The Alignment Problem in Constrained Code Generation
Pith reviewed 2026-06-26 13:30 UTC · model grok-4.3
The pith
Incomplete constrainers cause constrained decoding to underperform unconstrained decoding in code generation by distorting language model distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
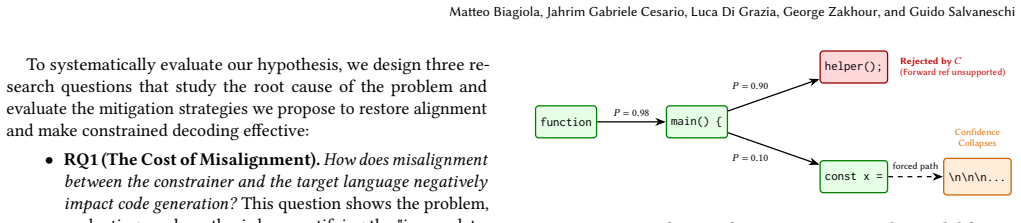
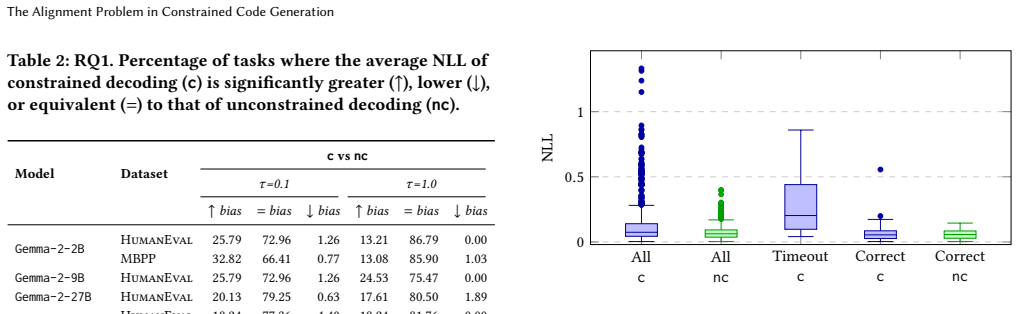
When the constrainer is incomplete, unconstrained decoding significantly outperforms constrained decoding in terms of functional correctness. Incompleteness pushes the model into low-probability regions of the program space, causing the generation to frequently time out, and reducing functional correctness by up to 97%.
What carries the argument
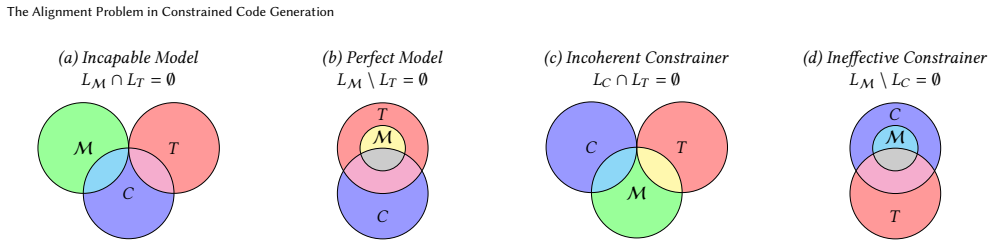
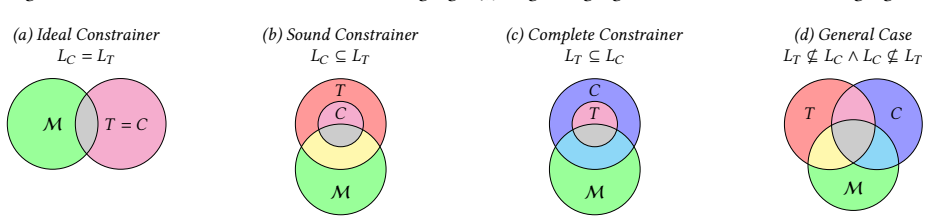
The alignment between constrainer, language model, and target specification language, where incompleteness creates a bias that distorts the model's distribution over valid programs.
