MOOSE-Copilot: A Web-Based Interactive Assistant for Unified Exploratory and Fine-Grained Scientific Hypothesis Discovery
Pith reviewed 2026-06-29 07:44 UTC · model grok-4.3
The pith
Structured human signals through a formalized interaction protocol outperform autonomous baselines in unified scientific hypothesis discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
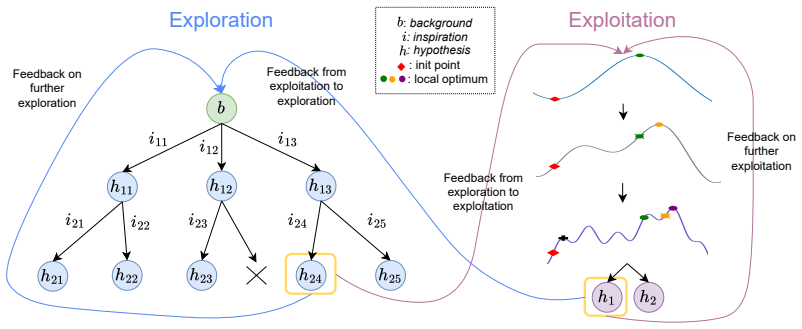
MOOSE-Copilot is presented as the first unified framework that bridges divergent exploratory search and convergent fine-grained refinement in scientific hypothesis discovery by means of a formalized human-AI interaction protocol, in which scientists inject initial blueprints, inter-stage routing decisions, and intra-stage feedback; oracle-simulated evaluation with idealized expert signals demonstrates that these structured inputs yield significant performance gains over purely autonomous baselines, and the framework is realized as a web-based no-code interface that renders the process as an interactive tree.
What carries the argument
The formalized human-AI interaction (HAII) protocol that routes three structured human signals (initial blueprints, inter-stage routing, and intra-stage feedback) through the generative pipeline.
If this is right
- Treating exploratory and refinement phases inside one steered process improves overall hypothesis output compared with isolated tasks.
- The three explicit signal types allow measurable characterization of gains under high-quality guidance.
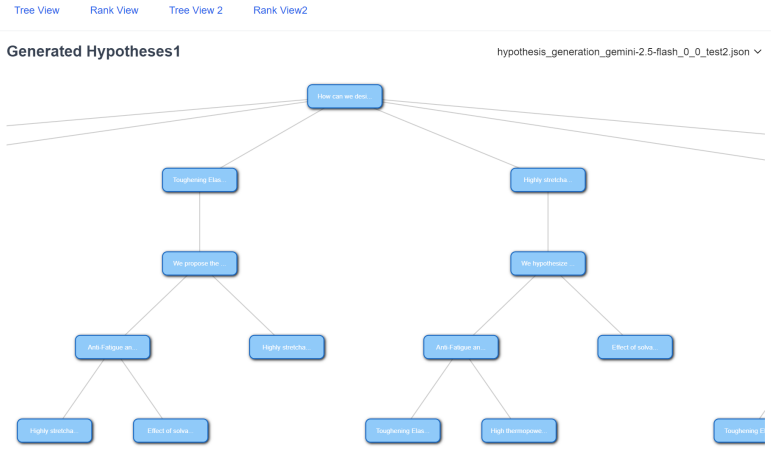
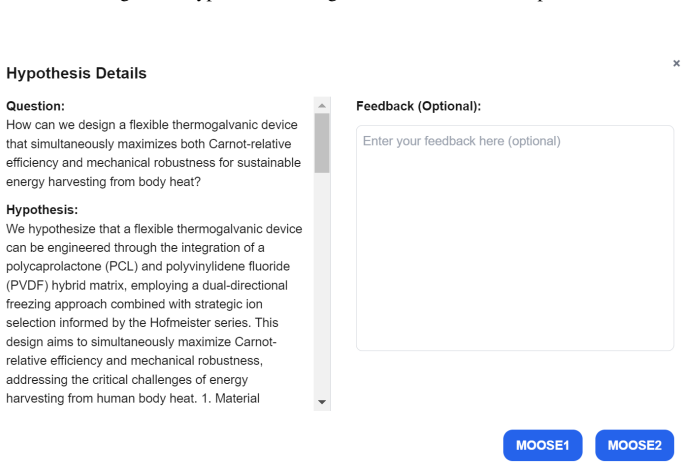
- A web interface that visualizes the search as a steerable tree removes the requirement for command-line agents.
- End-to-end hypothesis discovery becomes directly usable by researchers who lack programming expertise.
Where Pith is reading between the lines
- The tree visualization could surface patterns in how hypotheses evolve under different signal types.
- Similar staged human-signal protocols might transfer to other generative scientific tasks such as experiment planning.
- Widespread adoption could shorten the interval between posing a research question and obtaining testable hypotheses.
- Real-user studies would show how much domain expertise is required before the simulated gains appear.
Load-bearing premise
An oracle-simulated evaluation that uses idealized expert signals accurately represents the performance gains that would occur under real high-quality human guidance.
What would settle it
A side-by-side trial in which actual domain experts supply the three signals and independent raters compare the quality, novelty, and testability of the resulting hypotheses against matched autonomous runs.
