What Drives the Inlier-Memorization Effect? A Theory of Outlier Detection via Early Training Dynamics
Pith reviewed 2026-06-30 07:20 UTC · model grok-4.3
The pith
A simple autoencoder memorizes inliers earlier than outliers under mild assumptions during early training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
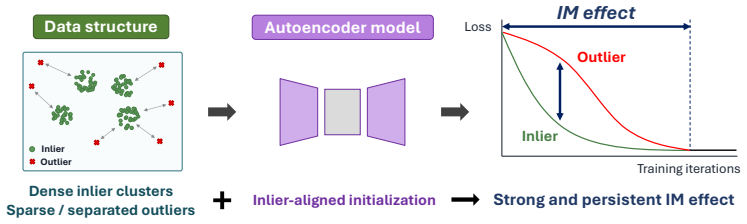
Under mild assumptions on the data distribution and parameter initialization, the model can successfully memorize inliers while failing to memorize outliers during certain stages of early training. The emergence, strength, and persistence of the inlier-memorization effect are characterized, along with their dependence on the data distribution and initialization.
What carries the argument
The separation of memorization times between inliers and outliers driven by differences in reconstruction error reduction rates during early gradient descent on an autoencoder.
Load-bearing premise
The data distribution and parameter initialization satisfy mild conditions that allow inliers to be memorized faster than outliers.
What would settle it
An experiment in which the autoencoder memorizes outliers at the same rate or earlier than inliers during the early training epochs, under the stated mild assumptions, would falsify the claim.
Figures


read the original abstract
Outlier detection (OD) aims to identify anomalous instances by learning the underlying structure of normal data (inliers), and is particularly challenging in fully unsupervised settings where no information about anomalies is available during training. Recent advances have leveraged the inlier-memorization (IM) effect, a phenomenon in which deep models memorize inlier patterns earlier than those of outliers, as a powerful signal for distinguishing outliers. However, despite its empirical success, the theoretical understanding of the IM effect remains limited. In this work, we present a theoretical study of the IM effect. Focusing on a simple autoencoder, we show that, under mild assumptions, the model can successfully memorize inliers while failing to memorize outliers during certain stages of early training. In particular, we characterize not only the emergence of the IM effect, but also its strength and persistence, and analyze how these properties depend on the data distribution and parameter initialization. In addition, building on these insights, we derive simple yet practical guidelines for enhancing the IM effect, including data preprocessing and parameter initialization schemes, achieving state-of-the-art performance on the ADBench datasets. Our findings provide a theoretical foundation for the IM effect and offer actionable directions for improving IM-based outlier detection methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a theoretical analysis of the inlier-memorization (IM) effect for outlier detection. Focusing on a simple autoencoder, it claims that under mild assumptions on the data distribution and parameter initialization, the model memorizes inliers earlier than outliers during early training stages. The work characterizes the emergence, strength, and persistence of the IM effect and its dependence on data distribution and initialization. Building on this, it derives practical guidelines for data preprocessing and initialization that achieve state-of-the-art performance on the ADBench benchmark.
Significance. If the derivation holds, the paper supplies a theoretical foundation for an empirically observed phenomenon that has been used in unsupervised outlier detection. The explicit characterization of how the effect depends on initialization and data properties, together with the derivation of actionable preprocessing and initialization schemes that reach SOTA on ADBench, would be a useful contribution to the literature on training dynamics and anomaly detection.
minor comments (2)
- The abstract states that the analysis proceeds 'under mild assumptions' on the data distribution and initialization but does not list them; the main text should state the precise assumptions (e.g., on the support of the inlier distribution or the scale of random initialization) at the beginning of the theoretical section so that readers can immediately assess their restrictiveness.
