A neurally plausible model learns successor representations in partially observable environments
Pith reviewed 2026-05-25 17:53 UTC · model grok-4.3
The pith
A model extends the distributed distributional code to successor features, enabling neurally plausible reinforcement learning from noisy partial observations where direct policy learning fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a neurally plausible model using distributional successor features, which builds on the distributed distributional code for the representation and computation of uncertainty, and which allows for efficient value function computation in partially observed environments via the successor representation. We show that distributional successor features can support reinforcement learning in noisy environments in which direct learning of successful policies is infeasible.
What carries the argument
Distributional successor features: an extension of the distributed distributional code that represents uncertainty over future states to compute values under partial observability.
If this is right
- Enables efficient value function computation without requiring full state observability.
- Supports rapid adaptation when the reward function or goal locations change.
- Yields successful policies in noisy settings where direct learning of policies is infeasible.
- Produces representations whose features match patterns seen in neural responses.
Where Pith is reading between the lines
- The same code could be tested for its ability to handle multi-step planning under sensory noise in larger state spaces.
- If neural recordings show population codes matching the distributional successor features during partial-observation tasks, that would align with the model's predictions.
- The framework suggests a route to combine successor representations with other forms of uncertainty propagation in sequential decision problems.
Load-bearing premise
The distributed distributional code for uncertainty can be extended to successor features while preserving neural plausibility and enabling efficient computation in partially observed settings.
What would settle it
A simulation of a noisy partially observable task in which the model produces no better policies than direct policy learning methods that the paper claims are infeasible.
Figures

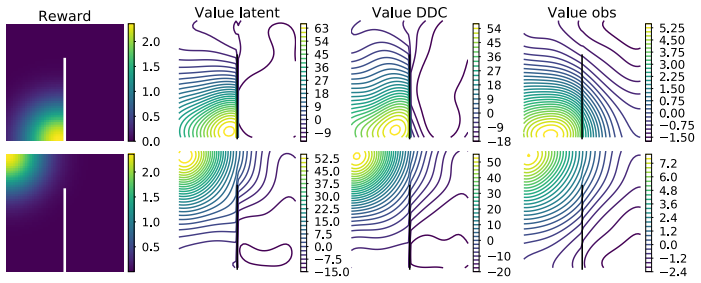
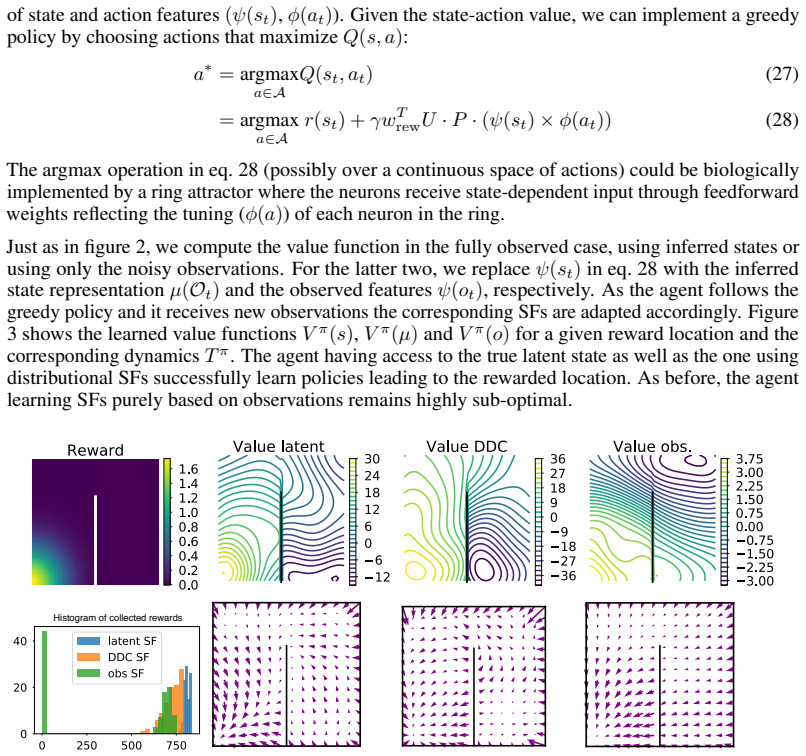
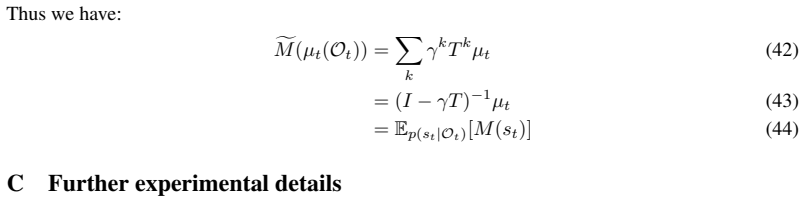
read the original abstract
Animals need to devise strategies to maximize returns while interacting with their environment based on incoming noisy sensory observations. Task-relevant states, such as the agent's location within an environment or the presence of a predator, are often not directly observable but must be inferred using available sensory information. Successor representations (SR) have been proposed as a middle-ground between model-based and model-free reinforcement learning strategies, allowing for fast value computation and rapid adaptation to changes in the reward function or goal locations. Indeed, recent studies suggest that features of neural responses are consistent with the SR framework. However, it is not clear how such representations might be learned and computed in partially observed, noisy environments. Here, we introduce a neurally plausible model using