Does Verbose Chain-of-Thought Really Help? In-Distribution Evidence that Content, Not Length, Matters
Pith reviewed 2026-06-30 06:43 UTC · model grok-4.3
The pith
Longer chain-of-thought outputs improve accuracy only when added tokens carry reasoning or validation content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The benefit of verbose chain-of-thought arises from the reasoning and validation content carried by the extra tokens rather than their length, as in-distribution pairs show no accuracy change and controlled semantic-equivalent comparisons yield only modest gains that depend on the quality of the verbose prose.
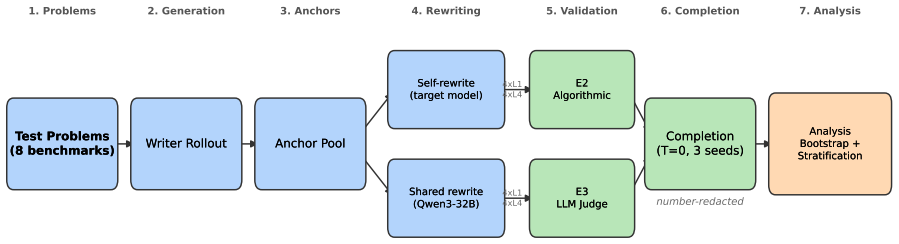
What carries the argument
Directed acyclic graph equivalence check for identifying traces with identical semantic content (same facts, operations, and intermediate values) despite differing verbosity.
If this is right
- Accuracy is unchanged when extra tokens add no new reasoning or validation content in natural generations.
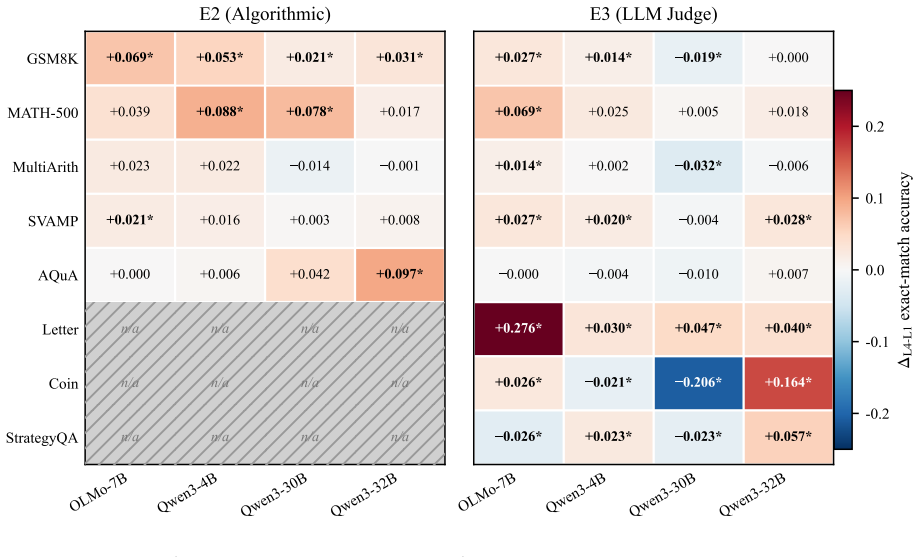
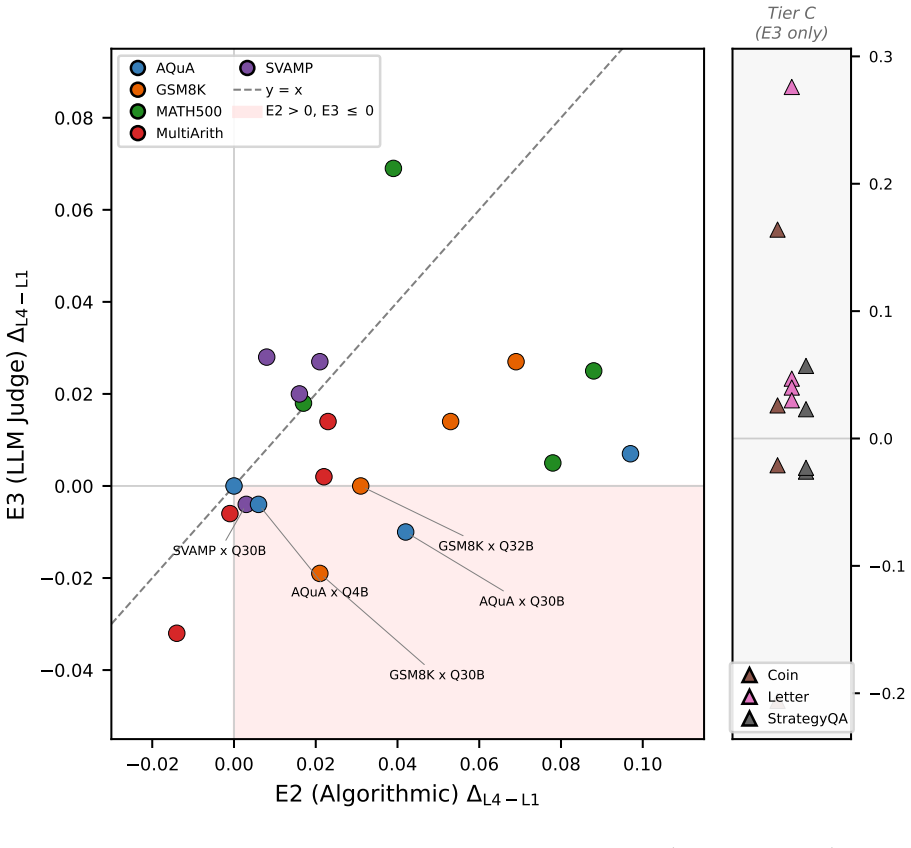
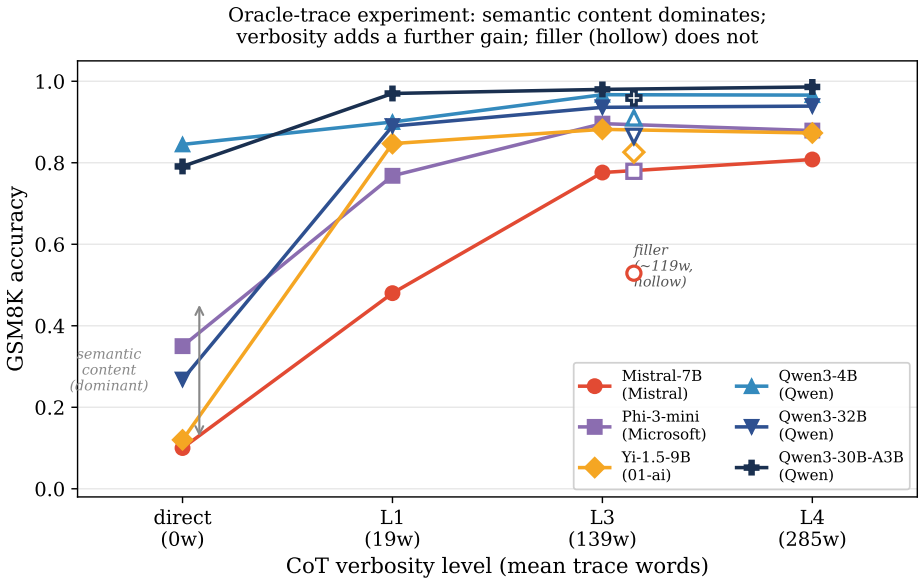
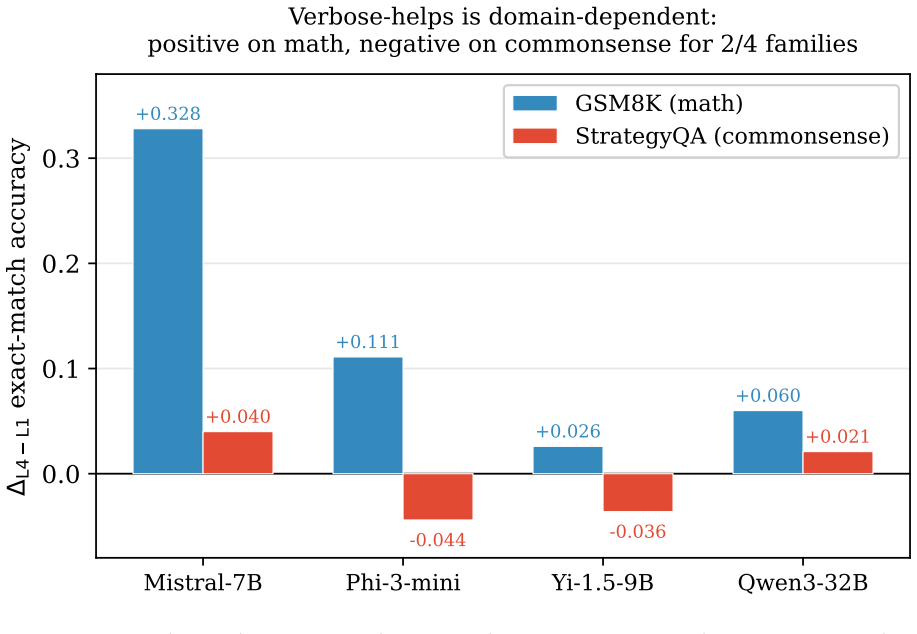
- Verbose traces with matched semantic content improve accuracy modestly, typically by 1-4 points, and only when the added prose has quality.
