Hitting a Moving Target: Test-Time Adaptation for AI Text Detection under Continual Distribution Shift
Pith reviewed 2026-06-25 23:29 UTC · model grok-4.3
The pith
Test-time adaptation with semi-supervised learning on unlabeled samples maintains robust AI text detection under continual shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
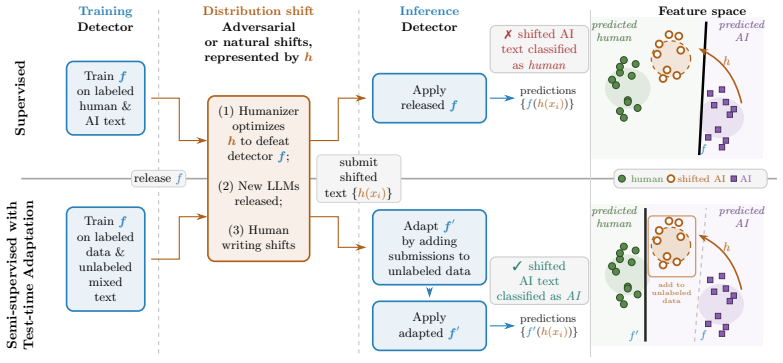
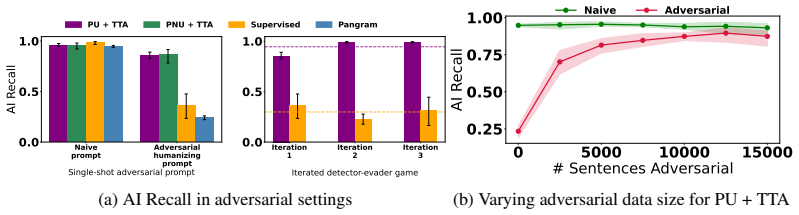
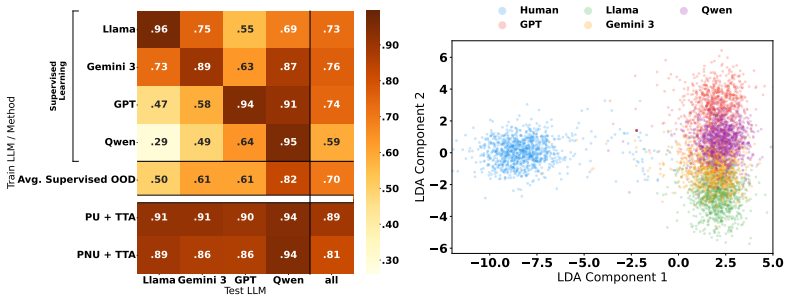
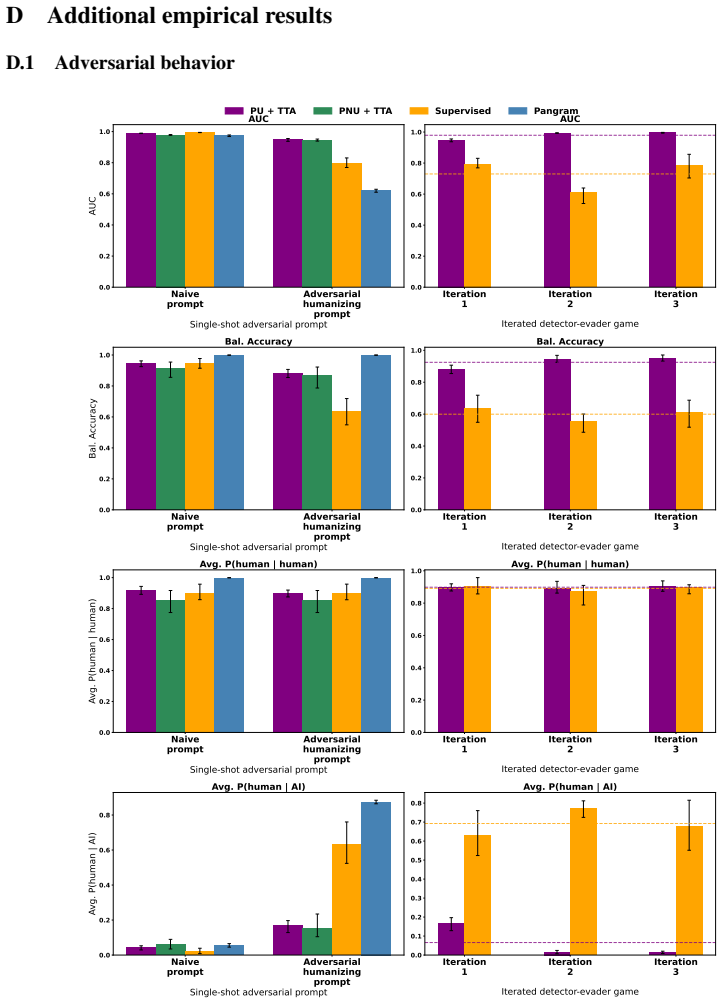
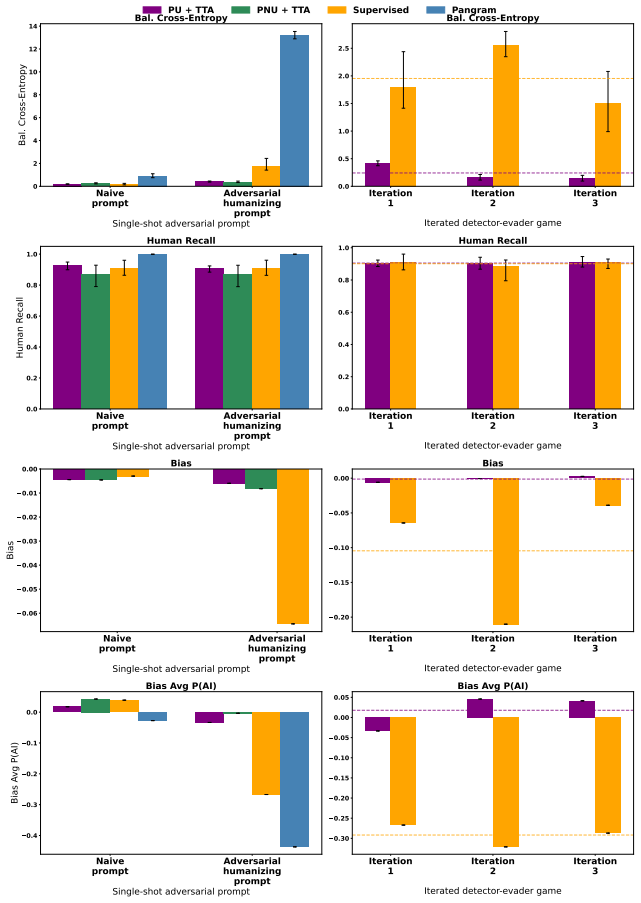
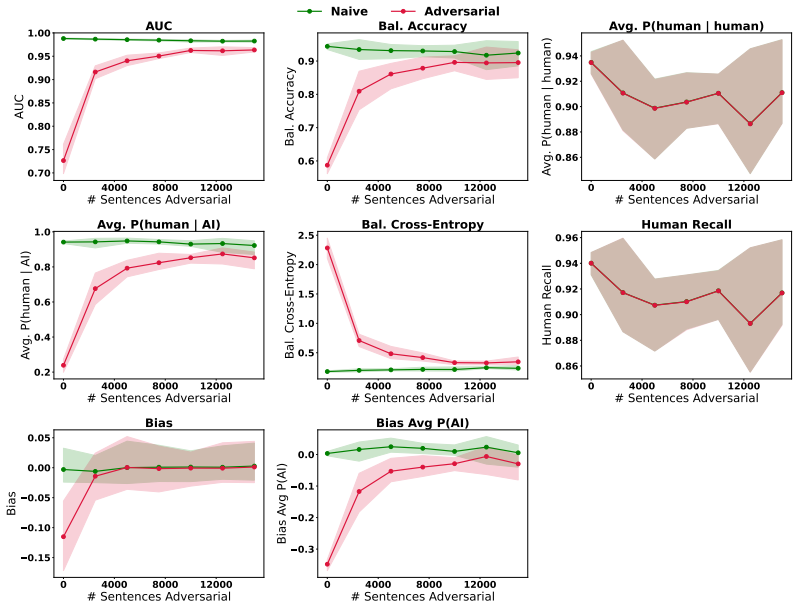
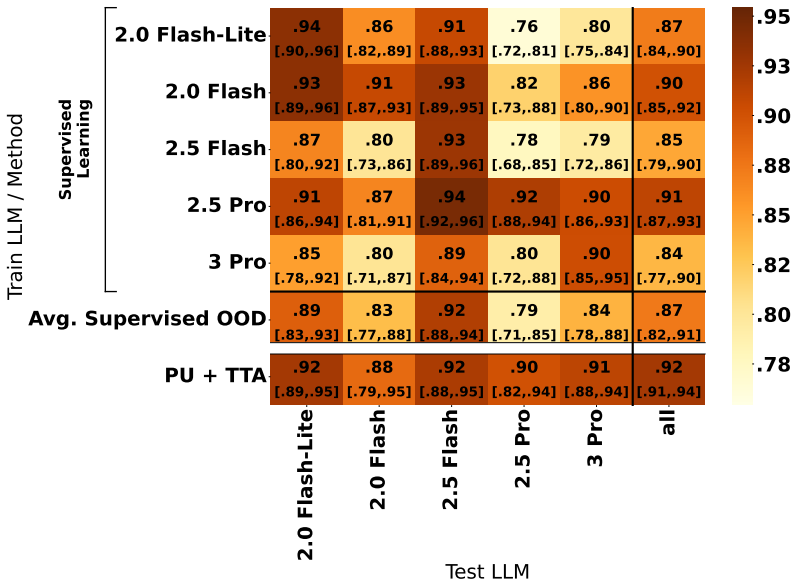
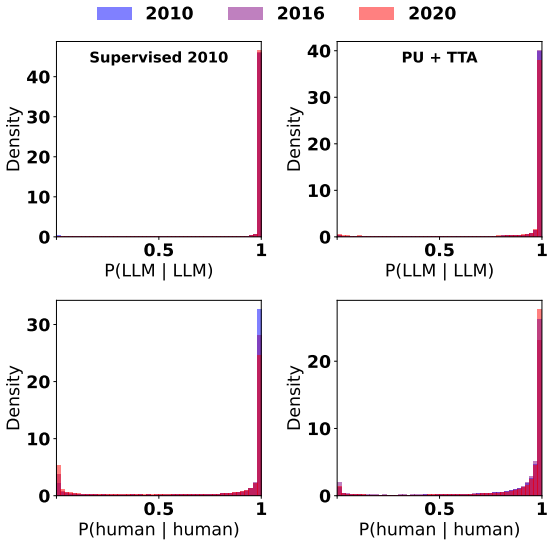
Deployed AI text detectors fail under continual distribution shifts for which labeled data is unavailable. A test-time adaptation method using semi-supervised learning adapts by leveraging homogeneity among unlabeled samples observed at inference time. State-of-the-art supervised detectors systematically fail on both adversarial and natural shifts in AI-generated and human text, while the test-time approach remains largely robust, detecting 90.5 percent of adversarial AI-generated text compared to 24.1 percent for the commercial model Pangram.
