gojcic, Sanja Fidler, et al. LYRA: Gen- erative 3D scene reconstruction via video diffusion model self-distillation, 2025. 1, 2, 3, 6, 7, 8
2025
-
[2]
FWD: Real-time novel view synthesis with forward warping and depth
Ang Cao, Chris Rockwell, and Justin Johnson. FWD: Real-time novel view synthesis with forward warping and depth. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 15713– 15724, 2022. 3
2022
-
[3]
pixelsplat: 3D Gaussian splats from im- age pairs for scalable generalizable 3D reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3D Gaussian splats from im- age pairs for scalable generalizable 3D reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2024. 3
2024
-
[4]
MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 14124–14133,
-
[5]
MVSplat: Efficient 3D Gaussian Splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. MVSplat: Efficient 3D Gaussian Splatting from sparse multi-view images. InProceedings of the European Confer- ence on Computer Vision (ECCV), 2024. 3
2024
-
[6]
CAT3D: Create anything in 3D with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. CAT3D: Create anything in 3D with multi-view diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3
2024
-
[7]
VFusion3D: Learning scalable 3D generative models from video diffu- sion models
Junlin Han, Filippos Kokkinos, and Philip Torr. VFusion3D: Learning scalable 3D generative models from video diffu- sion models. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 3
2024
-
[8]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2020. 3
2020
-
[9]
LRM: Large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. InProceedings of the International Conference on Learning Representations (ICLR), 2024. 2, 3
2024
-
[10]
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
Roni Itkin et al. Globalsplat: Efficient feed-forward 3D gaussian splatting via global scene tokens.arXiv preprint arXiv:2604.15284, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
AnySplat: Feed-forward 3D Gaussian Splatting from unconstrained views.ACM Transactions on Graphics, 44(6):1–16, 2025
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. AnySplat: Feed-forward 3D Gaussian Splatting from unconstrained views.ACM Transactions on Graphics, 44(6):1–16, 2025. SIGGRAPH Asia 2025. 3
2025
-
[12]
3D Gaussian Splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian Splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 2, 3
2023
-
[13]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017. 6
2017
-
[14]
MASt3R: Grounding image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jerome Revaud. MASt3R: Grounding image matching in 3D with MASt3R. InProceedings of the European Conference on Computer Vi- sion (ECCV), 2024. 2, 3
2024
-
[15]
Yihui Li et al. Tokensplat: Token-aligned 3D gaussian splatting for feed-forward pose-free reconstruction.arXiv preprint arXiv:2603.00697, 2026. 3
-
[16]
Wonderland: Nav- igating 3D scenes from a single image
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N Pla- taniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Nav- igating 3D scenes from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3, 6, 7
2025
-
[17]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 6
2024
-
[19]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Repre- sentations (ICLR), 2023. 3
2023
-
[20]
One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimiza- tion
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimiza- tion. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 3
2023
-
[21]
Zero-1-to- 3: Zero-shot one image to 3D object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to- 3: Zero-shot one image to 3D object. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 3
2023
-
[22]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Rep- resentations (ICLR), 2023. 3
2023
-
[23]
SyncDreamer: Gen- erating multiview-consistent images from a single-view im- age
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. SyncDreamer: Gen- erating multiview-consistent images from a single-view im- age. InProceedings of the International Conference on Learning Representations (ICLR), 2024. 3
2024
-
[24]
Wonder3d: Single image to 3D using cross-domain diffu- sion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3d: Single image to 3D using cross-domain diffu- sion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 9970– 9980, 2024. 3 9
2024
-
[25]
DPM-Solver: A fast ODE solver for diffu- sion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffu- sion probabilistic model sampling in around 10 steps. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[26]
Scaffold-GS: Structured 3D gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-GS: Structured 3D gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 20654–20664, 2024. 2
2024
-
[27]
NeRF: Representing scenes as neural radiance fields for view syn- thesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view syn- thesis. InProceedings of the European Conference on Com- puter Vision (ECCV), 2020. 2, 3
2020
-
[28]
Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM Transactions on Graphics (SIGGRAPH), 41(4):102:1–102:15, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM Transactions on Graphics (SIGGRAPH), 41(4):102:1–102:15, 2022. 2
2022
-
[29]
Cosmos world foundation model platform for physical AI, 2025
NVIDIA. Cosmos world foundation model platform for physical AI, 2025. 2
2025
-
[30]
Gen3C: 3D-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M ¨uller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3C: 3D-informed world-consistent video generation with precise camera con- trol. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2025. 2, 3, 6
