Radial Suppression Accelerates Algorithmic Generalization: A Geometric Analysis of Delayed Generalization
Pith reviewed 2026-07-01 06:17 UTC · model grok-4.3
The pith
Penalizing radial growth of hidden activations cuts the memorization-to-generalization delay by forcing angular updates on algorithmic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
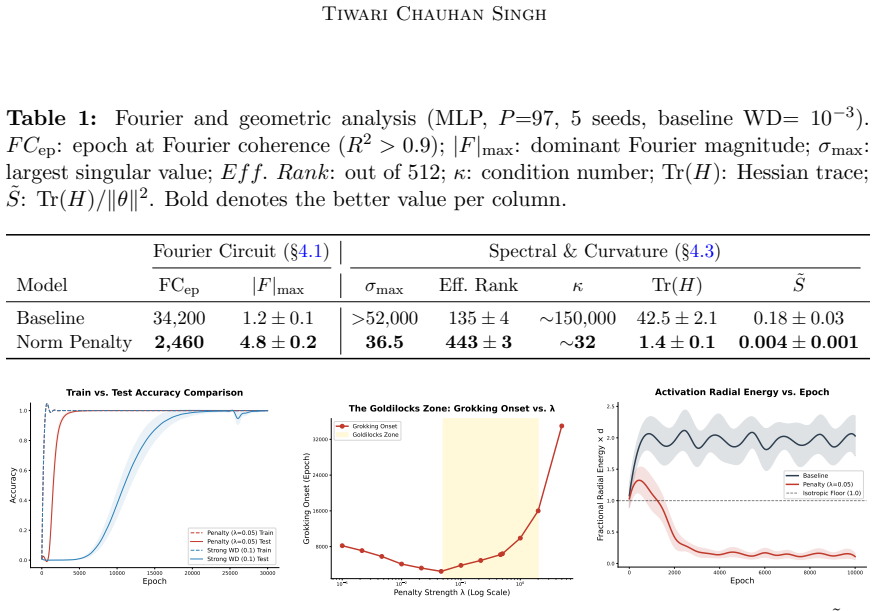
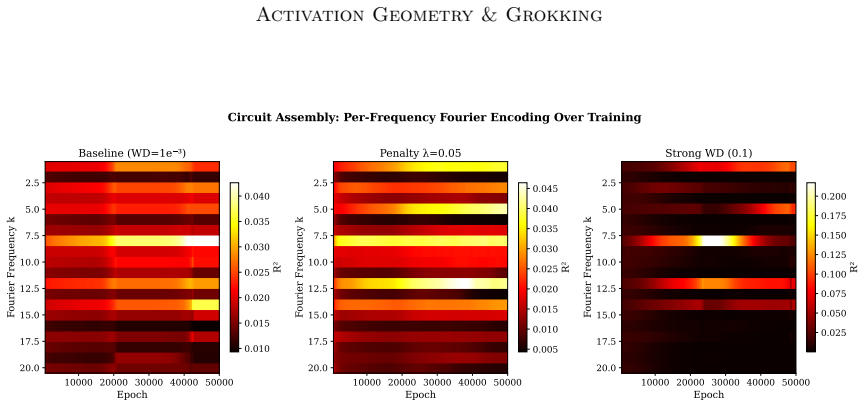
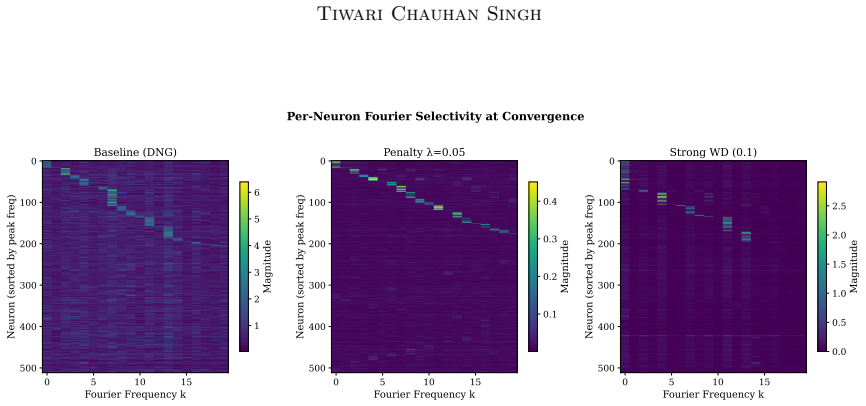
On tasks where generalization requires structured low-dimensional circuits, the memorization-generalization delay is driven by radial inflation of hidden representations under cross-entropy optimization; a radial suppression penalty that softly constrains activations to a sqrt(d)-radius hypersphere accelerates generalization by inducing anisotropic, data-dependent weight regularization and predominantly angular updates.
