Deep Double Q-learning
Pith reviewed 2026-05-22 00:19 UTC · model grok-4.3
The pith
Deep Double Q-learning explicitly trains two Q-functions to decouple selection from evaluation and reduce overestimation in deep RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
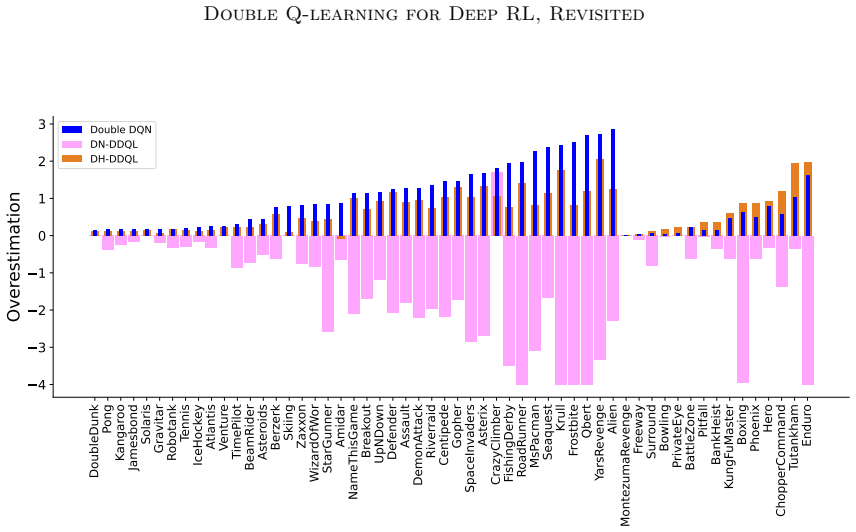
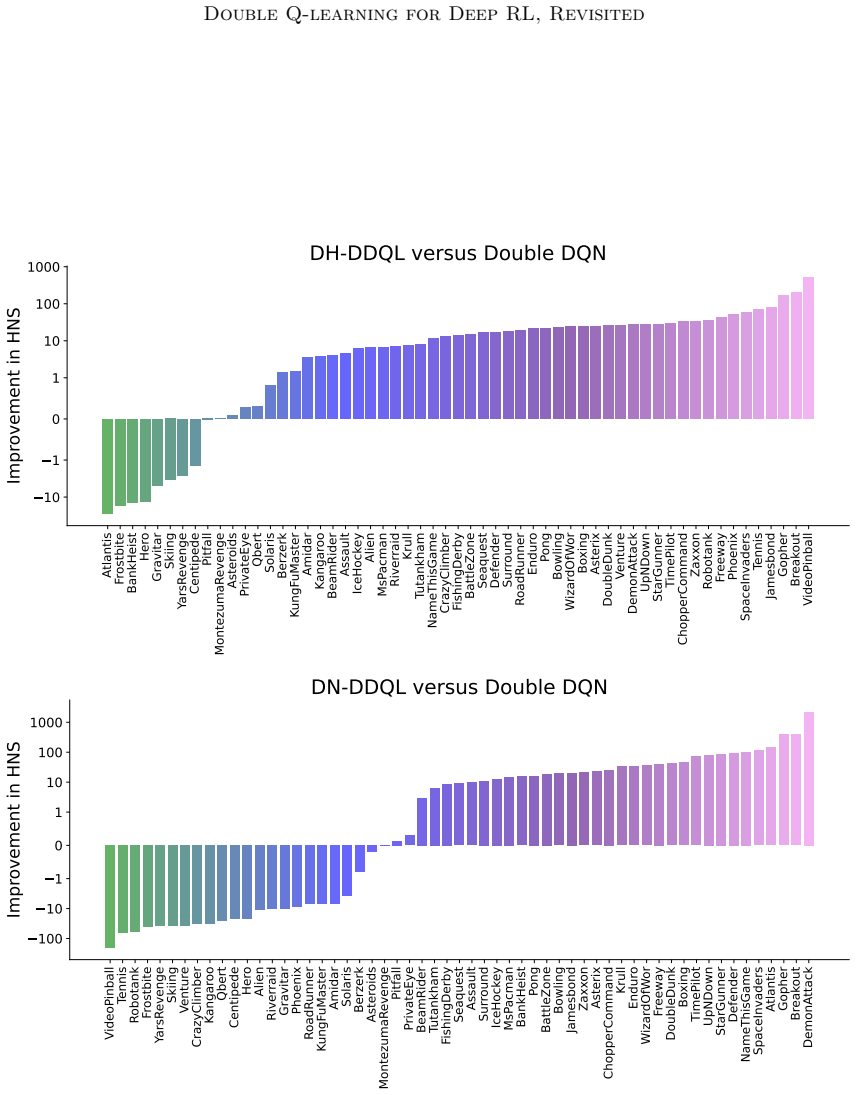
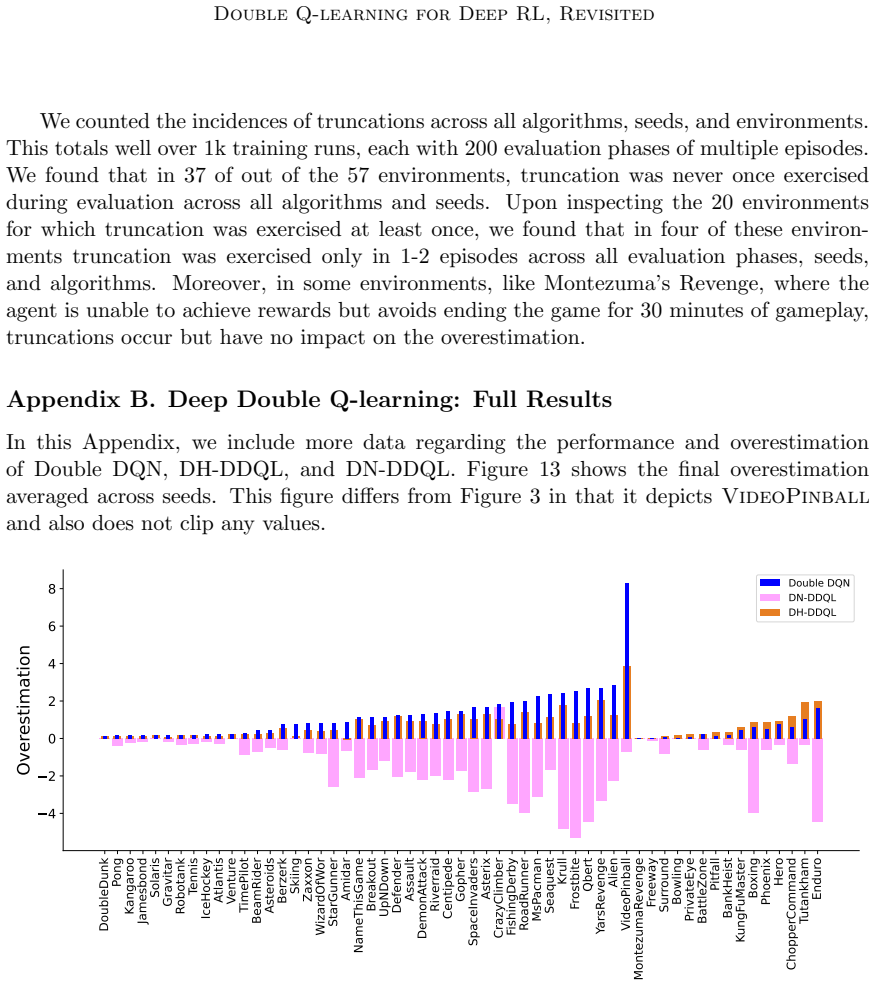
Deep Double Q-learning explicitly trains two Q-functions through Double Q-learning and decouples action-selection from action-evaluation in the bootstrap targets. Training is stabilized through lower replay ratios, longer target network update intervals, and shared layers, which together reduce overestimation and raise performance relative to Double DQN on Atari 2600 games.
