Locality Does Not Imply Reachability: Boundary Repair in Block-Sparse Causal Attention
Pith reviewed 2026-06-28 15:32 UTC · model grok-4.3
The pith
Fixed block causal attention with uniform masks across layers restricts each token's representation to its own block prefix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
If every attention layer uses the same fixed block causal mask and all remaining operations are positionwise, a target representation can depend only on tokens in its own block prefix. This yields an architecture-level boundary-copy separation for a constructed K-way boundary-copy distribution, with top-1 accuracy upper bound 1/K and expected cross-entropy lower bound log K.
What carries the argument
Structural dependency sets that track the tokens reachable to a target under repeated application of the fixed block causal mask together with positionwise operations.
If this is right
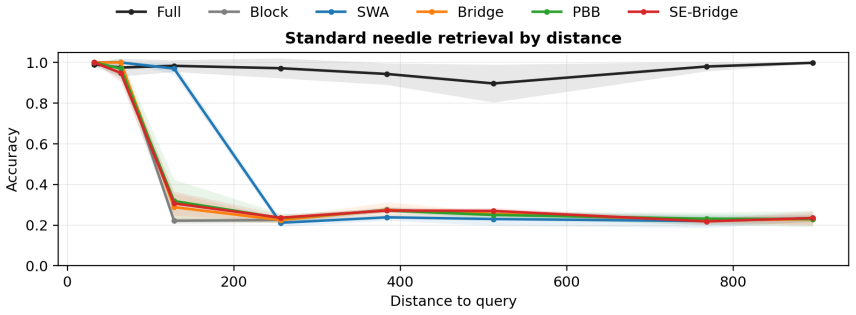
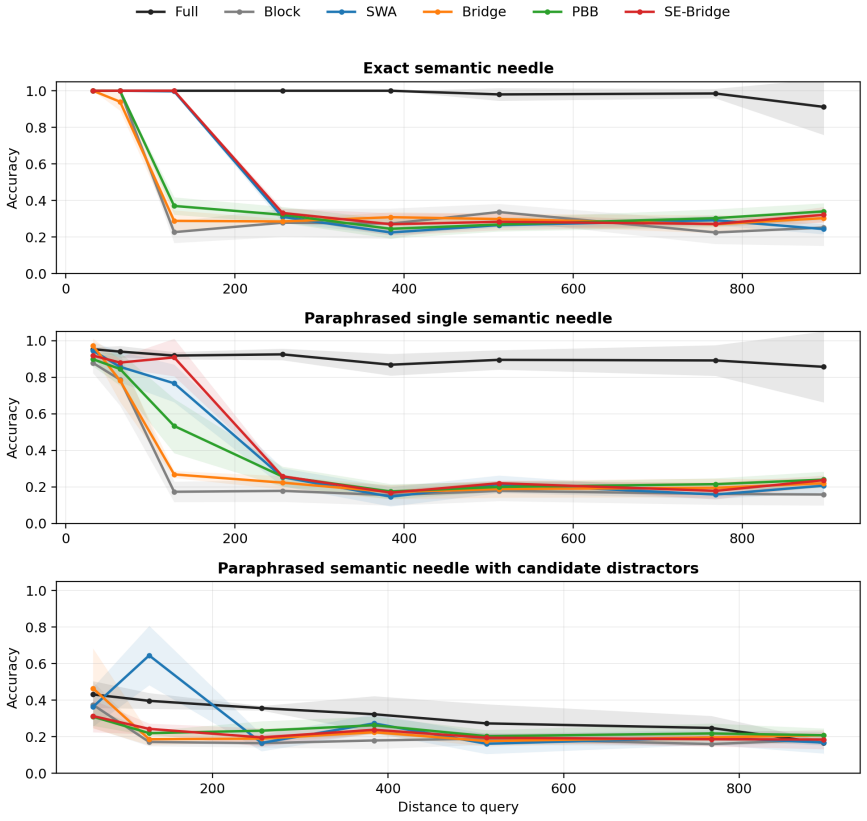
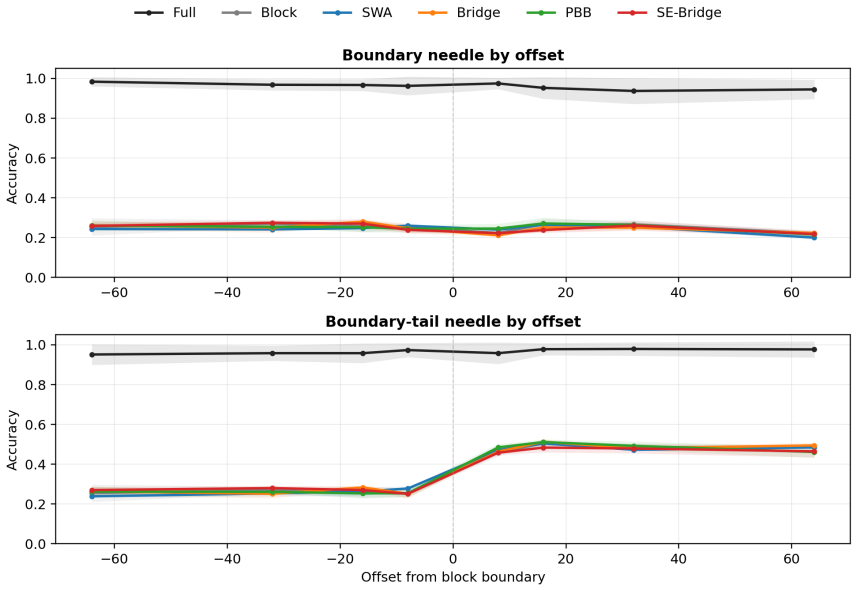
- Reachability between adjacent tokens fails whenever their positions straddle a block boundary under the uniform mask.
- Phase-conditioned coverage laws predict the exact source-target pairs that remain unreachable for any given block size and offset.
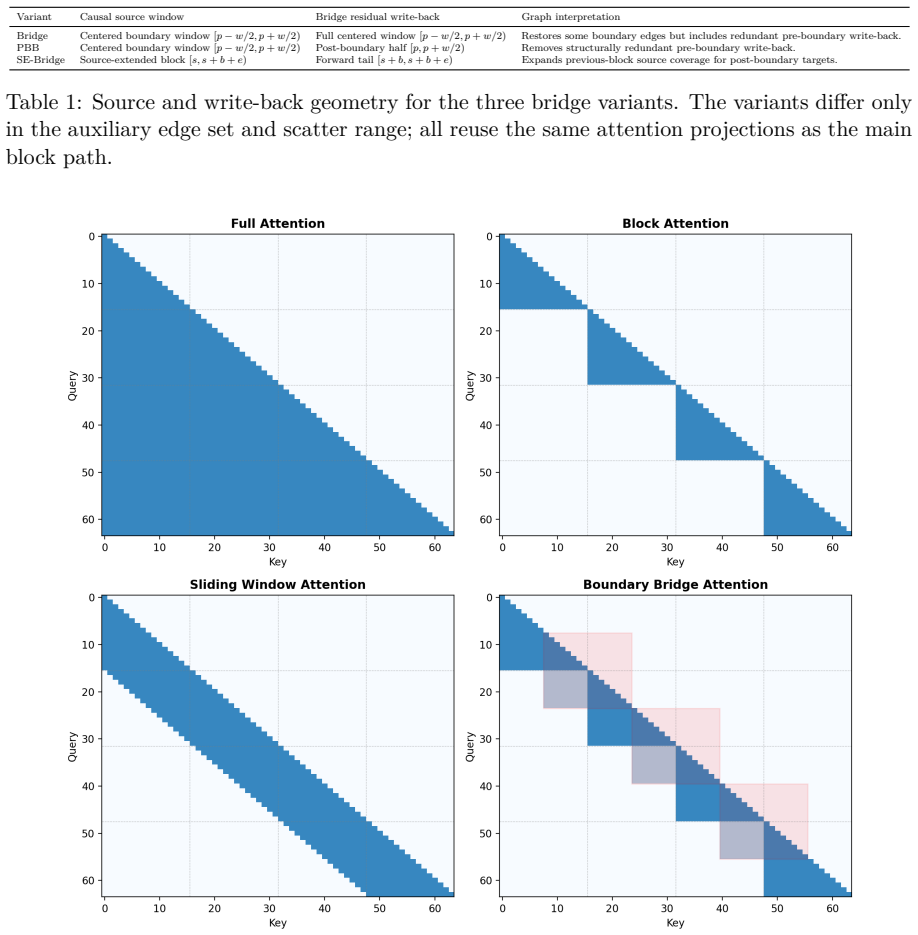
- Boundary Bridge Attention restores cross-boundary reachability by adding zero-parameter auxiliary edges while keeping the original block path fixed.
