Words Speak Louder Than Code: Investigating Cognitive Heuristics in LLM-Based Code Vulnerability Detection
Pith reviewed 2026-06-30 04:49 UTC · model grok-4.3
The pith
LLM-based code vulnerability detectors change their verdicts when the surrounding text triggers cognitive heuristics even though the code itself stays fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
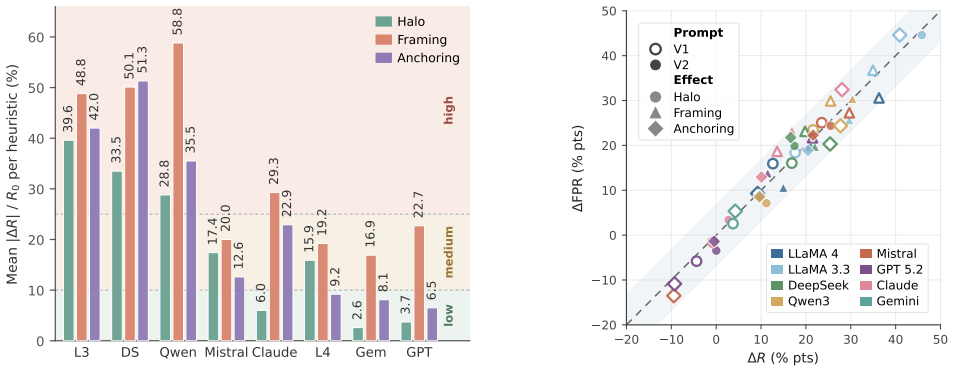
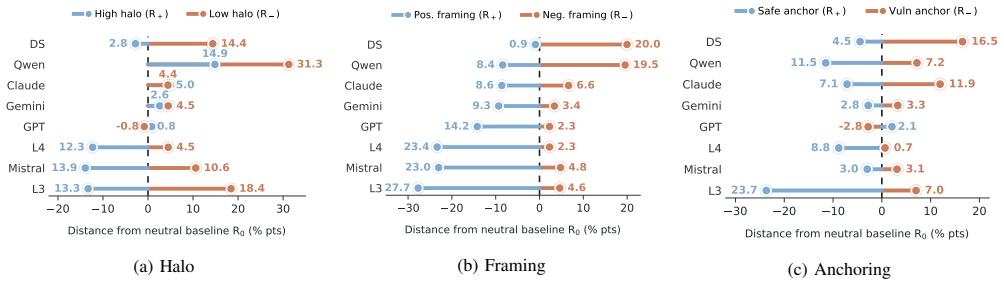
All eight evaluated LLMs are susceptible to the halo, framing, and anchoring heuristics when the code is held constant and only the surrounding context is varied. Average susceptibility across models reaches 33.2 percent for framing, 23.5 percent for anchoring, and 18.4 percent for halo. Code-level inspection shows that flaws requiring semantic reasoning are more easily shifted than pattern-matchable ones, and models frequently flip from safe to vulnerable without locating the actual flaw. A proof-of-concept black-box attack constructed from these context manipulations suppresses up to 97 percent of earlier detections.
What carries the argument
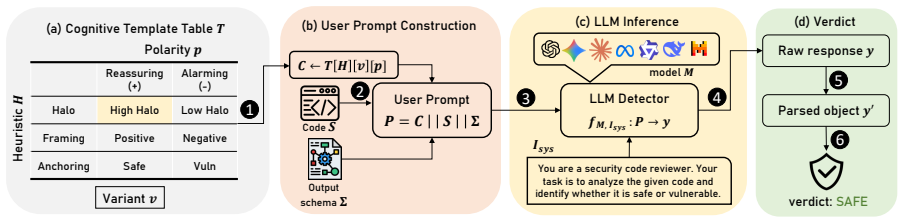
The controlled framework that holds the source code fixed while varying only the surrounding natural-language context to isolate each of the three heuristics.
If this is right
- Every tested model exhibits measurable shifts in verdict when context alone is changed.
- Vulnerabilities needing semantic reasoning are shifted more often than those found by pattern matching.
- Models can declare code vulnerable under one context and safe under another without correctly locating the flaw.
- A simple black-box attack using the same context changes can suppress up to 97 percent of prior detections.
- Cognitive susceptibility appears consistent across languages and model families.
Where Pith is reading between the lines
- Security pipelines that rely on LLM verdicts may need explicit context-normalization steps before trusting outputs.
