MIRTH: Mutual-Information Reasoning with Temporal Hubs for Vision-Language-Action Agents
Pith reviewed 2026-07-01 05:34 UTC · model grok-4.3
The pith
MIRTH augments vision-language-action models with dual-scale temporal memory hubs and mutual-information optimized latent reasoning tokens to reach stronger robotic performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
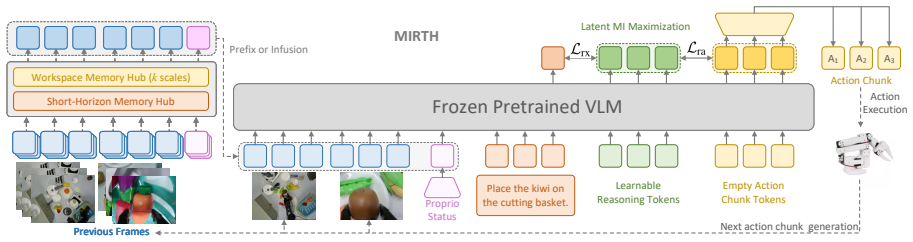
MIRTH augments a pretrained VLA backbone with dual-scale temporal memory hubs that compress long-term scene evolution and short-term motion trends into compact embeddings, latent reasoning tokens optimized via a mutual-information objective to carve out a semantic plan space aligning multimodal context with action trajectories, and a parallel action decoding scheme that replaces autoregressive generation with vector-wise prediction, leading to state-of-the-art performance on simulation benchmarks and real-world platforms with emergent error recovery capabilities.
What carries the argument
Dual-scale temporal memory hubs paired with mutual-information optimized latent reasoning tokens that compress dynamics and align multimodal context to action trajectories.
If this is right
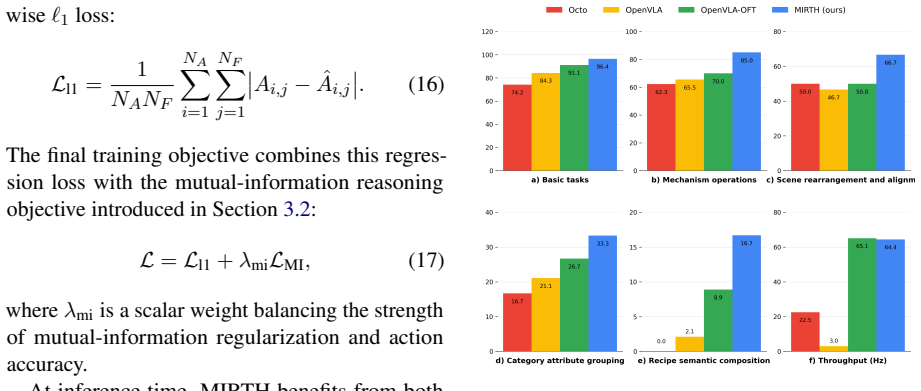
- State-of-the-art performance on simulation benchmarks for vision-language-action tasks
- Emergent error recovery capabilities observed on real-world robotic platforms
- Increased control throughput from replacing autoregressive scalar decoding with parallel vector-wise prediction
- Better bridging of high-level instructions to low-level motor commands through the semantic plan space
Where Pith is reading between the lines
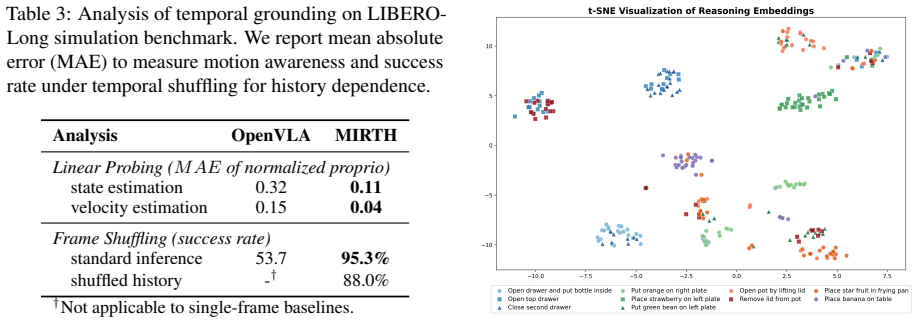
- The memory hubs could support scaling to tasks with longer time horizons by keeping history compact without full sequence replay
- Parallel decoding might allow higher rate control in fast-changing environments where sequential generation would lag
- Error recovery behavior could lower the cost of deploying agents by reducing the need for constant human intervention when small mistakes occur
Load-bearing premise
The dual-scale temporal memory hubs and mutual-information optimized latent reasoning tokens will align multimodal context with action trajectories without losing critical information or introducing optimization instabilities.
What would settle it
Running the augmented model on standard robotic control benchmarks and observing no improvement over the pretrained baseline or no error recovery behavior in physical trials.