- Sliding-window attention and boundary repair affect coverage differently and are therefore not interchangeable fixes.
Where Pith is reading between the lines
- The coverage analysis could be applied to other fixed sparse patterns to identify similar hidden reachability gaps.
- Varying the mask across layers would be a direct way to test whether the separation is mask-uniformity dependent.
- The same diagnostic could be run on any task whose labels require cross-block information to quantify practical impact.
Load-bearing premise
The block causal mask remains identical at every layer and every non-attention operation mixes no information across positions.
What would settle it
Train any model obeying the fixed uniform block mask and positionwise operations on the K-way boundary-copy distribution and check whether top-1 accuracy exceeds 1/K or cross-entropy drops below log K.
Figures
read the original abstract
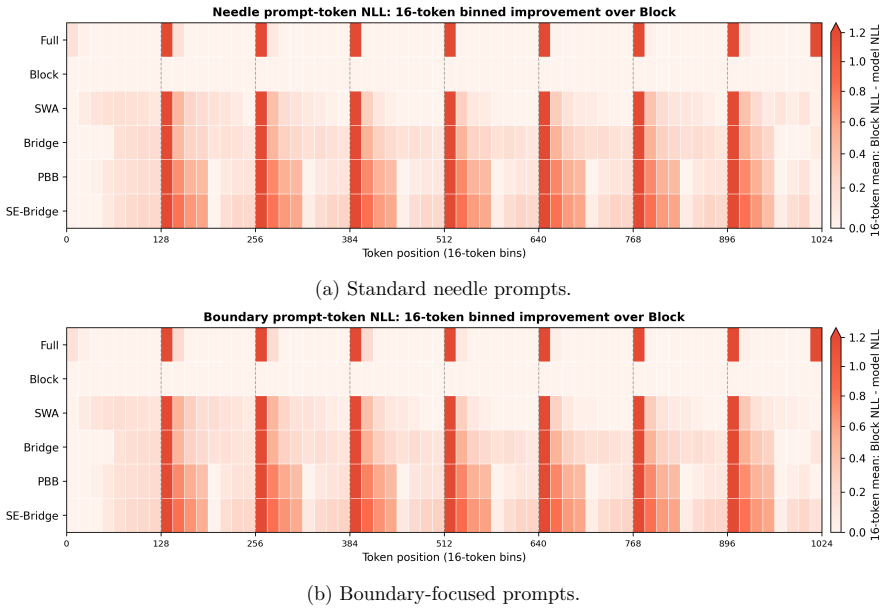
Sparse causal attention is usually described by sequence locality: nearby tokens should remain easy to access, while distant tokens may be dropped to reduce cost. This paper studies a mismatch between sequence locality and attention-graph reachability. In fixed block causal attention, two adjacent tokens can be disconnected in the attention graph at every depth. We formalize this boundary artifact through structural dependency sets: if every attention layer uses the same fixed block causal mask and all remaining operations are positionwise, a target representation can depend only on tokens in its own block prefix. This yields an architecture-level boundary-copy separation for a constructed K-way boundary-copy distribution, with top-1 accuracy upper bound 1/K and expected cross-entropy lower bound log K. We then derive phase-conditioned coverage functions showing that reachability depends on both source-target distance and the target's offset within its block. These coverage laws predict when a sparse pattern should fail, when a repair can help, and why sliding-window attention and boundary repair are not interchangeable. Boundary Bridge Attention is treated as a constructive witness: it preserves the fixed block path and adds zero-additional-parameter auxiliary causal edges near block boundaries using shared projections. Controlled 1024-token experiments show that gains concentrate in coverage-aligned diagnostics. As secondary external-validity evidence, a fixed-checkpoint 8K-token Qwen2.5-7B probe shows the same coverage-incomparability pattern. The contribution is a theory-guided diagnostic framework for locality-reachability mismatch in block-sparse causal attention, together with phase-conditioned coverage analysis and a minimal constructive repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that when every attention layer uses an identical fixed block-causal mask and all non-attention operations are strictly positionwise, structural dependency sets are confined to each token's own block prefix. This yields an architecture-level boundary-copy separation on a constructed K-way boundary-copy distribution, with top-1 accuracy upper-bounded by 1/K and expected cross-entropy lower-bounded by log K. Phase-conditioned coverage functions are derived to predict reachability as a function of source-target distance and the target's offset within its block. Boundary Bridge Attention is introduced as a parameter-free constructive witness that adds auxiliary causal edges near block boundaries while preserving the fixed block path. Controlled 1024-token experiments and an 8K-token fixed-checkpoint probe on Qwen2.5-7B are reported to align with the coverage predictions.