- Attackers could embed heuristic triggers in commit messages or documentation to reduce detection rates.
- Future benchmarks for LLM code analysis should include controlled context-variation tests as a standard check.
- Training or prompting methods that reduce sensitivity to framing and anchoring could improve reliability.
Load-bearing premise
Altering only the surrounding text while keeping the code identical isolates the intended heuristic without introducing other uncontrolled factors that could explain verdict changes.
What would settle it
Run the same fixed-code snippets under the original and heuristic-triggering contexts and find no statistically significant difference in the models' vulnerability verdicts.
Figures


read the original abstract
Researchers and practitioners increasingly apply Large Language Models (LLMs) for automated vulnerability detection. Recent work has shown that LLMs are susceptible to the same cognitive heuristics that bias human judgment. Yet, no work has investigated whether these heuristics affect a model's assessment of code vulnerabilities. In this paper, we present the first systematic exploration of cognitive heuristics in LLM-driven code vulnerability detection. We introduce a controlled framework that holds the code fixed and only varies the surrounding context to trigger three cognitive heuristics: the halo effect through author attribution, the framing effect through task objectives and consequences, and the anchoring effect through prior analysis results. Within this framework, we evaluate eight LLMs across three programming languages and perform both quantitative and code-level analyses. Our findings demonstrate that all evaluated models are susceptible to these heuristics. Cross-model average susceptibility is highest for framing at 33.2%, followed by anchoring at 23.5% and halo at 18.4%. Code-level analysis reveals that vulnerabilities that require semantic reasoning for detection are more susceptible to cognitive heuristics than those identifiable through pattern matching. Furthermore, models often change their verdict from safe to vulnerable based on the cognitive condition, without accurately identifying the actual vulnerability. To highlight the practical impact, we demonstrate a proof-of-concept black-box cognitive attack that can suppress up to 97% of previously detected vulnerabilities. These findings indicate that cognitive susceptibility is a consistent and exploitable property of LLM-based vulnerability detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to conduct the first systematic study of cognitive heuristics (halo via author attribution, framing via task objectives/consequences, anchoring via prior results) in LLM-based code vulnerability detection. It introduces a framework holding code fixed while varying only surrounding context, evaluates eight LLMs across three languages with quantitative susceptibility rates (framing 33.2%, anchoring 23.5%, halo 18.4% cross-model averages) plus code-level analysis showing higher susceptibility for semantic vs. pattern-matching vulnerabilities, and demonstrates a black-box attack suppressing up to 97% of prior detections.
Significance. If the isolation of heuristic effects and quantitative results hold after addressing controls and transparency, the work is significant as the first empirical demonstration of these biases in a security-critical LLM application. The multi-model/multi-language scope, distinction between vulnerability types, and practical attack POC provide actionable evidence that could affect deployment of LLM vulnerability detectors. The empirical measurement approach (no self-referential parameters) is a strength.
major comments (2)
- [Framework / Methodology (controlled framework description)] The central claim that observed verdict changes are caused by the specific heuristics (e.g., 33.2% framing susceptibility) depends on the framework isolating those effects. The description of holding code fixed while varying only surrounding context provides no evidence of baseline conditions that match length, token count, or syntactic structure of the added text while removing heuristic triggers. Without these, shifts could arise from general prompt sensitivity, attention dilution, or task re-framing (see skeptic concern on context changes).
- [Results / Quantitative analysis] The reported susceptibility rates and 97% attack suppression figure are load-bearing for the quantitative findings, yet the abstract (and by extension the results) provides no details on statistical methods, error bars, exact number of code samples per condition, or prompt templates. This prevents verification of the cross-model averages and undermines confidence in the susceptibility claims.
minor comments (2)
- [Abstract] The abstract states evaluation across 'three programming languages' but does not name them; this should be explicit in the methodology for reproducibility.
- [Code-level analysis subsection] Code-level analysis claims vulnerabilities requiring semantic reasoning are more susceptible, but the criteria for classifying 'semantic' vs. 'pattern-matching' vulnerabilities are not defined with examples or inter-rater details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas for improving methodological transparency and rigor. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: The central claim that observed verdict changes are caused by the specific heuristics (e.g., 33.2% framing susceptibility) depends on the framework isolating those effects. The description of holding code fixed while varying only surrounding context provides no evidence of baseline conditions that match length, token count, or syntactic structure of the added text while removing heuristic triggers. Without these, shifts could arise from general prompt sensitivity, attention dilution, or task re-framing (see skeptic concern on context changes).