If this is right
- Constrained decoding improves functional correctness only when the constrainer is complete enough to avoid rejecting valid programs.
- Design of constrainers must prioritize completeness alongside soundness to prevent distortion of the language model distribution.
- Functional correctness metrics for constrained code generation must account for increased timeout rates induced by incompleteness.
- Unconstrained decoding remains preferable in settings where the constrainer cannot be made sufficiently complete.
Where Pith is reading between the lines
- Measuring the degree of incompleteness before deployment could help decide whether to apply constrained decoding at all.
- Hybrid systems that switch to unconstrained generation when constraints become too restrictive may mitigate the observed performance loss.
- The same misalignment effect could appear in other constrained generation domains such as structured text or formal specifications.
Load-bearing premise
The observed performance gaps are caused primarily by incompleteness of the constrainer rather than other experimental factors such as benchmark selection or timeout thresholds.
What would settle it
An experiment that applies a demonstrably complete constrainer and finds constrained decoding then matches or exceeds unconstrained decoding on functional correctness.
Figures

read the original abstract
Large Language Models (LLMs) have demonstrated strong capabilities in code generation, but their outputs frequently contain syntax or type errors that result in compilation failures. Constrained decoding has been proposed as a solution to mitigate compilation errors by construction, improving functional correctness as a byproduct. However, previous works overlook a critical aspect of constrained decoding: the alignment between constrainer (e.g., types), language model and the target specification language (e.g., TypeScript). Misalignment is caused by the constrainer being incomplete--rejecting programs that belong to the target--or unsound--allowing programs that are not part of the target. The bias created by incompleteness distorts the language model distribution, and can be detrimental for code generation. We evaluate this hypothesis using seven language models, two target languages, two constrainers, enforcing types and syntax during decoding, and we study how language models react to varying levels of incompleteness. On three benchmarks, when the constrainer is incomplete, unconstrained decoding significantly outperforms constrained decoding in terms of functional correctness. Incompleteness pushes the model into low-probability regions of the program space, causing the generation to frequently time out, and reducing functional correctness by up to 97%. These contributions make the community aware of the negative effects of misalignment in constrained decoding, and provide quantitative insights on how to design constrainers that are beneficial for code generation systems with formal guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that misalignment between constrainers, language models, and target languages in constrained code generation arises from incompleteness (rejecting valid programs), which distorts the LM distribution, pushes generations into low-probability regions, causes frequent timeouts, and reduces functional correctness by up to 97% relative to unconstrained decoding. It supports this via evaluations across seven models, two target languages, two constrainers (types and syntax), and three benchmarks, concluding that incomplete constrainers can be detrimental and offering insights for better constrainer design.
Significance. If the central empirical claim can be isolated from confounds, the work would highlight an important practical limitation of constrained decoding for code generation that prior literature has overlooked. The quantitative results on performance degradation could inform constrainer design choices in systems aiming for formal guarantees. No machine-checked proofs, reproducible artifacts, or parameter-free derivations are described.
major comments (3)
- [Evaluation section] Evaluation section: The attribution of the performance gap (unconstrained outperforming constrained by up to 97%) to incompleteness lacks controls that vary timeout thresholds independently of the constrainer; without such isolation it is unclear whether the observed timeouts and correctness drops are driven by incompleteness or by the interaction of the chosen timeout with constrained search paths.
- [Methods and results] Methods and results: Incompleteness levels are not shown to be quantified via an independent metric separate from the decoding runs themselves; if incompleteness is measured from the same generations that exhibit timeouts, the causal claim that incompleteness pushes models into low-probability regions risks circularity.
- [Abstract and evaluation] Abstract and evaluation: The claim that 'incompleteness pushes the model into low-probability regions' is presented as the operative mechanism, yet no direct measurement (e.g., probability mass or entropy comparisons between constrained and unconstrained paths) is described to support this over alternative explanations such as benchmark selection or model-specific sampling.
minor comments (2)
- [Abstract] The abstract states results on 'seven language models, two target languages, two constrainers' but does not list the exact models, languages, or constrainers; adding an explicit table or list in the methods would improve clarity.
