C3-Bench: A Context-Aware Change Captioning Benchmark
Pith reviewed 2026-06-25 21:00 UTC · model grok-4.3
The pith
Change captioning models collapse outside training-style regimes, with even GPT-5.2 showing systematic domain- and position-dependent errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
C3-Bench establishes that the prevailing change captioning paradigm contains a fundamental blind spot: once change contexts depart from training-style regimes, conventional models collapse and state-of-the-art LMMs such as GPT-5.2 produce systematic domain- and position-dependent errors that prevent reliable change understanding across diverse real-world scenarios.
What carries the argument
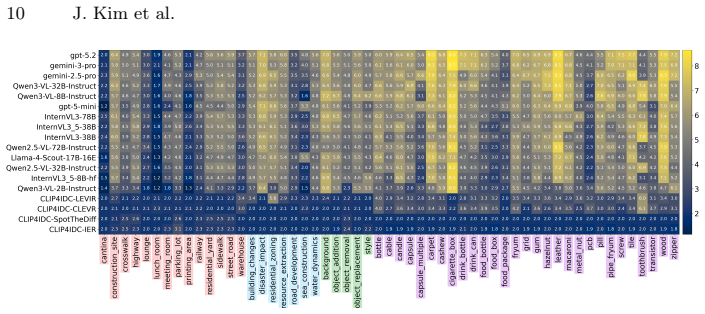
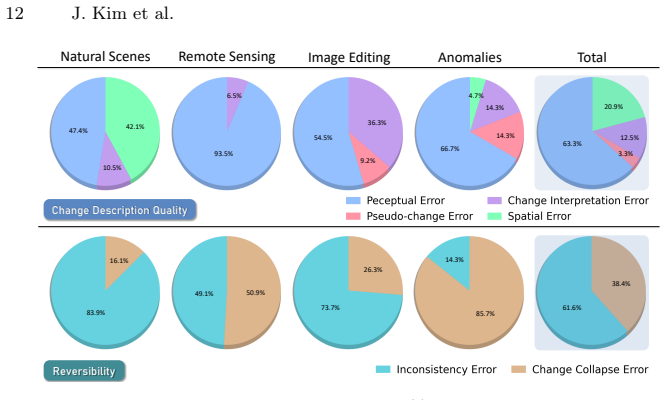
C3-Bench benchmark of 4,996 human-labeled image pairs across four domains together with an LLM-as-Judge framework that adds fine-grained scoring and a reversibility metric for symmetric consistency.
If this is right
- Conventional change captioning models fail completely when contexts differ from their training distributions.
- Even the strongest LMMs exhibit domain-specific and position-specific error patterns that distort change descriptions.
- Reversibility testing reveals whether models understand changes with symmetric consistency.
- Public datasets and code enable targeted development of models that handle diverse real-world change contexts.
- The benchmark delineates the requirements for building generalizable and trustworthy change captioning systems.
Where Pith is reading between the lines
- Future training regimes will need explicit coverage of the four domains and 51 contexts to close the observed gaps.
- Reversibility could become a standard diagnostic for any captioning system that claims to track changes.
- Domain-specific fine-tuning on the benchmark's failure cases may yield faster gains than scaling alone.
- The same evaluation structure could be applied to related tasks such as video change detection or scene graph updating.
Load-bearing premise
The 4,996 human-labeled image pairs and their change contexts were collected and annotated without systematic selection bias or labeling inconsistencies that would distort the observed model failures.
What would settle it
A model achieving consistently high scores on all four domains and all 51 contexts in C3-Bench without retraining or domain adaptation would falsify the claim of a fundamental blind spot.