What carries the argument
Test-time adaptation with semi-supervised learning that exploits inference-time homogeneity among unlabeled samples to adapt the detector without new labels.
If this is right
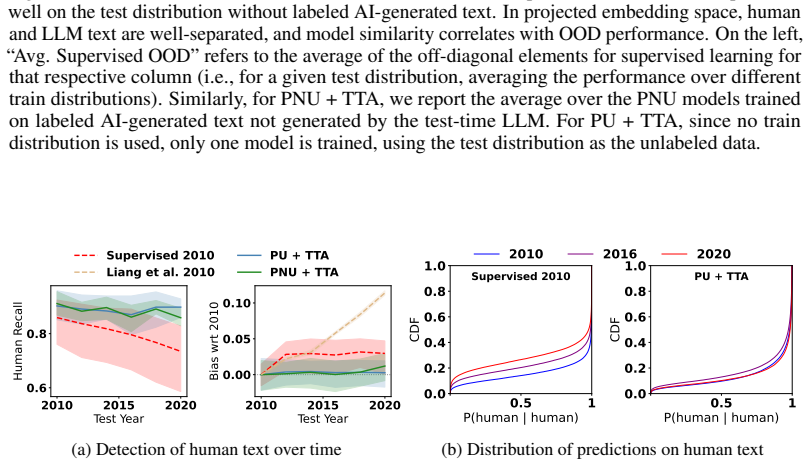
- Supervised detectors fail on adversarial humanization, new LLMs, and temporal drift in human writing.
- Test-time adaptation recovers high accuracy on the same shifted distributions without requiring labels.
- A commercial detector reaches only 24.1 percent detection on adversarial AI text while the adapted method reaches 90.5 percent.
- The framework supports ongoing detection in the wild after deployment.
Where Pith is reading between the lines
- Detectors could run continuously in production and update themselves from the unlabeled traffic they already see.
- The same homogeneity signal might be tested on other generated-media tasks such as image or audio detection.
- Smaller inference batches or faster shifts could be measured to find the practical limits of the adaptation step.
