MO-CAPO: Multi-Objective Cost-Aware Prompt Optimization
Pith reviewed 2026-05-20 21:06 UTC · model grok-4.3
The pith
MO-CAPO finds LLM prompts that trade off performance against inference cost more efficiently than standard multi-objective search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
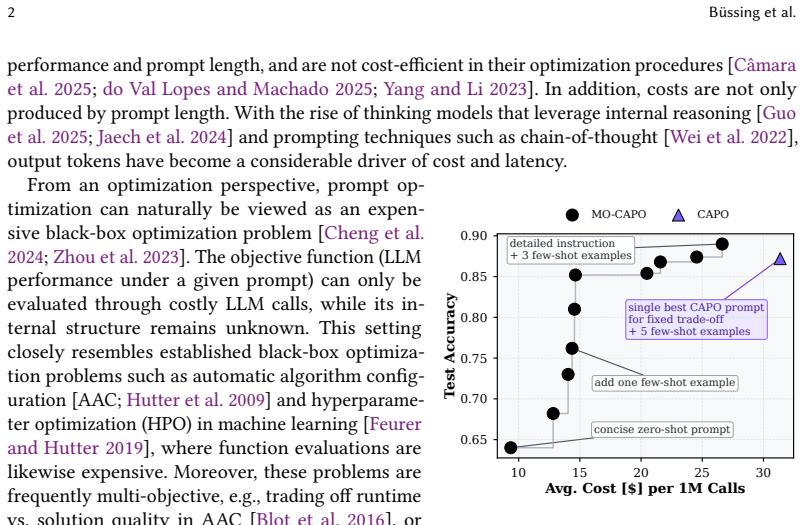
MO-CAPO is a multi-objective prompt optimization algorithm that jointly optimizes task performance and a deployment-oriented inference cost objective while applying budget allocation to search efficiently. It produces Pareto front approximations that are strong, robust, and diverse across four tasks and three LLMs. The method outperforms an NSGA-II baseline on the noisy R2 metric in eight of twelve cases and reaches competitive performance levels at considerably lower budgets. The resulting sets include trade-offs that single-objective optimizers miss, yet their highest-performance members stay competitive with those single-objective results.
What carries the argument
MO-CAPO algorithm, which integrates multi-objective evolutionary search with a deployment-oriented cost objective that captures the full computational profile of LLM inference and a budget allocation strategy to direct evaluations.
If this is right
- Users obtain multiple prompt candidates that cover a range of performance-cost trade-offs.
- Competitive performance is reachable with lower total evaluation budgets than standard multi-objective methods require.
- Single-objective prompt optimizers are shown to overlook useful lower-cost alternatives.
- Noisy R2 and approximation gap metrics enable a more realistic comparison of solution quality under noise.
Where Pith is reading between the lines
- Cost considerations could be folded into prompt engineering from the beginning rather than treated as a later filter.
- The same cost-aware structure might extend naturally to other objectives such as latency or energy use.
- Practitioners in resource-limited settings could use the discovered trade-off sets to match model deployment constraints directly.
Load-bearing premise
The deployment-oriented cost objective and budget allocation strategy are assumed to produce reliable cost estimates and to locate high-quality solutions without missing better ones that a more exhaustive search would find.
What would settle it
Run MO-CAPO and the NSGA-II baseline on the same tasks with a much larger shared evaluation budget and check whether the final Pareto fronts differ in dominance or hypervolume.
Figures






read the original abstract
Large language models (LLMs) achieve strong performance across a wide range of tasks but are highly sensitive to prompt design, motivating the need for automatic prompt optimization. Existing methods predominantly focus on performance alone, ignoring competing objectives such as inference cost or latency. At the same time, existing work on multi-objective prompt optimization relies on off-the-shelf NSGA-II, ignoring optimization efficiency. As a remedy, we introduce MO-CAPO, a novel multi-objective prompt optimization algorithm that jointly optimizes performance and inference cost while leveraging budget allocation for cost-efficient optimization. We further propose a deployment-oriented cost objective that captures the full computational profile of LLM inference. We evaluate our approach across four tasks and three LLMs and compare it to an NSGA-II-based multi-objective method and state-of-the-art single-objective prompt optimizers. Results show that MO-CAPO consistently identifies strong, robust, and diverse Pareto front approximations while maintaining cost-efficiency. It outperforms the NSGA-II baseline on 8 out of 12 cases in terms of the noisy R2 metric and achieves competitive performances often already at a considerably lower budget. The discovered solution sets span diverse performance-cost trade-offs that are omitted by single-objective optimizers, yet the top-performance candidates remain competitive with single-objective solutions. Additionally, we conduct the first evaluation of multi-objective machine learning experiments that considers generalization and robustness through noisy R2 and approximation gap, enabling a more realistic assessment of solution quality. MO-CAPO enables practitioners to select from an efficiently discovered set of multiple prompts offering different trade-offs between performance and cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MO-CAPO, a multi-objective prompt optimization algorithm that jointly optimizes LLM task performance and a deployment-oriented inference cost objective via budget allocation. It evaluates the method on four tasks and three LLMs against an NSGA-II baseline and single-objective prompt optimizers, claiming stronger, more diverse Pareto fronts with competitive performance at substantially lower budgets, supported by new robustness metrics (noisy R2 and approximation gap).