- [Evaluation] No discussion of how functional correctness is measured (e.g., test-case pass rate, exact match) or inter-rater reliability for any manual checks appears in the provided abstract; this detail should be added to the evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our experimental design. We address each major comment below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The attribution of the performance gap (unconstrained outperforming constrained by up to 97%) to incompleteness lacks controls that vary timeout thresholds independently of the constrainer; without such isolation it is unclear whether the observed timeouts and correctness drops are driven by incompleteness or by the interaction of the chosen timeout with constrained search paths.
Authors: We acknowledge that varying timeout thresholds independently would provide stronger isolation of the incompleteness effect. Our experiments use a fixed timeout value consistent with prior constrained decoding literature for code generation. The higher timeout rates under constrained decoding arise because incompleteness forces the search to exhaust valid high-probability paths, but we agree this could interact with the timeout choice. We will revise the evaluation section to explicitly discuss the fixed timeout as a potential confound and include it as a direction for future work. revision: partial
-
Referee: [Methods and results] Methods and results: Incompleteness levels are not shown to be quantified via an independent metric separate from the decoding runs themselves; if incompleteness is measured from the same generations that exhibit timeouts, the causal claim that incompleteness pushes models into low-probability regions risks circularity.
Authors: Incompleteness is quantified independently by measuring the rate at which the constrainer rejects ground-truth programs from the benchmarks (i.e., valid programs in the target language that the constrainer incorrectly rejects). This metric is computed prior to and separately from any decoding runs or timeout observations. The timeouts and functional correctness results are then correlated with these pre-computed incompleteness levels across different constrainers. We will revise the methods section to make this separation explicit and include the exact formula used for the independent incompleteness metric. revision: yes
-
Referee: [Abstract and evaluation] Abstract and evaluation: The claim that 'incompleteness pushes the model into low-probability regions' is presented as the operative mechanism, yet no direct measurement (e.g., probability mass or entropy comparisons between constrained and unconstrained paths) is described to support this over alternative explanations such as benchmark selection or model-specific sampling.
Authors: We rely on indirect but consistent evidence: across seven models and three benchmarks, incomplete constrainers produce substantially higher timeout rates and lower functional correctness, which we attribute to the model being forced away from its preferred (high-probability) valid programs. While direct probability mass or entropy measurements on paths would provide stronger mechanistic support, such measurements were not performed in the current study. We will add a limitations paragraph noting this and that alternative explanations cannot be fully ruled out without those measurements. revision: partial
Circularity Check
No circularity; purely empirical evaluation
full rationale
The paper advances an empirical hypothesis about misalignment in constrained decoding and tests it via direct experiments across seven LLMs, two languages, two constrainers, and three benchmarks. Functional correctness, timeout rates, and incompleteness effects are measured as observed outcomes rather than derived from any equations, fitted parameters, or self-referential definitions. No load-bearing self-citations, ansatzes, or uniqueness theorems appear in the abstract or described contributions. The central quantitative claim (up to 97% reduction) is an experimental result, not a prediction that reduces to its inputs by construction. This matches the default expectation of no significant circularity for benchmark-driven work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmarks and models used are representative for assessing constrained decoding effects.
Reference graph
Works this paper leans on
-
[1]
Agrawal, Aditya Kanade, Navin Goyal, Shuvendu K
Lakshya A. Agrawal, Aditya Kanade, Navin Goyal, Shuvendu K. Lahiri, and Sriram K. Rajamani. 2023. Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023...