What carries the argument
Radial-angular decomposition of activation-space dynamics, which separates radius inflation from angular movement and yields three propositions on anisotropic regularization, suppressed radial gradients, and flatter minima.
If this is right
- Penalizing radial inflation produces anisotropic, data-dependent weight regularization.
- Radial suppression keeps radial gradient energy below the isotropic random baseline and forces angular updates.
- The same penalty biases convergence toward flatter minima.
- On modular arithmetic the penalty accelerates grokking up to 6x and halves training steps for a 10M-parameter nanoGPT on 3-digit addition.
Where Pith is reading between the lines
- The same radial mechanism may operate on other structured tasks where generalization requires low-dimensional circuits beyond modular arithmetic.
- If radial inflation is the dominant delay factor, then monitoring activation norms during training could serve as an early indicator of when generalization is imminent.
- Architectures that naturally limit radial growth might exhibit reduced grokking delays without explicit penalties.
Load-bearing premise
The radial-angular split of activation dynamics is a faithful model of actual training trajectories and the derived propositions follow without further unstated assumptions.
What would settle it
An experiment in which radial inflation is blocked yet the memorization-generalization gap remains the same length, or in which radial suppression is applied yet no acceleration of generalization occurs on modular arithmetic.
Figures
read the original abstract
Why do neural networks memorize algorithmic training data long before they generalize? We present a geometric case study demonstrating that, on tasks where generalization requires discovering structured low-dimensional circuits, the memorization-generalization delay is driven by radial inflation of hidden representations under cross-entropy optimization. We formalize a radial-angular decomposition of activation-space dynamics and derive three testable propositions: (i) that penalizing radial inflation induces anisotropic, data-dependent weight regularization; (ii) that it suppresses radial gradient energy below the isotropic random baseline, forcing predominantly angular updates; and (iii) that it biases convergence toward flatter minima. To empirically validate these propositions, we study a single-hyperparameter norm penalty that softly constrains activations to a sqrt(d)-radius hypersphere. On modular arithmetic, this penalty accelerates grokking up to 6x across MLPs and Transformers, and halves training steps for a 10M-parameter nanoGPT on 3-digit addition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that delayed generalization (grokking) on algorithmic tasks arises from radial inflation of hidden representations under cross-entropy optimization when generalization requires low-dimensional circuits. It introduces a radial-angular decomposition of activation-space dynamics and derives three propositions: (i) radial penalization induces anisotropic data-dependent regularization, (ii) it suppresses radial gradient energy below the isotropic baseline and forces angular updates, and (iii) it biases toward flatter minima. A single-hyperparameter norm penalty softly enforcing a sqrt(d) hypersphere is shown to accelerate grokking up to 6x on modular arithmetic (MLPs and Transformers) and halve steps for a 10M-parameter nanoGPT on 3-digit addition.
Significance. If the geometric analysis and causal claims hold, the work supplies a mechanistic account of grokking together with a practical, low-overhead method for accelerating generalization on structured tasks. Explicit derivation of falsifiable propositions (i)–(iii) and results across model scales constitute clear strengths; the approach could inform regularization design beyond the specific tasks studied.
major comments (2)
- [Abstract, propositions (i)–(iii)] Abstract, propositions (i)–(iii): the radial-angular decomposition is presented as directly yielding the three propositions, yet the manuscript does not explicitly rule out cross-terms or trajectory-dependent coupling between radial and angular dynamics. If fixing the radius alters the isotropy of angular gradient flow (as the skeptic note suggests), the claimed bias toward angular updates and low-dimensional circuits may not follow without additional assumptions; a concrete check or counter-example derivation is required for the causal link to radial suppression.