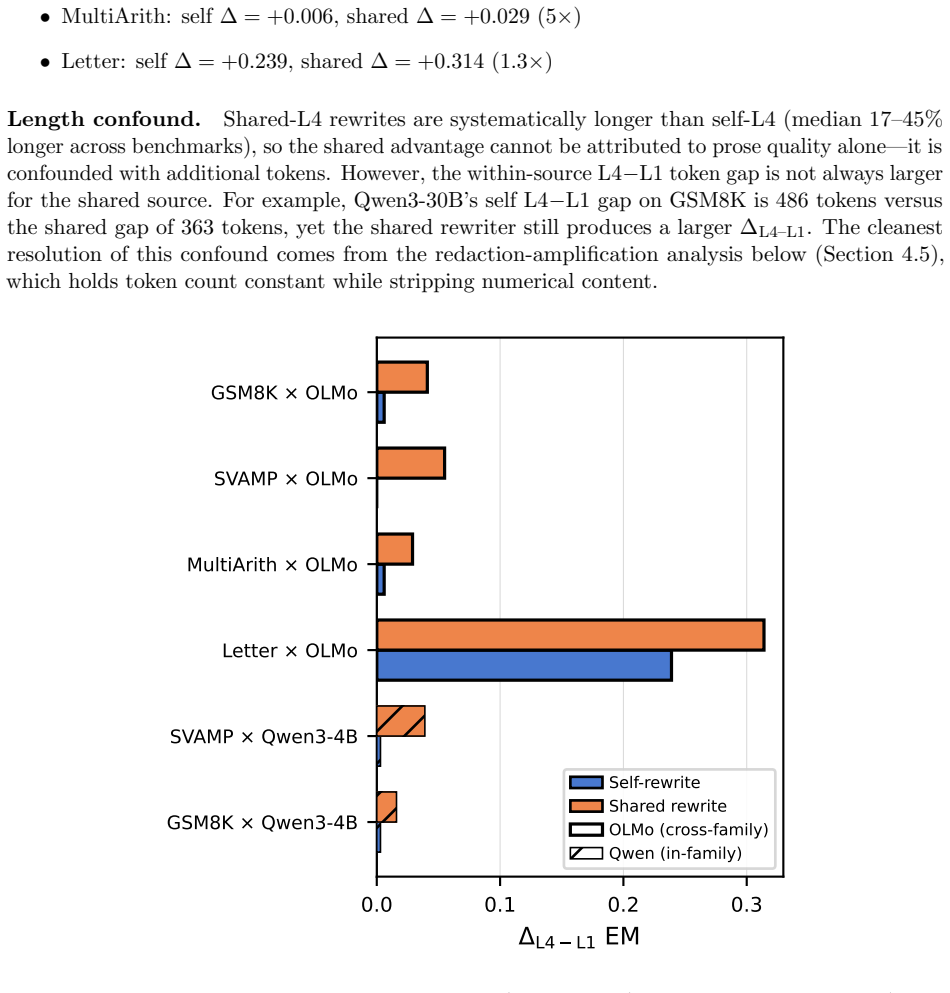
- The effect of verbosity is amplified under maximum numerical redaction, with a median factor of 3.24 across arithmetic benchmarks.
- Length-matched non-reasoning filler text provides no accuracy recovery.