2023
-
[2]
Guidance AI. 2025. LLGuidance: Super-fast Structured Outputs for Large Lan- guage Models. GitHub repository. https://guidance-ai.github.io/llguidance/llg- go-brrr Version 1.0.0, MIT License
2025
-
[3]
Andrea Arcuri and Lionel C. Briand. 2014. A Hitchhiker’s guide to statistical tests for assessing randomized algorithms in software engineering.Softw. Test. Verification Reliab.24, 3 (2014), 219–250. doi:10.1002/STVR.1486
-
[4]
Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J
Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. CoRRabs/2108.07732 (2021). arXiv:2108.07732 https://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[5]
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov. 2025. Small Lan- guage Models are the Future of Agentic AI.CoRRabs/2506.02153 (2025). doi:10.48550/ARXIV.2506.02153 arXiv:2506.02153
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.02153 2025
-
[6]
Loubna Ben Allal, Niklas Muennighoff, Logesh Kumar Umapathi, Ben Lipkin, and Leandro von Werra. 2022. A framework for the evaluation of code genera- tion models. https://github.com/bigcode-project/bigcode-evaluation-harness. Accessed 2026-06-18
2022
-
[7]
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. 2026. Qwen3-Coder-Next Technical Report.CoRR abs/2603.00729 (2026). doi:10.48550/ARXIV.2603.00729 arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.00729 2026
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[9]
Yiu Wai Chow, Luca Di Grazia, and Michael Pradel. 2024. PyTy: Repairing Static Type Errors in Python. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 87:1–87:13. doi:10.1145/3597503.3639184
-
[10]
Ruan, Yaxing Cai, Ziyi Xu, Yilong Zhao, Ruihang Lai, and Tianqi Chen
Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ziyi Xu, Yilong Zhao, Ruihang Lai, and Tianqi Chen. 2025. XGrammar: Flexible and Efficient Structured Genera- tion Engine for Large Language Models. InProceedings of the Eighth Conference on Machine Learning and Systems, MLSys 2025, Santa Clara, CA, USA, May 12- 15, 2025, Matei Zaharia, Gauri Joshi, and Yingyan (Ce...
2025
-
[11]
Margarida Ferreira, Victor Nicolet, Joey Dodds, and Daniel Kroening. 2025. Pro- gram Synthesis from Partial Traces.Proc. ACM Program. Lang.9, PLDI (2025), 1642–1665. doi:10.1145/3729316
-
[12]
Teodoro Freund, Yann Hamdaoui, and Arnaud Spiwack. 2021. Union and inter- section contracts are hard, actually. InDLS 2021: Proceedings of the 17th ACM SIG- PLAN International Symposium on Dynamic Languages, Virtual Event / Chicago, IL, USA, October 19, 2021, Arjun Guha (Ed.). ACM, 1–11. doi:10.1145/3486602.3486767
-
[13]
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. 2023. Grammar- Constrained Decoding for Structured NLP Tasks without Finetuning. InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computati...
-
[14]
ggml-org. 2026. GGML BNF Grammars. https://github.com/ggml-org/llama.cpp/ blob/master/grammars/README.md. GitHub, Accessed 2026-03-12
2026
-
[15]
Alessandro Giagnorio, Alberto Martin-Lopez, and Gabriele Bavota. 2025. En- hancing Code Generation for Low-Resource Languages: No Silver Bullet. In33rd IEEE/ACM International Conference on Program Comprehension, ICPC@ICSE 2025, Ottawa, ON, Canada, April 27-28, 2025. IEEE, 478–488. doi:10.1109/ICPC66645. 2025.00058
-
[16]
Emmanuel Anaya Gonzalez, Sairam Vaidya, Kanghee Park, Ruyi Ji, Taylor Berg- Kirkpatrick, and Loris D’Antoni. 2025. Constrained Sampling for Language Models Should Be Easy: An MCMC Perspective.CoRRabs/2506.05754 (2025). doi:10.48550/ARXIV.2506.05754 arXiv:2506.05754
-
[17]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wen- feng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence.CoRRabs/2401.14196 (2024). doi:10.48550/ARXIV.2401.14196 arXiv:2401.14196
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14196 2024
-
[18]