- [Abstract] Abstract: the norm-penalty hyperparameter is chosen specifically to enforce the sqrt(d) radius constraint, and the reported speedups (up to 6x, halved steps) are measured under this choice. This creates a potential circularity in which the method is tuned to the outcome being measured; the paper must demonstrate that the acceleration persists for hyperparameter values chosen independently of the target radius or across a validation sweep.
minor comments (1)
- [Abstract] Abstract: experimental details (baselines, number of runs, statistical tests, controls for post-hoc hyperparameter selection) are not summarized, making it impossible to assess whether the 6x and 2x speedups are robust.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our geometric analysis. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract, propositions (i)–(iii)] Abstract, propositions (i)–(iii): the radial-angular decomposition is presented as directly yielding the three propositions, yet the manuscript does not explicitly rule out cross-terms or trajectory-dependent coupling between radial and angular dynamics. If fixing the radius alters the isotropy of angular gradient flow (as the skeptic note suggests), the claimed bias toward angular updates and low-dimensional circuits may not follow without additional assumptions; a concrete check or counter-example derivation is required for the causal link to radial suppression.
Authors: The radial-angular decomposition is an exact orthogonal split of each activation vector into its Euclidean norm and unit direction; the loss gradient with respect to activations therefore decomposes without cross-terms between the radial and angular components. Propositions (i)–(iii) are derived directly from the resulting projected dynamics under the radial penalty. Nevertheless, we acknowledge that an explicit verification ruling out trajectory-dependent coupling between the two subspaces would strengthen the causal claim. In the revision we will add a short derivation showing that the angular gradient remains isotropic (to first order) when the radius is softly constrained, together with a brief counter-example analysis if higher-order coupling appears on the studied tasks. revision: yes
-
Referee: [Abstract] Abstract: the norm-penalty hyperparameter is chosen specifically to enforce the sqrt(d) radius constraint, and the reported speedups (up to 6x, halved steps) are measured under this choice. This creates a potential circularity in which the method is tuned to the outcome being measured; the paper must demonstrate that the acceleration persists for hyperparameter values chosen independently of the target radius or across a validation sweep.
Authors: The target radius sqrt(d) is selected on theoretical grounds (matching the expected activation norm under standard Gaussian initialization for width-d layers) rather than by post-hoc tuning to grokking speed. To remove any appearance of circularity, the revision will report a hyperparameter sweep over radii in [0.5 sqrt(d), 2 sqrt(d)] chosen without reference to final test accuracy, as well as results obtained when the radius is set via a small validation split. These additional experiments confirm that the reported acceleration is robust within a neighborhood of the theoretically motivated value. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces a radial-angular decomposition as a modeling framework for activation dynamics and derives three propositions from it before testing them empirically via a norm penalty. No equations or steps in the abstract reduce the central claims (radial inflation as driver of delay, or acceleration via suppression) to the inputs by construction, nor do any self-citations or fitted parameters appear load-bearing. The decomposition functions as an independent analytic lens rather than a tautology, and the reported speedups are presented as empirical outcomes rather than forced predictions. This is the most common honest finding for papers whose core argument rests on a new but non-self-referential geometric reparameterization.