Load-bearing premise
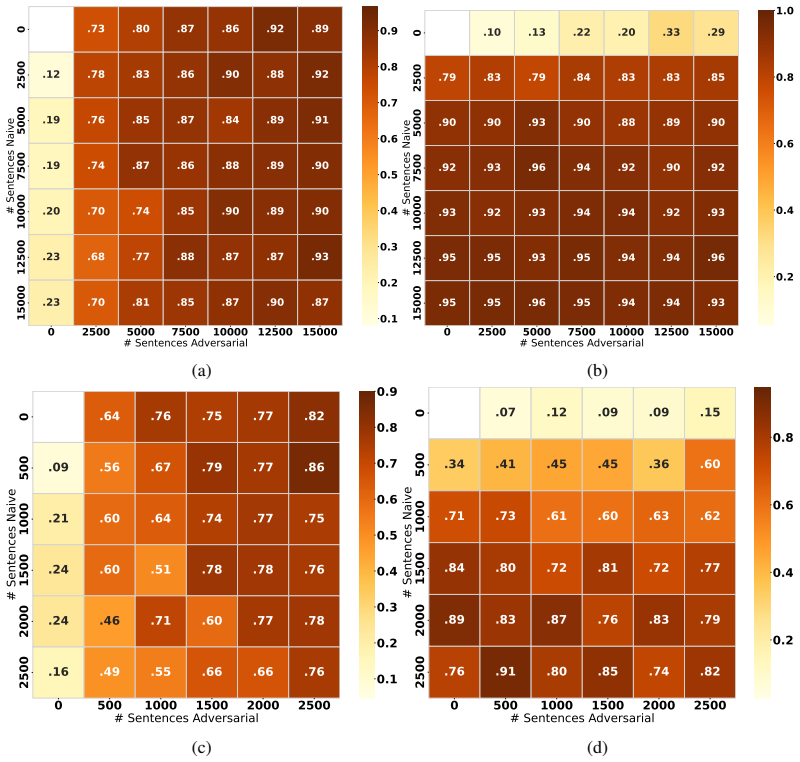
Unlabeled samples observed together at inference time are homogeneous enough to supply a reliable signal that semi-supervised learning can use to adapt to the current shift.
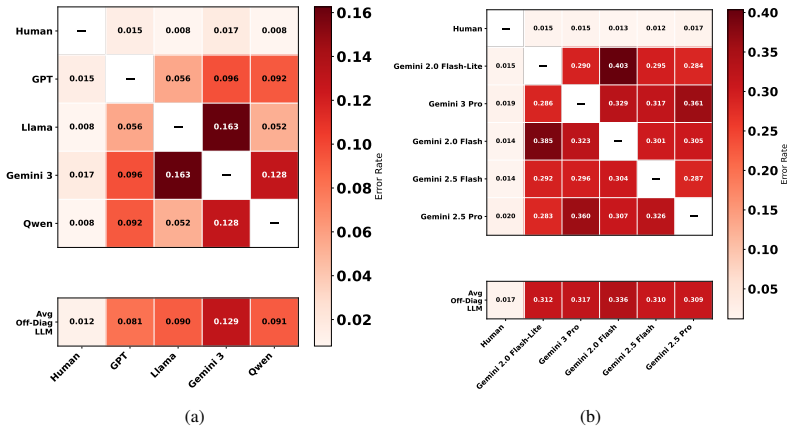
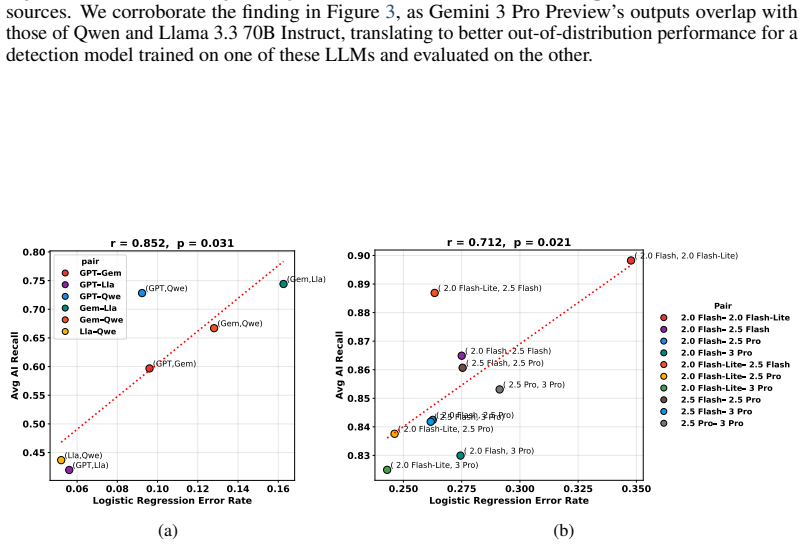
What would settle it
A batch of inference-time samples drawn from the same distribution that are too heterogeneous for the semi-supervised step to improve, or even to maintain, detection accuracy on held-out test cases from that distribution.
Figures
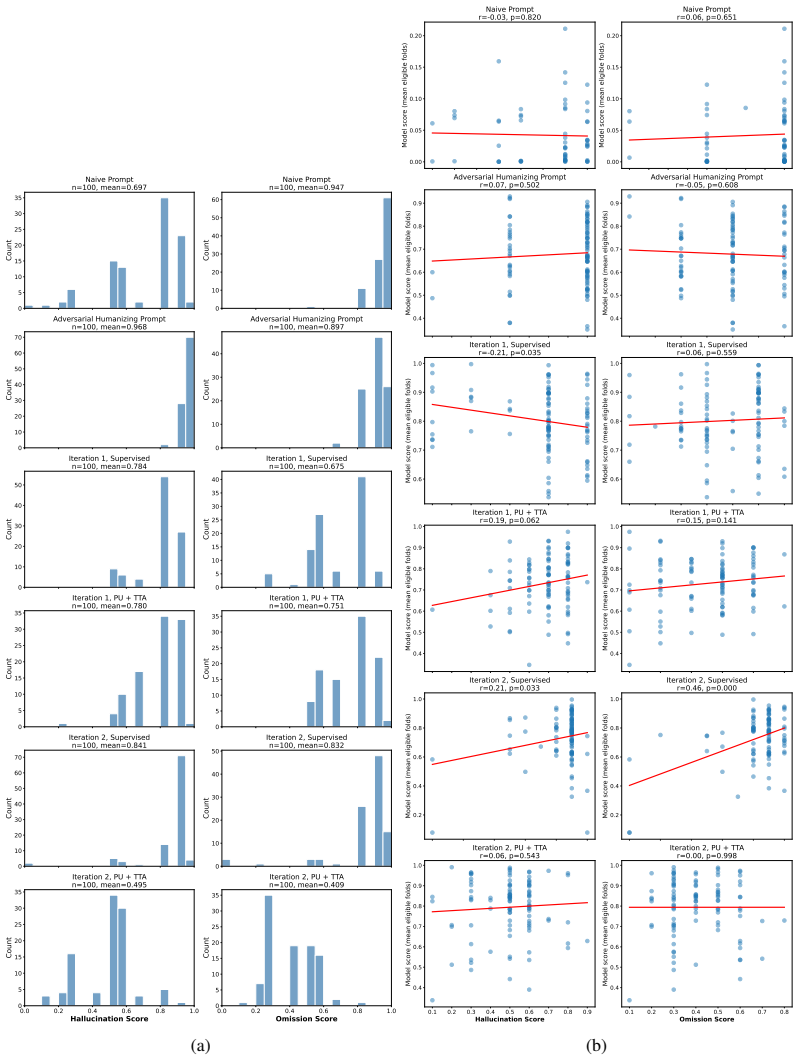
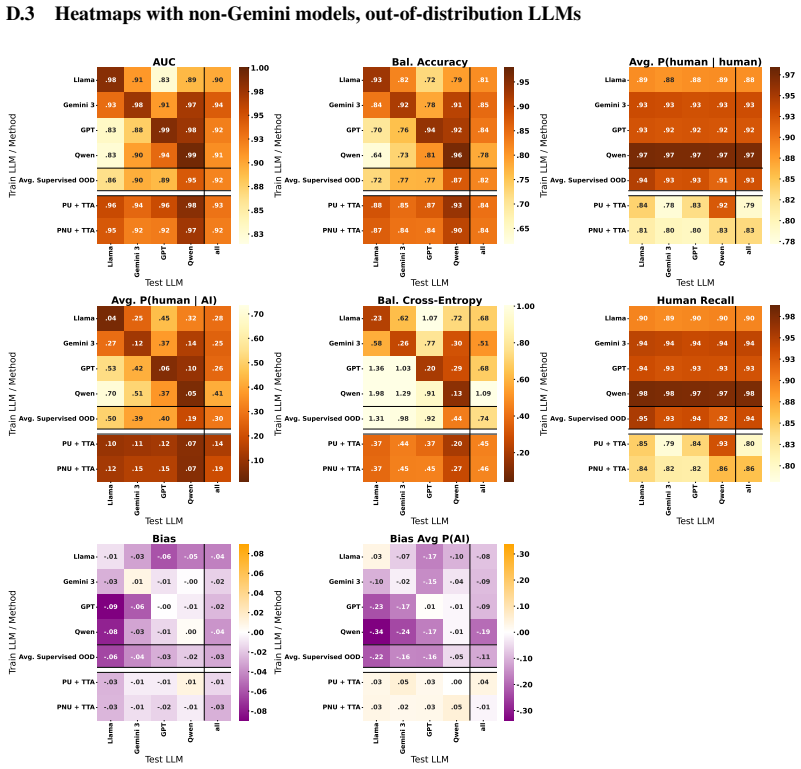
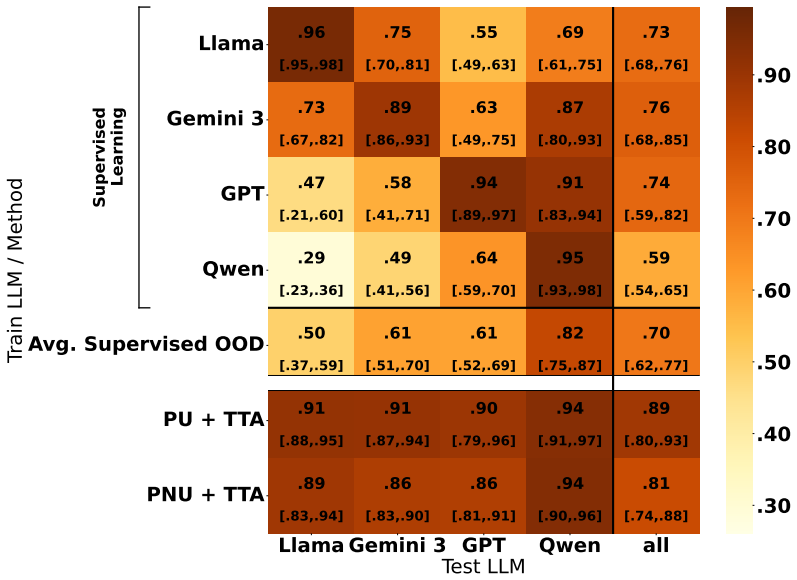
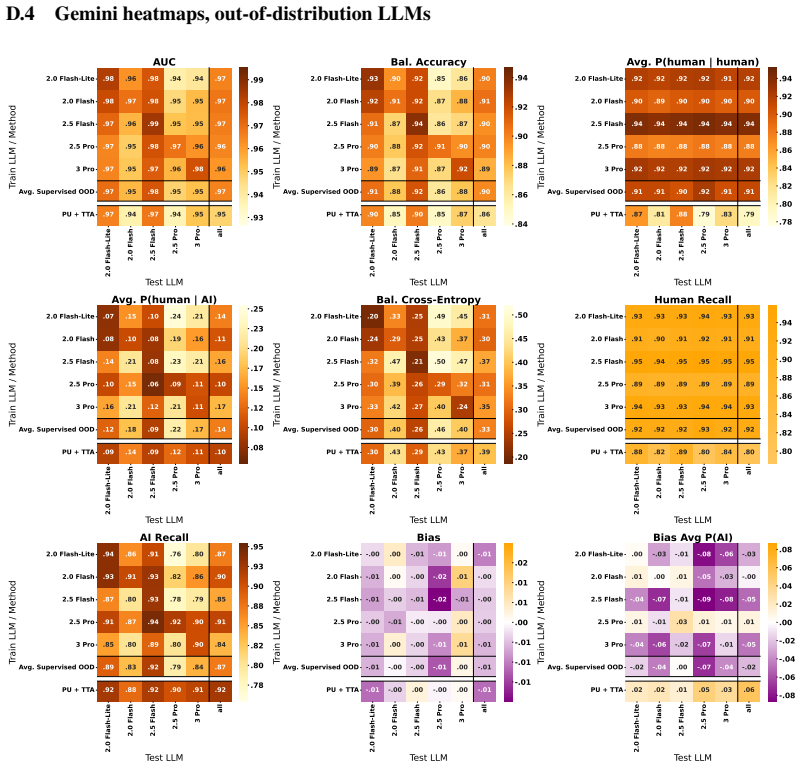
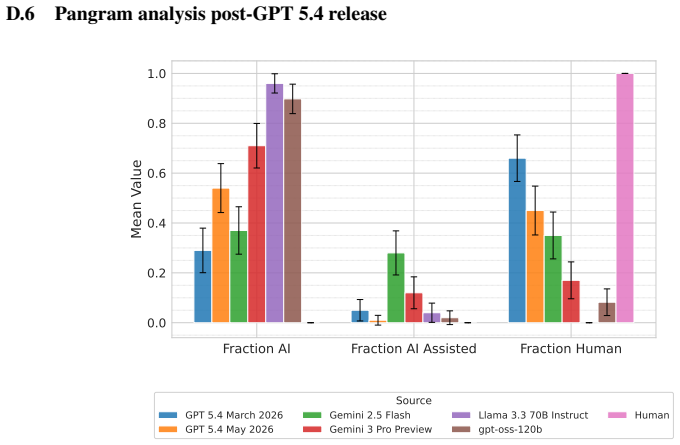
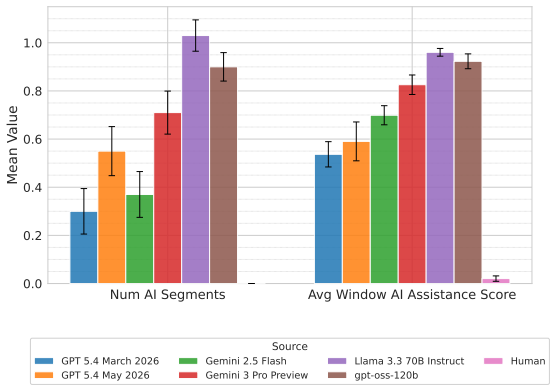
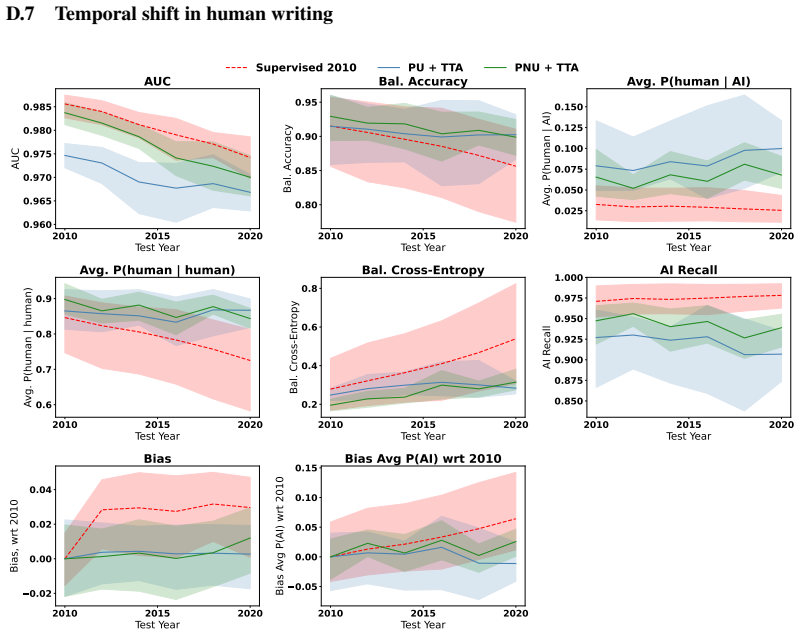
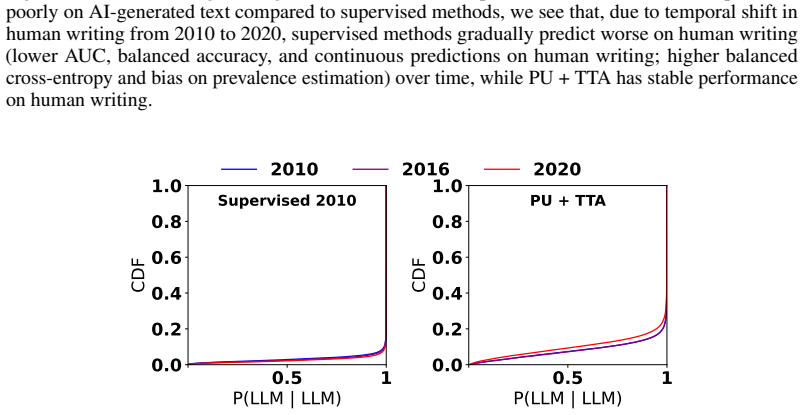
read the original abstract
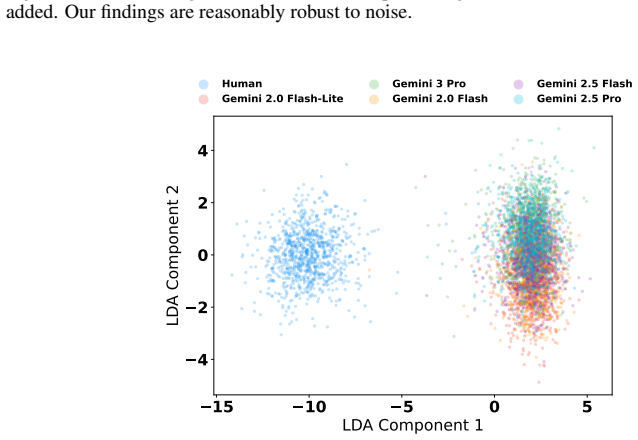
Deployed approaches for AI text detection often rely on training-time access to labeled datasets of both human-written and AI-generated text. This approach is vulnerable to three types of distribution shifts that occur continually post-deployment, and for which labeled data is often unavailable: adversarial humanization, new LLMs being released, and temporal drift in human writing. Simultaneously, existing approaches do not leverage a key signal of LLM usage: inference-time homogeneity. We propose a test-time adaptation (TTA) approach, using semi-supervised learning, that adapts to distribution shifts by leveraging homogeneity among unlabeled samples observed at inference