Figures




read the original abstract
While Change Captioning systems have garnered substantial attention to respond to our evolving world, their true performance on diverse real-world change contexts remains largely unexplored due to the lack of comprehensive evaluation frameworks. To fill this gap, we propose C3-Bench, a comprehensive benchmark for evaluating Context-aware Change Captioning. C3-Bench features: (1) 4,996 human-labeled image pairs of 51 real-world change contexts across four domains (e.g., natural scenes, remote sensing imagery, image editing, and anomalies), each with diverse, carefully curated scenarios derived from multiple change-centric communities; and (2) the first LLM-as-Judge evaluation framework in the change captioning task that measure fine-grained dimensions (e.g., correctness, specificity, fluency, and relevance), along with a novel reversibility metric exploring whether models understand changes with symmetric consistency. Based on C3-Bench, we benchmark 32 models -- including conventional change captioning models, proprietary Large Multimodal Models (LMMs), and 2B-90B open-source LMMs. We reveal a fundamental blind spot in the prevailing change captioning paradigm: Once the change context departs from training-style regimes, conventional models collapse, and even state-of-the-art LMMs such as GPT-5.2 exhibit systematic domain- and position-dependent errors that distort reliable change understanding. By making these hidden failure modes explicit and measurable, we delineate the next frontier for building generalizable and trustworthy change captioning systems. All codes and datasets are publicly available on the project page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces C3-Bench, a benchmark with 4,996 human-labeled image pairs across 51 real-world change contexts in four domains (natural scenes, remote sensing, image editing, anomalies), derived from multiple communities. It also presents the first LLM-as-Judge framework for change captioning that evaluates fine-grained dimensions (correctness, specificity, fluency, relevance) plus a novel reversibility metric. The work benchmarks 32 models (conventional change captioning models, proprietary LMMs, and open-source 2B-90B LMMs) and concludes that conventional models collapse outside training-style regimes while even SOTA LMMs such as GPT-5.2 show systematic domain- and position-dependent errors.
Significance. If the human annotations prove reliable, the benchmark supplies a much-needed evaluation resource that exposes previously unmeasured failure modes in change captioning systems and supplies concrete metrics (including reversibility) for future work. The public release of code and data is a clear strength supporting reproducibility. The empirical findings could usefully shift research priorities toward more robust, context-aware models, though their weight rests entirely on the fidelity of the 4,996 labeled pairs and 51 contexts.
major comments (2)
- [Abstract] Abstract: the central claim that 'conventional models collapse' and 'even state-of-the-art LMMs such as GPT-5.2 exhibit systematic domain- and position-dependent errors' rests on the 4,996 human-labeled pairs and 51 contexts being free of selection bias or labeling artifacts. No inter-annotator agreement statistics, adjudication protocol, sampling procedure for the contexts, or curation criteria are supplied, leaving open the possibility that observed error patterns are partly produced by the benchmark construction itself.
- [Abstract] Abstract: the description of the dataset as 'carefully curated' from 'multiple change-centric communities' is presented without any quantitative or procedural evidence of curation quality. Because the paper's headline finding is that models fail systematically once contexts depart from training regimes, the absence of these details is load-bearing for the reliability of the reported model rankings and error analyses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for transparency in benchmark construction. We agree these details are critical to support the central claims and will revise the abstract and main text accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'conventional models collapse' and 'even state-of-the-art LMMs such as GPT-5.2 exhibit systematic domain- and position-dependent errors' rests on the 4,996 human-labeled pairs and 51 contexts being free of selection bias or labeling artifacts. No inter-annotator agreement statistics, adjudication protocol, sampling procedure for the contexts, or curation criteria are supplied, leaving open the possibility that observed error patterns are partly produced by the benchmark construction itself.
Authors: We acknowledge that the abstract omits these statistics and protocols. The full manuscript (Section 3) describes the multi-source collection from established change-centric datasets and communities, with human labeling performed by trained annotators following explicit guidelines. However, to directly address the concern, we will add to the abstract a summary of inter-annotator agreement (Fleiss' kappa), the adjudication process for disagreements, the stratified sampling across domains, and explicit curation criteria. These additions will be supported by new tables in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the description of the dataset as 'carefully curated' from 'multiple change-centric communities' is presented without any quantitative or procedural evidence of curation quality. Because the paper's headline finding is that models fail systematically once contexts depart from training regimes, the absence of these details is load-bearing for the reliability of the reported model rankings and error analyses.
