Effective Dimensionality as an Operator Invariant for Physics-Preserving Constraint Adaptation in Physics-Informed Neural Networks
Pith reviewed 2026-06-27 23:32 UTC · model grok-4.3
The pith
The effective dimensionality d_eff in PINNs converges exactly to the kernel dimension of finite-kernel differential operators, independent of network architecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
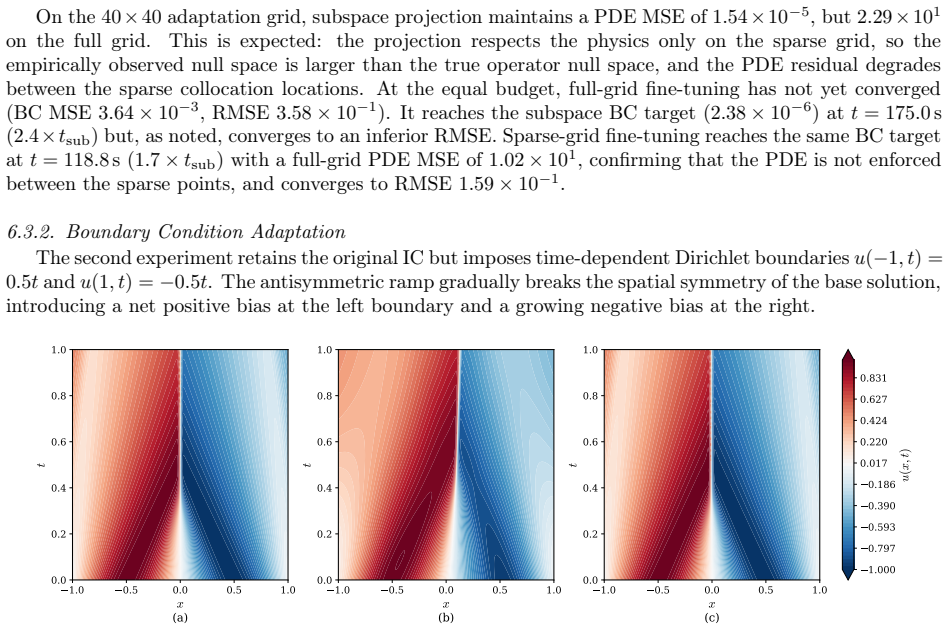
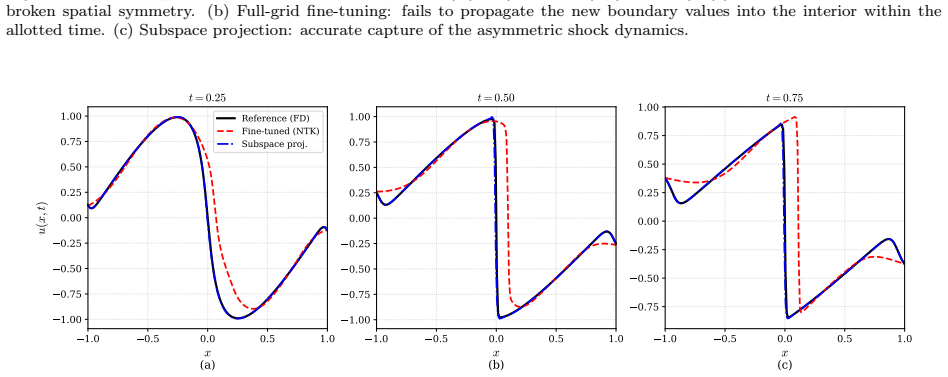
For operators with a finite-dimensional kernel, the effective dimensionality d_eff of a physics-constrained neural network converges exactly to the dimension of that kernel. This holds independently of network width, depth, or activation function, making d_eff a structural invariant of the continuous operator rather than a fit diagnostic. In cases of infinite-dimensional kernels, d_eff instead captures the network's finite representational bandwidth for the kernel. The measure also functions as a diagnostic for well-posed problems by reaching zero when constraints fully absorb free directions, and it underpins subspace projection techniques for efficient boundary condition adaptation without
What carries the argument
The Fisher Information Matrix applied to physics-constrained parameters, which measures the dimension of directions unconstrained by the differential operator.
If this is right
- Driving d_eff to zero certifies that the physics and boundary constraints have absorbed the network's free directions for well-posed problems.
- Subspace projection into the null space of the pre-trained physics operator allows new boundary conditions to be satisfied without disturbing the learned physics.
- This projection delivers near-equivalent accuracy to gradient-based fine-tuning but requires far less wall-clock time and tuning.
