MammoExpert: Benchmarking Chain-of-Thought Reasoning in Mammography Diagnosis
Pith reviewed 2026-06-26 14:39 UTC · model grok-4.3
The pith
A mammography dataset with explicit radiologist reasoning steps across three diagnostic phases raises lesion classification accuracy by 7 to 11 percent on multiple test sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MammoExpert supplies the first public mammography resource that pairs images with radiologist-authored Chain-of-Thought traces through three explicit phases, and models that learn to generate those traces produce measurably higher classification accuracy and more reasonable outputs than models trained only on image-level labels.
What carries the argument
The MammoExpert dataset whose Chain-of-Thought annotations decompose each diagnosis into primal observation, factual assessment, and diagnostic synthesis phases performed by nine senior radiologists.
If this is right
- Combining CBIS-DDSM with MammoExpert raises classification accuracy by 7.1 percent.
- Additional training to reproduce the CoT annotations yields a further 4 percent gain on the MammoExpert test set.
- The same full pipeline produces 6.9 percent and 6.7 percent gains on the INBreast and Vindr datasets respectively.
- The resulting models are described as both more accurate and more reasonable in their outputs than standard classification baselines.
Where Pith is reading between the lines
- If the three-phase structure generalizes, similar annotation protocols could be applied to other imaging modalities where diagnostic decisions rest on sequential visual and factual judgments.