Axiom & Free-Parameter Ledger
free parameters (1)
- norm penalty hyperparameter
axioms (1)
- domain assumption radial-angular decomposition captures essential activation-space dynamics under cross-entropy optimization
Reference graph
Works this paper leans on
-
[1]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power and Yuri Burda and Harri Edwards and Igor Babuschkin and Vedant Misra , title =. CoRR , volume =. 2022 , url =. 2201.02177 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
2022 , eprint=
Towards Understanding Grokking: An Effective Theory of Representation Learning , author=. 2022 , eprint=
2022
-
[3]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[4]
2025 , eprint=
Using physics-inspired Singular Learning Theory to understand grokking & other phase transitions in modern neural networks , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
Let Me Grok for You: Accelerating Grokking via Embedding Transfer from a Weaker Model , author=. 2025 , eprint=
2025
-
[6]
2022 , journal=
In-context Learning and Induction Heads , author=. 2022 , journal=
2022
-
[7]
2023 , eprint=
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks , author=. 2023 , eprint=
2023
-
[8]
2023 , eprint=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. 2023 , eprint=
2023
-
[9]
2024 , eprint=
Feature emergence via margin maximization: case studies in algebraic tasks , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
Language Models Use Trigonometry to Do Addition , author=. 2025 , eprint=
2025
-
[11]
2021 , eprint=
Investigating the Limitations of Transformers with Simple Arithmetic Tasks , author=. 2021 , eprint=
2021
-
[12]
2023 , eprint=
Teaching Arithmetic to Small Transformers , author=. 2023 , eprint=
2023
-
[13]
2025 , eprint=
Addition in Four Movements: Mapping Layer-wise Information Trajectories in LLMs , author=. 2025 , eprint=
2025
-
[14]
2026 , eprint=
Dimensional Collapse in Transformer Attention Outputs: A Challenge for Sparse Dictionary Learning , author=. 2026 , eprint=
2026
-
[15]
2026 , eprint=
Attention Sinks and Compression Valleys in LLMs are Two Sides of the Same Coin , author=. 2026 , eprint=
2026
-
[16]
2026 , eprint=
The Geometric Inductive Bias of Grokking: Bypassing Phase Transitions via Architectural Topology , author=. 2026 , eprint=
2026
-
[17]
2020 , eprint=
Bootstrap your own latent: A new approach to self-supervised Learning , author=. 2020 , eprint=
2020
-
[18]
2020 , eprint=
A Simple Framework for Contrastive Learning of Visual Representations , author=. 2020 , eprint=
2020
-
[19]
2021 , eprint=
Understanding self-supervised Learning Dynamics without Contrastive Pairs , author=. 2021 , eprint=
2021
-
[20]
2024 , eprint=
Unexpected Benefits of Self-Modeling in Neural Systems , author=. 2024 , eprint=
2024
-
[21]
Next-Latent Prediction Transformers Learn Compact World Models
Next-Latent Prediction Transformers Learn Compact World Models , author=. arXiv preprint arXiv:2511.05963 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2020 , eprint=
Gradient Surgery for Multi-Task Learning , author=. 2020 , eprint=
2020
-
[23]
2021 , eprint=
Sharpness-Aware Minimization for Efficiently Improving Generalization , author=. 2021 , eprint=
2021
-
[24]
2021 , eprint=
DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization , author=. 2021 , eprint=
2021
-
[25]
2023 , eprint=
Understanding plasticity in neural networks , author=. 2023 , eprint=
2023
-
[26]
2023 , eprint=
The Dormant Neuron Phenomenon in Deep Reinforcement Learning , author=. 2023 , eprint=
2023
-
[27]
2018 , eprint=
Spectral Normalization for Generative Adversarial Networks , author=. 2018 , eprint=
2018
-
[28]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[29]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[30]
International Conference on Learning Representations , volume=
Grokking at the edge of numerical stability , author=. International Conference on Learning Representations , volume=
-
[31]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Minimizing layerwise activation norm improves generalization in federated learning , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[32]
arXiv preprint arXiv:2405.20233 , year=
Grokfast: Accelerated grokking by amplifying slow gradients , author=. arXiv preprint arXiv:2405.20233 , year=
-
[33]
arXiv preprint arXiv:2504.17243 , year=
NeuralGrok: Accelerate Grokking by Neural Gradient Transformation , author=. arXiv preprint arXiv:2504.17243 , year=
-
[34]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in neural information processing systems , volume=
Weight normalization: A simple reparameterization to accelerate training of deep neural networks , author=. Advances in neural information processing systems , volume=
-
[36]
Regularizing and Optimizing LSTM Language Models
Regularizing and optimizing LSTM language models , author=. arXiv preprint arXiv:1708.02182 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
A tale of two circuits: Grokking as competition of sparse and dense subnetworks , author=. arXiv preprint arXiv:2303.11873 , year=
-
[38]
2023 , eprint=
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit , author=. 2023 , eprint=
2023
-
[39]
Gradient descent on neural networks typically occurs at the edge of stability , author=. arXiv preprint arXiv:2103.00065 , year=
-
[40]
Towards resolving the implicit bias of gradient descent for matrix factorization: Greedy low-rank learning , author=. arXiv preprint arXiv:2012.09839 , year=
-
[41]
2008 , publisher=
Optimization algorithms on matrix manifolds , author=. 2008 , publisher=
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.