Authors: We agree that the isolation of heuristic effects would be strengthened by explicit baseline conditions using neutral text matched on length, token count, and syntactic structure. The current manuscript describes the controlled framework but does not report such matched baselines. In the revision we will add these control conditions, re-run the relevant experiments, and report the results to demonstrate that verdict shifts are attributable to the heuristic triggers rather than general prompt sensitivity. revision: yes
-
Referee: The reported susceptibility rates and 97% attack suppression figure are load-bearing for the quantitative findings, yet the abstract (and by extension the results) provides no details on statistical methods, error bars, exact number of code samples per condition, or prompt templates. This prevents verification of the cross-model averages and undermines confidence in the susceptibility claims.
Authors: We acknowledge that the manuscript lacks sufficient detail on the quantitative analysis. The revision will include the exact number of code samples per condition and language, the statistical methods used (including significance tests), error bars or confidence intervals on all susceptibility rates and the attack suppression figure, and the full prompt templates. These additions will enable independent verification of the reported cross-model averages. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or self-referential reductions
full rationale
The paper conducts controlled experiments that measure verdict changes in LLMs when context is varied while code is held fixed. Susceptibility percentages (e.g., 33.2% framing) are reported as direct observations from model outputs across conditions, with no equations, fitted parameters, or derivations that reduce these values to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked to justify the central claims. The work is self-contained as an empirical study and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Partnering with Mozilla to improve Firefox’s security,
Anthropic, “Partnering with Mozilla to improve Firefox’s security,” March 2026. [Online]. Available: https://www.anthropic.com/news/ mozilla-firefox-security
2026
-
[2]
Found means fixed: Secure code more than three times faster with Copilot Autofix,
GitHub, “Found means fixed: Secure code more than three times faster with Copilot Autofix,” August 2024. [Online]. Available: https://github.blog/news-insights/product-news/ secure-code-more-than-three-times-faster-with-copilot-autofix/
2024
-
[3]
Introducing ZeroPath: The security platform that actually understands your code,
ZeroPath, “Introducing ZeroPath: The security platform that actually understands your code,” August 2025. [Online]. Available: https://zeropath.com/blog/introducing-zeropath-v1
2025
-
[4]
A constant error in psychological ratings
E. L. Thorndike, “A constant error in psychological ratings.”Journal of Applied Psychology, 1920
1920
-
[5]
The framing of decisions and the psychology of choice,
A. Tversky and D. Kahneman, “The framing of decisions and the psychology of choice,”Science, 1981
1981
-
[6]
Judgment under uncertainty: Heuristics and biases,
——, “Judgment under uncertainty: Heuristics and biases,”Science, 1974
1974
-
[7]
(Ir)rationality and Cognitive Biases in Large Language Models
O. Macmillan-Scott and M. Musolesi, “(ir)rationality and cognitive biases in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.09193
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
The bias is in the details: An assessment of cognitive bias in llms,
R. A. Knipper, C. S. Knipper, K. Zhang, V . Sims, C. Bowers, and S. Karmaker, “The bias is in the details: An assessment of cognitive bias in llms,” 2025. [Online]. Available: https: //arxiv.org/abs/2509.22856
-
[9]
A compre- hensive evaluation of cognitive biases in LLMs,
S. Malberg, R. Poletukhin, C. M. Schuster, and G. Groh, “A compre- hensive evaluation of cognitive biases in LLMs,” inProceedings of Natural Language Processing for Digital Humanities, 2025
2025
-
[10]
Cognitive bias in decision-making with LLMs,
J. M. Echterhoff, Y . Liu, A. Alessa, J. McAuley, and Z. He, “Cognitive bias in decision-making with LLMs,” inFindings of EMNLP, 2024
2024
-
[11]
Vulnerability detection with code language models: How far are we?
