A Scalable PyTorch Abstraction for Multi-GPU Gaussian Splatting
Pith reviewed 2026-06-27 13:11 UTC · model grok-4.3
The pith
A PyTorch backend distributes Gaussian parameters and splatting operators across GPUs via unified memory so models can handle over one billion splats without code changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
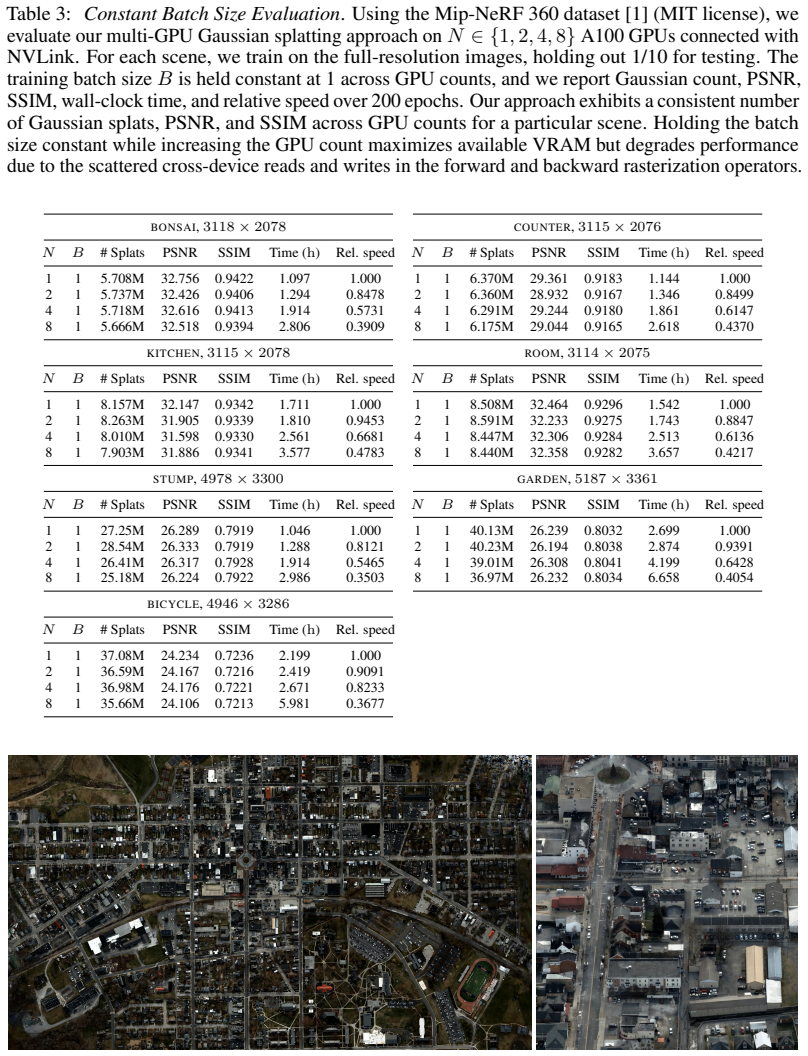
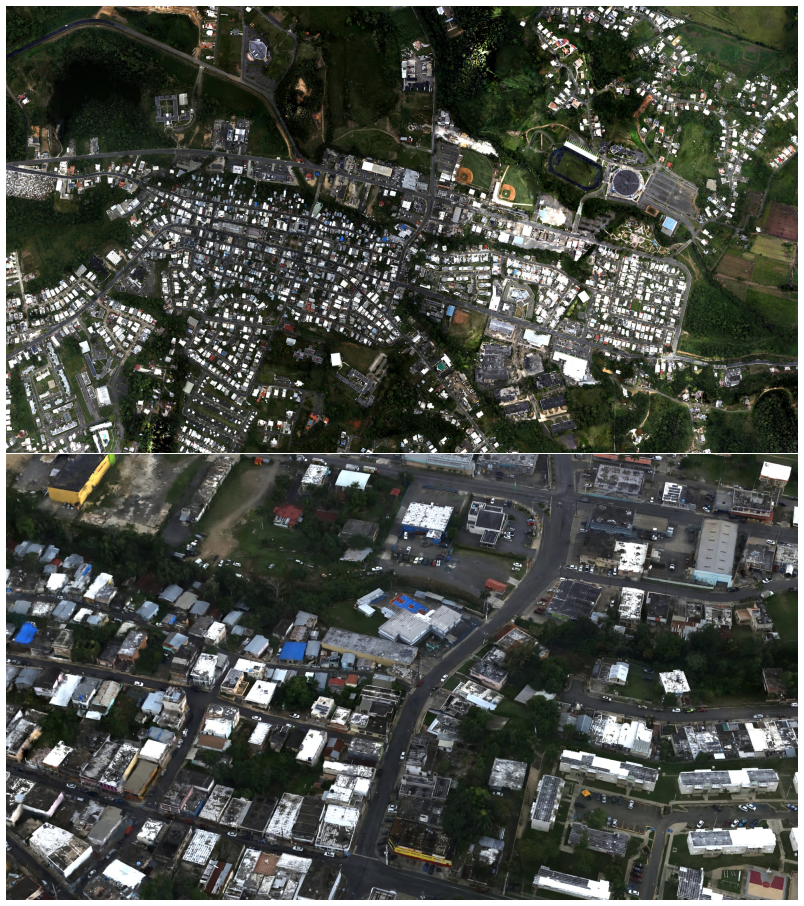
By proposing a PyTorch backend that distributes the Gaussian parameters and splatting operators across GPUs via CUDA unified memory and NVLink at the operator level, the model code requires no explicit cross-device communication. This approach enables city-scale reconstructions with street-level detail consisting of over 1 billion Gaussian splats, more than 25 times as many as the current state of the art.