- Models that output the intermediate reasoning steps may allow radiologists to inspect and correct specific stages rather than accept or reject a single binary label.
- The 42 radiographic features per case could serve as an auxiliary supervision signal that further constrains the model even when full CoT traces are unavailable.
Load-bearing premise
The structured reasoning traces written by the nine radiologists faithfully represent the diagnostic logic actually used in routine clinical practice.
What would settle it
Train the same model architecture on MammoExpert images with only the final diagnosis label and no reasoning annotations; if accuracy does not drop relative to the full CoT version on the held-out test set, the claim that the reasoning structure itself drives the gain is falsified.
Figures

read the original abstract
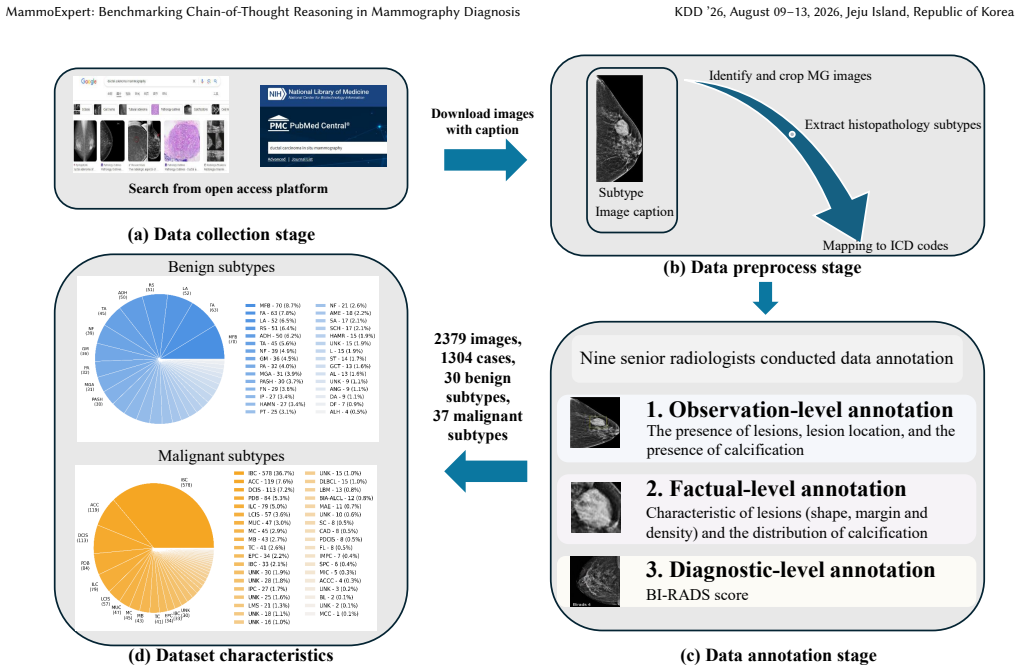
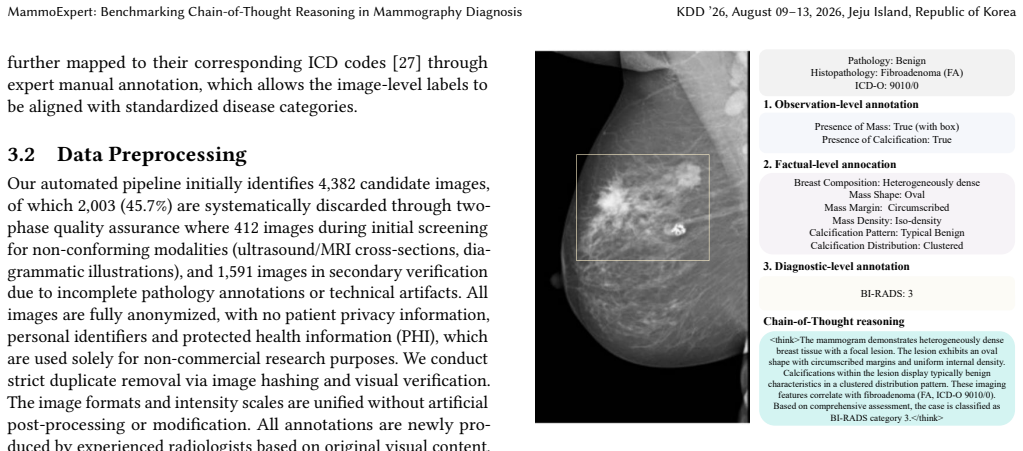
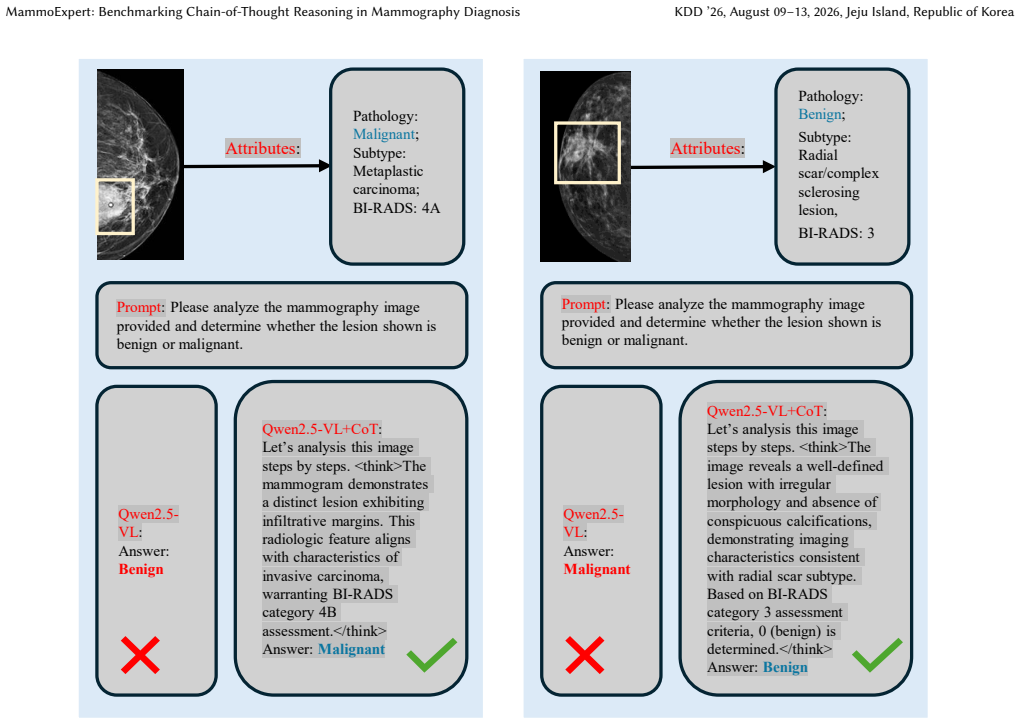
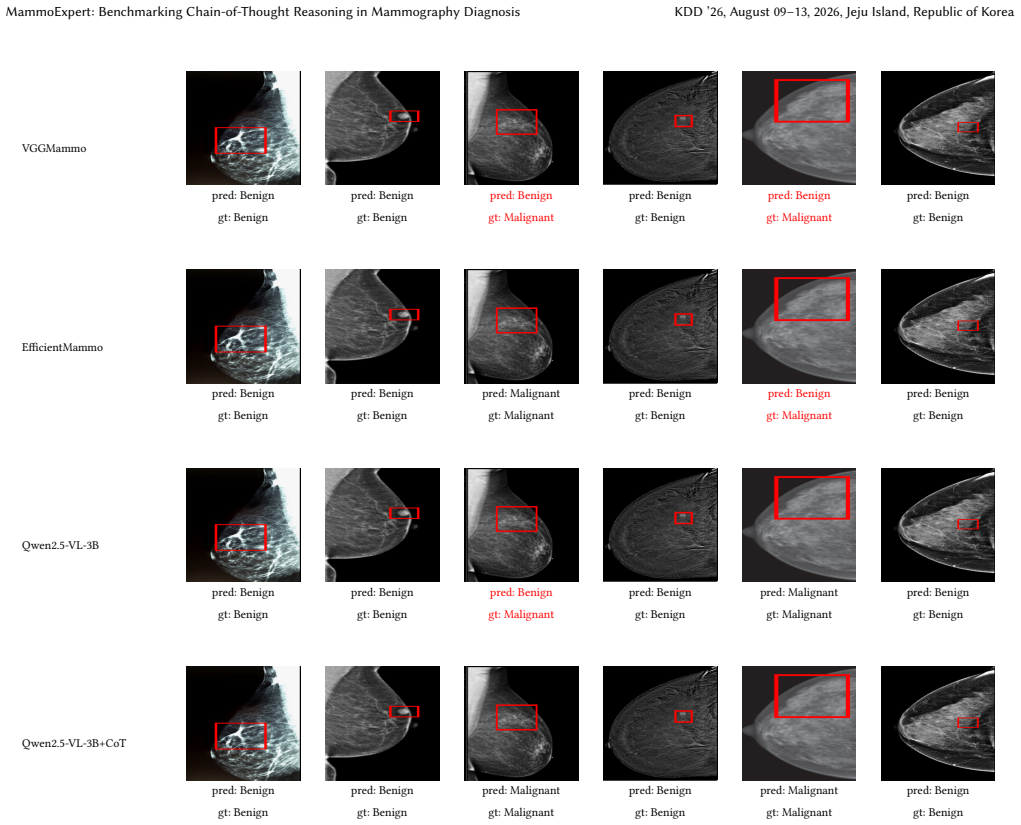
Mammography is an essential tool for breast cancer detection, with millions of examinations conducted annually. However, publicly available high-quality mammography datasets for AI development remain limited in both scale and annotation richness, particularly regarding pathological subtype coverage and structured diagnostic reasoning annotations. In this paper, we present MammoExpert, the first mammography dataset with Chain-of-Thought reasoning annotations across