Significance. If the stated conditional holds, the paper supplies a precise graph-reachability account of why block-sparse causal attention can fail on cross-boundary tasks even when sequence locality is respected. The derivation of the 1/K and log K bounds follows directly from the mask and positionwise assumptions; the phase-conditioned coverage functions supply falsifiable, distance-and-offset-dependent predictions; and Boundary Bridge Attention demonstrates a minimal repair with zero additional parameters. The controlled experiments and external Qwen probe provide supporting evidence without post-hoc exclusions. These elements together constitute a useful diagnostic framework for locality-reachability mismatch in sparse attention.
minor comments (2)
- [§3] §3 (structural dependency sets): an explicit small-scale worked example or pseudocode for computing the recursive reachability sets on a toy 2-block mask would clarify the definition for readers.
- [Experiments] Experimental section: the 1024-token results are described as concentrating in coverage-aligned diagnostics, but the precise numerical values, number of random seeds, and any variance measures are not stated; adding these details would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation to accept. We appreciate the recognition of the graph-reachability analysis, phase-conditioned coverage functions, and the minimal Boundary Bridge repair.
Circularity Check
No significant circularity; derivation self-contained from mask and reachability
full rationale
The central claims follow from explicit definitions of the fixed block-causal mask, positionwise non-attention operations, and per-layer attention-graph reachability. Structural dependency sets and phase-conditioned coverage functions are constructed directly as consequences of these architectural premises (no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations). The K-way boundary-copy separation bounds are logical implications of the reachability analysis under the stated assumptions. The paper is self-contained against external benchmarks with no reduction of its core results to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption All remaining operations after attention are positionwise
invented entities (3)
-
structural dependency sets
no independent evidence
-
phase-conditioned coverage functions
no independent evidence
-
Boundary Bridge Attention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ETC: Encoding long and structured inputs in transformers
Joshua Ainslie, Santiago Ontanon, Chris Alberti, Vaclav Cvicek, Zachary Fisher, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, and Li Yang. ETC: Encoding long and structured inputs in transformers. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 268–284, Online,
2020
-
[2]
doi: 10.18653/v1/2020.emnlp-main.19
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.19. URL https://aclanthology.org/2020.emnlp-main.19/. Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-Eval: Instituting standardized evaluation for long context language models. InProceedings of the 62nd Annual Meeting of ...