- For infinite-dimensional kernel operators, d_eff quantifies the network's representational bandwidth rather than recovering an integer invariant.
Where Pith is reading between the lines
- The invariant nature of d_eff could allow pre-determining suitable network capacities for problems with known kernel dimensions.
- Subspace projection might generalize to sequential constraint additions, preserving prior physics across multiple adaptations.
- This framework suggests testing d_eff stability when the neural network is replaced by other function approximators like polynomials or splines.
Load-bearing premise
The Fisher Information Matrix on the physics-constrained model accurately measures the dimension of parameter directions unconstrained by the differential operator and converges to the kernel dimension for finite-kernel operators.
What would settle it
Computing d_eff on a PINN trained for the Poisson equation (kernel dimension 1) and finding it not equal to 1 would falsify the convergence claim.
Figures
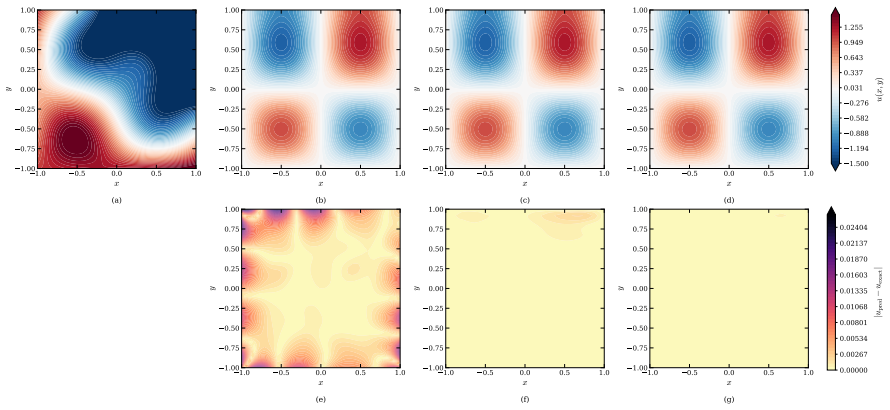
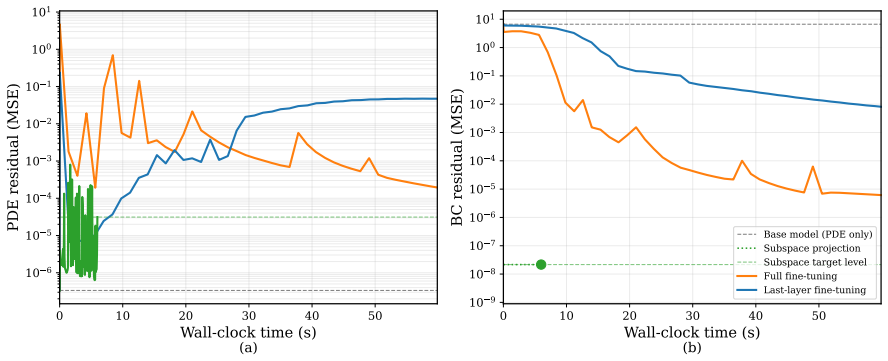
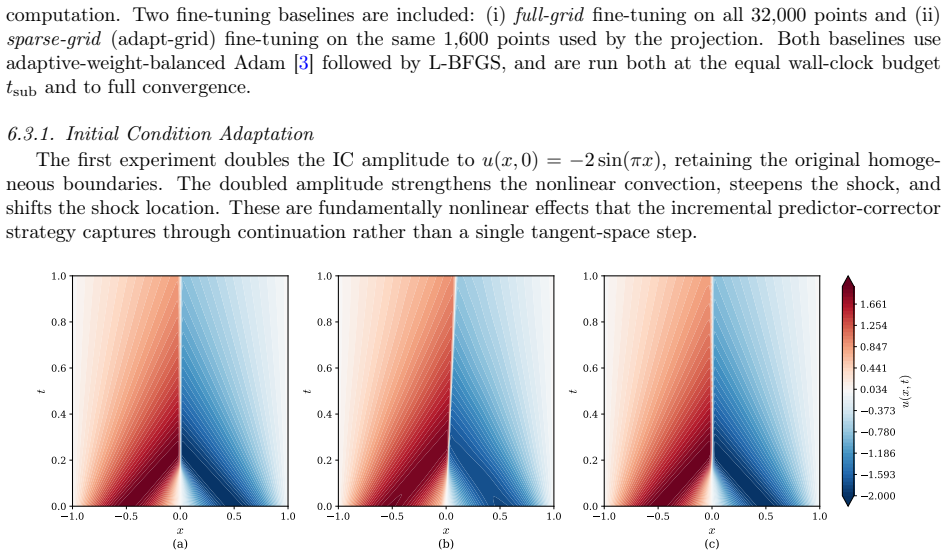
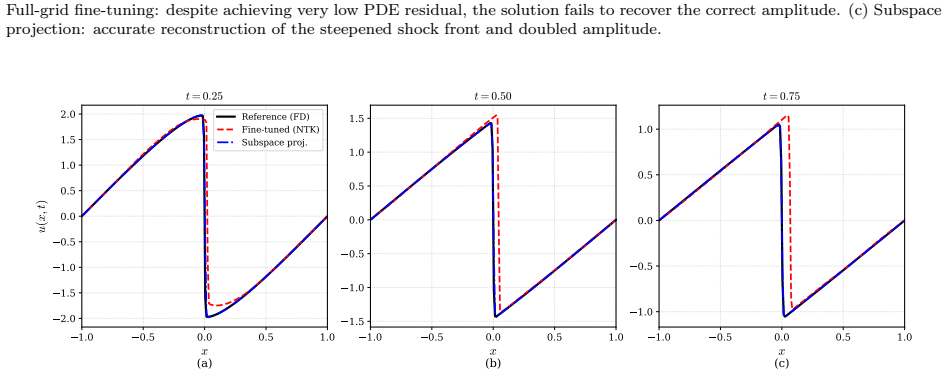
read the original abstract
Physics-Informed Neural Networks inherently suffer from task interference because they rely on a shared parameter space to satisfy both governing differential equations and boundary conditions. We analyze this structural conflict using the Fisher Information Matrix to quantify the effective degrees of freedom ($d_{eff}$) in a physics-constrained model. Unlike the classical $d_{eff}$ which measures how many parameter directions are informed by data against a statistical prior, our $d_{eff}$ measures the dimension of the parameter directions unconstrained by the differential operator. For operators with finite-dimensional kernel, we show that $d_{eff}$ converges to the kernel dimension exactly, independent of network width, depth, or activation function, recasting it from a fit diagnostic into a structural invariant of the underlying continuous operator. For operators with infinite-dimensional kernel, $d_{eff}$ instead measures the network's finite-dimensional representational bandwidth for that kernel rather than recovering an integer invariant. Importantly, $d_{eff}$ also serves as an a priori structural diagnostic. Driving $d_{eff}$ of a well-posed problem to zero certifies that the physics and boundary constraints have absorbed the network's free directions. Building on this characterization, we introduce subspace projection strategies for boundary adaptation. Rather than retraining from scratch, we project parameter updates into the null space of the pre-trained physics operator so that new boundary conditions are satisfied without disturbing the learned physics. Gradient-based fine-tuning can match or exceed this but needs more wall-clock time and tuning, whereas subspace projection delivers near-equivalent quality in seconds to minutes. We validate on linear and nonlinear