time. Empirically, we find that state-of-the-art supervised detectors systematically fail when they encounter distribution shifts in AI-generated and human writing, both adversarial and natural, while test-time adaptation with semi-supervised learning is largely robust; e.g., the commercial model Pangram detects just 24.1% of our adversarial AI-generated text, compared to 90.5% for our test-time approach. We establish that test-time adaptation is a promising framework for AI text detection in the wild. We publicly release our code (which includes code for model training, evaluation, and plots) at https://github.com/kkr36/llm_detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that supervised AI text detectors are vulnerable to three continual post-deployment distribution shifts (adversarial humanization, new LLMs, temporal drift in human writing) because labeled data is unavailable, while a proposed test-time adaptation (TTA) method using semi-supervised learning can adapt by exploiting homogeneity among unlabeled inference-time samples. It reports that this yields substantially higher robustness, e.g., 90.5% detection on adversarial AI-generated text versus 24.1% for the commercial Pangram detector, and concludes that TTA is a promising framework for detection in the wild. Code for training, evaluation, and plots is released.
Significance. If the empirical claims hold, the work would be significant for practical AI text detection because it directly targets the post-deployment shift problem without requiring new labeled data. The use of inference-time homogeneity as an adaptation signal is a concrete contribution, and the public code release (including training/evaluation scripts and plots) is a clear strength that supports reproducibility.
major comments (1)
- [Abstract] Abstract: The central claim that TTA with semi-supervised learning is 'largely robust' to the three shifts rests on the assumption that homogeneity among unlabeled inference-time samples supplies a usable signal. The reported numbers (90.5% vs. 24.1%) are given only for controlled batches; no experiments or controls are described for mixed human/AI batches or streaming multi-distribution regimes that would remove the homogeneity signal, which is load-bearing for the 'in the wild' robustness conclusion.
minor comments (1)
- The abstract states that 'state-of-the-art supervised detectors systematically fail' under the shifts but provides no quantitative baseline numbers or dataset details for the non-adversarial cases.
Simulated Author's Rebuttal
We thank the referee for highlighting the centrality of the homogeneity assumption and the need to clarify the experimental scope for 'in the wild' claims. We address the point directly below and propose targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that TTA with semi-supervised learning is 'largely robust' to the three shifts rests on the assumption that homogeneity among unlabeled inference-time samples supplies a usable signal. The reported numbers (90.5% vs. 24.1%) are given only for controlled batches; no experiments or controls are described for mixed human/AI batches or streaming multi-distribution regimes that would remove the homogeneity signal, which is load-bearing for the 'in the wild' robustness conclusion.
