LATERN: Test-Time Context-Aware Explainable Video Anomaly Detection
Pith reviewed 2026-06-30 21:17 UTC · model grok-4.3
The pith
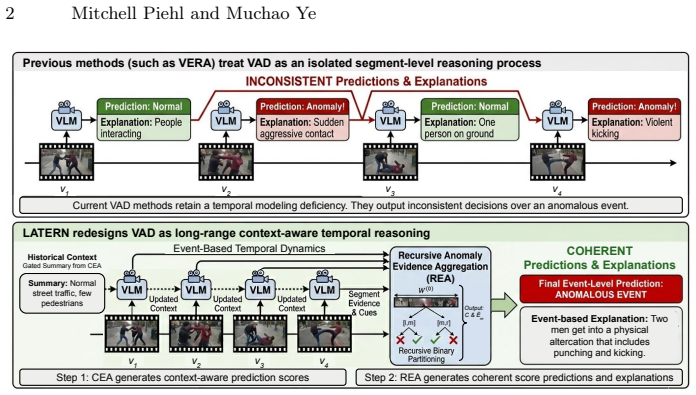
LATERN turns video anomaly detection into temporal evidence aggregation so frozen vision-language models can score anomalies against evolving context instead of isolated segments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
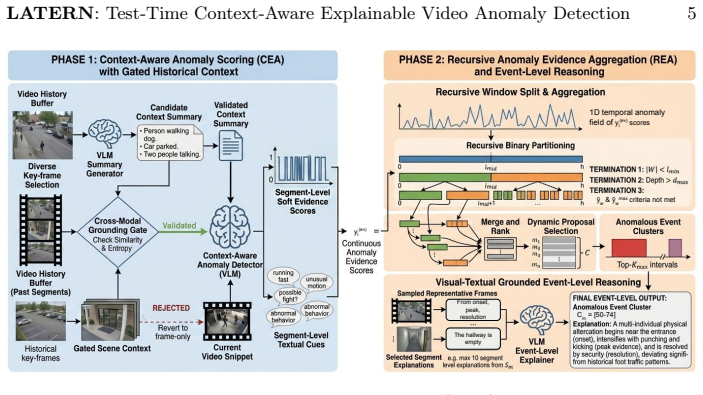
LATERN consists of Context-Aware Anomaly Scoring (CEA), which uses an image-grounded memory mechanism to select historical frames by frame diversity and visual-textual alignment as expanded context for generating reliable anomaly scores, and Recursive Evidence Aggregation (REA), which performs recursive temporal aggregation on those scores to identify coherent anomaly intervals and produce event-level decisions and explanations grounded in visual-textual evidence.
What carries the argument
The image-grounded memory mechanism inside the Context-Aware Anomaly Scoring (CEA) module, which selects and stores historical frames according to diversity and alignment criteria to supply temporal context for anomaly scoring.
If this is right
- Anomaly detection accuracy increases on UCF-Crime and XD-Violence benchmarks.
- Explanation consistency improves and outputs shift from fragmented segment predictions to temporally coherent event-level decisions.
- The framework works at test time with frozen VLMs and requires no retraining.
- Event-level explanations become grounded in aggregated visual-textual evidence rather than single-segment reasoning.
Where Pith is reading between the lines
- The same memory-selection idea could be tested on other token-constrained video tasks such as long-form action recognition or video question answering.
- If the memory mechanism proves robust, it offers a lightweight way to add temporal awareness to any VLM pipeline limited by context length.
- Future work could measure how the diversity and alignment criteria interact when anomaly events span very different time scales.
Load-bearing premise
Selectively choosing historical content via frame diversity and visual-textual alignment will reliably expand context enough to produce accurate anomaly scores.
What would settle it
On a long video containing a gradual anomaly, run both standard segment-level VLM inference and LATERN; if the memory-selected frames omit the transition period and LATERN scores remain no better than the baseline, the memory mechanism does not expand context as claimed.
Figures

read the original abstract
Vision-language models (VLMs) have recently emerged as a promising paradigm for video anomaly detection (VAD) due to their strong visual reasoning ability and natural language-based explainability. In this paper, we aim to address a key limitation of such pipelines, which perform segment-level inference independently owing to token constraints and reason without structured temporal context, allowing VLMs to interpret anomalies as deviations from evolving video dynamics rather than producing fragmented predictions and explanations. To specify, we propose a context-aware framework named LATERN, which reformulates VAD as a temporal evidence aggregation process. LATERN consists of two complementary modules: Context-Aware Anomaly Scoring (CEA) and Recursive Evidence Aggregation (REA). CEA introduces a novel image-grounded memory mechanism, which selectively chooses historical content via frame diversity and visual-textual alignment as expanded context to help generate reliable anomaly scores. Building upon these scores, REA performs recursive temporal aggregation to identify coherent anomaly intervals and produce event-level decisions and explanations grounded in visual-textual evidence. Extensive experiments on challenging benchmarks, including UCF-Crime and XD-Violence, show that LATERN enhances detection accuracy and explanation consistency for frozen VLMs during test time, while generating temporally coherent and semantically grounded event-level explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LATERN, a test-time context-aware framework for explainable video anomaly detection with frozen VLMs. It reformulates VAD as temporal evidence aggregation via two modules: Context-Aware Anomaly Scoring (CEA), which uses an image-grounded memory mechanism to select historical frames by diversity and visual-textual alignment for expanded context in anomaly scoring, and Recursive Evidence Aggregation (REA), which performs recursive temporal aggregation to produce coherent event-level decisions and explanations. The abstract claims that extensive experiments on UCF-Crime and XD-Violence demonstrate enhanced detection accuracy and explanation consistency.