Authors: We agree that quantitative evidence of curation quality should be foregrounded given the headline claims. While the methods section details the provenance from four distinct communities and the scenario selection process, the abstract does not. In revision we will insert concise quantitative indicators (e.g., domain balance statistics, context diversity metrics, and agreement scores) into the abstract and expand the main text with a dedicated curation-quality subsection. This will strengthen the evidential basis for the reported model behaviors. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements only
full rationale
The paper introduces C3-Bench as a new dataset of 4,996 human-labeled image pairs across 51 contexts and evaluates 32 models on it, reporting observed performance patterns. No equations, fitted parameters, predictions derived from prior fits, or self-citation chains appear in the provided text. Central claims rest on direct empirical results from the benchmark rather than any reduction to inputs by construction. This is the expected non-finding for a benchmark release paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kim et al
Achiam, O.J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., ing Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., laine Boyd, M., Brakman, A.L., Brockm...
2023
-
[2]
Autonomous Robots42, 1301 – 1322 (2016)
Alcantarilla, P.F., Stent, S., Ros, G., Arroyo, R., Gherardi, R.: Street-view change detection with deconvolutional networks. Autonomous Robots42, 1301 – 1322 (2016)
2016
-
[3]
Anderson, P., Fernando, B., Johnson, M., Gould, S.: Spice: Semantic propositional image caption evaluation. ArXivabs/1607.08822(2016)
Pith/arXiv arXiv 2016
-
[4]
Anonymous: Imagine how to change: Explicit procedure modeling for change cap- tioning.In:TheFourteenthInternationalConferenceonLearningRepresentations (2026)
2026
-
[5]
Anthropic: Claude developer platform (nd),https://claude.com/platform/api, accessed: 2026-01-22
2026
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L.Y., Ren, X., yi Ren, X., Song, S., Sun, Y.C.,...
2025
-
[7]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. ArXivabs/2502.13923(2025)
Pith/arXiv arXiv 2025
-
[8]
1539–1550 (2024)
Baldassini, F.B., Shukor, M., Cord, M., Soulier, L., Piwowarski, B.: What makes multimodal in-context learning work? 2024 IEEE/CVF Conference on Computer C3-Bench: A Context-Aware Change Captioning Benchmark 17 Vision and Pattern Recognition Workshops (CVPRW) pp. 1539–1550 (2024)
2024
-
[9]
In: IEEvaluation@ACL (2005)
Banerjee, S., Lavie, A.: Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In: IEEvaluation@ACL (2005)
2005
-
[10]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad — a compre- hensive real-world dataset for unsupervised anomaly detection. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 9584–9592 (2019)
2019
-
[11]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Berton, G.M., Masone, C., Caputo, B.: Rethinking visual geo-localization for large-scale applications. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 4868–4878 (2022)
2022
-
[12]
Black,A.,Shi,J.,Fai,Y.,Bui,T.,Collomosse,J.P.:Vixen:Visualtextcomparison network for image difference captioningabs/2402.19119(2024)
arXiv 2024
-
[13]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow im- age editing instructions. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 18392–18402 (2022)
2023
-
[14]
Chakraborty, S., Ghosal, S.S., Yin, M., Manocha, D., Wang, M., Bedi, A.S., Huang, F.: Transfer q star: Principled decoding for llm alignment (2024)
2024
-
[15]
IEEE Transactions on Image Processing32, 6047– 6060 (2023)
Chang, S., Ghamisi, P.: Changes to captions: An attentive network for remote sensing change captioning. IEEE Transactions on Image Processing32, 6047– 6060 (2023)