Significance. If the empirical claims hold after addressing protocol details, the work offers a practical advance in prompt optimization by explicitly trading off performance against cost and by introducing evaluation metrics that assess generalization and robustness of multi-objective solutions. The budget-aware search and deployment-oriented cost model address real deployment constraints that single-objective methods ignore.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The central performance claims rest on MO-CAPO outperforming NSGA-II on 8/12 cases in noisy R2 and achieving competitive results at lower budget, yet the manuscript provides no information on the number of independent runs, statistical significance tests, variance across seeds, or whether data splits were pre-specified before optimization. Without these, the reported superiority cannot be distinguished from experimental variability.
- [§3.2] §3.2 (Budget Allocation Mechanism): The cost-efficiency and non-inferior quality claims depend on the budget allocation rule correctly retaining promising candidates using early, noisy estimates of the deployment-oriented cost objective. No ablation study or analysis is presented showing that this early pruning does not discard prompts whose final noisy R2 or approximation-gap values would have placed them on the Pareto front after fuller evaluation.
minor comments (2)
- [§3.1] The definition of the deployment-oriented cost objective should be stated explicitly with its formula rather than described only in prose.
- [Figures 2-4] Figure captions for Pareto-front plots should include the exact budget values used for each method to allow direct visual comparison of cost-efficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor and validation that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The central performance claims rest on MO-CAPO outperforming NSGA-II on 8/12 cases in noisy R2 and achieving competitive results at lower budget, yet the manuscript provides no information on the number of independent runs, statistical significance tests, variance across seeds, or whether data splits were pre-specified before optimization. Without these, the reported superiority cannot be distinguished from experimental variability.
Authors: We agree that the experimental protocol requires more explicit documentation to support the performance claims. While the experiments used multiple random seeds and fixed data splits, these details were insufficiently described. In the revised manuscript we will expand §4 with a new subsection on the experimental protocol, specifying that all results are averaged over 5 independent runs with different seeds, that mean and standard deviation are reported for every metric, that train/validation/test splits were pre-specified and held constant across all methods and runs, and that paired statistical tests (Wilcoxon signed-rank) are applied to the noisy R2 differences. These additions will appear in both §4 and the corresponding result tables in §5. revision: yes
-
Referee: [§3.2] §3.2 (Budget Allocation Mechanism): The cost-efficiency and non-inferior quality claims depend on the budget allocation rule correctly retaining promising candidates using early, noisy estimates of the deployment-oriented cost objective. No ablation study or analysis is presented showing that this early pruning does not discard prompts whose final noisy R2 or approximation-gap values would have placed them on the Pareto front after fuller evaluation.
Authors: We recognize that an explicit validation of the early-pruning rule would strengthen the cost-efficiency claims. The original submission did not contain such an ablation. In the revised version we will add a targeted analysis (new paragraph in §5 and an accompanying figure) that compares the final Pareto fronts obtained with the budget allocation mechanism against an oracle version that evaluates every candidate to completion. The analysis will report (i) the fraction of candidates pruned early, (ii) the final noisy R2 and approximation-gap values of the pruned candidates, and (iii) the resulting difference in hypervolume and diversity metrics, thereby demonstrating that the early estimates do not systematically eliminate high-quality solutions. revision: yes
Circularity Check
No significant circularity: algorithm and claims are self-contained against external baselines
full rationale
The paper introduces MO-CAPO as an extension of standard NSGA-II with added budget allocation and a deployment-oriented cost objective, then reports empirical results on four tasks and three LLMs against the NSGA-II baseline and single-objective methods. No equations, predictions, or central claims reduce by construction to fitted parameters, self-referential normalizations, or load-bearing self-citations. All performance assertions (e.g., outperforming on 8/12 noisy R2 cases at lower budget) rest on direct experimental comparisons whose validity is independent of the method's internal definitions. The derivation chain therefore remains non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce MO-CAPO, a novel multi-objective prompt optimization algorithm that jointly optimizes performance and inference cost while leveraging budget allocation for cost-efficient optimization. We further propose a deployment-oriented cost objective that captures the full computational profile of LLM inference.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Heuristic-based Search Algorithm in Automatic Instruction-focused Prompt Optimization: A Survey. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 22093–22111. Sara Câmara, Eduardo Luz, Valéri...
-
[2]
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, 9340–9366. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainw...
work page 2024
-
[3]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models.arXiv:2302.13971 [cs.CL](2023). Xingchen Wan, Ruoxi Sun, Hootan Nakhost, and Sercan Arik. 2024. Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization. InProceedings of the 37th International Conference on Advances in Neural Information Processing Systems (NeurIPS’2...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.