distributional successor features, which builds on the distributed distributional code for the representation and computation of uncertainty, and which allows for efficient value function computation in partially observed environments via the successor representation. We show that distributional successor features can support reinforcement learning in noisy environments in which direct learning of successful policies is infeasible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neurally plausible model that extends the distributed distributional code to successor features, enabling learning of successor representations (SR) in partially observable environments. It claims this approach supports efficient value function computation and reinforcement learning in noisy POMDPs where direct policy learning is infeasible, building on prior work on distributional codes for uncertainty representation.
Significance. If the simulations and derivations hold, the work provides a concrete mechanism linking neural uncertainty representations to SR-based RL, offering potential explanations for biological value computation in uncertain settings and a practical algorithm for POMDPs. The modeling proposal is grounded in existing frameworks and addresses a clear gap in applying SR to partial observability.
minor comments (3)
- The abstract and introduction would benefit from a brief explicit statement of the key equations defining the distributional successor features (e.g., how the code for successor distributions is updated) to allow readers to assess the extension from the base distributed distributional code without immediately consulting the methods.
- Figure captions should include more detail on simulation parameters, such as noise levels in observations and number of trials, to make the results in the POMDP experiments reproducible from the figures alone.
- Notation for the successor features and value computation should be unified across sections; currently the transition from the standard SR to the distributional version is not always signposted with equation references.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the accurate summary of our contribution, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
Minor self-citation to prior distributional code work; central model extension remains independent
full rationale
The paper introduces a new model for distributional successor features in POMDPs by extending the distributed distributional code. It explicitly references building on that prior framework, but the abstract presents the extension itself (neural plausibility, efficient value computation via SR, support for RL where direct policies fail) as the novel contribution without any shown equations, fitted parameters, or self-defined terms that reduce the claimed result to its inputs by construction. No load-bearing uniqueness theorems, ansatzes, or renaming of known results are evident from the provided text. This is a standard modeling proposal whose support would be evaluated externally; the self-citation is not circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters for feature learning and distribution parameters
axioms (1)
- domain assumption The distributed distributional code provides a neurally plausible representation of uncertainty that can be extended to successor features.