2023
-
[16]
In: International Conference on Machine Learning (2024)
Chen, D., Chen, R., Zhang, S., Liu, Y., Wang, Y., Zhou, H., Zhang, Q., Zhou, P., Wan, Y., Sun, L.: Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In: International Conference on Machine Learning (2024)
2024
-
[17]
2024 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp
Chen, G., Shen, L., Shao, R., Deng, X., Nie, L.: Lion : Empowering multimodal large language model with dual-level visual knowledge. 2024 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp. 26530–26540 (2023)
2024
-
[18]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Chen, J., Xu, D., Fei, J., Feng, C.M., Elhoseiny, M.: Document haystacks: Vision- language reasoning over piles of 1000+ documents. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 24817–24826 (2024)
2025
-
[19]
IEEE Transactions on Geoscience and Remote Sensing61, 1–16 (2023)
Chen, K.J., Li, W., Lei, S., Chen, J., Jiang, X., Zou, Z., Shi, Z.X.: Continuous remote sensing image super-resolution based on context interaction in implicit function space. IEEE Transactions on Geoscience and Remote Sensing61, 1–16 (2023)
2023
-
[20]
IEEE Geoscience and Remote Sensing Letters20, 1–5 (2023)
Chen, K., Li, W., Chen, J., Zou, Z., Shi, Z.X.: Resolution-agnostic remote sensing scene classification with implicit neural representations. IEEE Geoscience and Remote Sensing Letters20, 1–5 (2023)
2023
-
[21]
IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium pp
Chen, K., Liu, C., Li, W., Liu, Z., Chen, H., Zhang, H., Zou, Z., Shi, Z.X.: Time travelling pixels: Bitemporal features integration with foundation model for re- mote sensing image change detection. IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium pp. 8581–8584 (2023)
2024
-
[22]
Chen, L., Li, J., wen Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., Zhao, F.: Are we on the right way for evaluating large vision-language models? ArXivabs/2403.20330(2024)
Pith/arXiv arXiv 2024
-
[23]
2021 IEEE Intelligent Vehicles Symposium (IV) pp
Chen, S., Yang, K., Stiefelhagen, R.: Dr-tanet: Dynamic receptive temporal at- tention network for street scene change detection. 2021 IEEE Intelligent Vehicles Symposium (IV) pp. 502–509 (2021)
2021
-
[24]
Du,P.,Liu,P.,Xia,J.,Feng,L.,Liu,S.,Tan,K.,Cheng,L.:Remotesensingimage interpretation for urban environment analysis: Methods, system and examples. Remote. Sens.6, 9458–9474 (2014) 18 J. Kim et al
2014
-
[25]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A.S., Yang, A., Mi- tra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Ro- driguez, A., Gregerson, A., Spataru, A., Rozière, B., Biron, B., Tang, B., Chern, B., Caucheteux, C., Nayak, C., Bi, C.,...
2024
-
[26]
Dubois, Y., Li, X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P., Hashimoto, T.: Alpacafarm: A simulation framework for methods that learn from human feedback. ArXivabs/2305.14387(2023)
arXiv 2023
-
[27]
In: North American Chapter of the Association for Computational Linguistics (2023)
Fu, J., Ng, S.K., Jiang, Z., Liu, P.: Gptscore: Evaluate as you desire. In: North American Chapter of the Association for Computational Linguistics (2023)
2023
-
[28]
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not perceive. ArXivabs/2404.12390(2024)
Pith/arXiv arXiv 2024
-
[29]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Galappaththige, C.J., Lai, J., Windrim, L., Dansereau, D.G., Suenderhauf, N., Miller, D.: Multi-view pose-agnostic change localization with zero labels. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 11600–11610 (2025)
2025
-
[30]
Gao, B.B.: Metauas: Universal anomaly segmentation with one-prompt meta- learning. ArXivabs/2505.09265(2025)
arXiv 2025
-
[31]