2025
-
[31]
Fouhey, and Justin Johnson
Chris Rockwell, David F. Fouhey, and Justin Johnson. Pixel- Synth: Generating a 3D-consistent experience from a single image. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 14104–14113,
-
[32]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3
2022
-
[33]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InProceedings of the In- ternational Conference on Learning Representations (ICLR),
-
[34]
ZeroNVS: Zero-shot 360- degree view synthesis from a single image
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry La- gun, Li Fei-Fei, Deqing Sun, et al. ZeroNVS: Zero-shot 360- degree view synthesis from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3, 6, 7
2024
-
[35]
GenWarp: Single image to novel views with semantic-preserving generative warp- ing
Junyoung Seo, Kazumi Fukuda, Takashi Shibuya, Takuya Narihira, Naoki Murata, Shoukang Hu, Chieh-Hsin Lai, Se- ungryong Kim, and Yuki Mitsufuji. GenWarp: Single image to novel views with semantic-preserving generative warp- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3
2024
-
[36]
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: A single image to consistent multi-view dif- fusion base model.arXiv preprint arXiv:2310.15110, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
3D photography using context-aware layered depth inpainting
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 3D photography using context-aware layered depth inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[38]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InProceedings of the Inter- national Conference on Learning Representations (ICLR),
-
[39]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InProceedings of the In- ternational Conference on Machine Learning (ICML), 2023. 3
2023
-
[40]
A VGGT: Rethinking global attention for accelerating VGGT
Xianbing Sun, Zhikai Zhu, Zhengyu Lou, Bo Yang, Jinyang Tang, Liqing Zhang, He Wang, and Jianfu Zhang. A VGGT: Rethinking global attention for accelerating VGGT. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 3
2026
-
[41]
Splatter image: Ultra-fast single-view 3D recon- struction
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Splatter image: Ultra-fast single-view 3D recon- struction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[42]
Flash3D: Feed-forward gen- eralisable 3D scene reconstruction from a single image
Stanislaw Szymanowicz, Eldar Insafutdinov, Chuanxia Zheng, Dylan Campbell, Jo ˜ao F Henriques, Christian Rup- precht, and Andrea Vedaldi. Flash3D: Feed-forward gen- eralisable 3D scene reconstruction from a single image. In Proceedings of the International Conference on 3D Vision (3DV), 2025. 3
2025
-
[43]
Bolt3D: Generating 3D scenes in seconds
Stanislaw Szymanowicz, Jason Y Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T Barron, and Philipp Henzler. Bolt3D: Generating 3D scenes in seconds. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 24846–24857, 2025. 2, 3
2025
-
[44]
Single-view view synthe- sis with multiplane images
Richard Tucker and Noah Snavely. Single-view view synthe- sis with multiplane images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[45]
Wan: Open and advanced large-scale video gen- erative models, 2025
Wan Team. Wan: Open and advanced large-scale video gen- erative models, 2025. 2
2025
-
[46]
VideoScene: Distilling video diffusion model to generate 3D scenes in one step
Hanyang Wang, Fangfu Liu, Jiawei Chi, and Yueqi Duan. VideoScene: Distilling video diffusion model to generate 3D scenes in one step. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 16475–16485, 2025. 3
2025
-
[47]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3
2025
-
[48]
Srinivasan, Howard Zhou, Jonathan T
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. IBRNet: Learning multi-view image-based rendering. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 4690–4699,
-
[49]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5261–5271, 2025. 2, 4
2025
-
[50]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[51]
SynSin: End-to-end view synthesis from a sin- gle image
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. SynSin: End-to-end view synthesis from a sin- gle image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[52]
Srinivasan, Dor Verbin, Jonathan T
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P. Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, and Aleksander Hoły´nski. ReconFusion: 3D reconstruction with diffusion priors. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 21551– 21561, 2024. 3
2024
-
[53]
DepthSplat: Connecting Gaussian Splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. DepthSplat: Connecting Gaussian Splatting and depth. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2025. 3
2025
-
[54]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4578–4587,
-
[55]
ViewCrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (TPAMI),
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. ViewCrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transac- tions on Pattern Analysis and Machine Intelligence (TPAMI),
-
[56]
GS-LRM: Large recon- struction model for 3D Gaussian Splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. GS-LRM: Large recon- struction model for 3D Gaussian Splatting. InProceedings of the European Conference on Computer Vision (ECCV),
-
[57]
Stereo magnification: Learning view synthesis using multiplane images.ACM Transactions on Graphics (SIGGRAPH), 37(4), 2018
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.ACM Transactions on Graphics (SIGGRAPH), 37(4), 2018. 1, 6 11
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.