BacktestBench: Benchmarking Large Language Models for Automated Quantitative Strategy Backtesting
Pith reviewed 2026-05-20 11:43 UTC · model grok-4.3
The pith
BacktestBench benchmarks large language models on automating quantitative trading strategy backtesting using 18,246 real-data QA pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
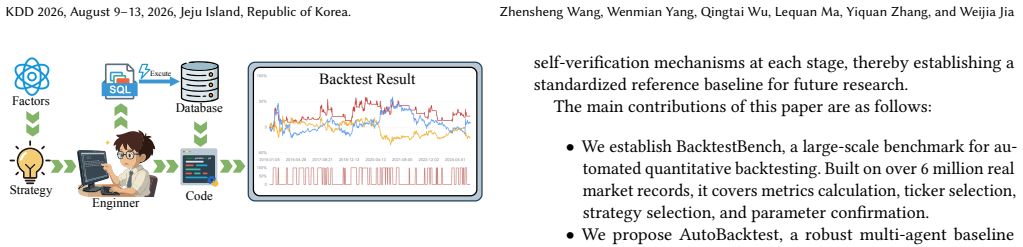
BacktestBench is introduced as the first large-scale benchmark for automated quantitative backtesting, constructed from over 6 million real market records and containing 18,246 annotated question-answering pairs divided into four task categories: metrics calculation, ticker selection, strategy selection, and parameter confirmation. The paper also presents AutoBacktest as a multi-agent system baseline that employs a Summarizer to extract semantic factors, a Retriever for SQL generation, and a Coder for Python implementation to convert natural language strategies into reproducible backtests. Evaluations across 23 LLMs with ablations highlight the role of verification and standardized indicator
What carries the argument
BacktestBench, the benchmark of 18,246 QA pairs from real market data, which evaluates LLMs on end-to-end automation of backtesting tasks.
If this is right
- Models that score high on the benchmark demonstrate better capability in generating accurate backtest code from natural language inputs.
- The AutoBacktest multi-agent approach outperforms single LLM methods by dividing tasks among specialized agents.
- Grounded verification steps and standardized indicator formats are critical for reliable end-to-end backtesting automation.
- Performance varies significantly across the four task categories, with some proving harder for current models.
Where Pith is reading between the lines
- If LLMs master these tasks, they could enable rapid prototyping of trading strategies for retail investors without requiring coding expertise.
- The benchmark opens the door to creating domain-specific training datasets for financial AI applications.
- Future work might expand the tasks to include risk management and portfolio-level backtesting to better simulate real trading environments.
Load-bearing premise
The annotated QA pairs from the 6 million market records accurately reflect the full range of technical and semantic difficulties in real quantitative backtesting.
What would settle it
Comparing the backtest outputs produced by high-scoring LLMs against results from professional quantitative analysts on a held-out set of strategies would test whether benchmark success translates to practical accuracy.
Figures












read the original abstract
Quantitative backtesting is essential for evaluating trading strategies but remains hampered by high technical barriers and limited scalability. While Large Language Models (LLMs) offer a transformative path to automate this complex, interdisciplinary workflow through advanced code generation, tool usage, and agentic planning, the practical realization is significantly challenged by the current lack of a large-scale benchmark dedicated to automated quantitative backtesting, which hinders progress in this field. To bridge this critical gap, we introduce BacktestBench, the first large-scale benchmark for automated quantitative backtesting. Built from over 6 million real market records, it comprises 18,246 meticulously annotated question-answering pairs across four task categories: metrics calculation, ticker selection, strategy selection, and parameter confirmation. We also propose AutoBacktest, a robust multi-agent baseline that translates natural language strategies into reproducible backtests by coordinating a Summarizer for semantic factor extraction, a Retriever for validated SQL generation, and a Coder for Python backtesting implementation. Our evaluation on 23 mainstream LLMs, complemented by targeted ablations, identifies key factors that influence end-to-end performance and highlights the importance of grounded verification and standardized indicator representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BacktestBench, the first large-scale benchmark for automated quantitative backtesting, built from over 6 million real market records and comprising 18,246 annotated QA pairs across four task categories (metrics calculation, ticker selection, strategy selection, and parameter confirmation). It also proposes AutoBacktest, a multi-agent baseline using Summarizer, Retriever, and Coder agents to translate natural language strategies into reproducible backtests, and evaluates performance across 23 LLMs with targeted ablations to identify factors influencing end-to-end results.