Google: Google AI Studio Documentation.https://aistudio.google.com/ (2025), accessed: 2025-12-12
2025
-
[32]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, Y., Guo, J.: A survey on llm-as-a-judge. ArXivabs/2411.15594 20 J. Kim et al. (2024)
Pith/arXiv arXiv 2024
-
[33]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Guo, Q., Mello, S.D., Yin, H., Byeon, W., Cheung, K.C., Yu, Y., Luo, P., Liu, S.: Regiongpt: Towards region understanding vision language model. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 13796–13806 (2024)
2024
-
[34]
Guo,Z.,Wang,T.,Laaksonen,J.T.:Clip4idc:Clipforimagedifferencecaptioning. ArXivabs/2206.00629(2022)
arXiv 2022
-
[35]
Gupta, R., Goodman, B., Patel, N.N., Hosfelt, R., Sajeev, S., Heim, E.T., Doshi, J., Lucas, K., Choset, H., Gaston, M.E.: xbd: A dataset for assessing building damage from satellite imagery. ArXivabs/1911.09296(2019)
arXiv 1911
-
[36]
In: International Conference on Computa- tional Linguistics (2012)
Han, L., Wong, D.F., Chao, L.S.: Lepor: A robust evaluation metric for machine translation with augmented factors. In: International Conference on Computa- tional Linguistics (2012)
2012
-
[37]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. ArXivabs/2104.08718(2021)
Pith/arXiv arXiv 2021
-
[38]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) pp
Hosseinzadeh, M., Wang, Y.: Image change captioning by learning from an auxil- iary task. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) pp. 2724–2733 (2021)
2021
-
[39]
Hu, E., Guo, L., Yue, T., Zhao, Z., Xue, S., Liu, J.: Onediff: A generalist model for image difference captioning. ArXivabs/2407.05645(2024)
arXiv 2024
-
[40]
IEEE Transactions on Image Processing34, 3294–3308 (2025)
Hu, J., Zhong, G., Yuan, J., Pan, W., Wang, X.: Mct-ccdiff: Context-aware con- trastivediffusionmodelwithmediator-bridgingcross-modaltransformerforimage change captioning. IEEE Transactions on Image Processing34, 3294–3308 (2025)
2025
-
[41]
Hu, X., Gao, M., Hu, S., Zhang, Y., Chen, Y., Xu, T., Wan, X.: Are llm-based evaluators confusing nlg quality criteria? ArXivabs/2402.12055(2024)
arXiv 2024
-
[42]
IEEE Transactions on Multimedia24, 2004–2017 (2022)
Huang, Q., Liang, Y., Wei, J., Yi, C., Liang, H., fung Leung, H., Li, Q.: Image difference captioning with instance-level fine-grained feature representation. IEEE Transactions on Multimedia24, 2004–2017 (2022)
2004
-
[43]
Hui, M., Yang, S., Zhao, B., Shi, Y., Wang, H., Wang, P., Zhou, Y., Xie, C.: Hq-edit: A high-quality dataset for instruction-based image editing. ArXiv abs/2404.09990(2024)
arXiv 2024
-
[44]
2025 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Jeong, C., Bae, I., Park, J.H., Jeon, H.G.: Test-time prompt tuning for zero-shot depth completion. 2025 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 9443–9454 (2025)
2025
-
[45]
Jhamtani,H.,Berg-Kirkpatrick,T.:Learningtodescribedifferencesbetweenpairs of similar images. ArXivabs/1808.10584(2018)
Pith/arXiv arXiv 2018
-
[46]
2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
Johnson, J., Hariharan, B., van der Maaten, L., Fei-Fei, L., Zitnick, C.L., Gir- shick, R.B.: Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 1988–1997 (2016)
2017
-
[47]
2075–2084 (2021)
Kim, H., Kim, J., Lee, H., a Park, H., Kim, G.: Viewpoint-agnostic change cap- tioningwithcycleconsistency.2021IEEE/CVFInternationalConferenceonCom- puter Vision (ICCV) pp. 2075–2084 (2021)
2075
-
[48]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Kim, J., Kim, U.: Towards generalizable scene change detection. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[49]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp
Li, D., Chen, L., Xu, C., Kong, H.: Umad: University of macau anomaly detec- tion benchmark dataset. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 5836–5843 (2024)