What carries the argument
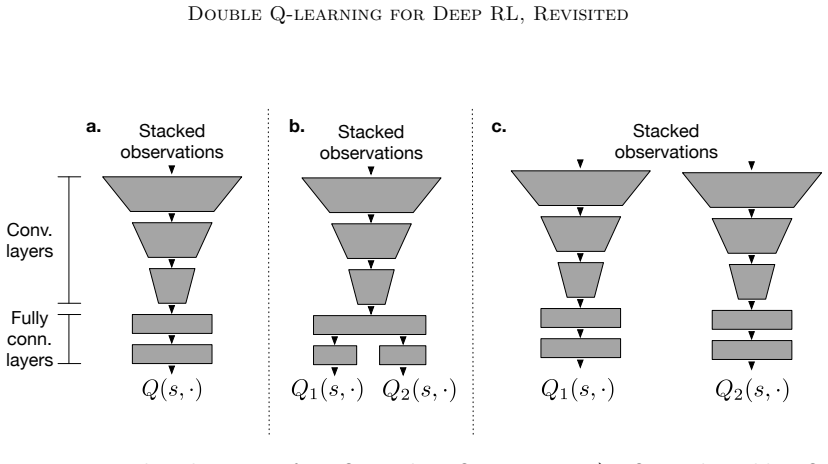
Two independent Q-functions that decouple action-selection from action-evaluation when computing bootstrap targets, stabilized by adjusted replay and target-update schedules plus shared layers.
If this is right
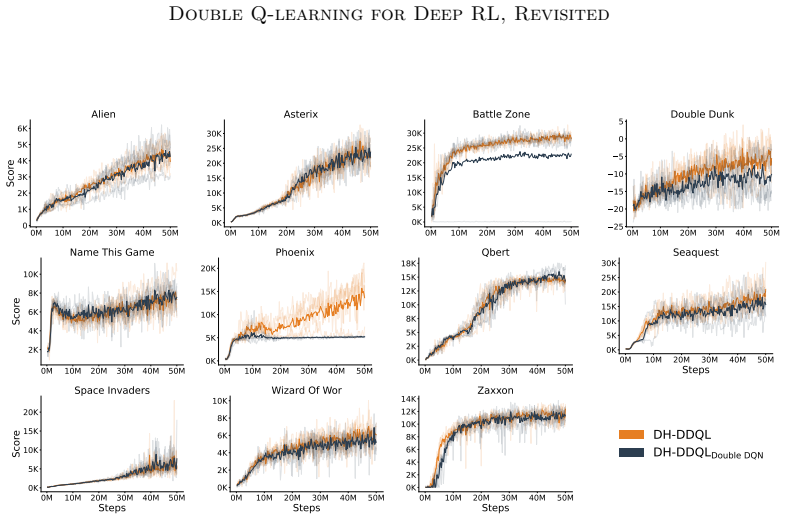
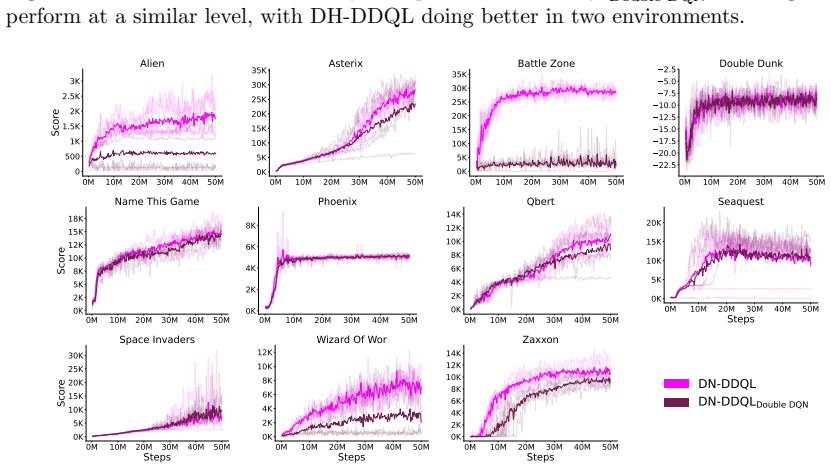
- DDQL outperforms Double DQN on 47 of the 57 Atari games while lowering overestimation further.
- Lower replay ratios and longer target-update intervals are required to keep the two estimators stable.
- Shared layers between the two Q-functions help avoid new instabilities during dual training.
- Minibatch sampling strategies and network architecture choices matter for successful adaptation of Double Q-learning to deep RL.
Where Pith is reading between the lines
- The same decoupling principle could be tested in continuous-control or robotic domains where overestimation also appears.
- Similar explicit separation of selection and evaluation might reduce bias in other deep RL methods such as actor-critic algorithms.
- Extending the stabilizations to deeper or wider networks would test whether the approach scales beyond the Atari setting.