Md Mahade Hasan, Muhammad Waseem, Kai-Kristian Kemell, Jussi Rasku, Juha Ala-Rantala, and Pekka Abrahamsson. 2026. Assessing small language models for code generation: An empirical study with benchmarks.J. Syst. Softw.236 (2026), 112815. doi:10.1016/J.JSS.2026.112815
-
[19]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans. Softw. Eng. Methodol.33, 8 (2024), 220:1–220:79. doi:10.1145/3695988
-
[20]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report.CoRRabs/2409.12186 (2024). doi:10.48550/ARXIV.2409.12186 arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[22]
Nima Karimipour, Michael Pradel, Martin Kellogg, and Manu Sridharan. 2025. LLM-Based Repair of Static Nullability Errors.CoRRabs/2507.20674 (2025). doi:10.48550/ARXIV.2507.20674 arXiv:2507.20674
-
[23]
Lingxiao Li, Salar Rahili, and Yiwei Zhao. 2025. Correctness-Guaranteed Code Generation via Constrained Decoding.CoRRabs/2508.15866 (2025). doi:10.48550/ ARXIV.2508.15866 arXiv:2508.15866
arXiv 2025
-
[24]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. InAdvances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Pro- cessing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 1...
2023
-
[25]
Lew, Tim Vieira, and Timothy J
João Loula, Benjamin LeBrun, Li Du, Ben Lipkin, Clemente Pasti, Gabriel Grand, Tianyu Liu, Yahya Emara, Marjorie Freedman, Jason Eisner, Ryan Cotterell, Vikash Mansinghka, Alexander K. Lew, Tim Vieira, and Timothy J. O’Donnell
-
[26]
InThe Thirteenth International Conference on Learn- ing Representations, ICLR 2025, Singapore, April 24-28, 2025
Syntactic and Semantic Control of Large Language Models via Se- quential Monte Carlo. InThe Thirteenth International Conference on Learn- ing Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=xoXn62FzD0
2025
-
[27]
Davide Molinelli, Luca Di Grazia, Alberto Martin-Lopez, Michael D. Ernst, and Mauro Pezzè. 2025. Do LLMs Generate Useful Test Oracles? An Empirical Study with an Unbiased Dataset. In40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025. IEEE, 278–290. doi:10.1109/ASE63991.2025.00031
-
[28]
Davide Molinelli, Alberto Martin-Lopez, Elliott Zackrone, Beyza Eken, Michael D. Ernst, and Mauro Pezzè. 2025. Tratto: A Neuro-Symbolic Approach to Deriving Axiomatic Test Oracles.Proc. ACM Softw. Eng.2, ISSTA (2025), 1887–1909. doi:10.1145/3728960
-
[29]
Niels Mündler, Jasper Dekoninck, and Martin T. Vechev. 2025. Constrained Decoding of Diffusion LLMs with Context-Free Grammars.CoRRabs/2508.10111 (2025). doi:10.48550/ARXIV.2508.10111 arXiv:2508.10111
-
[30]
Niels Mündler, Jingxuan He, Hao Wang, Koushik Sen, Dawn Song, and Martin T. Vechev. 2025. Type-Constrained Code Generation with Language Models.Proc. ACM Program. Lang.9, PLDI (2025), 601–626. doi:10.1145/3729274
-
[31]
Shaan Nagy, Timothy Zhou, Nadia Polikarpova, and Loris D’Antoni. 2026. Chop- Chop: A Programmable Framework for Semantically Constraining the Output of Language Models.Proc. ACM Program. Lang.10, POPL (2026), 1905–1932. doi:10.1145/3776708
-
[32]
NousResearch. 2025. NousResearch/json-mode-eval. Hugging Face dataset repos- itory. https://huggingface.co/datasets/NousResearch/json-mode-eval Accessed Matteo Biagiola, Jahrim Gabriele Cesario, Luca Di Grazia, George Zakhour, and Guido Salvaneschi 2026-03-12
2025
-
[33]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023). doi:10. 48550/ARXIV.2303.08774 arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[34]
Zhang, Mark Harman, and Meng Wang
Shuyin Ouyang, Jie M. Zhang, Mark Harman, and Meng Wang. 2025. An Em- pirical Study of the Non-Determinism of ChatGPT in Code Generation.ACM Trans. Softw. Eng. Methodol.34, 2 (2025), 42:1–42:28. doi:10.1145/3697010
-
[35]
Kanghee Park, Jiayu Wang, Taylor Berg-Kirkpatrick, Nadia Polikarpova, and Loris D’Antoni. 2024. Grammar-Aligned Decoding. InAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, Amir Globersons, Lester Mackey, Danielle Belgrave, An...