three diagnostic phases: (i) primal observation, (ii) factual assessment, and (iii) diagnostic synthesis. Comprising 2,379 mammography images covering 67 WHO-classified histopathology subtypes, each exam provides 42 radiographic features annotated by nine senior radiologists. We evaluate its performance on the breast lesion classification task, demonstrating superior accuracy and reasonability compared to existing classification models. Combining public dataset CBIS-DDSM with MammoExpert yields 7.1\% classification accuracy improvement, while the training model to learn CoT reasoning achieves another 4\% gain on the MammoExpert test set. Similar improvements are observed on INBreast and Vindr datasets, where the full approach yields accuracy gains of 6.9\% and 6.7\%, respectively. MammoExpert can serve as a benchmark for interpretable breast lesion diagnosis through explicit CoT reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MammoExpert, a new mammography dataset of 2,379 images spanning 67 WHO histopathology subtypes. Each image carries 42 radiographic features and Chain-of-Thought annotations in three phases (primal observation, factual assessment, diagnostic synthesis) produced by nine senior radiologists. The central empirical claims are that combining MammoExpert with CBIS-DDSM improves lesion classification accuracy by 7.1 %, that training on the CoT annotations yields an additional 4 % gain on the MammoExpert test set, and that the full approach produces 6.9 % and 6.7 % gains on INBreast and VinDr, respectively.