Significance. If the benchmark's QA pairs faithfully represent real-world quantitative backtesting challenges and the evaluation is free of annotation artifacts or data leakage, the work would provide a valuable standardized testbed for LLM-based automation in finance. The multi-agent baseline and ablation results on grounded verification could usefully guide future agentic systems, particularly if the dataset construction proves robust.
major comments (2)
- [§3] §3 (Dataset Construction): The central claim that the 18,246 QA pairs 'meticulously annotated' from >6M market records accurately encode the technical and semantic difficulties of backtesting workflows is load-bearing for all downstream LLM scores, yet the manuscript provides no inter-annotator agreement statistics, expert review protocol, or error-rate measurements on a held-out sample. Without these, systematic simplifications (e.g., in SQL templates or omission of slippage/edge cases) cannot be ruled out.
- [§4.2] §4.2 (Evaluation Setup): The paper does not report controls for data leakage between the market records used to build the benchmark and the training data of the 23 evaluated LLMs, nor does it describe how the four task categories were balanced or validated for coverage of real workflows. This directly affects the reliability of the reported performance rankings and ablation conclusions.
minor comments (2)
- [Table 1] Table 1: The caption and column headers for task-category statistics could more explicitly define the 'parameter confirmation' category to avoid ambiguity with 'strategy selection'.
- [§5] §5 (Ablations): The description of the 'standardized indicator representations' ablation would benefit from a concrete example of the representation change and its effect size on a specific LLM.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We have carefully considered the major comments and provide point-by-point responses below. Where appropriate, we will revise the manuscript to incorporate additional details and clarifications to address the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The central claim that the 18,246 QA pairs 'meticulously annotated' from >6M market records accurately encode the technical and semantic difficulties of backtesting workflows is load-bearing for all downstream LLM scores, yet the manuscript provides no inter-annotator agreement statistics, expert review protocol, or error-rate measurements on a held-out sample. Without these, systematic simplifications (e.g., in SQL templates or omission of slippage/edge cases) cannot be ruled out.
Authors: We thank the referee for this observation. The QA pairs were annotated by experts in quantitative finance following a structured protocol designed to reflect real-world backtesting difficulties, including the use of actual market data for generating questions and answers. However, the original manuscript did not report inter-annotator agreement statistics, a detailed expert review protocol, or error-rate measurements. We agree that these would strengthen the paper. In the revision, we will elaborate on the annotation methodology in §3, describe the protocol used, and include any quality assurance steps performed. We will also add a discussion of potential limitations such as possible simplifications in the templates. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Setup): The paper does not report controls for data leakage between the market records used to build the benchmark and the training data of the 23 evaluated LLMs, nor does it describe how the four task categories were balanced or validated for coverage of real workflows. This directly affects the reliability of the reported performance rankings and ablation conclusions.