2024
-
[36]
Kanghee Park, Timothy Zhou, and Loris D’Antoni. 2025. Flexible and Efficient Grammar-Constrained Decoding. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceed- ings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Teg...
2025
-
[37]
Gabriel Poesia, Alex Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gulwani. 2022. Synchromesh: Reliable Code Generation from Pre-trained Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=KmtVD97J43e
2022
-
[38]
Bierman, and Panagiotis Vekris
Aseem Rastogi, Nikhil Swamy, Cédric Fournet, Gavin M. Bierman, and Panagiotis Vekris. 2015. Safe & Efficient Gradual Typing for TypeScript. InProceedings of the 42nd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2015, Mumbai, India, January 15-17, 2015, Sriram K. Rajamani and David Walker (Eds.). ACM, 167–180. doi:10.114...
-
[39]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xi- aoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton- Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Th...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[40]
Jan-Philipp Schreiter, Kirill Fuks, and Horst Hellbrück. 2025. A Novel Approach and Framework for Configuration of Agent-Based LLMs in Real-World Applica- tions. InIntelligent Computing, Kohei Arai (Ed.). Springer Nature Switzerland, Cham, 635–650
2025
-
[41]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.CoRRabs/2402.03300 (2024). doi:10.48550/ARXIV.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[42]
Tarun Suresh, Debangshu Banerjee, Shubham Ugare, Sasa Misailovic, and Gagan- deep Singh. 2025. DINGO: Constrained Inference for Diffusion LLMs. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Infor- mation Processing Systems 2025, NeurIPS 2025, San Diago, CA, USA, December 2-7, 2025 / Mexico City, Mexico, November 30 - ...
2025
-
[43]
Gemma Team. 2024. Gemma: Open Models Based on Gemini Research and Technology.CoRRabs/2403.08295 (2024). doi:10.48550/ARXIV.2403.08295 arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.08295 2024
-
[44]
TOML. 2026. TOML: Tom’s Obvious Minimal Language, v1.1.0. https://toml.io/ en/. Accessed 2026-03-13
2026
-
[46]
Shubham Ugare, Tarun Suresh, Hangoo Kang, Sasa Misailovic, and Gagandeep Singh. 2025. SynCode: LLM Generation with Grammar Augmentation.Trans. Mach. Learn. Res.2025 (2025). https://openreview.net/forum?id=HiUZtgAPoH
2025
-
[47]
András Vargha and Harold D. Delaney. 2000. A Critique and Improvement of the "CL" Common Language Effect Size Statistics of McGraw and Wong. Journal of Educational and Behavioral Statistics25, 2 (2000), 101–132. http: //www.jstor.org/stable/1165329
arXiv 2000
-
[48]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
2017
-
[49]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. 2023. Efficient Guided Generation for Large Language Models.CoRRabs/2307.09702 (2023). doi:10.48550/ARXIV.2307.09702 arXiv:2307.09702
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09702 2023
-
[50]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Leret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. 2025. SWE-smith: Scaling Data for Software Engineering Agents.CoRRabs/2504.21798 (2025). doi:10.48550/ARXIV.2504.21798 arXiv:2504.21798
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21798 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.