PureMagic: A Dynamic Scheduler for Lattice Surgery
Pith reviewed 2026-05-21 17:06 UTC · model grok-4.3
The pith
PureMagic repurposes ancilla patches to dynamically schedule both routing and stochastic magic state cultivation, eliminating dedicated buses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
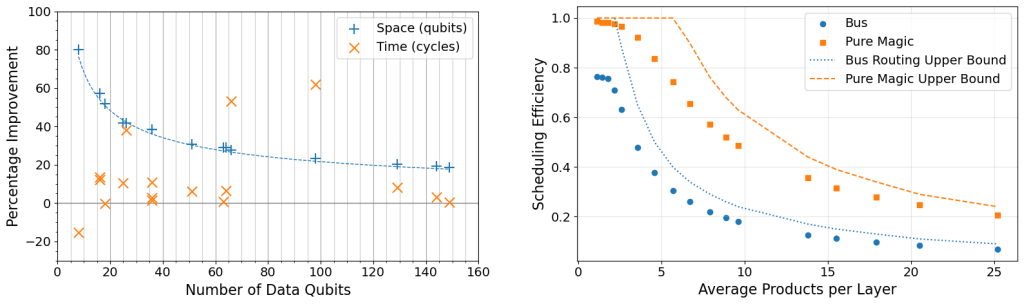
PureMagic eliminates dedicated bus patches by repurposing all ancilla patches for both routing and cultivation. When routing is required, cultivation is interrupted and resumed afterward, naturally cutting off long tails of stochastic times so no ancilla ever sits idle. A weight limit on Tableau transpilation is added to trade gate count for greater parallelism that the dynamic scheduler can exploit. On 29 benchmark circuits PureMagic delivers 40% to 150% efficiency gains over bus routing, uses 19% to 80% fewer logical qubits, reduces average magic-state preparation time by 4.5x, and reaches up to 15x higher efficiency than the static scheduler DASCOT once preparation costs are counted. The
What carries the argument
The dynamic interruption-and-restart rule that lets stochastic cultivation run on the same ancilla patches used for routing, automatically truncating long preparation tails while guaranteeing zero idle ancilla.
If this is right
- Logical qubit overhead for magic-state preparation drops because no patches are reserved solely for buses or factories.
- Average time to obtain a usable magic state falls because long stochastic tails are cut off by routing interruptions.
- Overall circuit volume improves when magic-state preparation cost is included in the accounting.
- Scheduled volumes lie between the conservative and optimistic FLASQ lower bounds, indicating near-optimal ancilla utilization.
Where Pith is reading between the lines
- The same interrupt-and-restart idea could be applied to other stochastic subroutines that share patches with routing.
- Hardware designs might reduce the area allocated to specialized magic-state factories if dynamic sharing proves reliable.
- Running the same benchmarks on hardware with realistic error models would test whether the 29 circuits capture typical workloads.
- Combining the weight-limited transpilation with other parallelism techniques could yield further gains in dynamic settings.
Load-bearing premise
Pausing and restarting stochastic cultivation on an ancilla patch adds negligible extra error or latency beyond the natural cutoff of long tails.
What would settle it
A measured increase in logical error rate or added latency when cultivation is interrupted and resumed on the same physical patch would falsify the negligible-overhead claim.
Figures











read the original abstract
Fault-tolerant quantum computation on surface codes requires magic states for universal computation. Traditional distillation factories deliver magic states deterministically but consume large areas of logical qubits, forcing static, peripheral placement. Magic state cultivation reduces magic state preparation to a single logical qubit, but is inherently stochastic, making static scheduling infeasible. We introduce PureMagic, a dynamic scheduler that eliminates dedicated bus patches by repurposing all ancilla patches for both routing and cultivation. When a patch is needed for routing, cultivation is interrupted and restarted afterward, naturally cutting off the long tail of cultivation times and ensuring no ancilla is ever idle. We also introduce a weight limit on Tableau transpilation that trades gate count for parallelism, which PureMagic is particularly well-suited to exploit. Across 29 benchmark circuits, PureMagic achieves 40% to 150% efficiency improvement over bus routing, uses 19% to 80% fewer logical qubits, and reduces average magic state preparation time by 4.5x. Compared to DASCOT, a state-of-the-art static scheduler, PureMagic is up to 15x more efficient when magic state preparation costs are included. PureMagic's scheduled volumes fall between the conservative and optimistic FLASQ theoretical lower bounds, demonstrating near-optimal use of ancilla resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PureMagic, a dynamic scheduler for lattice surgery in surface-code quantum computing. It allows repurposing ancilla patches for both routing and stochastic magic state cultivation, interrupting cultivation when routing is needed and restarting it later to naturally truncate long tails. The approach includes a weight limit on Tableau transpilation for better parallelism. Evaluations on 29 benchmark circuits show 40-150% efficiency gains over bus routing, 19-80% fewer logical qubits, 4.5x faster average magic state prep, and up to 15x better than DASCOT including prep costs, with scheduled volumes between FLASQ bounds.