Authors: We appreciate the referee pointing out these gaps in the evaluation setup. For data leakage, given that training data details for the 23 LLMs (many of which are proprietary) are not publicly accessible, we are unable to perform exhaustive controls. We will add a section in the revised manuscript discussing this challenge and the steps taken to minimize risk, such as using recent market data. Regarding the balancing and validation of task categories, the four categories were chosen to cover essential elements of quantitative strategy development and backtesting as per standard practices in the field. We will revise §4.2 to provide more details on the rationale for category selection, their distribution in the benchmark, and how they map to real workflows based on our design process. revision: partial
- Full controls for data leakage with the training data of proprietary LLMs
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces an external benchmark (BacktestBench with 18,246 QA pairs from >6M real market records) and a multi-agent baseline (AutoBacktest) without any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. Central claims rest on new artifacts and independent LLM evaluations rather than reducing to inputs by construction. This is the most common honest finding for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four task categories (metrics calculation, ticker selection, strategy selection, parameter confirmation) comprehensively cover the quantitative backtesting workflow.
invented entities (2)
-
BacktestBench
no independent evidence
-
AutoBacktest
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce BacktestBench, the first large-scale benchmark for automated quantitative backtesting. Built from over 6 million real market records, it comprises 18,246 meticulously annotated question-answering pairs across four task categories: metrics calculation, ticker selection, strategy selection, and parameter confirmation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AutoBacktest coordinates three functionally specialized agents: (1) the Summarizer, responsible for semantic-level extraction of financial indicators; (2) the Retriever, which handles data-level precise querying and quality verification; and (3) the Coder, focusing on logic-level code implementation and backtest execution.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Hao Hu, Xiaor...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.20534 2025
-
[2]
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang Cai, Haichao Zhu, Jian Sun...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13585 2025
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Yanxu Chen, Zijun Yao, Yantao Liu, Jin Ye, Jianing Yu, Lei Hou, and Juanzi Li. 2025. StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets? CoRRabs/2510.02209 (2025). arXiv:2510.02209 doi:10.48550/ARXIV.2510.02209
-
[5]
2018.Advances in financial machine learning
Marcos Lopez De Prado. 2018.Advances in financial machine learning. John Wiley & Sons
work page 2018
-
[6]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.CoRRabs/2512.02556 (2025). arXiv:2512.02556 doi:10.48550/ARXIV.2512. 02556
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512 2025
-
[7]
Zihan Dong, Xinyu Fan, and Zhiyuan Peng. 2024. FNSPID: A Comprehensive Financial News Dataset in Time Series. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 4918–4927. doi:10.1145/3637528.3671629
-
[8]
Martin Eling and Frank Schuhmacher. 2007. Does the choice of performance measure influence the evaluation of hedge funds?Journal of Banking & Finance 31, 9 (2007), 2632–2647
work page 2007
- [9]
-
[10]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, et al . 2025. Gemma 3 Technical Report. arXiv:2503.19786 [cs.CL] https://arxiv.org/abs/2503. 19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zhaolu Kang, Junhao Gong, Wenqing Hu, Shuo Yin, Kehan Jiang, Zhicheng Fang, Yingjie He, Chunlei Meng, Rong Fu, Dongyang Chen, Leqi Zheng, Eric Hanchen Jiang, Yunfei Feng, Yitong Leng, Junfan Zhu, Xiaoyou Chen, Xi Yang, and Richeng Xuan. 2026. QuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models. arXiv:2601.08689 [cs.CL] https:/...
-
[12]
Zhizhuo Kou, Holam Yu, Jingshu Peng, and Lei Chen. 2024. Automate Strat- egy Finding with LLM in Quant investment.CoRRabs/2409.06289 (2024). arXiv:2409.06289 doi:10.48550/ARXIV.2409.06289
-
[13]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. InThe Thirteenth International Conference on Learning Repr...
work page 2025
-
[14]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM already serve as a database interface? a big bench for large-scale database grounded text-to-SQLs. InProceedings of the 37th Internat...
work page 2023
-
[15]
Xiao-Yang Liu, Ziyi Xia, Jingyang Rui, Jiechao Gao, Hongyang Yang, Ming Zhu, Christina Dan Wang, Zhaoran Wang, and Jian Guo. 2022. FinRL-meta: market environments and benchmarks for data-driven financial reinforcement learning. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curr...
work page 2022
-
[16]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. WizardCoder: Em- powering Code Large Language Models with Evol-Instruct. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/for...