- Because the central result is restricted to a linear or shallow autoencoder, the manuscript should include a brief discussion (perhaps in the conclusion) of which qualitative features are expected to survive in deeper or nonlinear networks; this would strengthen the bridge to the practical guidelines that are tested on real data.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The paper's central claim is a characterization of the inlier-memorization effect for a simple autoencoder, derived under mild assumptions on the data distribution and parameter initialization. The abstract explicitly ties the emergence, strength, and persistence of the effect to these assumptions and data properties, without any visible reduction of predictions to fitted parameters or self-referential definitions. No load-bearing self-citations, ansatzes smuggled via prior work, or uniqueness theorems imported from the authors themselves are indicated in the provided text. The additional derivation of practical guidelines is presented as building on the theoretical insights and is independently validated via SOTA performance on ADBench, supplying an external empirical check. This is the most common honest outcome for a theory paper whose assumptions are stated as enabling the separation rather than being defined in terms of the target result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild assumptions on data distribution and parameter initialization enable memorization separation in a simple autoencoder
Reference graph
Works this paper leans on
-
[1]
Anomaly detection: A survey.ACM computing surveys (CSUR), 41(3):1–58, 2009
Varun Chandola, Arindam Banerjee, and Vipin Kumar. Anomaly detection: A survey.ACM computing surveys (CSUR), 41(3):1–58, 2009
2009
-
[2]
Deep Learning for Anomaly Detection: A Survey
Raghavendra Chalapathy and Sanjay Chawla. Deep learning for anomaly detection: A survey.arXiv preprint arXiv:1901.03407, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[3]
Financial fraud: a review of anomaly detection techniques and recent advances.Expert systems With applications, 193:116429, 2022
Waleed Hilal, S Andrew Gadsden, and John Yawney. Financial fraud: a review of anomaly detection techniques and recent advances.Expert systems With applications, 193:116429, 2022
2022
-
[4]
A survey of network anomaly detection techniques.Journal of network and computer applications, 60:19–31, 2016
Mohiuddin Ahmed, Abdun Naser Mahmood, and Jiankun Hu. A survey of network anomaly detection techniques.Journal of network and computer applications, 60:19–31, 2016
2016
-
[5]
Deep learning for medical anomaly detection–a survey.ACM computing surveys (CSUR), 54(7):1–37, 2021
Tharindu Fernando, Harshala Gammulle, Simon Denman, Sridha Sridharan, and Clinton Fookes. Deep learning for medical anomaly detection–a survey.ACM computing surveys (CSUR), 54(7):1–37, 2021
2021
-
[6]
ODIM: outlier detection via likelihood of under-fitted generative models
Dongha Kim, Jaesung Hwang, Jongjin Lee, Kunwoong Kim, and Yongdai Kim. ODIM: outlier detection via likelihood of under-fitted generative models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
2024
-
[7]
Yuang Zhang, Liping Wang, Yihong Huang, Yuanxing Zheng, Fan Zhang, and Xuemin Lin. Grad- stop: Exploring training dynamics in unsupervised outlier detection through gradient.arXiv preprint arXiv:2412.08501, 2024
-
[8]
ALTBI: constructing improved outlier detection models via optimization of inlier-memorization effect
Seoyoung Cho, Jaesung Hwang, Kwan-Young Bak, and Dongha Kim. ALTBI: constructing improved outlier detection models via optimization of inlier-memorization effect. In Toby Walsh, Julie Shah, and Zico Kolter, editors,AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, page...
2025
-
[9]
Memorize early, then query: Inlier-memorization-guided active outlier detection.Proceedings of the AAAI Conference on Artificial Intelligence, 40(17):15000– 15008, Mar
Minseo Kang, Seunghwan Park, and Dongha Kim. Memorize early, then query: Inlier-memorization-guided active outlier detection.Proceedings of the AAAI Conference on Artificial Intelligence, 40(17):15000– 15008, Mar. 2026
2026
-
[10]
Breunig, Hans-Peter Kriegel, Raymond T
Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. Lof: Identifying density-based local outliers.SIGMOD Rec., 29(2):93–104, may 2000
2000
-
[11]
Discovering cluster-based local outliers.Pattern recognition letters, 24(9-10):1641–1650, 2003