Y . Ding, Y . Fu, O. Ibrahim, C. Sitawarin, X. Chen, B. Alomair, D. Wagner, B. Ray, and Y . Chen, “Vulnerability detection with code language models: How far are we?” inICSE, 2025
2025
-
[12]
Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,” in 2024 IEEE Symposium on Security and Privacy (SP), 2024
2024
-
[13]
How far have we gone in vulnerability detection using large language models,
Z. Gao, H. Wang, Y . Zhou, W. Zhu, and C. Zhang, “How far have we gone in vulnerability detection using large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2311.12420
-
[14]
Do large language models show decision heuristics similar to humans? a case study using GPT-3.5,
G. Suri, L. R. Slater, A. Ziaee, and M. Nguyen, “Do large language models show decision heuristics similar to humans? a case study using GPT-3.5,”Journal of Experimental Psychology: General, 2024
2024
-
[15]
Justice in judgment: Unveiling (hidden) bias in LLM-assisted peer reviews,
S. S. M. Vasu, I. Sheth, H.-P. Wang, R. Binkyte, and M. Fritz, “Justice in judgment: Unveiling (hidden) bias in LLM-assisted peer reviews,” inNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling, 2025
2025
-
[16]
Ariely,Predictably irrational: The hidden forces that shape our decisions
D. Ariely,Predictably irrational: The hidden forces that shape our decisions. HarperCollins, 2008
2008
-
[17]
A survey of behavioral finance,
N. Barberis and R. Thaler, “A survey of behavioral finance,”Handbook of the Economics of Finance, 2003
2003
-
[18]
The effect of price, brand name, and store name on buyers’ perceptions of product quality: An integrative review,
A. R. Rao and K. B. Monroe, “The effect of price, brand name, and store name on buyers’ perceptions of product quality: An integrative review,”Journal of Marketing Research, 1989
1989
-
[19]
On the elicitation of preferences for alternative therapies,
B. J. McNeil, S. G. Pauker, H. C. Sox Jr, and A. Tversky, “On the elicitation of preferences for alternative therapies,”New England Journal of Medicine, 1982
1982
-
[20]
Cognitive biases in software engineering: A systematic mapping study,
R. Mohanani, I. Salman, B. Turhan, P. Rodr ´ıguez, and P. Ralph, “Cognitive biases in software engineering: A systematic mapping study,”IEEE Transactions on Software Engineering, 2018
2018
-
[21]
The halo effect revis- ited: Forewarned is not forearmed,
C. G. Wetzel, T. D. Wilson, and J. Kort, “The halo effect revis- ited: Forewarned is not forearmed,”Journal of Experimental Social Psychology, 1981
1981
-
[22]
Peer-review practices of psychological journals: The fate of published articles, submitted again,
D. P. Peters and S. J. Ceci, “Peer-review practices of psychological journals: The fate of published articles, submitted again,”Behavioral and Brain Sciences, 1982
1982
-
[23]
The effect of message framing on breast self-examination attitudes, intentions, and behavior,
B. E. Meyerowitz and S. Chaiken, “The effect of message framing on breast self-examination attitudes, intentions, and behavior,”Journal of Personality and Social Psychology, 1987
1987
-
[24]
Experts, amateurs, and real estate: An anchoring-and-adjustment perspective on property pricing decisions,
G. B. Northcraft and M. A. Neale, “Experts, amateurs, and real estate: An anchoring-and-adjustment perspective on property pricing decisions,”Organizational Behavior and Human Decision Processes, 1987
1987
-
[25]
First offers as anchors: The role of perspective-taking and negotiator focus,
A. D. Galinsky and T. Mussweiler, “First offers as anchors: The role of perspective-taking and negotiator focus,”Journal of Personality and Social Psychology, 2001
2001
-
[26]
Llms in software security: A survey of vulnerability detection techniques and insights,
Z. Sheng, Z. Chen, S. Gu, H. Huang, G. Gu, and J. Huang, “Llms in software security: A survey of vulnerability detection techniques and insights,”ACM Computing Surveys, 2025
2025
-
[27]
Large language models for cyber security: A systematic literature review,
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[28]
Large language model for vulnerability detection and repair: Literature review and the road ahead,