- 25 of 32 benchmark-target combinations show positive effects under at least one validator.
Where Pith is reading between the lines
- Prompt engineering should target specific validation and checking behaviors rather than overall length.
- Internal model processes may treat verbose traces as opportunities for self-correction not triggered by length alone.
- These patterns may generalize to other reasoning domains if similar content controls are applied.
- Hybrid explanations combining token computation and semantic processing best fit the dual evidence lines.
Load-bearing premise
The directed acyclic graph equivalence check accurately identifies traces with identical semantic content even when one is verbose.
What would settle it
Finding that verbose traces without additional validation content reliably increase accuracy, or that the DAG check fails to match semantically identical traces, would falsify the conclusion.
Figures

read the original abstract
Chain-of-thought (CoT) prompting improves LLM reasoning, but the source is contested: do the intermediate steps help because they carry useful semantic content, or because conditioning on more tokens buys extra computation before the model commits to an answer? We bring two lines of evidence to bear. First, in distribution: we repeatedly sample each model on the same question and pair a shorter with a longer of its own natural generations that follow the same reasoning plan, so nothing is rewritten and both traces are genuinely in-distribution. Across 25 models the extra tokens leave accuracy essentially unchanged for every independently-trained reasoner, and a blind analysis of the surplus tokens shows that what gain exists elsewhere tracks validation- and checking-content, not verbosity per se. Second, as a controlled intervention, we ask whether two traces expressing the same semantic content (the same facts, operations, and intermediate values, verified through directed acyclic graph equivalence) produce different outcomes when one is more verbose, using a dual-validator design across four targets and eight benchmarks with number-redacted completion and stratified bootstrap confidence intervals. Verbose traces do improve accuracy (25 of 32 benchmark-target cells are positive under at least one validator), but the effects are modest (typically 1-4 points) and depend on the quality of the verbose prose, not merely its length. Under maximum numerical redaction the effect is amplified (median 3.24x across four arithmetic benchmarks), and length-matched non-reasoning filler recovers none of it. Both lines converge: what matters is what the extra tokens do (the reasoning and validation content they carry), not how many there are, a picture neither a pure forward-pass-compute nor a pure semantic-content account fully explains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that verbose chain-of-thought (CoT) improves LLM reasoning because of the semantic content carried by extra tokens (reasoning and validation steps), not their length or the extra forward-pass compute they enable. Evidence comes from two converging lines: (1) in-distribution sampling across 25 models where shorter and longer natural generations matched on reasoning plan show essentially unchanged accuracy, with any gains tracking validation content rather than verbosity; (2) controlled interventions on four targets and eight benchmarks that hold semantic content fixed via DAG equivalence (same facts, operations, intermediate values) and find modest accuracy gains (typically 1-4 points) from verbose traces that depend on prose quality, are amplified under numerical redaction (median 3.24x on arithmetic benchmarks), and are not recovered by length-matched non-reasoning fillers. Both lines use explicit controls including blind surplus-token analysis, stratified bootstrap CIs, and dual-validator design.
Significance. If the results hold, the work supplies large-scale, multi-control empirical evidence that distinguishes content-based from pure compute- or length-based accounts of CoT, with direct implications for mechanistic understanding of LLM reasoning. Strengths include the in-distribution natural-generation design, convergence of observational and interventional evidence, scale (25 models, 8 benchmarks), and explicit handling of confounders via number redaction, filler baselines, and bootstrap CIs. The manuscript reports reproducible experimental controls and falsifiable predictions about when verbosity helps.
minor comments (2)
- The dual-validator design and DAG equivalence procedure are central to the interventional line; a short appendix table listing inter-validator agreement rates and any cases of DAG mismatch would improve transparency without altering the main text.
- The abstract states results across '25 models' and 'eight benchmarks' but does not name the model families or benchmark list; adding these in the abstract or a footnote would aid quick assessment by readers.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive assessment, including the recommendation to accept. We have no major comments to address.
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical results from repeated sampling of natural generations, length-matched pairing under identical reasoning plans, and controlled interventions that hold semantic content fixed via DAG equivalence checks. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described methods or claims. All central evidence rests on direct experimental measurements with explicit controls (blind surplus-token analysis, length-matched fillers, number redaction, stratified bootstrap CIs), making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural model generations can be paired by shared reasoning plan without content rewriting while remaining in-distribution.