Figures


read the original abstract
Large language models (LLMs) show remarkable potential in scientific hypothesis discovery. However, existing approaches face two critical limitations: they treat divergent exploratory search and convergent fine-grained refinement as isolated tasks, and they operate autonomously with little to no human guidance. We present MOOSE-Copilot, the first unified framework to bridge this abstraction gap through a formalized human-AI interaction (HAII) protocol. Our system empowers scientists to steer the generative process via three explicit signals: initial blueprints, inter-stage routing, and intra-stage feedback. Using an oracle-simulated evaluation in which an LLM provides idealized expert signals, we show that injecting these structured signals significantly outperforms purely autonomous baselines, characterizing the gains achievable under high-quality guidance. Furthermore, we build a web-based interface that turns the framework into a no-code workflow: researchers pose a question, watch the hypothesis search unfold as an interactive tree, and steer it by selecting hypotheses, routing between stages, and injecting feedback-no command-line agents required. This makes end-to-end hypothesis discovery directly accessible to interdisciplinary researchers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOOSE-Copilot as the first unified framework bridging exploratory and fine-grained scientific hypothesis discovery via a formalized human-AI interaction (HAII) protocol. Users steer LLM generation through three signals: initial blueprints, inter-stage routing, and intra-stage feedback. An oracle-simulated evaluation (LLM supplying idealized expert signals) is used to claim that these structured signals significantly outperform purely autonomous baselines. A web-based no-code interface is also presented, allowing researchers to pose questions, view hypothesis search as an interactive tree, and steer via selections, routing, and feedback.
Significance. If the oracle results generalize, the formalized HAII protocol and unified treatment of divergent/convergent phases could meaningfully advance interactive tools for scientific discovery. The no-code web interface addresses accessibility for non-programmers, a practical strength. However, the simulation-based evidence limits immediate impact; real-user validation would be needed to establish the protocol's value over existing autonomous or lightly-interactive baselines.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that 'injecting these structured signals significantly outperforms purely autonomous baselines' rests on an oracle-simulated evaluation, yet the manuscript provides no details on metrics (e.g., hypothesis quality, novelty, or diversity scores), number of runs, statistical tests, or exact oracle prompting. This absence makes the performance gains impossible to assess or reproduce.
- [Evaluation] Evaluation section: The assumption that LLM-oracle signals accurately characterize gains under 'high-quality guidance' is load-bearing but untested. Because the oracle is itself an LLM, shared inductive biases or hallucination patterns with the system could inflate measured benefits; no validation against real expert input is reported, directly undermining the claim that the HAII protocol delivers gains achievable with human scientists.
minor comments (2)
- [Abstract] Abstract: The phrasing 'no command-line agents required' is colloquial; rephrase for formal tone.
- [System description] Interface description: Adding a figure or screenshot of the interactive tree view would clarify the no-code workflow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important gaps in the evaluation's transparency and the limitations of the oracle simulation. We address each point below, proposing revisions where the manuscript can be strengthened without overclaiming results.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The central claim that 'injecting these structured signals significantly outperforms purely autonomous baselines' rests on an oracle-simulated evaluation, yet the manuscript provides no details on metrics (e.g., hypothesis quality, novelty, or diversity scores), number of runs, statistical tests, or exact oracle prompting. This absence makes the performance gains impossible to assess or reproduce.
Authors: We agree that the Evaluation section lacks the necessary implementation details for reproducibility. In the revised manuscript we will add: explicit definitions and computation methods for all metrics (hypothesis quality, novelty, diversity); the total number of runs per condition; any statistical tests applied; and the precise system prompt and temperature settings used for the oracle LLM. These additions will be placed in a new subsection under Evaluation and referenced from the abstract claim. revision: yes
-
Referee: [Evaluation] The assumption that LLM-oracle signals accurately characterize gains under 'high-quality guidance' is load-bearing but untested. Because the oracle is itself an LLM, shared inductive biases or hallucination patterns with the system could inflate measured benefits; no validation against real expert input is reported, directly undermining the claim that the HAII protocol delivers gains achievable with human scientists.
Authors: The oracle evaluation is explicitly framed as an idealized simulation to isolate the effect of structured HAII signals rather than to claim equivalence with human experts. We will revise the text to (a) emphasize that the reported gains represent an upper-bound characterization under high-quality guidance and (b) add an explicit Limitations paragraph discussing possible shared biases between the oracle and the generation model. A full human-expert validation study lies outside the scope of the present work. revision: partial
- Empirical validation of the HAII protocol against actual human scientists rather than an LLM oracle
Circularity Check
No circularity: empirical system evaluation with no derivation chain
full rationale
The paper presents an empirical system (MOOSE-Copilot) and reports performance gains from structured HAII signals versus autonomous baselines under oracle-simulated evaluation. No equations, parameter fitting, or mathematical derivation chain exists in the provided text. The central claim is a direct empirical comparison rather than a reduction of outputs to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The evaluation methodology (oracle LLM signals) is a stated assumption open to external critique but does not create definitional circularity within any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ideasynth: Iterative research idea develop- ment through evolving and composing idea facets with literature-grounded feedback.arXiv preprint arXiv:2410.04025. Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. 2024. Math...
-
[2]
LLM-SR: Scientific Equation Discovery via Pro- gramming with Large Language Models[J]
LLM-SR: scientific equation discovery via programming with large language models.CoRR, abs/2404.18400. Zonglin Yang and Lidong Bing. 2026. Moose-star: Un- locking tractable training for scientific discovery by breaking the complexity barrier. InProceedings of the 43rd International Conference on Machine Learn- ing. Zonglin Yang, Xinya Du, Junxian Li, Jie ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.