operators, demonstrating accurate adaptation to initial and boundary shifts and unencountered constraint types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines an effective dimensionality d_eff for PINNs via the Fisher Information Matrix of the physics loss, claiming it measures parameter directions unconstrained by the differential operator. For operators with finite-dimensional kernels, it asserts that d_eff converges exactly to the kernel dimension independent of network width, depth, or activation. The work introduces subspace projection methods to adapt boundary conditions by projecting updates into the null space of a pre-trained physics operator and validates the approach on linear and nonlinear operators, contrasting it with gradient-based fine-tuning.
Significance. If the invariance result holds, the paper would recast d_eff from a diagnostic into a structural property of the continuous operator, providing both theoretical insight into PINN parameter spaces and a computationally efficient adaptation technique. The subspace projection strategy could reduce wall-clock time for constraint changes in applications, and the finite vs. infinite kernel distinction adds useful nuance.
major comments (2)
- [Abstract and d_eff definition section] Abstract and the section defining d_eff: the central claim that d_eff converges exactly to dim(ker) independent of architecture requires a derivation or theorem showing why the null space of the discrete FIM (built from collocation residuals) coincides with the continuous operator kernel for finite-width networks. No such derivation or proof sketch is evident, and the claim is load-bearing for recasting d_eff as an operator invariant.
- [Subspace projection section] The section on subspace projection: the method assumes the pre-trained physics operator's null space can be reliably identified via the FIM without residual dependence on sampling density or network representability; this needs explicit verification or bounds, as the skeptic concern about discrete collocation and finite networks directly impacts whether projection preserves the learned physics exactly.
minor comments (1)
- [Methods] Clarify the precise construction of the FIM (e.g., which loss terms and how the Hessian or outer-product approximation is used) to avoid ambiguity in the definition of unconstrained directions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas to strengthen the theoretical and empirical support in our manuscript. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract and d_eff definition section] Abstract and the section defining d_eff: the central claim that d_eff converges exactly to dim(ker) independent of architecture requires a derivation or theorem showing why the null space of the discrete FIM (built from collocation residuals) coincides with the continuous operator kernel for finite-width networks. No such derivation or proof sketch is evident, and the claim is load-bearing for recasting d_eff as an operator invariant.