2024
-
[50]
In: AAAI Conference on Artificial Intelligence (2025) C3-Bench: A Context-Aware Change Captioning Benchmark 21
Li, R., Li, L., Zhang, J., Zhao, Q., Wang, H., Yan, C.: Region-aware difference distilling with attribute-guided contrastive regularization for change captioning. In: AAAI Conference on Artificial Intelligence (2025) C3-Bench: A Context-Aware Change Captioning Benchmark 21
2025
-
[51]
In: Annual Meeting of the Association for Computational Linguistics (2004)
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Annual Meeting of the Association for Computational Linguistics (2004)
2004
-
[52]
IEEE Transactions on Geoscience and Remote Sensing60, 1–20 (2022)
Liu, C., Zhao, R., Chen, H., Zou, Z., Shi, Z.X.: Remote sensing image change cap- tioning with dual-branch transformers: A new method and a large scale dataset. IEEE Transactions on Geoscience and Remote Sensing60, 1–20 (2022)
2022
-
[53]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. ArXiv abs/2304.08485(2023)
Pith/arXiv arXiv 2023
-
[54]
In: Conference on Empirical Methods in Natural Language Processing (2024)
Liu, M., Xu, Z., Lin, Z., Ashby, T., Rimchala, J., Zhang, J., Huang, L.: Holistic evaluation for interleaved text-and-image generation. In: Conference on Empirical Methods in Natural Language Processing (2024)
2024
-
[55]
In: Conference on Empirical Methods in Natural Language Processing (2023)
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-eval: Nlg evaluation using gpt-4 with better human alignment. In: Conference on Empirical Methods in Natural Language Processing (2023)
2023
-
[56]
In: AAAI Conference on Artificial Intelligence (2025)
Lv, F., Wang, R., Jing, L.: Revisiting change captioning from self-supervised global-part alignment. In: AAAI Conference on Artificial Intelligence (2025)
2025
-
[57]
OpenAI: OpenAI Platform Documentation.https://platform.openai.com/ docs/overview(2025), accessed: 2025-12-12
2025
-
[58]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.Q., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y.B., Li, S.W., Misra, I., Rabbat, M.G., Sharma, V., Synnaeve, G., Xu, H., Jégou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual ...
Pith/arXiv arXiv 2023
-
[59]
In: Annual Meeting of the Association for Com- putational Linguistics (2002)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Annual Meeting of the Association for Com- putational Linguistics (2002)
2002
-
[60]
2019 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Park, D.H., Darrell, T., Rohrbach, A.: Robust change captioning. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 4623–4632 (2019)
2019
-
[61]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Park, J.M., Kim, U.H., Lee, S., Kim, J.H.: Dual task learning by leveraging both dense correspondence and mis-correspondence for robust change detection with imperfect matches. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 13739–13749 (2022)
2022
-
[62]
Park, K.R., Park, J., Kim, S.T., Lee, H.J., Kim, J.U.: Leveraging textual compo- sitional reasoning for robust change captioning. ArXivabs/2511.22903(2025)
arXiv 2025
-
[63]
In: WMT@EMNLP (2015)
Popovic, M.: chrf: character n-gram f-score for automatic mt evaluation. In: WMT@EMNLP (2015)
2015
-
[64]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Qiu, Y., Yamamoto, S., Nakashima, K., Suzuki, R., Iwata, K., Kataoka, H., Satoh, Y.: Describing and localizing multiple changes with transformers. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 1951–1960 (2021)
2021
-
[65]
2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) pp
Ryu, S., Kim, K., Baek, E., Shin, D., Lee, J.: Towards scalable human-aligned benchmark for text-guided image editing. 2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) pp. 18292–18301 (2025)