Significance. If the reported gains can be shown to arise specifically from the structured CoT annotations rather than from the additional 42 feature labels or increased data volume, the dataset would supply a useful public benchmark for interpretable medical-image models. The multi-radiologist annotation protocol and broad subtype coverage are positive features of the resource.
major comments (2)
- [Abstract] Abstract: the claim of a 4 % incremental gain from CoT training (and the overall 7.1 % / 6.9 % / 6.7 % improvements) is not supported by any ablation that holds data volume and radiologist input fixed while adding only the 42 radiographic features (or features plus non-CoT captions). Without this control, the incremental benefit cannot be attributed to the three-phase reasoning structure.
- [Abstract] Abstract: no information is supplied on the classification baselines, statistical testing, train/test splits, or controls for confounds, preventing assessment of whether the numeric improvements are robust.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional controls and details would strengthen the attribution of results and the transparency of the experimental setup. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 4 % incremental gain from CoT training (and the overall 7.1 % / 6.9 % / 6.7 % improvements) is not supported by any ablation that holds data volume and radiologist input fixed while adding only the 42 radiographic features (or features plus non-CoT captions). Without this control, the incremental benefit cannot be attributed to the three-phase reasoning structure.
Authors: We agree that the current results do not include an ablation that holds data volume and radiologist annotations fixed while adding only the 42 features versus features plus the three-phase CoT structure. The reported gains compare the full MammoExpert resource against external baselines, but lack this specific control. In the revised manuscript we will add the requested ablations (features-only vs. features+CoT on identical data volume) and update the abstract and results accordingly. revision: yes
-
Referee: [Abstract] Abstract: no information is supplied on the classification baselines, statistical testing, train/test splits, or controls for confounds, preventing assessment of whether the numeric improvements are robust.
Authors: We acknowledge that the abstract omits these experimental details. The full manuscript describes the baselines (ResNet, ViT, and several vision-language models), the 80/20 patient-level split on MammoExpert, and paired t-tests for significance, but does not explicitly list confound controls. We will revise the abstract to include a concise statement of these elements and expand the methods section with the requested information on splits, testing, and confound controls (e.g., stratification by acquisition site and equipment). revision: yes
Circularity Check
No circularity; empirical dataset benchmark with external validation
full rationale
The paper presents a new annotated mammography dataset (MammoExpert) with CoT reasoning labels and 42 radiographic features, then reports empirical accuracy gains when training models on it combined with public datasets (CBIS-DDSM, INBreast, VinDr). No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text. All reported improvements are measured on held-out test sets against baselines, with no reduction of any claim to a self-referential definition or self-citation chain. The central contribution is the dataset itself plus standard supervised learning results, which are externally falsifiable and do not rely on internal construction for their validity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotations by nine senior radiologists provide reliable ground truth for radiographic features and CoT reasoning across the three phases.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
Pith/arXiv arXiv 2025
-
[3]
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maxim- ilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. 2023. Learning to exploit temporal structure for biomedical vision-language processing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15016–15027