Zengyou He, Xiaofei Xu, and Shengchun Deng. Discovering cluster-based local outliers.Pattern recognition letters, 24(9-10):1641–1650, 2003
2003
-
[12]
Outliers detection with the minimum covariance determinant estimator in practice.Statistical Methodology, 6(4):363–379, 2009
Cecile Fauconnier and Gentiane Haesbroeck. Outliers detection with the minimum covariance determinant estimator in practice.Statistical Methodology, 6(4):363–379, 2009
2009
-
[13]
Isolation forest
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In2008 eighth ieee international conference on data mining, pages 413–422. IEEE, 2008
2008
-
[14]
Estimating support of a high-dimensional distribution.Neural Computation, 13:1443–1471, 07 2001
Bernhard Schölkopf, John Platt, John Shawe-Taylor, Alexander Smola, and Robert Williamson. Estimating support of a high-dimensional distribution.Neural Computation, 13:1443–1471, 07 2001
2001
-
[15]
Support vector data description.Machine learning, 54:45–66, 2004
David MJ Tax and Robert PW Duin. Support vector data description.Machine learning, 54:45–66, 2004
2004
-
[16]
Deep one-class classification
Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Müller, and Marius Kloft. Deep one-class classification. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4393–4402. PMLR, 10–15 Jul 2018
2018
-
[17]
Vandermeulen, Nico Görnitz, Alexander Binder, Emmanuel Müller, Klaus-Robert Müller, and Marius Kloft
Lukas Ruff, Robert A. Vandermeulen, Nico Görnitz, Alexander Binder, Emmanuel Müller, Klaus-Robert Müller, and Marius Kloft. Deep semi-supervised anomaly detection. InInternational Conference on Learning Representations, 2020
2020
-
[18]
Csi: Novelty detection via contrastive learning on distributionally shifted instances
Jihoon Tack, Sangwoo Mo, Jongheon Jeong, and Jinwoo Shin. Csi: Novelty detection via contrastive learning on distributionally shifted instances. InAdvances in Neural Information Processing Systems, volume 33, pages 11839–11852. Curran Associates, Inc., 2020
2020
-
[19]
Deep Anomaly Detection Using Geometric Transformations
Izhak Golan and Ran El-Yaniv. Deep anomaly detection using geometric transformations.arXiv preprint arXiv:1805.10917, 2018. 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020
2020
-
[21]
Anomaly detection for tabular data with internal contrastive learning
Tom Shenkar and Lior Wolf. Anomaly detection for tabular data with internal contrastive learning. In International conference on learning representations, 2022
2022
-
[22]
Neural transformation learning for deep anomaly detection beyond images
Chen Qiu, Timo Pfrommer, Marius Kloft, Stephan Mandt, and Maja Rudolph. Neural transformation learning for deep anomaly detection beyond images. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Proceedings of Machine Learning Research, pages 8703–8714. ...
2021
-
[23]
Paffenroth
Chong Zhou and Randy C. Paffenroth. Anomaly detection with robust deep autoencoders. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, pages 665–674. ACM, 2017
2017
-
[24]
Deep structured energy based models for anomaly detection
Shuangfei Zhai, Yu Cheng, Weining Lu, and Zhongfei Zhang. Deep structured energy based models for anomaly detection. InInternational conference on machine learning, pages 1100–1109. PMLR, 2016
2016
-
[25]
Waldstein, Ursula Schmidt-Erfurth, and Georg Langs
Thomas Schlegl, Philipp Seeböck, Sebastian M. Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Marc Niethammer, Martin Styner, Stephen R. Aylward, Hongtu Zhu, Ipek Oguz, Pew-Thian Yap, and Dinggang Shen, editors,Information Processing in Medical Imaging - ...
2017
-
[26]
Generative adversarial active learning for unsupervised outlier detection.IEEE Transactions on Knowledge and Data Engineering, 32(8):1517–1528, 2019
Yezheng Liu, Zhe Li, Chong Zhou, Yuanchun Jiang, Jianshan Sun, Meng Wang, and Xiangnan He. Generative adversarial active learning for unsupervised outlier detection.IEEE Transactions on Knowledge and Data Engineering, 32(8):1517–1528, 2019
2019
-
[27]
On Diffusion Modeling for Anomaly Detection
Victor Livernoche, Vineet Jain, Yashar Hezaveh, and Siamak Ravanbakhsh. On diffusion modeling for anomaly detection.CoRR, abs/2305.18593, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Hyperparameter sensitivity in deep outlier detection: Analysis and a scalable hyper-ensemble solution
Xueying Ding, Lingxiao Zhao, and Leman Akoglu. Hyperparameter sensitivity in deep outlier detection: Analysis and a scalable hyper-ensemble solution. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, N...