work page 2024
-
[17]
Malik Magdon-Ismail and Amir F Atiya. 2004. Maximum drawdown.Risk Magazine17, 10 (2004), 99–102
work page 2004
-
[18]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card.CoRRabs/2508.10925 (2025). arXiv:2508.10925 doi:10.48550/ARXIV.2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[19]
2011.The evaluation and optimization of trading strategies
Robert Pardo. 2011.The evaluation and optimization of trading strategies. John Wiley & Sons
work page 2011
-
[20]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xi- aoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Tho...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[21]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessí, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: language models can teach themselves to use tools. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates ...
work page 2023
-
[22]
William F Sharpe. 1998. The sharpe ratio.Streetwise–the Best of the Journal of Portfolio Management3, 3 (1998), 169–85
work page 1998
-
[23]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 377, 19 pages
work page 2023
-
[24]
Abhay Srivastava, Sam Jung, and Spencer Mateega. 2025. Market-Bench: Evalu- ating Large Language Models on Introductory Quantitative Trading and Market Dynamics.CoRRabs/2512.12264 (2025). arXiv:2512.12264 doi:10.48550/ARXIV. KDD’26, August 9-13,2026, Jeju, Korea Zhensheng Wang, Wenmian Yang, Qingtai Wu, Lequan Ma, Yiquan Zhang, and Weijia Jia 2512.12264
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[25]
URLhttps://doi.org/10.1145/3226595.3226636
Michael Stonebraker, Lawrence A. Rowe, and Michael Hirohama. 2019. The implementation of POSTGRES. InMaking Databases Work: the Pragmatic Wisdom of Michael Stonebraker, Michael L. Brodie (Ed.). ACM Books, Vol. 22. ACM / Morgan & Claypool, 519–559. doi:10.1145/3226595.3226639
-
[26]
Shuo Sun, Molei Qin, Wentao Zhang, Haochong Xia, Chuqiao Zong, Jie Ying, Yonggang Xie, Lingxuan Zhao, Xinrun Wang, and Bo An. 2023. TradeMaster: a holistic quantitative trading platform empowered by reinforcement learning. In Proceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran A...
work page 2023
-
[27]
Alan M. Turing. 1990. Computing Machinery and Intelligence. InThe Philosophy of Artificial Intelligence, Margaret A. Boden (Ed.). Oxford University Press, 40–66
work page 1990
-
[28]
Saizhuo Wang, Hang Yuan, Lionel M. Ni, and Jian Guo. 2024. QuantAgent: Seeking Holy Grail in Trading by Self-Improving Large Language Model.CoRR abs/2402.03755 (2024). arXiv:2402.03755 doi:10.48550/ARXIV.2402.03755
-
[29]
LLM-Core Xiaomi. 2026. MiMo-V2-Flash Technical Report. arXiv:2601.02780 [cs.CL] https://arxiv.org/abs/2601.02780
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023. PIXIU: a large language model, instruction data and evaluation benchmark for finance. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’23). Curran Associates Inc., Red Hook, NY,...
work page 2023
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[32]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview. net/forum?id=WE_vluYUL-X
work page 2023
-
[33]
Shuo Yu, Hongyan Xue, Xiang Ao, Feiyang Pan, Jia He, Dandan Tu, and Qing He
-
[34]
Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, Ambuj K. Singh, Yizhou Sun, Leman Akoglu, Dimitrios Gunopulos, Xifeng Yan, Ravi Kumar, Fatma Ozcan, and Jieping Ye (Eds.). ACM, New York, NY...
-
[35]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
-
[36]
Suchow, Denghui Zhang, and Khaldoun Khashanah
Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Jordan W. Suchow, Denghui Zhang, and Khaldoun Khashanah. 2025. FinMem: A Performance- Enhanced LLM Trading Agent With Layered Memory and Character Design. IEEE Trans. Big Data11, 6 (2025), 3443–3459. doi:10.1109/TBDATA.2025.3593370
-
[37]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bowen Xu, Ca...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.06471 2025
-
[38]
Order Sizing: Do not mention minimum 100 shares, odd lots, integers, or full position exits.2. Session Logic: Do not mention "No buying on last day" or "Forced close on last day."