2023
-
[4]
Gaurav Bhole, S Suba, and Nita Parekh. 2025. Mammo-Bench: A Large-scale Benchmark Dataset of Mammography Images. InInternational Conference on Computational Advances in Bio and Medical Sciences. Springer, 144–156
2025
-
[5]
Chunyan Cui, Li Li, Hongmin Cai, Zhihao Fan, Ling Zhang, Tingting Dan, Jiao Li, and Jinghua Wang. 2021. The Chinese Mammography Database (CMMD): An online mammography database with biopsy confirmed types for machine diagnosis of breast.The Cancer Imaging Archive1 (2021)
2021
-
[6]
Alex J DeGrave, Zhuo Ran Cai, Joseph D Janizek, Roxana Daneshjou, and Su- In Lee. 2023. Dissection of medical AI reasoning processes via physician and generative-AI collaboration.Medrxiv(2023)
2023
-
[7]
Karin Dembrower, Peter Lindholm, and Fredrik Strand. 2020. A multi-million mammography image dataset and population-based screening cohort for the training and evaluation of deep neural networks—the cohort of screen-aged women (CSAW).Journal of digital imaging33, 2 (2020), 408–413
2020
-
[8]
Peter C Gøtzsche and Karsten Juhl Jørgensen. 2013. Screening for breast cancer with mammography.Cochrane database of systematic reviews6 (2013)
2013
-
[9]
Peter C Gøtzsche and Ole Olsen. 2000. Is screening for breast cancer with mammography justifiable?The Lancet355, 9198 (2000), 129–134
2000
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[11]
Gordon H Guyatt and Drummond Rennie. 1993. Users’ guides to the medical literature.Jama270, 17 (1993), 2096–2097
1993
-
[12]
Mark D Halling-Brown, Lucy M Warren, Dominic Ward, Emma Lewis, Alistair Mackenzie, Matthew G Wallis, Louise S Wilkinson, Rosalind M Given-Wilson, Rita McAvinchey, and Kenneth C Young. 2020. OPTIMAM mammography im- age database: a large-scale resource of mammography images and clinical data. Radiology: Artificial Intelligence3, 1 (2020), e200103
2020
-
[13]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[14]
Michael Heath, Kevin Bowyer, Daniel Kopans, P Kegelmeyer Jr, Richard Moore, Kyong Chang, and S Munishkumaran. 1998. Current status of the digital database for screening mammography. InDigital Mammography: Nijmegen, 1998. Springer, 457–460
1998
-
[15]
Andreas Holzinger, Chris Biemann, Constantinos S Pattichis, and Douglas B Kell
-
[16]
What do we need to build explainable AI systems for the medical domain? arXiv preprint arXiv:1712.09923(2017)
Pith/arXiv arXiv 2017
-
[17]
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. 2023. A visual–language foundation model for pathology image analysis using medical twitter.Nature medicine29, 9 (2023), 2307–2316
2023
-
[18]
Joanne Kim, Andrew Harper, Valerie McCormack, Hyuna Sung, Nehmat Hous- sami, Eileen Morgan, Miriam Mutebi, Gail Garvey, Isabelle Soerjomataram, and Miranda M Fidler-Benaoudia. 2025. Global patterns and trends in breast cancer incidence and mortality across 185 countries.Nature Medicine(2025), 1–9
2025
-
[19]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[20]
Rebecca Sawyer Lee, Francisco Gimenez, Assaf Hoogi, Kanae Kawai Miyake, Mia Gorovoy, and Daniel L Rubin. 2017. A curated mammography data set for use in computer-aided detection and diagnosis research.Scientific data4, 1 (2017), 1–9
2017
-
[21]
Constance D Lehman, Robert F Arao, Brian L Sprague, Janie M Lee, Diana SM Buist, Karla Kerlikowske, Louise M Henderson, Tracy Onega, Anna NA Tosteson, Garth H Rauscher, et al. 2017. National performance benchmarks for modern screening digital mammography: update from the Breast Cancer Surveillance Consortium.Radiology283, 1 (2017), 49–58
2017
-
[22]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2021
-
[23]
Elizabeth S McDonald, Amy S Clark, Julia Tchou, Paul Zhang, and Gary M Freedman. 2016. Clinical diagnosis and management of breast cancer.Journal of Nuclear Medicine57, Supplement 1 (2016), 9S–16S
2016
-
[24]
Jing Miao, Charat Thongprayoon, Supawadee Suppadungsuk, Pajaree Krisanapan, Yeshwanter Radhakrishnan, and Wisit Cheungpasitporn. 2024. Chain of thought utilization in large language models and application in nephrology.Medicina60, 1 (2024), 148