Authors: The manuscript derives d_eff from the FIM of the physics loss and argues that for finite-kernel operators the unconstrained directions correspond exactly to the kernel because the loss is zero along those directions by definition of the kernel. However, we acknowledge that a more formal theorem linking the discrete collocation-based FIM to the continuous operator would clarify this independence from architecture. In the revised manuscript, we will include a proof sketch demonstrating that as the number of collocation points increases, the null space of the empirical FIM converges to the kernel of the operator, independent of the neural network's finite parameterization, since the residual is identically zero on the kernel. revision: yes
-
Referee: [Subspace projection section] The section on subspace projection: the method assumes the pre-trained physics operator's null space can be reliably identified via the FIM without residual dependence on sampling density or network representability; this needs explicit verification or bounds, as the skeptic concern about discrete collocation and finite networks directly impacts whether projection preserves the learned physics exactly.
Authors: We agree that the reliability of the null space identification is crucial for the projection method to preserve the physics exactly. The paper provides empirical validation across different operators and networks, showing that the adapted models maintain low physics loss. To address this rigorously, the revision will add analysis and experiments that vary the collocation density and network width to provide bounds on the approximation error in the identified null space, ensuring that the projection error is controlled by the PINN's training accuracy. revision: yes
Circularity Check
No circularity: d_eff defined via FIM and shown equal to kernel dim via independent derivation
full rationale
The abstract defines d_eff explicitly as the dimension of parameter directions unconstrained by the differential operator (via FIM of the physics loss) and states a separate result that this quantity equals the kernel dimension for finite-kernel operators, independent of architecture. This equivalence is presented as a shown mathematical property rather than a definitional identity or fitted input. No self-citation chains, ansatz smuggling, or renaming of known results appear in the provided text, and the derivation chain is self-contained against the continuous operator without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Fisher Information Matrix quantifies the dimension of parameter directions unconstrained by the differential operator in a physics-constrained model.
Reference graph
Works this paper leans on
-
[1]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning frame- work for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational physics 378 (2019) 686–707
2019
-
[2]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, Physics-informed machine learning, Nature Reviews Physics 3 (6) (2021) 422–440
2021
-
[3]
S. Wang, Y. Teng, P. Perdikaris, Understanding and mitigating gradient flow pathologies in physics- informed neural networks, SIAM Journal on Scientific Computing 43 (5) (2021) A3055–A3081
2021
-
[4]
S. Wang, X. Yu, P. Perdikaris, When and why pinns fail to train: A neural tangent kernel perspective, Journal of Computational Physics 449 (2022) 110768. 26
2022
-
[5]
Jacot, F
A. Jacot, F. Gabriel, C. Hongler, Neural tangent kernel: Convergence and generalization in neural networks, Advances in neural information processing systems 31 (2018)
2018
-
[6]
Krishnapriyan, A
A. Krishnapriyan, A. Gholami, S. Zhe, R. Kirby, M. W. Mahoney, Characterizing possible failure modes in physics-informed neural networks, Advances in neural information processing systems 34 (2021) 26548–26560
2021
-
[7]
Challenges in training pinns: A loss landscape perspective,
P. Rathore, W. Lei, Z. Frangella, L. Lu, M. Udell, Challenges in training pinns: A loss landscape perspective, arXiv preprint arXiv:2402.01868 (2024)
-
[8]
L. D. McClenny, U. M. Braga-Neto, Self-adaptive physics-informed neural networks, Journal of Com- putational Physics 474 (2023) 111722
2023
-
[9]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, C. Finn, Gradient surgery for multi-task learning, Advances in neural information processing systems 33 (2020) 5824–5836
2020
-
[10]
Q. Liu, M. Chu, N. Thuerey, Config: Towards conflict-free training of physics informed neural networks, in: International Conference on Learning Representations, Vol. 2025, 2025, pp. 59531–59566
2025
-
[11]
Leake, D