Significance. If the modeling of interruption overheads holds, this work offers a significant advance in practical resource management for fault-tolerant quantum computation, potentially reducing the large overheads associated with magic state factories and routing in lattice surgery. The use of dynamic scheduling to exploit stochasticity and the comparisons to baselines and theoretical bounds provide a strong foundation for improved efficiency in near-term quantum hardware.
major comments (2)
- The headline efficiency numbers (4.5x average prep-time reduction, up to 15x vs DASCOT) rest on the claim that repurposing ancilla patches for routing simply interrupts cultivation and restarts it later, with the long tail being cut off naturally and no ancilla ever idle. This requires that restart incurs only the natural stochastic cutoff and negligible extra error or latency. In surface-code cultivation, however, the protocol state (e.g., accumulated syndrome history or patch configuration) may not be trivially resumable; an explicit restart could reset progress or inject additional logical error, eroding the reported gains. The 29 benchmarks are not shown to include workloads where interruption frequency is high enough to expose this cost.
- Simulation assumptions, error modeling during interruptions, or statistical significance of the 4.5x and 15x claims are not detailed. The abstract reports concrete percentage improvements on 29 circuits and comparisons to DASCOT and theoretical bounds, but lacks visible details on simulation assumptions, error modeling during interruptions, or statistical significance of the 4.5x and 15x claims.
minor comments (2)
- Clarify in the methods section how the weight limit on Tableau transpilation is chosen and how it specifically benefits from PureMagic's dynamic scheduling.
- Ensure figures comparing efficiency and qubit counts across the 29 benchmarks include error bars or variance measures to support the reported ranges (40% to 150%, 19% to 80%).
Simulated Author's Rebuttal
We are grateful to the referee for their positive assessment of the significance of our work and for the constructive major comments. We have revised the manuscript to provide greater clarity on our modeling of dynamic scheduling, interruption overheads, and simulation details, as detailed in the point-by-point responses below.
read point-by-point responses
-
Referee: The headline efficiency numbers (4.5x average prep-time reduction, up to 15x vs DASCOT) rest on the claim that repurposing ancilla patches for routing simply interrupts cultivation and restarts it later, with the long tail being cut off naturally and no ancilla ever idle. This requires that restart incurs only the natural stochastic cutoff and negligible extra error or latency. In surface-code cultivation, however, the protocol state (e.g., accumulated syndrome history or patch configuration) may not be trivially resumable; an explicit restart could reset progress or inject additional logical error, eroding the reported gains. The 29 benchmarks are not shown to include workloads where interruption frequency is high enough to expose this cost.
Authors: We thank the referee for this careful observation. In our PureMagic scheduler, the cultivation process is treated as a sequence of independent stochastic attempts, where interruption for routing purposes causes the current attempt to be abandoned and a new attempt to be initiated once the patch is available again. This design choice ensures that the long tail of cultivation times is naturally truncated without requiring the system to wait for rare long-duration successes. We model the restart as incurring only the standard initiation latency of the cultivation protocol, with no additional logical error introduced because the surface code patches maintain their error correction properties throughout, and no syndrome history is carried over in a way that would be invalidated. To demonstrate that our benchmarks cover relevant interruption scenarios, we have added a new table and discussion in the revised manuscript quantifying the average and maximum interruption frequencies observed across the 29 circuits, showing that the efficiency gains persist even under frequent interruptions. revision: yes
-
Referee: Simulation assumptions, error modeling during interruptions, or statistical significance of the 4.5x and 15x claims are not detailed. The abstract reports concrete percentage improvements on 29 circuits and comparisons to DASCOT and theoretical bounds, but lacks visible details on simulation assumptions, error modeling during interruptions, or statistical significance of the 4.5x and 15x claims.
Authors: We agree that the manuscript would benefit from more explicit details on these aspects. In the revised version, we have expanded Section 5 (Evaluation) with a new subsection on 'Simulation Methodology and Assumptions.' This includes: a description of the Monte Carlo simulation framework used to model stochastic cultivation times (assuming geometric distributions based on per-cycle success probabilities); explicit error modeling for interruptions, where we assume zero additional error cost during the pause and restart phases as the logical patch remains under continuous error correction; and statistical reporting, where all reported speedups (including the 4.5x average and up to 15x vs. DASCOT) are accompanied by standard deviations and are computed as averages over 1000 independent simulation runs per benchmark to ensure statistical significance. We have also updated the abstract to reference these details. revision: yes
Circularity Check
No circularity in empirical scheduler evaluation
full rationale
The paper introduces PureMagic as a dynamic scheduler for lattice surgery and reports its performance through direct empirical evaluation on 29 benchmark circuits. Efficiency gains, qubit reductions, and preparation time improvements are measured outcomes from applying the scheduler and comparing against independent external baselines (bus routing and DASCOT). The positioning of scheduled volumes between FLASQ conservative and optimistic lower bounds is a comparative statement to external theoretical results rather than a self-derived quantity. No load-bearing steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on observable simulation results under the stated scheduling rules.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Surface codes require magic states for universal fault-tolerant computation.