2022
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Stochastic backpropagation and approxi- mate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approxi- mate inference in deep generative models. In Eric P. Xing and Tony Jebara, editors,Proceedings of the 31st International Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pages 1278–1286, Bejing, China, 22–24 Jun 2014. PMLR
2014
-
[31]
Normalizing flows: An introduction and review of current methods.IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020
Ivan Kobyzev, Simon JD Prince, and Marcus A Brubaker. Normalizing flows: An introduction and review of current methods.IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020
2020
-
[32]
G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks.Science, 313(5786):504–507, 2006
2006
-
[33]
Du, Wei Hu, Zhiyuan Li, and Ruosong Wang
Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimiza- tion and generalization for overparameterized two-layer neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, P...
2019
-
[34]
Samet Oymak and Mahdi Soltanolkotabi. Towards moderate overparameterization: global convergence guarantees for training shallow neural networks.CoRR, abs/1902.04674, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[35]
Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks
Mingchen Li, Mahdi Soltanolkotabi, and Samet Oymak. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In Silvia Chiappa and Roberto Calandra, editors,The 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020, 26-28 August 2020, Online [Palermo, Sicily, Italy], Proc...
2020
-
[36]
Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein
Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. Deep neural networks as gaussian processes. In6th International Conference on Learn- ing Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018
2018
-
[37]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Clément Hongler, and Franck Gabriel. Neural tangent kernel: Convergence and generalization in neural networks. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, editors,Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 201...
2018
-
[38]
Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington
Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Information P...
2019
-
[39]
Thanh Van Nguyen, Raymond K. W. Wong, and Chinmay Hegde. Benefits of jointly training autoencoders: An improved neural tangent kernel analysis.IEEE Trans. Inf. Theory, 67(7):4669–4692, 2021
2021
-
[40]
On the convergence analysis of over-parameterized variational autoencoders: a neural tangent kernel perspective.Mach
Li Wang and Wei Huang. On the convergence analysis of over-parameterized variational autoencoders: a neural tangent kernel perspective.Mach. Learn., 114(1):15, 2025
2025
-
[41]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In2015 IEEE International Conference on Computer Vision (ICCV), pages 1026–1034, 2015
2015
-
[42]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, V...
2021
-
[44]
BERT: pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAAC...
2019
-
[45]
Tabpfn: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[46]
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. A closer look at tabpfn v2: Strength, limitation, and extension. CoRR, abs/2502.17361, 2025
-
[47]
A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Trans
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Trans. Pattern Anal. Mach. Intell., 46(12):9052–9071, 2024
2024
-
[48]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.CoRR, abs/1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Towards the generalization of contrastive self-supervised learning
Weiran Huang, Mingyang Yi, Xuyang Zhao, and Zihao Jiang. Towards the generalization of contrastive self-supervised learning. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[50]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Confere...
2017
-
[51]
Adbench: Anomaly detection benchmark
Songqiao Han, Xiyang Hu, Hailiang Huang, Mingqi Jiang, and Yue Zhao. Adbench: Anomaly detection benchmark. InNeural Information Processing Systems (NeurIPS), 2022
2022
-
[52]
Representation learning: A review and new perspec- tives.IEEE Trans
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspec- tives.IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, August 2013
2013
-
[53]
Emergence of invariance and disentanglement in deep representa- tions.Journal of Machine Learning Research, 19:1–34, 09 2018