2024
-
[25]
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. 2023. Med- flamingo: a multimodal medical few-shot learner. InMachine learning for health (ML4H). PMLR, 353–367
2023
-
[26]
I. C. Moreira, I. Amaral, I. Domingues, A. Cardoso, M. J. Cardoso, and J. S. Cardoso
-
[27]
Inbreast: toward a full-field digital mammographic database.Academic radiology19, 2 (2012), 236–248
2012
-
[28]
Hieu T Nguyen, Ha Q Nguyen, Hieu H Pham, Khanh Lam, Linh T Le, Minh Dao, and Van Vu. 2023. VinDr-Mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography.Scientific Data10, 1 (2023), 277
2023
-
[29]
Kimberly J O’malley, Karon F Cook, Matt D Price, Kimberly Raiford Wildes, John F Hurdle, and Carol M Ashton. 2005. Measuring diagnoses: ICD code accuracy. Health services research40, 5p2 (2005), 1620–1639
2005
-
[30]
Daniel GP Petrini, Carlos Shimizu, Rosimeire A Roela, Gabriel Vansuita Valente, Maria Aparecida Azevedo Koike Folgueira, and Hae Yong Kim. 2022. Breast cancer diagnosis in two-view mammography using end-to-end trained efficientnet-based convolutional network.Ieee access10 (2022), 77723–77731
2022
-
[31]
Gonzalo Iñaki Quintana, Zhijin Li, Laurence Vancamberg, Mathilde Mougeot, Agnès Desolneux, and Serge Muller. 2023. Exploiting patch sizes and resolutions for multi-scale deep learning in mammogram image classification.Bioengineering 10, 5 (2023), 534
2023
-
[32]
Rebecca Sawyer-Lee, Francisco Gimenez, Assaf Hoogi, and Daniel Rubin. 2016. Curated breast imaging subset of digital database for screening mammography (CBIS-DDSM).(No Title)(2016)
2016
-
[33]
Li Shen, Laurie R Margolies, Joseph H Rothstein, Eugene Fluder, Russell McBride, and Weiva Sieh. 2019. Deep learning to improve breast cancer detection on screening mammography.Scientific reports9, 1 (2019), 12495
2019
-
[34]
Hans-Peter Sinn and Hans Kreipe. 2013. A brief overview of the WHO classi- fication of breast tumors, focusing on issues and updates from the 3rd edition. Breast care8, 2 (2013), 149–154
2013
-
[35]
David Allen Spak, JS Plaxco, L Santiago, MJ Dryden, and BE Dogan. 2017. BI- RADS®fifth edition: A summary of changes.Diagnostic and interventional imaging98, 3 (2017), 179–190
2017
-
[36]
John Suckling. 1994. The mammographic images analysis society digital mammo- gram database. InExerpta Medica. International Congress Series, 1994, Vol. 1069. 375–378
1994
-
[37]
Jinyuan Wang, Junlong Li, and Hai Zhao. 2023. Self-prompted chain-of-thought on large language models for open-domain multi-hop reasoning.arXiv preprint arXiv:2310.13552(2023)
arXiv 2023
-
[38]
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. 2022. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 3876–3887
2022
-
[39]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[40]
Tao Wei, Angelica I Aviles-Rivero, Shuo Wang, Yuan Huang, Fiona J Gilbert, Carola-Bibiane Schönlieb, and Chang Wen Chen. 2022. Beyond fine-tuning: Clas- sifying high resolution mammograms using function-preserving transformations. Medical image analysis82 (2022), 102618
2022
-
[41]
2019.WHO Classification of Tumours, 5th Edition, Volume 2: Breast Tumours
WHO Classification of Tumours Editorial Board. 2019.WHO Classification of Tumours, 5th Edition, Volume 2: Breast Tumours. International Agency for Research on Cancer (IARC), Lyon. https://publications.iarc.fr/Book-And-Report-Series/ Who-Classification-Of-Tumours/Breast-Tumours-2019
2019
-
[42]
Nan Wu, Jason Phang, Jungkyu Park, Yiqiu Shen, Zhe Huang, Masha Zorin, Stanisław Jastrzębski, Thibault Févry, Joe Katsnelson, Eric Kim, et al. 2019. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE transactions on medical imaging39, 4 (2019), 1184–1194
2019
-
[43]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems36 (2023), 11809–11822
2023
-
[44]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2024. Development of a large-scale medical visual question- answering dataset.Communications Medicine4, 1 (2024), 277
2024
-
[45]
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493 (2022)
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.