-
[39]
Capital Management: Do not mention fixed capital limits or cash sufficiency checks
Conflict Resolution: Do not mention simultaneous signal priority.4. Capital Management: Do not mention fixed capital limits or cash sufficiency checks
-
[40]
Execution: Do not mention "Buy at Open / Sell at Close" unless the code *deviates* from this standard
-
[41]
Math Details: Do not explain standard return formulas, annualization, or window warmups.7. Data Handling: Do not mention NaN handling. ### 3. Language Guidelines- Humanize Time (BUT BE PRECISE): - Forbidden: "T", "T-1", "Day t". - Required: "Today," "yesterday," "the previous day," "the past 20 days."- Time Reference Precision (CRITICAL): - Never describe...
-
[42]
Scope: Exchange name, Stock name, Initial Capital, Date Range
-
[43]
Explicitly state if it uses today's or yesterday's data.3
Entry Logic: The specific condition to open a position. Explicitly state if it uses today's or yesterday's data.3. Exit Logic: The specific condition to close the position. Explicitly state if it uses today's or yesterday's data
-
[44]
Metric: The specific performance indicator to calculate.### 5. Output Format (CRITICAL) You must output a single JSON object. Do not include markdown formatting (like ``` The JSON key containing the narrative must be exactly matches the expected schema.Example Structure: {"nlp_strategy": "YOUR GENERATED TEXT HERE"}### 6. Few-Shot Examples (Strictly Follow...
work page 2020
-
[45]
Base Rules: Hard constraints of the backtesting framework (e.g., lot size, execution price, calculation standards), which are considered absolute truth and must not be questioned
-
[46]
Trading Strategy: Specific trading ideas defined by the user (e.g., signal triggering conditions, parameter settings)
-
[47]
Code Implementation: The Python script written based on the above two points. ### Your Task: Dual-Dimension Audit Please verify the following two dimensions item by item and generate a JSON audit report. #### Dimension 1: Code Fidelity Core Goal: Does the code 100% faithfully reproduce the [Base Rules] and [Trading Strategy]? Review Checklist:
-
[48]
Parameter Consistency: Do values such as `window_size`, `threshold`, and `cash` correspond exactly to the text?
-
[49]
Definition Precision: If the [Trading Strategy] is vague (e.g., writing only "moving average" without specifying "N-day", or "price" without specifying "closing price"), treat it as an implementation error (`False`). The code must not "hallucinate" undefined logic
-
[50]
No Hidden Logic: Does the code contain extra logic not mentioned in the text (e.g., secretly added stop-loss, filters)? If so, treat it as an error
-
[51]
Future Function Detection: Check if future data is used when calculating the signal for the current day (Look-ahead Bias). #### Dimension 2: Strategy Validity Core Goal: Is the [Trading Strategy] itself valid regarding quantitative principles? (Note: Do not evaluate the [Base Rules]) Review Checklist:
-
[52]
Executability: Can the signal trigger point be executed in the real market? (e.g., requiring a buy at today's highest price, which is unpredictable in real-time)
-
[53]
Logical Closed Loop: Are opening and closing conditions complete? Are there logical loopholes like "buy only, never sell" or "infinite loops"?