What carries the argument
PyTorch backend that distributes Gaussian parameters and splatting operators across GPUs via CUDA unified memory and NVLink at the operator level, exposing multiple GPUs as one aggregate device.
Load-bearing premise
Distributing Gaussian parameters and splatting operators via CUDA unified memory and NVLink at the operator level will maintain correctness and deliver the claimed scale without hidden performance penalties or the need for model-level changes.
What would settle it
A run of a standard single-GPU Gaussian splatting model under this backend on a scene that exceeds single-GPU memory, producing either visibly incorrect output or failing to exceed roughly 40 million splats, would falsify the scaling claim.
Figures
read the original abstract
Gaussian splatting methods have become increasingly popular for neural reconstruction of the real world. However, they are often limited in scale and resolution due to compute and memory constraints. We present a multi-GPU Gaussian splatting approach that scales reconstruction to higher resolutions and larger scenes while abstracting away the code complexity typically associated with distributing a model. To accomplish this, we propose a PyTorch backend that distributes the Gaussian parameters and splatting operators across GPUs via CUDA unified memory and NVLink. Because distribution occurs at the operator level, the model code requires no explicit cross-device communication. More broadly, the backend exposes multiple GPUs as an aggregate PyTorch device and supports other PyTorch operators. We demonstrate city-scale reconstructions with street-level detail consisting of over 1 billion Gaussian splats, more than 25 times as many as the current state of the art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a PyTorch backend for multi-GPU Gaussian splatting that uses CUDA unified memory and NVLink to distribute Gaussian parameters and splatting operators across GPUs at the operator level. This abstraction allows scaling to city-scale scenes with over 1 billion Gaussian splats—claimed to be more than 25 times the current state of the art—without requiring explicit cross-device communication or changes to the model code. The backend also exposes multiple GPUs as an aggregate PyTorch device supporting other operators.
Significance. If the empirical claims hold, this work would provide a practical way to scale Gaussian splatting to much larger scenes, which is a significant limitation in current methods. The operator-level distribution via unified memory is an interesting engineering approach that could reduce the barrier to multi-GPU usage in PyTorch-based models. However, the significance depends on whether the approach maintains correctness and performance for the specific operations in Gaussian splatting.
major comments (2)
- Abstract: The claim that the approach enables 'city-scale reconstructions with street-level detail consisting of over 1 billion Gaussian splats, more than 25 times as many as the current state of the art' is not accompanied by any benchmarks, error analysis, comparison methodology, or implementation details, which are necessary to substantiate the central empirical claim.
- Description of the backend: The assertion that distributing splatting operators (including depth sorting and alpha compositing) via CUDA unified memory will maintain correctness without hidden performance penalties is not supported by analysis or experiments; the irregular access patterns in rasterization may lead to coherence traffic or fallback to host memory, undermining the scale claim.
minor comments (1)
- Abstract: The abstract mentions 'more broadly, the backend exposes multiple GPUs as an aggregate PyTorch device and supports other PyTorch operators' but provides no examples or validation of this generality.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to clarify our work. We address each major comment below and will make revisions to strengthen the substantiation of our claims.
read point-by-point responses
-
Referee: Abstract: The claim that the approach enables 'city-scale reconstructions with street-level detail consisting of over 1 billion Gaussian splats, more than 25 times as many as the current state of the art' is not accompanied by any benchmarks, error analysis, comparison methodology, or implementation details, which are necessary to substantiate the central empirical claim.