Load-bearing premise
The specific combination of lower replay ratios, longer target network update intervals, and shared layers will stabilize training of two independent Q-functions without reintroducing estimator correlations or new instabilities.
What would settle it
Running DDQL on the same 57 Atari games and still observing high overestimation or no aggregate improvement over Double DQN would falsify the central claim.
Figures












read the original abstract
Double Q-learning is a classical control algorithm that mitigates the maximization bias of Q-learning. To do so, it explicitly trains two independent action-value functions and uses them to decouple action-selection and action-evaluation when computing bootstrap targets. Double DQN adapts target bootstrap decoupling to deep reinforcement learning (RL), but explicitly trains only a single action-value function and does not fully decouple its estimators. Consequently, the two estimators remain correlated, and overestimation persists. In this paper, we introduce Deep Double Q-learning (DDQL), a deep RL algorithm that explicitly trains two Q-functions through Double Q-learning. DDQL stabilizes training through a combination of techniques, including lower replay ratios, longer target network update intervals, and shared layers. Across 57 Atari 2600 games, DDQL improves aggregate performance over Double DQN, outperforming it on 47 games while further reducing overestimation. In addition, we study key design choices when adapting Double Q-learning to deep RL, including the network architecture, replay ratio, and minibatch sampling strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Deep Double Q-learning (DDQL), a deep RL adaptation of classical Double Q-learning that explicitly trains two action-value functions to decouple action selection from evaluation. DDQL employs stabilization techniques including lower replay ratios, longer target-network update intervals, and shared layers between the two Q-networks. On 57 Atari 2600 games, DDQL is reported to outperform Double DQN on 47 games with higher aggregate performance and further reduced overestimation; the paper also examines design choices such as network architecture, replay ratio, and minibatch sampling.
Significance. If the empirical gains prove robust, the work is significant for demonstrating that fuller realization of the Double Q-learning decoupling mechanism can yield measurable improvements over Double DQN in deep settings. The large-scale Atari evaluation and explicit study of stabilization hyperparameters provide practical guidance for mitigating maximization bias. The manuscript does not ship machine-checked proofs or parameter-free derivations, but the reproducible benchmarking protocol on a standard suite is a positive attribute.
major comments (2)
- [Network Architecture and Stabilization] Network Architecture and Stabilization section: the claim that shared layers plus lower replay ratio and longer target updates preserve sufficient estimator independence is load-bearing for the central decoupling argument, yet no direct measurement (e.g., correlation between the two Q-head outputs or gradient alignment statistics) or ablation removing the shared backbone is presented. Shared parameters allow gradients from both heads to update the same features, which risks reintroducing the very correlations Double Q-learning is intended to avoid.
- [Empirical Results] Empirical Results section (Atari evaluation): the reported 47/57 win rate and aggregate improvement lack error bars across random seeds, confidence intervals, or statistical significance tests. Without these, it is impossible to determine whether the observed gains are distinguishable from training stochasticity or hyperparameter sensitivity, weakening the claim that DDQL reliably outperforms Double DQN.
minor comments (2)
- [Abstract] The abstract states that DDQL 'further reduc[es] overestimation' but does not define the precise overestimation metric or show the corresponding plot or table reference.
- [Figures] Figure captions for learning curves should explicitly state the number of independent runs and whether shaded regions represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on Deep Double Q-learning. We address each major comment below and describe the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [Network Architecture and Stabilization] Network Architecture and Stabilization section: the claim that shared layers plus lower replay ratio and longer target updates preserve sufficient estimator independence is load-bearing for the central decoupling argument, yet no direct measurement (e.g., correlation between the two Q-head outputs or gradient alignment statistics) or ablation removing the shared backbone is presented. Shared parameters allow gradients from both heads to update the same features, which risks reintroducing the very correlations Double Q-learning is intended to avoid.