-
[54]
Causal Logic: Is there reverse causality? (e.g., using position results to infer buy signals). ### Few-Shot Examples (Strictly Follow Logic) #### Example 1: Mismatch in Parameters (Code False) *Strategy says "20-day MA", Code uses `rolling(30)`.* { "code_correct": false, "code_correct_reason": "Parameter mismatch: Strategy specifies a 20-day MA, but code ...
work page 2026
-
[55]
Analyze the user's strategy description carefully
-
[56]
Identify every technical indicator (e.g., moving averages, RSI, volatility) and performance metric (e.g., Sharpe Ratio, Max Drawdown)
-
[57]
Standardize & Extract the factor names using the following rules: - Full Names: Convert abbreviations to full English names (e.g., use "Rate of Change" instead of "ROC", "Moving Average" instead of "MA"). - Time Windows: Always put the time window at the beginning (e.g., "20-day", "12-day"). - Format: Use the format "[Time Period]-[Full Factor Name]" (e.g...
-
[58]
factors". ### Output Format Rules{format_instructions} ### Few-Shot Examples Example 1 Input:
Output the result as a strictly valid JSON object containing a single key "factors". ### Output Format Rules{format_instructions} ### Few-Shot Examples Example 1 Input: "We need to determine the optimal threshold value for the volume-based buy condition in the combined strategy for Yunnan Copper listed on theShenzhen Stock Exchange. Please conduct a backt...
work page 2021
-
[59]
Execute your query. 2. Convert the result into a Pandas DataFrame
-
[60]
Sort the data by `trade_date` (ascending) automatically
-
[61]
Generate a text preview.- Return Value: - If `status` is "success": It returns a text preview of the sorted data (first 5 and last 5 rows) and the total row count. - If `status` is "error": It returns the specific error message. - TOOL USAGE LIMIT: You use tools at most 25 times. ### Data Mapping: Short Codes to Database ColumnsThe user strategy contains ...
-
[62]
Column Mapping Table (Map these codes to SQL columns):| Short Code in Formula | Required Database Column | |-----------------------|--------------------------|| `OPEN` | `opening_price` | ······
-
[63]
Ignored Short Codes (NOT Columns):The following terms represent variables or functions, NOT database columns. Do NOT select them: - `CASH`, `POSITION`, `PORTFOLIO`- `DELAY`, `SMA`, `EMA`, `MAX`, `MIN`, `STD`, `MEAN`, `SQRT`, `ABS`, `CUMMAX` Example Logic: - If formula is `(CASH + POSITION * CLOSE) / DELAY(PERCENTAGE_CHANGE,1)`: - `CASH` -> Ignore. - `POSI...
-
[64]
Identify the correct table based on exchange
-
[65]
Match Company Name Smartly: Use English full names (e.g., 'Shenzhen Anche Technologies').3) Parse Formulas: Look at the "Factors & Indicators" section. Map Valid Codes -> DB Columns. Ignore Variables (CASH/POSITION)
-
[66]
Produce ONE simple SELECT query to fetch these raw columns.5) Call `executePostgresQuery` to verify
-
[67]
When verified, output ONLY the final JSON. ### Final Output ProtocolOutput ONLY a JSON object: {"sql_statement": "YOUR_VERIFIED_SQL_HERE"} Figure 12: Prompt For Retriever. BacktestBench: Benchmarking Large Language Models for Automated Quantitative Strategy Backtesting KDD’26, August 9-13,2026, Jeju, Korea Prompt for Coder # RoleYou are a quantitative tra...
work page 2026
-
[68]
OUTPUT JSON: - Extract the final answer from the successful execution. - Format the result strictly as a JSON object. - DO NOT include any code, explanations, or reasoning in the final response. # TRADING RULES & PROTOCOLS (STRICT ENFORCEMENT) ### 1. Execution Mechanism (Long-Only) - Type: Long-only (no short selling). - Alternation: Buy and Sell must str...
-
[69]
SINGLE TOOL CALL: Combine all logic (indicators, signals, backtest loop) into ONE Python block. 3. PRINT RESULTS: Your Python code MUST `print()` the final result so you can read it
-
[70]
NO CODE IN ANSWER: The final response must ONLY be the JSON
-
[71]
TOOL USAGE LIMIT: You use tools at most 25 times. Figure 13: Prompt For Coder
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.