Authors: We agree that the abstract would be strengthened by explicit reference to supporting evidence. The full manuscript reports the scaling results, including direct comparisons to prior single-GPU and multi-GPU baselines that establish the >25x factor, along with error metrics on city-scale scenes. To address the comment, we will revise the abstract to include a brief clause noting that these results are obtained from the experiments in Section 4, which detail the benchmark scenes, Gaussian counts, and comparison methodology. revision: yes
-
Referee: Description of the backend: The assertion that distributing splatting operators (including depth sorting and alpha compositing) via CUDA unified memory will maintain correctness without hidden performance penalties is not supported by analysis or experiments; the irregular access patterns in rasterization may lead to coherence traffic or fallback to host memory, undermining the scale claim.
Authors: The manuscript relies on the semantics of CUDA unified memory and NVLink to preserve operator correctness without explicit communication in user code. We acknowledge that the current text does not include targeted profiling of coherence traffic or fallback behavior for the irregular accesses in depth sorting and alpha compositing. In revision we will add a dedicated analysis subsection with micro-benchmarks measuring page migration overhead and effective bandwidth on the target hardware, plus end-to-end timing breakdowns that quantify any hidden penalties relative to the reported scaling results. revision: yes
Circularity Check
No circularity: engineering abstraction with empirical validation only
full rationale
The paper describes an engineering implementation of a PyTorch backend for multi-GPU distribution of Gaussian splatting via CUDA unified memory and NVLink at the operator level. The scale claim (1B+ Gaussians) is presented as an empirical demonstration rather than a mathematical derivation or prediction derived from fitted parameters. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text; the contribution is self-contained as a software abstraction whose correctness is externally testable via benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5470–5479, June 2022
2022
-
[2]
cuDNN: Efficient primitives for deep learning, 2014
Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. cuDNN: Efficient primitives for deep learning, 2014
2014
-
[3]
Implementing cuda unified memory in the pytorch framework
Jake Choi, Heon Young Yeom, and Yoonhee Kim. Implementing cuda unified memory in the pytorch framework. In 2021 IEEE International Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C), pages 20–25, 2021
2021
-
[4]
pytorch_diffusion: A PyTorch reimplementation of denoising diffusion proba- bilistic models
Patrick Esser. pytorch_diffusion: A PyTorch reimplementation of denoising diffusion proba- bilistic models. https://github.com/pesser/pytorch_diffusion, 2020
2020
-
[5]
Oded Green, Robert McColl, and David A. Bader. GPU merge path: A GPU merging algorithm. In Proceedings of the 26th ACM International Conference on Supercomputing (ICS) , pages 331–340, 2012
2012
-
[6]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
2020
-
[7]
Le, Yonghui Wu, and Zhifeng Chen.GPipe: efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V . Le, Yonghui Wu, and Zhifeng Chen.GPipe: efficient training of giant neural networks using pipeline parallelism. Curran Associates Inc., Red Hook, NY , USA, 2019
2019
-
[8]
Huynh-Thu and M
Q. Huynh-Thu and M. Ghanbari. Scope of validity of PSNR in image/video quality assessment. Electronics Letters, 44(13):800–801, 2008
2008
-
[9]
Hyde, Michael Bao, and Ronald Fedkiw
David A.B. Hyde, Michael Bao, and Ronald Fedkiw. On obtaining sparse semantic solutions for inverse problems, control, and neural network training. Journal of Computational Physics, 443:110498, 2021
2021
-
[10]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkuehler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph., 42(4), July 2023
2023
-
[11]
A hierarchical 3d gaussian representation for real-time rendering of very large datasets
Bernhard Kerbl, Andreas Meuleman, Georgios Kopanas, Michael Wimmer, Alexandre Lanvin, and George Drettakis. A hierarchical 3d gaussian representation for real-time rendering of very large datasets. ACM Trans. Graph., 43(4), July 2024
2024
-
[12]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations (ICLR), 2015
2015
-
[13]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023
2023
-
[14]
NeRF-XL: Scaling nerfs with multiple GPUs
Ruilong Li, Sanja Fidler, Angjoo Kanazawa, and Francis Williams. NeRF-XL: Scaling nerfs with multiple GPUs. In European Conference on Computer Vision (ECCV), 2024
2024
-
[15]
PyTorch distributed: Experiences on accelerating data parallel training
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala. PyTorch distributed: Experiences on accelerating data parallel training. Proc. VLDB Endow., 13(12):3005–3018, 2020