Authors: We agree that direct measurements of estimator independence and an ablation with fully separate backbones would strengthen the central argument. Our design uses shared layers for computational efficiency and feature reuse while relying on separate output heads together with reduced replay ratios and extended target-update intervals to limit correlation; the observed further reduction in overestimation provides indirect support. Nevertheless, the absence of explicit correlation statistics or a no-shared-backbone ablation is a limitation. We will add both an analysis of Q-head output correlations and gradient alignment as well as the requested ablation study in the revised manuscript. revision: yes
-
Referee: [Empirical Results] Empirical Results section (Atari evaluation): the reported 47/57 win rate and aggregate improvement lack error bars across random seeds, confidence intervals, or statistical significance tests. Without these, it is impossible to determine whether the observed gains are distinguishable from training stochasticity or hyperparameter sensitivity, weakening the claim that DDQL reliably outperforms Double DQN.
Authors: We concur that reporting variability across random seeds and formal statistical comparisons would make the empirical claims more robust. The 47/57 win rate and aggregate scores were obtained from single runs per game, consistent with standard large-scale Atari reporting, yet this practice does leave the results vulnerable to seed-specific effects. We will rerun the full evaluation suite with multiple independent seeds, include error bars and confidence intervals, and add statistical significance tests between DDQL and Double DQN in the revised version. revision: yes
Circularity Check
No circularity: purely empirical algorithm proposal and benchmarking
full rationale
The paper introduces DDQL by adapting the classical Double Q-learning algorithm (which decouples selection and evaluation via two independent Q-functions) to deep networks, then stabilizes training with replay ratio, target update frequency, and shared layers before reporting Atari 2600 results. No derivation, equation, or 'prediction' is shown to reduce to a fitted parameter or self-citation by construction. All performance claims rest on external benchmark comparisons (57 games) rather than internal self-reference. The skeptic concern about shared layers reintroducing correlations is an assumption-validity issue, not a circularity reduction. This is a standard empirical RL paper with independent external validation.
Axiom & Free-Parameter Ledger
free parameters (2)
- replay ratio
- target network update interval
axioms (1)
- domain assumption Explicitly training two independent action-value functions decouples selection and evaluation sufficiently to reduce overestimation in deep RL.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DDQL maintains two Q-network parameters θ1 and θ2... uses one Q-function to select... and the other to evaluate... LDDQL = L1 + L2
-
IndisputableMonolith/Foundation/ArithmeticFromLogicLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lower replay ratios, longer target network update intervals, and shared layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Agarwal, D. Schuurmans, and M. Norouzi. An Optimistic Perspective on Offline Reinforcement Learning . In International Conference on Machine Learning, 2020
work page 2020
-
[2]
R. Agarwal, M. Schwarzer, P. S. Castro, A. C. Courville, and M. G. Bellemare. Deep Reinforcement Learning at the Edge of the Statistical Precipice . Neural Information Processing Systems, 2021
work page 2021
-
[3]
M. Aitchison, P. Sweetser, and M. Hutter. Atari-5: Distilling the Arcade Learning Environment down to Five Games . In International Conference on Machine Learning, pages 421--438, 2023
work page 2023
-
[4]
O. Anschel, N. Baram, and N. Shimkin. Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning . In International Conference on Machine Learning, 2017
work page 2017
-
[5]
M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The Arcade Learning Environment: An Evaluation Platform for General Agents . Journal of Artificial Intelligence Research, 2013
work page 2013
-
[6]
M. G. Bellemare, W. Dabney, and R. Munos. A Distributional Perspective on Reinforcement Learning . In International Conference on Machine Learning, 2017
work page 2017
- [7]
-
[8]
X. Chen, C. Wang, Z. Zhou, and K. Ross. Randomized Ensembled Double Q-Learning: Learning Fast Without a Model . In International Conference on Learning Representations, 2021
work page 2021
-
[9]