- domain assumption Directed acyclic graph equivalence verifies identical semantic content (facts, operations, values) across verbose and non-verbose traces.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2210.00720 , year=
Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. Complexity-based prompting for multi-step reasoning.arXiv preprint arXiv:2210.00720,
-
[2]
The Last Word Often Wins: A Format Confound in Chain-of-Thought Corruption Studies
Gabriel Garcia. The last word often wins: A format confound in chain-of-thought faithfulness evaluation.arXiv preprint arXiv:2605.10799,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, and Amrit Singh Bedi. Does thinking more al- ways help? understanding test-time scaling in reasoning models.arXiv preprint arXiv:2506.04210,
- [4]
-
[5]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The impact of reasoning step length on large language models
Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, and Mengnan Du. The impact of reasoning step length on large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 1830–1842,
2024
-
[7]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
What makes chain-of-thought prompting effective? a counterfactual study
Aman Madaan, Katherine Hermann, and Amir Yazdanbakhsh. What makes chain-of-thought prompting effective? a counterfactual study. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 1448–1535,
2023
-
[9]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand` es, and Tatsunori B Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
15 Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models.arXiv preprint arXiv:2404.15758,
-
[12]
A rewrite with a redacted final answer IS equivalent if the reasoning operations and dependency structure that PRODUCE that answer are preserved
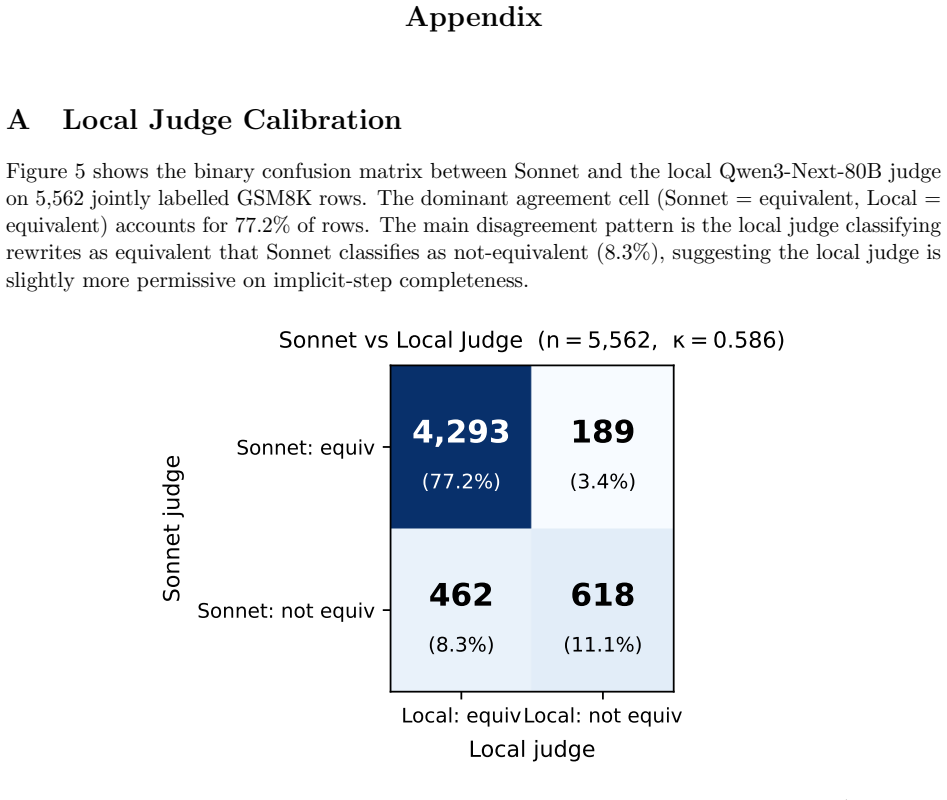
16 Appendix A Local Judge Calibration Figure 5 shows the binary confusion matrix between Sonnet and the local Qwen3-Next-80B judge on 5,562 jointly labelled GSM8K rows. The dominant agreement cell (Sonnet = equivalent, Local = equivalent) accounts for 77.2% of rows. The main disagreement pattern is the local judge classifying rewrites as equivalent that S...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.