- domain assumption Magic state cultivation is inherently stochastic with a long tail of preparation times.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
When a patch is needed for routing, cultivation is interrupted and restarted afterward, naturally cutting off the long tail of cultivation times
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model the time taken to cultivate the magic state using an exponential distribution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Improved simulation of stabilizer circuits,
S. Aaronson and D. Gottesman, “Improved simulation of stabilizer circuits,”Physical Review A, vol. 70, no. 5, Nov. 2004. [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.70.052328
-
[2]
BQSKit: Berkeley quantum synthesis toolkit,
BQSKit Development Team, “BQSKit: Berkeley quantum synthesis toolkit,” https://github.com/BQSKit/bqskit, 2024, accessed: 2025-01-16
work page 2024
-
[3]
Universal quantum computation with ideal Clifford gates and noisy ancillas,
S. Bravyi and A. Kitaev, “Universal quantum computation with ideal Clifford gates and noisy ancillas,”Physical Review A, vol. 71, no. 2, p. 022316, 2005
work page 2005
-
[4]
Trading classical and quantum computational resources,
S. Bravyi, G. Smith, and J. A. Smolin, “Trading classical and quantum computational resources,”Phys. Rev. X, vol. 6, p. 021043, Jun
-
[5]
Available: https://link.aps.org/doi/10.1103/PhysRevX.6
[Online]. Available: https://link.aps.org/doi/10.1103/PhysRevX.6. 021043
-
[6]
Correlated decoding of logical algo- rithms with transversal gates,
M. Cain, C. Zhao, H. Zhou, N. Meister, J. P. B. Ataides, A. Jaffe, D. Bluvstein, and M. D. Lukin, “Correlated decoding of logical algo- rithms with transversal gates,”Physical Review Letters, vol. 133, no. 24, p. 240602, 2024
work page 2024
-
[7]
C. Chamberland and E. T. Campbell, “Universal quantum computing with twist-free and temporally encoded lattice surgery,”PRX Quantum, vol. 3, p. 010331, Feb 2022. [Online]. Available: https://link.aps.org/ doi/10.1103/PRXQuantum.3.010331
-
[8]
Low overhead quantum computation using lattice surgery,
A. G. Fowler and C. Gidney, “Low overhead quantum computation using lattice surgery,” 2018
work page 2018
-
[9]
Surface codes: Towards practical large-scale quantum computation,
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, “Surface codes: Towards practical large-scale quantum computation,”Physical Review A, vol. 86, no. 3, p. 032324, 2012
work page 2012
-
[10]
How to factor 2048 bit RSA integers with less than a million noisy qubits
C. Gidney, “How to factor 2048 bit rsa integers with less than a million noisy qubits,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.15917
work page internal anchor Pith review Pith/arXiv arXiv 2048
-
[11]
Magic state cultivation: growing T states as cheap as CNOT gates
C. Gidney, N. Shutty, and C. Jones, “Magic state cultivation: growing t states as cheap as cnot gates,” 2024. [Online]. Available: https://arxiv.org/abs/2409.17595
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Y . Hirano and K. Fujii, “Locality-aware pauli-based computation for local magic state preparation,” 2025. [Online]. Available: https: //arxiv.org/abs/2504.12091
-
[13]
Surface code quantum computing by lattice surgery,
D. Horsman, A. G. Fowler, S. Devitt, and R. Van Meter, “Surface code quantum computing by lattice surgery,”New Journal of Physics, vol. 14, no. 12, p. 123011, 2012
work page 2012
-
[14]
Fault-tolerant quantum computation by anyons,
A. Y . Kitaev, “Fault-tolerant quantum computation by anyons,”Annals of Physics, vol. 303, no. 1, pp. 2–30, 2003
work page 2003
-
[15]
URL https://doi.org/10.1109/HPCA61900.2025.00102
T. Kobori, Y . Suzuki, Y . Ueno, T. Tanimoto, S. Todo, and Y . Tokunaga, “Lsqca: Resource-efficient load/store architecture for limited-scale fault-tolerant quantum computing,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, Mar. 2025, p. 304–320. [Online]. Available: http://dx.doi.org/10.1109/HPCA61900.2025.00033
-
[16]
A fast algorithm for steiner trees,