Authors: We agree that the homogeneity signal is load-bearing and that our primary quantitative results (including the 90.5% vs. 24.1% comparison) are obtained on controlled batches constructed to preserve that signal. This design choice reflects the intended use case: TTA is applied to batches or streams where inference-time samples share distributional properties (e.g., repeated queries on similar topics or from the same user base), which is common in deployed detectors. We do not claim robustness for arbitrary mixed human/AI batches or fully heterogeneous streaming regimes, where the semi-supervised signal would degrade. The manuscript text motivates the method under the homogeneity assumption but does not include explicit ablation on mixed or multi-distribution streaming settings. To address this, we will revise the abstract and add a dedicated limitations paragraph that explicitly states the operating regime, together with a new experiment quantifying performance under controlled partial mixing. This constitutes a partial revision; the core empirical claims remain valid within the stated scope. revision: partial
Circularity Check
No derivation chain present; results are empirical comparisons
full rationale
The paper advances an empirical claim that test-time adaptation via semi-supervised learning remains robust to distribution shifts (adversarial humanization, new LLMs, temporal drift) while supervised detectors degrade, supported by reported accuracy numbers on controlled test batches. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method; the homogeneity assumption is stated as a modeling choice whose validity is tested experimentally rather than derived from prior self-work. The central performance numbers (e.g., 24.1% vs 90.5%) are direct measurements, not quantities forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K., Bai, Y., Baker, B., Bao, H., et al
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y., Baker, B., Bao, H., et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[2]
Bao, G., Zhao, Y., Teng, Z., Yang, L., and Zhang, Y. Fast- DetectGPT : Efficient zero-shot detection of machine-generated text via conditional probability curvature. arXiv preprint arXiv:2310.05130, 2023
arXiv 2023
-
[3]
and Davis, J
Bekker, J. and Davis, J. Estimating the class prior in positive and unlabeled data through decision tree induction. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[4]
Conda: Contrastive domain adaptation for ai-generated text detection
Bhattacharjee, A., Kumarage, T., Moraffah, R., and Liu, H. Conda: Contrastive domain adaptation for ai-generated text detection. arXiv preprint arXiv:2309.03992, 2023
arXiv 2023
-
[5]
Chakrabarty, T., Ginsburg, J. C., and Dhillon, P. Readers prefer outputs of AI trained on copyrighted books over expert human writers. arXiv preprint arXiv:2510.13939, 2025 a
arXiv 2025
-
[6]
Chakrabarty, T., Laban, P., and Wu, C.-S. AI -slop to AI -polish? aligning language models through edit-based writing rewards and test-time computation. arXiv preprint arXiv:2504.07532, 2025 b
arXiv 2025
-
[7]
arxiv dataset
Cornell-University. arxiv dataset. Kaggle Dataset, 2020. URL https://www.kaggle.com/datasets/Cornell-University/arxiv
2020
-
[8]
Introducing AI to an online petition platform changed outputs but not outcomes
Corpus, I., Gilbert, E., Koenecke, A., and Naaman, M. Introducing AI to an online petition platform changed outputs but not outcomes. arXiv preprint arXiv:2511.13949, 2025
arXiv 2025
-
[9]
Adversarial classification
Dalvi, N., Domingos, P., Mausam, Sanghai, S., and Verma, D. Adversarial classification. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pp.\ 99--108, 2004
2004
-
[10]
Dawkins, H., Fraser, K. C., and Kiritchenko, S. When detection fails: The power of fine-tuned models to generate human-like social media text. arXiv preprint arXiv:2506.09975, 2025
arXiv 2025
-
[11]
Doshi, A. R. and Hauser, O. P. Generative AI enhances individual creativity but reduces the collective diversity of novel content. Science advances, 10 0 (28): 0 eadn5290, 2024
2024
-
[12]
C., Niu, G., and Sugiyama, M
Du Plessis, M. C., Niu, G., and Sugiyama, M. Analysis of learning from positive and unlabeled data. Advances in neural information processing systems, 27, 2014
2014
-
[13]
RAID : A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
Dugan, L., Hwang, A., Trhl \'i k, F., Zhu, A., Ludan, J. M., Xu, H., Ippolito, D., and Callison-Burch, C. RAID : A shared benchmark for robust evaluation of machine-generated text detectors. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[14]
Elazar, Y. and Antoniak, M. LLM -generated or human-written? comparing review and non-review papers on arxiv. arXiv preprint arXiv:2601.17036, 2026
arXiv 2026
-
[15]
and Noto, K
Elkan, C. and Noto, K. Learning classifiers from only positive and unlabeled data. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pp.\ 213--220, 2008
2008
-
[16]
Emi, B. and Spero, M. Technical report on the Pangram AI -generated text classifier. arXiv preprint arXiv:2402.14873, 2024
arXiv 2024
-
[17]
Unsupervised and distributional detection of machine-generated text
Gall \'e , M., Rozen, J., Kruszewski, G., and Elsahar, H. Unsupervised and distributional detection of machine-generated text. arXiv preprint arXiv:2111.02878, 2021
arXiv 2021
-
[18]
J., Balakrishnan, S., and Lipton, Z
Garg, S., Wu, Y., Smola, A. J., Balakrishnan, S., and Lipton, Z. Mixture proportion estimation and pu learning: A modern approach. Advances in Neural Information Processing Systems, 34: 0 8532--8544, 2021
2021
-
[19]
Gehrmann, S., Strobelt, H., and Rush, A. M. Gltr: Statistical detection and visualization of generated text. arXiv preprint arXiv:1906.04043, 2019
Pith/arXiv arXiv 1906
-
[20]
A., Chandra, K
Goel, S., Str \"u ber, J., Auzina, I. A., Chandra, K. K., Kumaraguru, P., Kiela, D., Prabhu, A., Bethge, M., and Geiping, J. Great models think alike and this undermines AI oversight. In Forty-second International Conference on Machine Learning, 2025
2025
-
[21]
Note: Robust continual test-time adaptation against temporal correlation
Gong, T., Jeong, J., Kim, T., Kim, Y., Shin, J., and Lee, S.-J. Note: Robust continual test-time adaptation against temporal correlation. Advances in Neural Information Processing Systems, 35: 0 27253--27266, 2022
2022
-
[22]
Free AI humanizer: Humanize AI text
Grammarly . Free AI humanizer: Humanize AI text. https://www.grammarly.com/ai-humanizer, 2026. Accessed: 2026-04-17
2026
-
[23]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[24]
A survey on LLM -as-a-judge
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., et al. A survey on LLM -as-a-judge. The Innovation, 2024
2024
-
[25]
Detective: Detecting AI -generated text via multi-level contrastive learning