Alessandro Achille and Stefano Soatto. Emergence of invariance and disentanglement in deep representa- tions.Journal of Machine Learning Research, 19:1–34, 09 2018
2018
-
[54]
Efficient algorithms for mining outliers from large data sets
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. Efficient algorithms for mining outliers from large data sets. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pages 427–438, 2000
2000
-
[55]
A novel anomaly detection scheme based on principal component classifier
Mei-Ling Shyu, Shu-Ching Chen, Kanoksri Sarinnapakorn, and LiWu Chang. A novel anomaly detection scheme based on principal component classifier. InProceedings of the IEEE foundations and new directions of data mining workshop, pages 172–179. IEEE Press, 2003
2003
-
[56]
Feature bagging for outlier detection
Aleksandar Lazarevic and Vipin Kumar. Feature bagging for outlier detection. InProceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, pages 157–166, 2005
2005
-
[57]
Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm.KI-2012: poster and demo track, 1:59–63, 2012
Markus Goldstein and Andreas Dengel. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm.KI-2012: poster and demo track, 1:59–63, 2012
2012
-
[58]
Loda: Lightweight on-line detector of anomalies.Machine Learning, 102:275–304, 2016
Tomáš Pevn `y. Loda: Lightweight on-line detector of anomalies.Machine Learning, 102:275–304, 2016
2016
-
[59]
Copod: copula-based outlier detection
Zheng Li, Yue Zhao, Nicola Botta, Cezar Ionescu, and Xiyang Hu. Copod: copula-based outlier detection. In2020 IEEE international conference on data mining (ICDM), pages 1118–1123. IEEE, 2020
2020
-
[60]
Ecod: Unsupervised outlier detection using empirical cumulative distribution functions.IEEE Transactions on Knowledge and Data Engineering, 2022
Zheng Li, Yue Zhao, Xiyang Hu, Nicola Botta, Cezar Ionescu, and George Chen. Ecod: Unsupervised outlier detection using empirical cumulative distribution functions.IEEE Transactions on Knowledge and Data Engineering, 2022
2022
-
[61]
Deep autoencoding gaussian mixture model for unsupervised anomaly detection
Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Daeki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. InInternational Conference on Learning Representations, 2018
2018
-
[62]
DROCC: deep robust one-class classification
Sachin Goyal, Aditi Raghunathan, Moksh Jain, Harsha Vardhan Simhadri, and Prateek Jain. DROCC: deep robust one-class classification. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, volume 119 ofProceedings of Machine Learning Research, pages 3711–3721. PMLR, 2020
2020
-
[63]
Classification-based anomaly detection for general data
Liron Bergman and Yedid Hoshen. Classification-based anomaly detection for general data. InInternational Conference on Learning Representations, 2020. 13 A Theoretical Studies We present here the assumptions, formal statements, and proofs of Theorem 3.1 and Corollary 3.2, which establish the early inlier fitting behavior of the autoencoder. The proofs pro...
2020
-
[64]
The cluster-centered loss replaces each input sample by its corresponding cluster-centered input while preserving the original reconstruction targets. For a given W , let eJ(W) and J(W) denote the Jacobian matrices of the cluster-centered and observed-input maps, respectively: eJ(W) := ∂FW (eX) ∂w ∈R np×Hp andJ(W) := ∂FW (X) ∂w ∈R np×Hp . In addition, for...
-
[65]
Let z:=D ⊤u/∥D⊤u∥2
Since PK k=1 nk∥uk∥2 2 = 1 , we also get nmin ≤ ∥D⊤u∥2 2 ≤n max and eJ(W) ⊤u=J c(W) ⊤D⊤u. Let z:=D ⊤u/∥D⊤u∥2. Then ∥z∥2 = 1 , so by Assumption A.4, αc∥D⊤u∥2 ≤ ∥eJ(W) ⊤u∥2 ≤β c∥D⊤u∥2. Using the bound on∥D ⊤u∥2 yields √nminαc ≤ ∥eJ(W) ⊤u∥2 ≤ √nmaxβc.Finally, we have eJ(W1)− eJ(W2) =D(J c(W1)−J c(W2)). Since∥D∥= √nmax, we obtain ∥eJ(W1)− eJ(W2)∥ ≤ √nmax∥Jc(W...
-
[66]
Since η≤α 2/(8β4), 4η2β4 ≤ 1 2 ηα2, and therefore ∥rτ+1 ∥2 2 ≤(1−ηα 2)∥rτ ∥2
-
[67]
Using the gradient descent update, it holds that ∥fWτ+1 −fWτ ∥F ≤ηβ∥ rτ ∥2 ≤ηβ(1−ηα 2)τ /2bR0
In particular, we have that ∥rτ+1 ∥2 ≤ ∥rτ ∥2 ≤ bR0,which leads to∥Π S+(erτ)∥2 2 ≤(1−ηα 2)τ ∥ΠS+(er0)∥2 2. Using the gradient descent update, it holds that ∥fWτ+1 −fWτ ∥F ≤ηβ∥ rτ ∥2 ≤ηβ(1−ηα 2)τ /2bR0. Therefore, we get ∥fWτ −W 0∥F ≤ τ−1X s=0 ∥fWs+1 −fWs∥F ≤ηβR 0 ∞X s=0 (1−ηα 2)s/2 ≤ 2β α2 R0 ≤R loc. Finally, since the inputsexi are constant inside each c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.