2025
-
[66]
ACM Computing Surveys (CSUR)55, 1 – 39 (2020)
Sai, A.B., Mohankumar, A.K., Khapra, M.M.: A survey of evaluation metrics used for nlg systems. ACM Computing Surveys (CSUR)55, 1 – 39 (2020)
2020
-
[67]
2020 IEEE International Conference on Robotics and Automation (ICRA) pp
Sakurada, K., Shibuya, M., Wang, W.: Weakly supervised silhouette-based se- mantic scene change detection. 2020 IEEE International Conference on Robotics and Automation (ICRA) pp. 6861–6867 (2018) 22 J. Kim et al
2020
-
[68]
Sakurada, K., Wang, W., Kawaguchi, N., Nakamura, R.: Dense optical flow based change detection network robust to difference of camera viewpoints. ArXiv abs/1712.02941(2017)
Pith/arXiv arXiv 2017
-
[69]
In: Annual Meeting of the Association for Computational Linguistics (2020)
Sellam, T., Das, D., Parikh, A.P.: Bleurt: Learning robust metrics for text genera- tion. In: Annual Meeting of the Association for Computational Linguistics (2020)
2020
-
[70]
Shafique,A.,Cao,G.,Khan,Z.,Asad,M.,Aslam,M.:Deeplearning-basedchange detection in remote sensing images: A review. Remote. Sens.14, 871 (2022)
2022
-
[71]
IEEE Transactions on Geoscience and Remote Sensing60, 1–16 (2021)
Shi,Q.,Liu,M.,Li,S.,Liu,X.,Wang,F.,Zhang,L.:Adeeplysupervisedattention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Transactions on Geoscience and Remote Sensing60, 1–16 (2021)
2021
-
[72]
Shi, X., Yang, X., Gu, J., Joty, S.R., Cai, J.: Finding it at another side: A viewpoint-adapted matching encoder for change captioning. ArXiv abs/2009.14352(2020)
arXiv 2009
-
[73]
In: Conference of the Association for Machine Translation in the Americas (2006)
Snover, M.G., Dorr, B.J., Schwartz, R.M., Micciulla, L., Makhoul, J.: A study of translation edit rate with targeted human annotation. In: Conference of the Association for Machine Translation in the Americas (2006)
2006
-
[74]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Sun, Y., Qiu, Y., Khan, M., Matsuzawa, F., Iwata, K.: The stvchrono dataset: Towards continuous change recognition in time. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 14111–14120 (2024)
2024
-
[75]
In: Annual Meeting of the Association for Computational Linguistics (2019)
Tan, H., Dernoncourt, F., Lin, Z.L., Bui, T., Bansal, M.: Expressing visual rela- tionships via language. In: Annual Meeting of the Association for Computational Linguistics (2019)
2019
-
[76]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Tian, X., Zou, S., Yang, Z., Zhang, J.: Identifying and mitigating position bias of multi-image vision-language models. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 10599–10609 (2025)
2025
-
[77]
IEEE Transactions on Image Processing32, 2620–2635 (2023)
Tu, Y., Li, L., Su, L., Du, J., Lu, K., Huang, Q.: Viewpoint-adaptive representa- tion disentanglement network for change captioning. IEEE Transactions on Image Processing32, 2620–2635 (2023)
2023
-
[78]
IEEE Transactions on Multimedia25, 9518–9529 (2023)
Tu, Y., Li, L., Su, L., Lu, K., Huang, Q.: Neighborhood contrastive transformer for change captioning. IEEE Transactions on Multimedia25, 9518–9529 (2023)
2023
-
[79]
In: European Conference on Computer Vision (2024)
Tu, Y., Li, L., Su, L., Yan, C., Huang, Q.: Distractors-immune representation learning with cross-modal contrastive regularization for change captioning. In: European Conference on Computer Vision (2024)
2024
-
[80]
2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) pp
Tu, Y., Li, L., Su, L., Zha, Z.J., Yan, C.C., Huang, Q.: Self-supervised cross-view representation reconstruction for change captioning. 2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) pp. 2793–2803 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.