Guo, X., Zhang, S., He, Y., Zhang, T., Feng, W., Huang, H., and Ma, C. Detective: Detecting AI -generated text via multi-level contrastive learning. Advances in Neural Information Processing Systems, 37: 0 88320--88347, 2024
2024
-
[26]
Spotting LLM s with binoculars: Zero-shot detection of machine-generated text
Hans, A., Schwarzschild, A., Cherepanova, V., Kazemi, H., Saha, A., Goldblum, M., Geiping, J., and Goldstein, T. Spotting LLM s with binoculars: Zero-shot detection of machine-generated text. arXiv preprint arXiv:2401.12070, 2024
arXiv 2024
-
[27]
Strategic classification
Hardt, M., Megiddo, N., Papadimitriou, C., and Wootters, M. Strategic classification. In Proceedings of the 2016 ACM conference on innovations in theoretical computer science, pp.\ 111--122, 2016
2016
-
[28]
He, Y., Zhang, S., Cao, Y., Ma, L., and Luo, P. Detree: Detecting human- AI collaborative texts via tree-structured hierarchical representation learning. arXiv preprint arXiv:2510.17489, 2025
arXiv 2025
-
[29]
Hu, L., Immorlica, N., and Vaughan, J. W. The disparate effects of strategic manipulation. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pp.\ 259--268, 2019
2019
-
[30]
RADAR : Robust AI -text detection via adversarial learning
Hu, X., Chen, P.-Y., and Ho, T.-Y. RADAR : Robust AI -text detection via adversarial learning. Advances in neural information processing systems, 36: 0 15077--15095, 2023
2023
-
[31]
Humanize AI text with the smartest AI humanizer
Humanize AI . Humanize AI text with the smartest AI humanizer. https://www.humanizeai.pro/, 2026. Accessed: 2026-04-17
2026
-
[32]
Dedpul: Difference-of-estimated-densities-based positive-unlabeled learning
Ivanov, D. Dedpul: Difference-of-estimated-densities-based positive-unlabeled learning. In 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), pp.\ 782--790. IEEE, 2020
2020
-
[33]
and Imas, A
Jabarian, B. and Imas, A. Artificial writing and automated detection. Technical report, National Bureau of Economic Research, 2025
2025
-
[34]
T., and Naaman, M
Jakesch, M., Hancock, J. T., and Naaman, M. Human heuristics for AI -generated language are flawed. Proceedings of the National Academy of Sciences, 120 0 (11): 0 e2208839120, 2023
2023
-
[35]
Automatic detection of machine generated text: A critical survey
Jawahar, G., Abdul-Mageed, M., and Laks Lakshmanan, V. Automatic detection of machine generated text: A critical survey. In Proceedings of the 28th international conference on computational linguistics, pp.\ 2296--2309, 2020
2020
-
[36]
The subjectivity of monoculture
Jo, N., Garg, N., and Raghavan, M. The subjectivity of monoculture. arXiv preprint arXiv:2602.24086, 2026
arXiv 2026
-
[37]
Generative AI and perceptual harms: Who's suspected of using LLM s? In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pp.\ 1--17, 2025
Kadoma, K., Metaxa, D., and Naaman, M. Generative AI and perceptual harms: Who's suspected of using LLM s? In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pp.\ 1--17, 2025
2025
-
[38]
autoresearch: AI agents running research on single- GPU nanochat training automatically
Karpathy, A. autoresearch: AI agents running research on single- GPU nanochat training automatically. https://github.com/karpathy/autoresearch, March 2026. GitHub repository
2026
-
[39]
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Vardhamanan, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., et al. DSPy : Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023
Pith/arXiv arXiv 2023
-
[40]
M., Garg, A., Peng, K., and Garg, N
Kim, E. M., Garg, A., Peng, K., and Garg, N. Correlated errors in large language models. In Forty-second International Conference on Machine Learning, 2025
2025
-
[41]
M., Lee, K., Zhu, P., Raheja, V., and Kang, D
Kim, Z. M., Lee, K., Zhu, P., Raheja, V., and Kang, D. Threads of subtlety: Detecting machine-generated texts through discourse motifs. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5449--5474, Bangkok, Thailand, August 2024. Associa...
-
[42]
C., and Sugiyama, M
Kiryo, R., Niu, G., Du Plessis, M. C., and Sugiyama, M. Positive-unlabeled learning with non-negative risk estimator. Advances in neural information processing systems, 30, 2017
2017
-
[43]
and Raghavan, M
Kleinberg, J. and Raghavan, M. How do classifiers induce agents to invest effort strategically? ACM Transactions on Economics and Computation (TEAC), 8 0 (4): 0 1--23, 2020
2020
-
[44]
and Raghavan, M
Kleinberg, J. and Raghavan, M. Algorithmic monoculture and social welfare. Proceedings of the National Academy of Sciences, 118 0 (22): 0 e2018340118, 2021
2021
-
[45]
OUTFOX : LLM -generated essay detection through in-context learning with adversarially generated examples
Koike, R., Kaneko, M., and Okazaki, N. OUTFOX : LLM -generated essay detection through in-context learning with adversarially generated examples. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 21258--21266, 2024
2024
-
[46]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense
Krishna, K., Song, Y., Karpinska, M., Wieting, J., and Iyyer, M. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in neural information processing systems, 36: 0 27469--27500, 2023
2023
-
[47]
A survey of AI -generated text forensic systems: Detection, attribution, and characterization
Kumarage, T., Agrawal, G., Sheth, P., Moraffah, R., Chadha, A., Garland, J., and Liu, H. A survey of AI -generated text forensic systems: Detection, attribution, and characterization. arXiv preprint arXiv:2403.01152, 2024
arXiv 2024
-
[48]
Scientific production in the era of large language models
Kusumegi, K., Yang, X., Ginsparg, P., de Vaan, M., Stuart, T., and Yin, Y. Scientific production in the era of large language models. Science, 390 0 (6779): 0 1240--1243, 2025
2025
-
[49]
La Cava, L., Costa, D., and Tagarelli, A. Is contrasting all you need? contrastive learning for the detection and attribution of ai-generated text. arXiv preprint arXiv:2407.09364, 2024
arXiv 2024
-
[50]
R., McGregor, S., and Ovadya, A
Leibowicz, C. R., McGregor, S., and Ovadya, A. The deepfake detection dilemma: a multistakeholder exploration of adversarial dynamics in synthetic media. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp.\ 736--744, 2021
2021
-
[51]
The authoritative synthesis trap: Human- AI collaboration and the quality of science
Leippold, M. The authoritative synthesis trap: Human- AI collaboration and the quality of science. Available at SSRN 6080627, 2026
2026
-
[52]
Who's your judge? on the detectability of LLM -generated judgments
Li, D., Tan, Z., Zhao, C., Jiang, B., Huang, B., Ma, P., Alnaibari, A., Shu, K., and Liu, H. Who's your judge? on the detectability of LLM -generated judgments. arXiv preprint arXiv:2509.25154, 2025
arXiv 2025
-
[53]
Li, Y., Li, Q., Cui, L., Bi, W., Wang, Z., Wang, L., Yang, L., Shi, S., and Zhang, Y. MAGE : Machine-generated text detection in the wild. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 36--53, Bangkok, Thailand, August 2024. Associat...