X. Zhou, S. Cao, X. Sun, and D. Lo, “Large language model for vulnerability detection and repair: Literature review and the road ahead,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[29]
Y . Sun, D. Wu, Y . Xue, H. Liu, W. Ma, L. Zhang, Y . Liu, and Y . Li, “Llm4vuln: A unified evaluation framework for decoupling and enhancing llms’ vulnerability reasoning,” 2024. [Online]. Available: https://arxiv.org/abs/2401.16185
-
[30]
Finetuning Large Language Models for Vulnerability Detection
A. Shestov, R. Levichev, R. Mussabayev, E. Maslov, A. Cheshkov, and P. Zadorozhny, “Finetuning large language models for vulnerability detection,” 2024. [Online]. Available: https://arxiv.org/abs/2401.17010
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Outside the comfort zone: Analysing llm capabilities in software vulnerability detection,
Y . Guo, C. Patsakis, Q. Hu, Q. Tang, and F. Casino, “Outside the comfort zone: Analysing llm capabilities in software vulnerability detection,” inESORICS, 2024
2024
-
[32]
Prompt-enhanced software vulnerability detection using chatgpt,
C. Zhang, H. Liu, J. Zeng, K. Yang, Y . Li, and H. Li, “Prompt-enhanced software vulnerability detection using chatgpt,” inProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, 2024
2024
-
[33]
Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,
X. Du, G. Zheng, K. Wang, Y . Zou, Y . Wang, W. Deng, J. Feng, M. Liu, B. Chen, X. Peng, T. Ma, and Y . Lou, “Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[34]
Llmxcpg: Context-aware vulnerability detection through code property graph-guided llms,
A. Lekssayset al., “Llmxcpg: Context-aware vulnerability detection through code property graph-guided llms,” inUSENIX Security Symposium, 2025
2025
-
[35]
LLMDFA: Analyzing dataflow in code with large language models,
C. Wang, W. Zhang, Z. Su, X. Xu, X. Xie, and X. Zhang, “LLMDFA: Analyzing dataflow in code with large language models,” inNeural Information Processing Systems, 2024
2024
-
[36]
Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,
Y . Sun, D. Wu, Y . Xue, H. Liu, H. Wang, Z. Xu, X. Xie, and Y . Liu, “Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,” inICSE, 2024
2024
-
[37]
From Naptime to Big Sleep: Using large language models to catch vulnerabilities in real-world code,
Google Project Zero, “From Naptime to Big Sleep: Using large language models to catch vulnerabilities in real-world code,” November 2024. [Online]. Available: https://projectzero.google/2024/ 10/from-naptime-to-big-sleep.html
2024
-
[38]
Comparison of static application security testing tools and large language models for repo-level vulnerability detection,
X. Zhou, D.-M. Tran, T. Le-Cong, T. Zhang, I. C. Irsan, J. Sumarlin, B. Le, and D. Lo, “Comparison of static application security testing tools and large language models for repo-level vulnerability detection,”
-
[39]
Available: https://arxiv.org/abs/2407.16235
[Online]. Available: https://arxiv.org/abs/2407.16235
-
[40]
Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,
A. Yildiz, S. G. Teo, Y . Lou, Y . Feng, C. Wang, and D. M. Divakaran, “Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,” inACL, 2025
2025
-
[41]
Y . Liu, L. Gao, M. Yang, Y . Xie, P. Chen, X. Zhang, and W. Chen, “Vuldetectbench: Evaluating the deep capability of vulnerability detection with large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.07595
-
[42]
Instructed to bias: Instruction-tuned language models exhibit emergent cognitive bias,
I. Itzhak, G. Stanovsky, N. Rosenfeld, and Y . Belinkov, “Instructed to bias: Instruction-tuned language models exhibit emergent cognitive bias,”TACL, 2024
2024
-
[43]
Influence of external information on large language models mirrors social cognitive patterns,
N. Bian, H. Lin, P. Liu, Y . Lu, C. Zhang, B. He, X. Han, and L. Sun, “Influence of external information on large language models mirrors social cognitive patterns,”IEEE Transactions on Computational Social Systems, 2025
2025
-
[44]
Capturing failures of large language models via human cognitive biases,
E. Jones and J. Steinhardt, “Capturing failures of large language models via human cognitive biases,” inNeurIPS, 2022
2022
-
[45]
Benchmarking cognitive biases in large language models as evaluators,
R. Koo, M. Lee, V . Raheja, J. I. Park, Z. M. Kim, and D. Kang, “Benchmarking cognitive biases in large language models as evaluators,” inFindings of ACL, 2024