2020
-
[16]
Litegs: A high- performance framework to train 3dgs in subminutes via system and algorithm codesign
Kaimin Liao, Hua Wang, Zhi Chen, Luchao Wang, and Yaohua Tang. Litegs: A high- performance framework to train 3dgs in subminutes via system and algorithm codesign. arXiv preprint arXiv:2503.01199, 2025. 10
arXiv 2025
-
[17]
Vastgaussian: Vast 3d gaussians for large scene reconstruction
Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, Youliang Yan, and Wenming Yang. Vastgaussian: Vast 3d gaussians for large scene reconstruction. In CVPR, 2024
2024
-
[18]
Citygaussian: Real-time high-quality large-scale scene rendering with gaussians
Yang Liu, Chuanchen Luo, Lue Fan, Naiyan Wang, Junran Peng, and Zhaoxiang Zhang. Citygaussian: Real-time high-quality large-scale scene rendering with gaussians. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors, Computer Vision – ECCV 2024, pages 265–282, Cham, 2025. Springer Nature Switzerland
2024
-
[19]
Scaffold- gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold- gs: Structured 3d gaussians for view-adaptive rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20654–20664, June 2024
2024
-
[20]
Taming 3dgs: High-quality radiance fields with limited resources
Saswat Subhajyoti Mallick, Rahul Goel, Bernhard Kerbl, Markus Steinberger, Francisco Vicente Carrasco, and Fernando De La Torre. Taming 3dgs: High-quality radiance fields with limited resources. In SIGGRAPH Asia 2024 Conference Papers, SA ’24, 2024
2024
-
[21]
Single-pass parallel prefix scan with decoupled look-back
Duane Merrill and Michael Garland. Single-pass parallel prefix scan with decoupled look-back. Technical Report NVR-2016-002, NVIDIA Corporation, 2016
2016
-
[22]
High performance and scalable radix sorting: A case study of implementing dynamic parallelism for GPU computing
Duane Merrill and Andrew Grimshaw. High performance and scalable radix sorting: A case study of implementing dynamic parallelism for GPU computing. Parallel Processing Letters, 21(2):245–272, 2011
2011
-
[23]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: representing scenes as neural radiance fields for view synthesis. Commun. ACM, 65(1):99–106, December 2021
2021
-
[24]
Guy M. Morton. A computer oriented geodetic data base and a new technique in file sequencing. Technical report, IBM Ltd., Ottawa, Canada, 1966
1966
-
[25]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Perfor...
-
[26]
Association for Computing Machinery
-
[27]
cuBLAS library
NVIDIA Corporation. cuBLAS library. https://docs.nvidia.com/cuda/cublas/, 2025
2025
-
[28]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-performa...
2019
-
[29]
PyTorch DTensor: Distributed tensor
PyTorch. PyTorch DTensor: Distributed tensor. https://docs.pytorch.org/docs/2.11/ distributed.tensor.html, 2025
2025
-
[30]
Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians
Kerui Ren, Lihan Jiang, Tao Lu, Mulin Yu, Linning Xu, Zhangkai Ni, and Bo Dai. Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–15, 2025
2025
-
[31]
Schönberger and Jan-Michael Frahm
Johannes L. Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[32]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600– 612, 2004. 11
2004
-
[33]
fvdb: A deep-learning framework for sparse, large scale, and high performance spatial intelligence
Francis Williams, Jiahui Huang, Jonathan Swartz, Gergely Klar, Vijay Thakkar, Matthew Cong, Xuanchi Ren, Ruilong Li, Clement Fuji-Tsang, Sanja Fidler, Eftychios Sifakis, and Ken Museth. fvdb: A deep-learning framework for sparse, large scale, and high performance spatial intelligence. ACM Trans. Graph., 43(4), July 2024
2024
-
[34]
Gspmd: General and scalable parallelization for ml computation graphs, 2021
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, Ruoming Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. Gspmd: General and scalable parallelization for ml computation graphs, 2021
2021
-
[35]
gsplat: An open-source library for gaussian splatting
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research, 26(34):1–17, 2025
2025
-
[36]
Dogs: Distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaussian consensus
Gim Hee Lee Yu Chen. Dogs: Distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaussian consensus. In arXiv, 2024
2024
-
[37]
On scaling up 3d gaussian splatting training
Hexu Zhao, Haoyang Weng, Daohan Lu, Ang Li, Jinyang Li, Aurojit Panda, and Saining Xie. On scaling up 3d gaussian splatting training. In Alessio Del Bue, Cristian Canton, Jordi Pont-Tuset, and Tatiana Tommasi, editors,Computer Vision – ECCV 2024 Workshops, pages 14–36, Cham, 2025. Springer Nature Switzerland
2024
-
[38]
Pytorch fsdp: Experiences on scaling fully sharded data parallel, 2023
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel, 2023. A Supplementary Material A.1 Memory Poo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.