Reference graph
Works this paper leans on
-
[1]
Andr \'e Barreto, Will Dabney, R \'e mi Munos, Jonathan J. Hunt, Tom Schaul, Hado P. van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. In Advances in neural information processing systems, pages 4055--4065, 2017
work page 2017
-
[2]
Transfer in Deep Reinforcement Learning Using Successor Features and Generalised Policy Improvement
Andr \'e Barreto, Diana Borsa, John Quan, Tom Schaul, David Silver, Matteo Hessel, Daniel Mankowitz, Augustin Z \'i dek, and R \'e mi Munos. Transfer in Deep Reinforcement Learning Using Successor Features and Generalised Policy Improvement . arXiv:1901.10964 [cs], January 2019. URL http://arxiv.org/abs/1901.10964. arXiv: 1901.10964
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[3]
Daw, Yael Niv, and Peter Dayan
Nathaniel D. Daw, Yael Niv, and Peter Dayan. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature Neuroscience, 8 0 (12): 0 1704, December 2005. ISSN 1546-1726. doi:10.1038/nn1560. URL https://www.nature.com/articles/nn1560
-
[4]
Nathaniel D. Daw, Samuel J. Gershman, Ben Seymour, Peter Dayan, and Raymond J. Dolan. Model- Based Influences on Humans ' Choices and Striatal Prediction Errors . Neuron, 69 0 (6): 0 1204--1215, March 2011. ISSN 0896-6273. doi:10.1016/j.neuron.2011.02.027. URL http://www.sciencedirect.com/science/article/pii/S0896627311001255
-
[5]
Improving Generalization for Temporal Difference Learning : The Successor Representation
Peter Dayan. Improving Generalization for Temporal Difference Learning : The Successor Representation . Neural Computation, 5 0 (4): 0 613--624, July 1993. ISSN 0899-7667. doi:10.1162/neco.1993.5.4.613. URL https://doi.org/10.1162/neco.1993.5.4.613
-
[6]
Peter Dayan and Nathaniel D. Daw. Decision theory, reinforcement learning, and the brain. Cognitive, Affective, & Behavioral Neuroscience, 8 0 (4): 0 429--453, December 2008. ISSN 1531-135X. doi:10.3758/CABN.8.4.429. URL https://doi.org/10.3758/CABN.8.4.429
-
[7]
Samuel J. Gershman. The Successor Representation : Its Computational Logic and Neural Substrates . J. Neurosci., 38 0 (33): 0 7193--7200, August 2018. ISSN 0270-6474, 1529-2401. doi:10.1523/JNEUROSCI.0151-18.2018. URL http://www.jneurosci.org/content/38/33/7193
-
[8]
Jan Gl \"a scher, Nathaniel Daw, Peter Dayan, and John P. O'Doherty. States versus Rewards : Dissociable Neural Prediction Error Signals Underlying Model - Based and Model - Free Reinforcement Learning . Neuron, 66 0 (4): 0 585--595, May 2010. ISSN 0896-6273. doi:10.1016/j.neuron.2010.04.016. URL http://www.sciencedirect.com/science/article/pii/S0896627310002874
-
[9]
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Sch \"o lkopf, and Alexander Smola. A Kernel Two - Sample Test . Journal of Machine Learning Research, 13: 0 723--773, March 2012. URL http://jmlr.csail.mit.edu/papers/v13/gretton12a.html
work page 2012
-
[10]
G E Hinton, P Dayan, B J Frey, and R M Neal. The "wake-sleep" algorithm for unsupervised neural networks. Science, 268 0 (5214): 0 1158--1161, May 1995. ISSN 0036-8075
work page 1995
-
[11]
Deep Successor Reinforcement Learning
Tejas D. Kulkarni, Ardavan Saeedi, Simanta Gautam, and Samuel J. Gershman. Deep Successor Reinforcement Learning . arXiv:1606.02396 [cs, stat], June 2016. URL http://arxiv.org/abs/1606.02396. arXiv: 1606.02396
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Marcelo G. Mattar and Nathaniel D. Daw. Prioritized memory access explains planning and hippocampal replay. Nature Neuroscience, 21 0 (11): 0 1609, November 2018. ISSN 1546-1726. doi:10.1038/s41593-018-0232-z. URL https://www.nature.com/articles/s41593-018-0232-z
-