2024
-
[46]
Exploiting synergistic cognitive biases to bypass safety in llms,
X. Yang, B. Zhou, X. Tang, J. Han, and S. Hu, “Exploiting synergistic cognitive biases to bypass safety in llms,” inProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[47]
When wording steers the evaluation: Framing bias in llm judges,
Y . Hwang, D. Lee, T. Kang, M. Lee, and K. Jung, “When wording steers the evaluation: Framing bias in llm judges,” 2026. [Online]. Available: https://arxiv.org/abs/2601.13537
-
[48]
Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting,
M. Sclar, Y . Choi, Y . Tsvetkov, and A. Suhr, “Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting,” inICLR, 2024
2024
-
[49]
State of what art? a call for multi-prompt LLM evaluation,
M. Mizrahi, G. Kaplan, D. Malkin, R. Dror, D. Shahaf, and G. Stanovsky, “State of what art? a call for multi-prompt LLM evaluation,”TACL, 2024
2024
-
[50]
Towards understanding sycophancy in language models,
M. Sharma et al., “Towards understanding sycophancy in language models,” inICLR, 2024
2024
-
[51]
Syceval: Evaluating llm sycophancy,
A. Fanous, J. Goldberg, A. Agarwal, J. Lin, A. Zhou, S. Xu, V . Bikia, R. Daneshjou, and S. Koyejo, “Syceval: Evaluating llm sycophancy,” AAAI/ACM Conference on AI, Ethics, and Society, 2025
2025
-
[52]
ELEPHANT: Measuring and understanding social sycophancy in LLMs,
M. Cheng, S. Yu, C. Lee, P. Khadpe, L. Ibrahim, and D. Jurafsky, “ELEPHANT: Measuring and understanding social sycophancy in LLMs,” inICLR, 2026
2026
-
[53]
Addressing cognitive bias in medical language models,
S. Schmidgall, C. Harris, I. Essien, D. Olshvang, T. Rahman, J. W. Kim, R. Ziaei, J. Eshraghian, P. Abadir, and R. Chellappa, “Addressing cognitive bias in medical language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.08113
-
[54]
Ai can be cognitively biased: An exploratory study on threshold priming in llm-based batch relevance assessment,
N. Chen, J. Liu, X. Dong, Q. Liu, T. Sakai, and X.-M. Wu, “Ai can be cognitively biased: An exploratory study on threshold priming in llm-based batch relevance assessment,” inACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, 2024
2024
-
[55]
Justice or prejudice? quantifying biases in LLM-as-a-judge,
J. Ye, Y . Wang, Y . Huang, D. Chen, Q. Zhang, N. Moniz, T. Gao, W. Geyer, C. Huang, P.-Y . Chen, N. V . Chawla, and X. Zhang, “Justice or prejudice? quantifying biases in LLM-as-a-judge,” inICLR, 2025
2025
-
[56]
Beauty and the bias: Exploring the impact of attractiveness on multimodal large language models,
A. Gulati, M. D’Inc `a, N. Sebe, B. Lepri, and N. Oliver, “Beauty and the bias: Exploring the impact of attractiveness on multimodal large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2504.16104
-
[57]
More or less wrong: A benchmark for directional bias in llm comparative reasoning,
M. Shafiei, H. Saffari, and N. S. Moosavi, “More or less wrong: A benchmark for directional bias in llm comparative reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2506.03923
-
[58]
Large language models show amplified cognitive biases in moral decision-making,
V . Cheung, M. Maier, and F. Lieder, “Large language models show amplified cognitive biases in moral decision-making,”Proceedings of the National Academy of Sciences, 2025
2025
-
[59]
How does cognitive bias affect large language models? a case study on the anchoring effect in price negotiation simulations,
Y . Takenami, Y . J. Huang, Y . Murawaki, and C. Chu, “How does cognitive bias affect large language models? a case study on the anchoring effect in price negotiation simulations,” inFindings of EMNLP, 2025
2025
-
[60]
Trojan- Puzzle: Covertly Poisoning Code-Suggestion Models ,
H. Aghakhani, W. Dai, A. Manoel, X. Fernandes, A. Kharkar, C. Kruegel, G. Vigna, D. Evans, B. Zorn, and R. Sim, “ Trojan- Puzzle: Covertly Poisoning Code-Suggestion Models ,” in2024 IEEE Symposium on Security and Privacy (SP), 2024
2024
-
[61]
An llm-assisted easy-to-trigger backdoor attack on code completion models: injecting disguised vulnerabilities against strong detection,