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li
URL https://aclanthology.org/2024.acl-long.776/. Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computat...
2024
-
[4]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li
URLhttps://aclanthology.org/2024.acl-long.172/. Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computa...
2024
-
[5]
Longformer: The Long-Document Transformer
doi: 10.18653/v1/2025.acl-long.183. URL https://aclanthology.org/2025.acl-long.183/. Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.183 2025
-
[6]
Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Pith/arXiv arXiv 1904
-
[7]
Transformer- XL : Attentive Language Models beyond a Fixed-Length Context
Association for Computational Linguistics. doi: 10.18653/v1/P19-1285. URLhttps://aclanthology.org/P19-1285/. Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations,
-
[8]
URLhttps: //huggingface.co/deepseek-ai/DeepSeek-V4-Flash/blob/main/DeepSeek_V4.pdf. Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. LongNet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
-
[9]
AbsenceBench: Language models can’t tell what’s missing.arXiv preprint arXiv:2506.11440,
33 Harvey Yiyun Fu, Aryan Shrivastava, Jared Moore, Peter West, Chenhao Tan, and Ari Holtzman. AbsenceBench: Language models can’t tell what’s missing.arXiv preprint arXiv:2506.11440,
-
[10]
Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Leonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
-
[11]
URL https://arxiv.org/abs/2404.06654. arXiv:2404.06654. DeLesley Hutchins, Imanol Schlag, Yuhuai Wu, Ethan Dyer, and Behnam Neyshabur. Block-recurrent transformers. InAdvances in Neural Information Processing Systems,
-
[12]
Mistral 7B.arXiv preprint arXiv:2310.06825,
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B.arXiv preprint arXiv:2310.06825,
-
[13]
doi: 10.52202/079017-1663. URLhttps://papers.nips.cc/paper_files/paper/2024/hash/ 5dfbe6f5671e82c76841ba687a8a9ecb-Abstract-Conference.html. Gregory Kamradt. Needle in a haystack – pressure testing LLMs.GitHub repository,
-
[14]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
doi: 10.1162/tacl_a_00638. URLhttps://aclanthology.org/2024.tacl-1.9/. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision,
-
[15]
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ ab05dc8bf36a9f66edbff6992ec86f56-Abstract-Conference.html. Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143,
Pith/arXiv arXiv 2023
-
[16]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
-
[17]
doi: 10.48550/arXiv.2412.15115. URLhttps://arxiv.org/abs/2412.15115. arXiv:2412.15115v2. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI technical report,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[18]
URL https://aclanthology.org/2021.tacl-1.4/
doi: 10.1162/tacl_a_00353. URL https://aclanthology.org/2021.tacl-1.4/. Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context LLM inference. InInternational Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 47901–47911. PMLR,
-
[19]
URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ 5c1ddd2e59df46fd2aa85c833b1b36ed-Abstract-Conference.html. Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native Sparse Attention: Hardware-aligne...
2025
-
[20]
URL https://aclanthology.org/2025.acl-long.1126/
doi: 10.18653/v1/2025.acl-long.1126. URL https://aclanthology.org/2025.acl-long.1126/. Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. InAdvances in Neural Information Processing Systems, volum...
-
[21]
URLhttps://proceedings.neurips.cc/ paper/2020/hash/c8512d142a2d849725f31a9a7a361ab9-Abstract.html. Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun.∞Bench: Extending long context evaluation beyond 100k tokens. InProceedings of the 62nd Annual Meeting of the Association fo...
2020
-
[22]
doi: 10.18653/v1/2024.acl-long.814
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.814. URLhttps://aclanthology.org/2024.acl-long.814/. 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.