Figures


read the original abstract
VLA models have emerged as a powerful paradigm for transferring semantic knowledge from web-scale data to physical robotic control. However, current single-frame architectures suffer from intrinsic limitations: temporal myopia that discards historical dynamics, reasoning gaps between high-level instructions and low-level motor commands, and inference inefficiency due to autoregressive scalar decoding. In this work, we propose MIRTH, a unified framework designed to address these challenges. MIRTH augments a pretrained VLA backbone with three key innovations: (1) dual-scale temporal memory hubs that compress long-term scene evolution and short-term motion trends into compact embeddings; (2) latent reasoning tokens optimized via a mutual-information objective carving out a semantic plan space to align multimodal context with action trajectories; and (3) a parallel action decoding scheme that replaces autoregressive generation with vector-wise prediction to maximize control throughput. Extensive evaluations on the LIBERO simulation benchmark and a real-world LeRobot platform demonstrate that MIRTH achieves state-of-the-art performance and exhibiting emergent error recovery capabilities. The codes and collected datasets are released at http://github.com/kiva12138/mirth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MIRTH, a framework augmenting pretrained vision-language-action (VLA) backbones with three components: dual-scale temporal memory hubs that compress long-term scene evolution and short-term motion trends into embeddings; latent reasoning tokens optimized via a mutual-information objective to align multimodal context with action trajectories; and parallel (non-autoregressive) action decoding for throughput. It reports state-of-the-art results plus emergent error recovery on the LIBERO benchmark and a real-world LeRobot platform, with code and datasets released.
Significance. If the empirical claims hold, the work could advance VLA agents by mitigating temporal myopia and reasoning gaps between instructions and motor commands. The mutual-information objective and dual-scale hubs constitute a concrete attempt to create an explicit semantic plan space; the parallel decoding addresses a practical efficiency bottleneck. Open-sourcing code and data is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The central claims of SOTA performance and emergent error recovery rest on the dual-scale temporal hubs and mutual-information objective, yet no equations, definitions of the hubs, or optimization details are supplied. Without these it is impossible to verify whether the mutual-information term supplies independent grounding or simply reduces to quantities already fitted by the backbone.
- [Experiments] Experiments: The SOTA and error-recovery assertions are stated without reference to any tables, ablation results, statistical tests, or protocol details on LIBERO or LeRobot. This absence directly undermines assessment of whether the architectural additions are load-bearing for the reported gains.
minor comments (1)
- [Abstract] Abstract: The sentence 'demonstrate that MIRTH achieves state-of-the-art performance and exhibiting emergent error recovery capabilities' contains a grammatical inconsistency; 'exhibiting' should be 'exhibits'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central claims of SOTA performance and emergent error recovery rest on the dual-scale temporal hubs and mutual-information objective, yet no equations, definitions of the hubs, or optimization details are supplied. Without these it is impossible to verify whether the mutual-information term supplies independent grounding or simply reduces to quantities already fitted by the backbone.
Authors: We agree that the submitted manuscript does not include explicit equations or formal definitions for the dual-scale temporal memory hubs or the mutual-information objective. The abstract and methods sections describe the components at a high level only. In the revised version we will add the precise mathematical formulations, including the embedding definitions for long-term scene evolution and short-term motion trends, the MI loss expression, and the optimization procedure, so that readers can assess whether the MI term provides independent grounding beyond the backbone. revision: yes
-
Referee: [Experiments] Experiments: The SOTA and error-recovery assertions are stated without reference to any tables, ablation results, statistical tests, or protocol details on LIBERO or LeRobot. This absence directly undermines assessment of whether the architectural additions are load-bearing for the reported gains.
Authors: The current manuscript text states the performance claims without explicit table references, ablation breakdowns, or protocol details. We will revise the experiments section to include numbered citations to all result tables, component-wise ablations, statistical significance tests, and full evaluation protocols for both LIBERO and the LeRobot platform, making clear the contribution of each proposed module. revision: yes
Circularity Check
No circularity identified; analysis limited by absence of equations or derivations
full rationale
The supplied paper text consists solely of an abstract describing high-level components (dual-scale temporal memory hubs, mutual-information optimized latent reasoning tokens, parallel action decoding) without any equations, mathematical derivations, self-citations, or fitted-parameter details. No load-bearing step can be quoted or shown to reduce to its inputs by construction, as required by the analysis rules. The performance claims are presented as empirical results on benchmarks rather than derived predictions, rendering the derivation chain self-contained by default.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Helios: Hierarchical exploration for language- grounded interaction in open scenes.arXiv preprint arXiv:2509.22498. Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jas- mine Hsu, and 1 others. 2022. Rt-1: Robotics trans- former for real-world control at scal...