J. Farebrother, J. Orbay, Q. Vuong, A. Ali Taiga, Y. Chebotar, T. Xiao, A. Irpan, S. Levine, P. S. Castro, A. Faust, A. Kumar, and R. Agarwal. Stop Regressing: Training Value Functions via Classification for Scalable Deep RL . In International Conference on Machine Learning, 2024
work page 2024
- [10]
-
[11]
S. Fujimoto, H. van Hoof, and D. Meger. Addressing Function Approximation Error in Actor-Critic Methods . In International Conference on Machine Learning, pages 1587--1596, 2018
work page 2018
- [12]
-
[13]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, et al. Soft Actor-Critic Algorithms and Applications . arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [14]
-
[15]
G. H. John. When the Best Move Isn’t Optimal: Q-learning with Exploration . In AAAI Conference on Artificial Intelligence, 1994
work page 1994
-
[16]
Q. Lan, Y. Pan, A. Fyshe, and M. White. Maxmin Q-learning: Controlling the Estimation Bias of Q-learning . In International Conference on Learning Representations, 2020
work page 2020
- [17]
-
[18]
L.-J. Lin. Reinforcement Learning and Teaching . In AAAI Conference on Artificial Intelligence, 1991
work page 1991
-
[19]
L.-J. Lin. Reinforcement Learning for Robots Using Neural Networks. Carnegie Mellon University, 1992
work page 1992
-
[20]
M. C. Machado, M. G. Bellemare, E. Talvitie, J. Veness, M. Hausknecht, and M. Bowling. Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents . Journal of Artificial Intelligence Research, 2018
work page 2018
-
[21]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. Human-level control through deep reinforcement learning . Nature, 2015
work page 2015
-
[22]
J. S. Obando-Ceron and P. S. Castro. Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research . In International Conference on Machine Learning, 2021
work page 2021
- [23]
-
[24]
G. Ostrovski, P. S. Castro, and W. Dabney. The Difficulty of Passive Learning in Deep Reinforcement Learning . Neural Information Processing Systems, 2021
work page 2021
-
[25]
A. Patterson, S. Neumann, M. White, and A. White. Empirical Design in Reinforcement Learning . Journal of Machine Learning Research, 2024
work page 2024
-
[26]
O. Peer, C. Tessler, N. Merlis, and R. Meir. Ensemble Bootstrapping for Q-Learning . In International Conference on Machine Learning, 2021
work page 2021
-
[27]
J. Quan and G. Ostrovski. DQN Zoo : Reference implementations of DQN -based agents, 2020. URL http://github.com/deepmind/dqn_zoo
work page 2020
- [28]
- [29]
-
[30]
J. E. Smith and R. L. Winkler. The Optimizer’s Curse: Skepticism and Postdecision Surprise in Decision Analysis . Management Science, 2006
work page 2006
-
[31]
R. S. Sutton. Learning to Predict by the Methods of Temporal Differences . Machine learning, 1988
work page 1988
-
[32]
R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction . MIT Press, 2018
work page 2018
-
[33]
S. Thrun and A. Schwartz. Issues in Using Function Approximation for Reinforcement Learning . In Connectionist Models Summer School, 1993
work page 1993
- [34]
-
[35]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul \ a o, A. Kallinteris, M. Krimmel, A. KG, et al. Gymnasium: A Standard Interface for Reinforcement Learning Environments . arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
H. van Hasselt. Double Q-learning . Neural Information Processing Systems, 2010
work page 2010
-
[37]
H. van Hasselt, A. Guez, and D. Silver. Deep Reinforcement Learning with Double Q-learning . In AAAI Conference on Artificial Intelligence, 2016
work page 2016
-
[38]
Deep Reinforcement Learning and the Deadly Triad
H. van Hasselt, Y. Doron, F. Strub, M. Hessel, N. Sonnerat, and J. Modayil. Deep Reinforcement Learning and the Deadly Triad . arXiv preprint arXiv:1812.02648, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
H. van Hasselt, M. Hessel, and J. Aslanides. When to use parametric models in reinforcement learning? In Neural Information Processing Systems, 2019
work page 2019
-
[40]
J. Wagenbach and M. Sabatelli. Factors of Influence of the Overestimation Bias of Q-Learning . arXiv preprint arXiv:2210.05262, 2022
-
[41]
M. Waltz and O. Okhrin. Addressing maximization bias in reinforcement learning with two-sample testing. Artificial Intelligence, 2024
work page 2024
-
[42]
X. Wang and A. Vinel. Cross Learning in Deep Q-Networks . arXiv preprint arXiv:2009.13780, 2020
-
[43]
Z. Wang, T. Schaul, M. Hessel, H. Hasselt, M. Lanctot, and N. Freitas. Dueling Network Architectures for Deep Reinforcement Learning . In International Conference on Machine Learning, 2016
work page 2016
-
[44]
C. J. Watkins. Learning from Delayed Rewards . PhD thesis , University of Cambridge, Cambridge, UK, 1989
work page 1989
-
[45]
C. J. Watkins and P. Dayan. Q-learning. Machine learning, 1992
work page 1992
- [46]
-
[47]
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.