[13]
Dorsal hippocampus contributes to model-based planning
Kevin J Miller, Matthew M Botvinick, and Carlos D Brody. Dorsal hippocampus contributes to model-based planning. Nature Neuroscience, 20 0 (9): 0 1269--1276, September 2017. ISSN 1097-6256, 1546-1726. doi:10.1038/nn.4613. URL http://www.nature.com/articles/nn.4613
-
[14]
I. Momennejad, E. M. Russek, J. H. Cheong, M. M. Botvinick, N. D. Daw, and S. J. Gershman. The successor representation in human reinforcement learning. Nature Human Behaviour, 1 0 (9): 0 680, September 2017. ISSN 2397-3374. doi:10.1038/s41562-017-0180-8. URL https://www.nature.com/articles/s41562-017-0180-8
-
[15]
Brad E. Pfeiffer and David J. Foster. Hippocampal place-cell sequences depict future paths to remembered goals. Nature, 497 0 (7447): 0 74--79, May 2013. ISSN 1476-4687. doi:10.1038/nature12112. URL https://www.nature.com/articles/nature12112
-
[16]
Russek, Ida Momennejad, Matthew M
Evan M. Russek, Ida Momennejad, Matthew M. Botvinick, Samuel J. Gershman, and Nathaniel D. Daw. Predictive representations can link model-based reinforcement learning to model-free mechanisms. PLOS Computational Biology, 13 0 (9): 0 e1005768, September 2017. ISSN 1553-7358. doi:10.1371/journal.pcbi.1005768. URL https://journals.plos.org/ploscompbiol/artic...
-
[17]
Doubly Distributional Population Codes : Simultaneous Representation of Uncertainty and Multiplicity
Maneesh Sahani and Peter Dayan. Doubly Distributional Population Codes : Simultaneous Representation of Uncertainty and Multiplicity . Neural Computation, 15 0 (10): 0 2255--2279, October 2003. ISSN 0899-7667. doi:10.1162/089976603322362356. URL http://dx.doi.org/10.1162/089976603322362356
-
[18]
Kimberly L. Stachenfeld, Matthew M. Botvinick, and Samuel J. Gershman. The hippocampus as a predictive map. Nature Neuroscience, 20 0 (11): 0 1643--1653, November 2017. ISSN 1546-1726. doi:10.1038/nn.4650. URL https://www.nature.com/articles/nn.4650
-
[19]
Babayan, Naoshige Uchida, and Samuel J
Clara Kwon Starkweather, Benedicte M. Babayan, Naoshige Uchida, and Samuel J. Gershman. Dopamine reward prediction errors reflect hidden-state inference across time. Nat. Neurosci., 20 0 (4): 0 581--589, April 2017. ISSN 1546-1726. doi:10.1038/nn.4520
-
[20]
Hippocampal Reactivation of Random Trajectories Resembling Brownian Diffusion
Federico Stella, Peter Baracskay, Joseph O Neill, and Jozsef Csicsvari. Hippocampal Reactivation of Random Trajectories Resembling Brownian Diffusion . Neuron, February 2019. ISSN 0896-6273. doi:10.1016/j.neuron.2019.01.052. URL http://www.sciencedirect.com/science/article/pii/S0896627319300790
-
[21]
Richard S. Sutton and Andrew G. Barto. Introduction to reinforcement learning, volume 135. MIT press Cambridge, 1998
work page 1998
-
[22]
Flexible and accurate inference and learning for deep generative models
Eszter V \'e rtes and Maneesh Sahani. Flexible and accurate inference and learning for deep generative models. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31 , pages 4166--4175. Curran Associates, Inc., 2018. URL http://papers.nips.cc/paper/7671-flexible-a...
work page 2018
-
[23]
Martin J. Wainwright and Michael I. Jordan. Graphical Models , Exponential Families , and Variational Inference . Found. Trends Mach. Learn., 1 0 (1-2): 0 1--305, January 2008. ISSN 1935-8237. doi:10.1561/2200000001. URL http://dx.doi.org/10.1561/2200000001
-
[24]
Zemel, Peter Dayan, and Alexandre Pouget
Richard S. Zemel, Peter Dayan, and Alexandre Pouget. Probabilistic interpretation of population codes. Neural computation, 10 0 (2): 0 403--430, 1998
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.