-
[2]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag San- keti, and 1 others. 2024. Openvla: An open- source vision-language-action model.arXiv preprint arXiv:2406.0...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Representation Learning with Contrastive Predictive Coding
Octo: An open-source generalist robot policy. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024. Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, V...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Viorica P ˘atr˘aucean, Xu Owen He, Joseph Heyward, Chuhan Zhang, Mehdi S
PO-GUISE+: Pose and object guided trans- former token selection for efficient driver action recognition.IEEE Transactions on Intelligent Trans- portation Systems. Viorica P ˘atr˘aucean, Xu Owen He, Joseph Heyward, Chuhan Zhang, Mehdi S. M. Sajjadi, George- Cristian Muraru, Artem Zholus, Mahdi Karami, Ross Goroshin, Yutian Chen, Simon Osindero, João Car- r...
-
[5]
InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 284–293
Long-term feature banks for detailed video understanding. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 284–293. Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pa...
2023
-
[6]
Scalar-wise decoding (standard VLA): Each token represents a single scalar action dimension. •N=T×F . (e.g., for T= 10, F= 6 , we require 60 tokens in context model- ing). • The model autoregressively predicts dis- cretized bins or scalar values for each degree of freedom sequentially
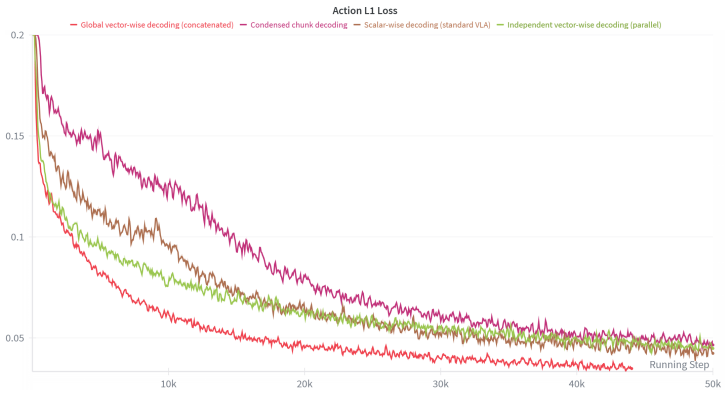
-
[7]
Global vector-wise decoding (concate- nated):Each token represents a single timestep, and the entire sequence is projected jointly. •N=T. • We flatten the hidden states of all timesteps into a single vector and ap- ply a global projection matrix Wglobal ∈ R(T·D)×(T·F) : ˆAflat =W global ·flatten(H)(19) where flatten(H)∈R T·D is the flattened representatio...
-
[8]
Independent vector-wise decoding (paral- lel):Each token represents a single timestep, but is projected independently. •N=T. • A shared projection matrix Wsep ∈ RD×F is applied to each token’s hidden stateh t in parallel: ˆat =W sep·ht, t∈ {1, . . . , T}.(20)
-
[9]
Condensed chunk decoding:A single token represents the entire trajectory chunk. •N= 1. • The single hidden state H∈R D is pro- jected to the full trajectory via Wchunk ∈ RD×(T·F) : ˆAflat =W chunk ·H.(21) In our experiments, we observe significant dif- ferences in convergence dynamics among these paradigms (but with comparable final performance). As visua...
-
[10]
Basic Tasks Place the banana in the plate on the right 50 Place the brown kiwi on the cutting board 50 Place the carrot in the plate on the left 50 Place the star fruit in the white frying pan 50
-
[11]
Mechanism Operations Open the top drawer of the four-drawer cabinet 50 Close the second drawer of the four-drawer cabinet 50 Open the top drawer, place the spatula inside it, and close the drawer 50 Open the second drawer, put the banana into it, and close the drawer 50
-
[12]
Scene Rearrange Empty the small bucket onto the cutting board 50 Swap all items currently on the left white plate with the items on the right white plate 50 Clear the white frying pan by moving any items inside it onto the cutting board, leaving the frying pan empty 50 Clean up the workspace by moving all fruits onto the left white plate and all vegetable...
-
[13]
Category Reasoning Put all fruits except the banana into the white frying pan 50 Clear the cooking area: move all food items off the cutting board and leave only tools on the cutting board 50 Place all vegetables except the corn with green leaves into the pot with the dark lid 50 Move any fruits that are directly on the table into the pot with the dark li...
-
[14]
Group Validation Instructions
Semantic Recipe Prepare ingredients for a simple vegetable scramble by placing the raw egg, carrot, green bean, and yellow bell pepper onto the cutting board, and leave all fruits where they are 50 Prepare ingredients for a fruit yogurt by placing the strawberry, kiwi, apple pieces, and banana into the white frying pan 50 Prepare a ’breakfast plate’ by pl...
-
[15]
Basic TasksPut the carrot on the cutting board
-
[16]
Mechanism OpsOpen the second drawer, place the soup spoon inside, and then close it
-
[17]
Scene Rearrange Organize the tools by placing the spatula, spoon, and strainer together in front of the cabinet
-
[18]
Category Reasoning Place all red items (apple, strawberry, red bottle) onto the left white plate and all green items onto the cutting board
-
[19]
Semantic Recipe Prepare a ’healthy dinner’ set by placing the corn, carrot, and eggplant into the pot with the dark lid, while keeping the fruits on the table
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.