L. Kou, G. Markowsky, and L. Berman, “A fast algorithm for steiner trees,”Acta informatica, vol. 15, no. 2, pp. 141–145, 1981
work page 1981
-
[17]
L. C. Lau, “Packing steiner forests,” inInternational Conference on Integer Programming and Combinatorial Optimization. Springer, 2005, pp. 362–376
work page 2005
-
[18]
T. Leblond, C. Dean, G. Watkins, and R. Bennink, “Realistic cost to execute practical quantum circuits using direct clifford+t lattice surgery compilation,”ACM Transactions on Quantum Computing, vol. 5, no. 4, Oct. 2024. [Online]. Available: https://doi.org/10.1145/3689826
-
[19]
On the terminal steiner tree problem,
G. Lin and G. Xue, “On the terminal steiner tree problem,”Information Processing Letters, vol. 84, no. 2, pp. 103–107, 2002
work page 2002
-
[20]
D. Litinski, “A game of surface codes: Large-scale quantum computing with lattice surgery,”Quantum, vol. 3, p. 128, Mar. 2019. [Online]. Available: http://dx.doi.org/10.22331/q-2019-03-05-128
-
[21]
Dependency-aware compilation for surface code quantum architectures,
A. Molavi, A. Xu, S. Tannu, and A. Albarghouthi, “Dependency-aware compilation for surface code quantum architectures,”Proc. ACM Program. Lang., vol. 9, no. OOPSLA1, Apr. 2025. [Online]. Available: https://doi.org/10.1145/3720416
-
[22]
P. D. Nation, A. A. Saki, S. Brandhofer, L. Bello, S. Garion, M. Treinish, and A. Javadi-Abhari, “Benchmarking the performance of quantum computing software for quantum circuit creation, manipulation and compilation,”Nature Computational Science, pp. 1–9, 2025
work page 2025
-
[23]
Quantum computation with realistic magic-state factories,
J. O’Gorman and E. T. Campbell, “Quantum computation with realistic magic-state factories,”Physical Review A, vol. 95, no. 3, Mar. 2017
work page 2017
-
[24]
Fault-tolerant quantum computation with high threshold in two dimensions,
R. Raussendorf and J. Harrington, “Fault-tolerant quantum computation with high threshold in two dimensions,”Physical review letters, vol. 98, no. 19, p. 190504, 2007
work page 2007
-
[25]
Fold-transversal surface code cultivation.arXiv preprint arXiv:2509.05212, 2025
K. Sahay, P.-K. Tsai, K. Chang, Q. Su, T. B. Smith, S. Singh, and S. Puri, “Fold-transversal surface code cultivation,” 2025. [Online]. Available: https://arxiv.org/abs/2509.05212
-
[26]
Multi-qubit lattice surgery scheduling
A. Silva, X. Zhang, Z. Webb, M. Kramer, C.-W. Yang, X. Liu, J. Lemieux, K.-W. Chen, A. Scherer, and P. Ronagh, “Multi-qubit lattice surgery scheduling.” Schloss Dagstuhl – Leibniz-Zentrum f ¨ur Informatik, 2024. [Online]. Available: https://drops.dagstuhl.de/entities/ document/10.4230/LIPIcs.TQC.2024.1
-
[27]
Multiple particle interference and quantum error correction,
A. Steane, “Multiple particle interference and quantum error correction,” Proceedings of the Royal Society A: Mathematical, Physical and Engi- neering Sciences, vol. 452, 01 1996
work page 1996
-
[28]
Ndpbridge: Enabling cross-bank coordination in near-dram-bank processing architectures,
D. B. Tan, M. Y . Niu, and C. Gidney, “A sat scalpel for lattice surgery: Representation and synthesis of subroutines for surface-code fault-tolerant quantum computing,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, Jun. 2024, p. 325–339. [Online]. Available: http: //dx.doi.org/10.1109/ISCA59077.2024.00032
-
[29]
Efficient magic state cultivation on the surface code,
Y . Vaknin, S. Jacoby, A. Grimsmo, and A. Retzker, “Efficient magic state cultivation on the surface code,” 2025. [Online]. Available: https://arxiv.org/abs/2502.01743
-
[30]
J. Viszlai, W. Yang, S. F. Lin, J. Liu, N. Nottingham, J. M. Baker, and F. T. Chong, “Matching generalized-bicycle codes to neutral atoms for low-overhead fault-tolerance,” 2024. [Online]. Available: https://arxiv.org/abs/2311.16980
-
[31]
Tour de gross: A modular quantum computer based on bivariate bicycle codes
T. J. Yoder, E. Schoute, P. Rall, E. Pritchett, J. M. Gambetta, A. W. Cross, M. Carroll, and M. E. Beverland, “Tour de gross: A modular quantum computer based on bivariate bicycle codes,” 2025. [Online]. Available: https://arxiv.org/abs/2506.03094 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.