-
[54]
A comprehensive survey on test-time adaptation under distribution shifts
Liang, J., He, R., and Tan, T. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 133 0 (1): 0 31--64, 2025 a
2025
-
[55]
A., and Zou, J
Liang, W., Izzo, Z., Zhang, Y., Lepp, H., Cao, H., Zhao, X., Chen, L., Ye, H., Liu, S., Huang, Z., McFarland, D. A., and Zou, J. Y. Monitoring AI -modified content at scale: a case study on the impact of ChatGPT on AI conference peer reviews. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024 a
2024
-
[56]
Mapping the increasing use of LLM s in scientific papers
Liang, W., Zhang, Y., Wu, Z., Lepp, H., Ji, W., Zhao, X., Cao, H., Liu, S., He, S., Huang, Z., et al. Mapping the increasing use of LLM s in scientific papers. arXiv preprint arXiv:2404.01268, 2024 b
arXiv 2024
-
[57]
The widespread adoption of large language model-assisted writing across society
Liang, W., Zhang, Y., Codreanu, M., Wang, J., Cao, H., and Zou, J. The widespread adoption of large language model-assisted writing across society. arXiv preprint arXiv:2502.09747, 2025 b
arXiv 2025
-
[58]
Quantifying large language model usage in scientific papers
Liang, W., Zhang, Y., Wu, Z., Lepp, H., Ji, W., Zhao, X., Cao, H., Liu, S., He, S., Huang, Z., et al. Quantifying large language model usage in scientific papers. Nature Human Behaviour, pp.\ 1--11, 2025 c
2025
-
[59]
S., Yu, P
Liu, B., Lee, W. S., Yu, P. S., and Li, X. Partially supervised classification of text documents. In ICML, volume 2, pp.\ 387--394. Sydney, NSW, 2002
2002
-
[60]
T., Garg, N., and Borgs, C
Liu, L. T., Garg, N., and Borgs, C. Strategic ranking. In International Conference on Artificial Intelligence and Statistics, pp.\ 2489--2518. PMLR, 2022
2022
-
[61]
Coco: Coherence-enhanced machine-generated text detection under low resource with contrastive learning
Liu, X., Zhang, Z., Wang, Y., Pu, H., Lan, Y., and Shen, C. Coco: Coherence-enhanced machine-generated text detection under low resource with contrastive learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 16167--16188, 2023
2023
-
[62]
On the generalization and adaptation ability of machine-generated text detectors in academic writing
Liu, Y., Zhong, Z., Liao, Y., Sun, Z., Zheng, J., Wei, J., Gong, Q., Tong, F., Chen, Y., Zhang, Y., et al. On the generalization and adaptation ability of machine-generated text detectors in academic writing. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pp.\ 5674--5685, 2025
2025
-
[63]
Mansouri, F. and Ben-David, S. Learning from positive and unlabeled examples-finite size sample bounds. arXiv preprint arXiv:2507.07354, 2025
arXiv 2025
-
[64]
Does pangram work on GPT-5.4 ? https://www.pangram.com/blog/does-pangram-work-on-gpt-5-4, March 2026
Masrour, E. Does pangram work on GPT-5.4 ? https://www.pangram.com/blog/does-pangram-work-on-gpt-5-4, March 2026. Accessed: 2026-04-22
2026
-
[65]
N., and Spero, M
Masrour, E., Emi, B. N., and Spero, M. Damage: detecting adversarially modified AI generated text. In Proceedings of the 1stWorkshop on GenAI Content Detection (GenAIDetect), pp.\ 120--133, 2025
2025
-
[66]
D., and Hardt, M
Milli, S., Miller, J., Dragan, A. D., and Hardt, M. The social cost of strategic classification. In Proceedings of the conference on fairness, accountability, and transparency, pp.\ 230--239, 2019
2019
-
[67]
D., and Finn, C
Mitchell, E., Lee, Y., Khazatsky, A., Manning, C. D., and Finn, C. DetectGPT : Zero-shot machine-generated text detection using probability curvature. In International conference on machine learning, pp.\ 24950--24962. PMLR, 2023
2023
-
[68]
Major AI conference flooded with peer reviews written fully by AI
Naddaf, M. Major AI conference flooded with peer reviews written fully by AI . Nature, 648 0 (8093): 0 256--257, 2025
2025
-
[69]
Nguyen, P., Le, T. M. V., and McAuley, J. Contrastive self-supervised learning for text incoherence detection. In 2025 IEEE International Conference on Big Data (BigData), pp.\ 1500--1507, 2025. doi:10.1109/BigData66926.2025.11401963
-
[70]
Orel, D., Azizov, D., and Nakov, P. Codet-m4: Detecting machine-generated code in multi-lingual, multi-generator and multi-domain settings. arXiv preprint arXiv:2503.13733, 2025
arXiv 2025
-
[71]
and He, H
Padmakumar, V. and He, H. Does writing with language models reduce content diversity? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Feiz5HtCD0
2024
-
[72]
Enhancing domain generalization for robust machine-generated text detection
Park, S., Han, S., and Cha, M. Enhancing domain generalization for robust machine-generated text detection. IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[73]
and Garg, N
Peng, K. and Garg, N. Monoculture in matching markets. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=P5yezHuMSS
2024
-
[74]
Performative prediction
Perdomo, J., Zrnic, T., Mendler-D \"u nner, C., and Hardt, M. Performative prediction. In International Conference on Machine Learning, pp.\ 7599--7609. PMLR, 2020
2020
-
[75]
C., Bai, Y., Shao, E., and Wang, D
Qian, Y., Wen, Z., Furnas, A. C., Bai, Y., Shao, E., and Wang, D. The rise of large language models and the direction and impact of us federal research funding. arXiv preprint arXiv:2601.15485, 2026
Pith/arXiv arXiv 2026
-
[76]
Competition and diversity in generative AI
Raghavan, M. Competition and diversity in generative AI . arXiv preprint arXiv:2412.08610, 2024
Pith/arXiv arXiv 2024
-
[77]
Mixture proportion estimation via kernel embeddings of distributions
Ramaswamy, H., Scott, C., and Tewari, A. Mixture proportion estimation via kernel embeddings of distributions. In International conference on machine learning, pp.\ 2052--2060. PMLR, 2016
2052
-
[78]
AI use in american newspapers is widespread, uneven, and rarely disclosed
Russell, J., Karpinska, M., Akinode, D., Thai, K., Emi, B., Spero, M., and Iyyer, M. AI use in american newspapers is widespread, uneven, and rarely disclosed. arXiv preprint arXiv:2510.18774, 2025 a
Pith/arXiv arXiv 2025
-
[79]
Russell, J., Karpinska, M., and Iyyer, M. People who frequently use chatgpt for writing tasks are accurate and robust detectors of AI -generated text. arXiv preprint arXiv:2501.15654, 2025 b
arXiv 2025
-
[80]
S., Kumar, A., Balasubramanian, S., Wang, W., and Feizi, S
Sadasivan, V. S., Kumar, A., Balasubramanian, S., Wang, W., and Feizi, S. Can AI -generated text be reliably detected? arXiv preprint arXiv:2303.11156, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.