S. Yan, S. Wang, Y . Duan, H. Hong, K. Lee, D. Kim, and Y . Hong, “An llm-assisted easy-to-trigger backdoor attack on code completion models: injecting disguised vulnerabilities against strong detection,” inUSENIX Conference on Security Symposium, 2024
2024
-
[62]
Stealthy Backdoor Attack for Code Models ,
Z. Yang, B. Xu, J. M. Zhang, H. J. Kang, J. Shi, J. He, and D. Lo, “ Stealthy Backdoor Attack for Code Models ,”IEEE Transactions on Software Engineering, 2024
2024
-
[63]
Black-box adversarial attacks on LLM-based code completion,
S. Jenko, N. M ¨undler, J. He, M. Vero, and M. Vechev, “Black-box adversarial attacks on LLM-based code completion,” inICML, 2025
2025
-
[64]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection,” inACM Workshop on Artificial Intelligence and Security (AISec), 2023
2023
-
[65]
Adversarial bug reports as a security risk in language model-based automated program repair,
P. Przymus, A. Happe, and J. Cito, “Adversarial bug reports as a security risk in language model-based automated program repair,”
-
[66]
Adversarial Bug Reports as a Security Risk in Language Model-Based Automated Program Repair
[Online]. Available: https://arxiv.org/abs/2509.05372
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Trust me, i know this function: Hijacking LLM static analysis using bias,
S. Bernstein, D. Beste, D. Ayzenshteyn, L. Schonherr, and Y . Mirsky, “Trust me, i know this function: Hijacking LLM static analysis using bias,” inNetwork and Distributed System Security Symposium, 2026
2026
-
[68]
Attractive metadata attack: Inducing llm agents to invoke malicious tools,
K. Mo, L. Hu, Y . Long, and Z. Li, “Attractive metadata attack: Inducing llm agents to invoke malicious tools,” inNeurIPS 2025, Poster, 2025
2025
-
[69]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
T. Shi et al., “Promptarmor: Simple yet effective prompt injection defenses,” 2025. [Online]. Available: https://arxiv.org/abs/2507.15219
-
[70]
Adversarial suffix filtering: a defense pipeline for llms,
D. Khachaturov and R. Mullins, “Adversarial suffix filtering: a defense pipeline for llms,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.09602
-
[71]
To protect the llm agent against the prompt injection attack with polymorphic prompt,
Z. Wang, N. Nagaraja, L. Zhang, H. Bahsi, P. Patil, and P. Liu, “To protect the llm agent against the prompt injection attack with polymorphic prompt,” inIEEE/IFIP International Conference on Dependable Systems and Networks - Supplemental Volume, 2025
2025
-
[72]
S. Thornton, “Can adversarial code comments fool ai security reviewers – large-scale empirical study of comment-based attacks and defenses against llm code analysis,” 2026. [Online]. Available: https://arxiv.org/abs/2602.16741
-
[73]
A task-based taxonomy of cognitive biases for information visualization,
E. Dimara, S. Franconeri, C. Plaisant, A. Bezerianos, and P. Drag- icevic, “A task-based taxonomy of cognitive biases for information visualization,”IEEE Transactions on Visualization and Computer Graphics, 2020
2020
-
[74]
Cleanvul: Automatic function-level vulnerability detection in code commits using llm heuristics,
Y . Li et al., “Cleanvul: Automatic function-level vulnerability detection in code commits using llm heuristics,” 2025. [Online]. Available: https://arxiv.org/abs/2411.17274
-
[75]
Llama 4 maverick,
Meta AI, “Llama 4 maverick,” https://openrouter.ai/meta-llama/ llama-4-maverick, 2025, [Online; accessed 17-Dec-2025]
2025
-
[76]
Llama 3.3 70b instruct,
Meta-AI, “Llama 3.3 70b instruct,” https://openrouter.ai/meta-llama/ llama-3.3-70b-instruct, 2024, [Online; accessed 17-Dec-2025]
2024
-
[77]
Deepseek v3.1,
DeepSeek-AI, “Deepseek v3.1,” https://openrouter.ai/deepseek/ deepseek-chat-v3.1, 2025, [Online; accessed 17-Dec-2025]
2025
-
[78]
Qwen3 coder next,
Alibaba Cloud, “Qwen3 coder next,” https://openrouter.ai/qwen/ qwen3-coder-next, 2026, [Online; accessed 12-Feb-2026]
2026
-
[79]
Mistral small 3.1 24b,
Mistral AI, “Mistral small 3.1 24b,” https://openrouter.ai/mistralai/ mistral-small-3.1-24b-instruct, 2025, [Online; accessed 17-Dec-2025]
2025
-
[80]
Update to gpt-5 system card: Gpt-5.2,
OpenAI, “Update to gpt-5 system card: Gpt-5.2,” https: //cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/ oai 5 2 system-card.pdf, OpenAI, Tech. Rep., 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.