C. Leake, D. Mortari, Deep theory of functional connections: A new method for estimating the solutions of partial differential equations, Machine learning and knowledge extraction 2 (1) (2020) 37–55
2020
-
[12]
I. E. Lagaris, A. Likas, D. I. Fotiadis, Artificial neural networks for solving ordinary and partial differ- ential equations, IEEE transactions on neural networks 9 (5) (1998) 987–1000
1998
-
[13]
Sukumar, A
N. Sukumar, A. Srivastava, Exact imposition of boundary conditions with distance functions in physics- informed deep neural networks, Computer Methods in Applied Mechanics and Engineering 389 (2022) 114333
2022
-
[14]
Desai, M
S. Desai, M. Freeman, Z. Wang, S. Somnath, One-shot transfer learning of physics-informed neural networks, Machine Learning: Science and Technology 3 (2) (2022) 025010
2022
-
[15]
C. Xu, B. T. Cao, Y. Yuan, G. Meschke, Transfer learning based physics-informed neural networks for solving inverse problems in engineering structures under different loading scenarios, Computer Methods in Applied Mechanics and Engineering 405 (2023) 115852
2023
-
[16]
Goswami, C
S. Goswami, C. Anitescu, S. Chakraborty, T. Rabczuk, Transfer learning enhanced physics informed neural network for phase-field modeling of fracture, Theoretical and Applied Fracture Mechanics 106 (2020) 102447
2020
- [17]
-
[18]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature machine intelligence 3 (3) (2021) 218–229
2021
-
[19]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, arXiv preprint arXiv:2010.08895 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
S. Wang, H. Wang, P. Perdikaris, Learning the solution operator of parametric partial differential equations with physics-informed deeponets, Science advances 7 (40) (2021) eabi8605
2021
-
[21]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al., Overcoming catastrophic forgetting in neural networks, Proceedings of the national academy of sciences 114 (13) (2017) 3521–3526
2017
-
[22]
G. Zeng, Y. Chen, B. Cui, S. Yu, Continual learning of context-dependent processing in neural networks, Nature Machine Intelligence 1 (8) (2019) 364–372. 27
2019
-
[23]
Farajtabar, N
M. Farajtabar, N. Azizan, A. Mott, A. Li, Orthogonal gradient descent for continual learning, in: International conference on artificial intelligence and statistics, PMLR, 2020, pp. 3762–3773
2020
-
[24]
E. Schiassi, C. Leake, M. De Florio, H. Johnston, R. Furfaro, D. Mortari, Extreme theory of functional connections: A physics-informed neural network method for solving parametric differential equations, arXiv preprint arXiv:2005.10632 (2020)
-
[25]
D. E. De Falco, E. Schiassi, F. Calabrò, Least squares with equality constraints extreme learning ma- chines for the resolution of pdes, Journal of Computational Physics (2025) 114553
2025
-
[26]
Amari, Natural gradient works efficiently in learning, Neural computation 10 (2) (1998) 251–276
S.-I. Amari, Natural gradient works efficiently in learning, Neural computation 10 (2) (1998) 251–276
1998
-
[27]
R. Karakida, S. Akaho, S.-i. Amari, Pathological spectra of the fisher information metric and its variants in deep neural networks, arXiv preprint arXiv:1910.05992 (2019)
-
[28]
Ansuini, A
A. Ansuini, A. Laio, J. H. Macke, D. Zoccolan, Intrinsic dimension of data representations in deep neural networks, Advances in Neural Information Processing Systems 32 (2019)
2019
- [29]
-
[30]
Mishra, R
S. Mishra, R. Molinaro, Estimates on the generalization error of physics-informed neural networks for approximating a class of inverse problems for pdes, IMA Journal of Numerical Analysis 42 (2) (2022) 981–1022
2022
-
[31]
De Ryck, S
T. De Ryck, S. Mishra, Generic bounds on the approximation error for physics-informed (and) operator learning, Advances in Neural Information Processing Systems 35 (2022) 10945–10958
2022
-
[32]
Doumèche, G
N. Doumèche, G. Biau, C. Boyer, On the convergence of pinns, Bernoulli 31 (3) (2025) 2127–2151
2025
-
[33]
D. J. MacKay, A practical bayesian framework for backpropagation networks, Neural computation 4 (3) (1992) 448–472
1992
-
[34]
Sjöberg, L
J. Sjöberg, L. Ljung, Overtraining, regularization and searching for a minimum, with application to neural networks, International Journal of Control 62 (6) (1995) 1391–1407
1995
-
[35]
Ljung, et al., Theory for the user, System identification (1987)
L. Ljung, et al., Theory for the user, System identification (1987)
1987
-
[36]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[37]
Absil, R
P.-A. Absil, R. Mahony, R. Sepulchre, Optimization algorithms on matrix manifolds, Princeton Univer- sity Press, 2008. 28
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.