Significance. If the CEA memory selection and REA aggregation mechanisms can be shown to reliably improve anomaly scores and coherence over segment-independent inference, the work would address a genuine limitation in current VLM-based VAD pipelines and offer a practical test-time approach for temporally grounded explanations.
major comments (2)
- [Abstract] Abstract: the assertion of performance gains on UCF-Crime and XD-Violence is unsupported by any quantitative results, baselines, ablation studies, or error analysis, making it impossible to evaluate whether the CEA or REA mechanisms deliver the claimed improvements.
- [CEA module description] CEA module (image-grounded memory mechanism): the claim that selecting historical frames via frame diversity and visual-textual alignment reliably expands useful context (rather than noise or redundant tokens under VLM length limits) is presented without implementation details, justification, or evidence of correlation with true temporal evidence; this assumption is load-bearing for both the accuracy gains and the downstream REA coherence.
minor comments (1)
- [Abstract] Abstract: the description of the anomaly scoring process and the specific VLM backbone could be clarified to allow readers to assess compatibility with existing VAD pipelines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where the manuscript would benefit from additional quantitative support in the abstract and expanded technical details on the CEA module. We address each point below and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of performance gains on UCF-Crime and XD-Violence is unsupported by any quantitative results, baselines, ablation studies, or error analysis, making it impossible to evaluate whether the CEA or REA mechanisms deliver the claimed improvements.
Authors: We agree that the abstract would be strengthened by including concrete quantitative highlights rather than a purely qualitative summary. The full manuscript contains the requested elements in Section 4 (quantitative comparisons against baselines, ablation studies isolating CEA and REA, and error analysis on both UCF-Crime and XD-Violence). We will revise the abstract to report key metrics (e.g., AUC improvements and coherence scores) while preserving its length constraints. revision: yes
-
Referee: [CEA module description] CEA module (image-grounded memory mechanism): the claim that selecting historical frames via frame diversity and visual-textual alignment reliably expands useful context (rather than noise or redundant tokens under VLM length limits) is presented without implementation details, justification, or evidence of correlation with true temporal evidence; this assumption is load-bearing for both the accuracy gains and the downstream REA coherence.
Authors: We acknowledge that the current description of the image-grounded memory mechanism is high-level and lacks the requested implementation specifics and supporting evidence. We will expand the CEA section with: (1) precise algorithmic details on how diversity and visual-textual alignment scores are computed and combined, (2) explicit handling of token-budget constraints, and (3) additional ablation results demonstrating that the selected frames correlate with improved anomaly scoring and downstream REA coherence. These additions will be placed in the main text and supplementary material. revision: yes
Circularity Check
No circularity: framework description contains no equations or self-referential derivations
full rationale
The provided abstract and description introduce LATERN as a new test-time framework with CEA (image-grounded memory via diversity/alignment) and REA (recursive aggregation) modules. No equations, parameter fits, or derivations are present. No self-citations are invoked as load-bearing uniqueness theorems. The central claims rest on empirical results on UCF-Crime/XD-Violence rather than reducing to inputs by construction. This is a standard non-circular method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024)
2024
-
[2]
In: CVPR (2024)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR (2024)
2024
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara, P., Khant, D., Aryan, S., Singh, T., Yadav, D.: Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Du, H., Zhang, S., Xie, B., Nan, G., Zhang, J., Xu, J., Liu, H., Leng, S., Liu, J., Fan, H., Huang, D., Feng, J., Chen, L., Zhang, C., Li, X., Zhang, H., Chen, J., Cui, Q., Tao, X.: Uncovering what, why and how: A comprehensive benchmark for causation understanding of video anomaly. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (...
-
[5]
Nature630(8017), 625–630 (2024)
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting hallucinations in large lan- guage models using semantic entropy. Nature630(8017), 625–630 (2024)
2024
-
[6]
ACM Computing Surveys (CSUR)54(7), 1–37 (2021)
Fernando, T., Gammulle, H., Denman, S., Sridharan, S., Fookes, C.: Deep learning for medical anomaly detection–a survey. ACM Computing Surveys (CSUR)54(7), 1–37 (2021)
2021
-
[7]
Theo- retical Computer Science38, 293–306 (1985)
Gonzalez, T.F.: Clustering to minimize the maximum intercluster distance. Theo- retical Computer Science38, 293–306 (1985)
1985
-
[8]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Huang, C., Wang, B., Wang, W., Wen, J., Liu, C., Shen, L., Cao, X.: Vad-r1: Towards video anomaly reasoning via perception-to-cognition chain-of-thought. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Kossen, J., Han, J., Razzak, M., Schut, L., Malik, S., Gal, Y.: Semantic en- tropy probes: Robust and cheap hallucination detection in llms. arXiv preprint arXiv:2406.15927 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Kuhn, L., Gal, Y., Farquhar, S.: Semantic uncertainty: Linguistic invari- ances for uncertainty estimation in natural language generation. arXiv preprint arXiv:2302.09664 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
arXiv preprint arXiv:2505.15205 (2025)
Lee, H., Kim, H., Kim, I.J., Choi, Y.: Flashback: Memory-driven zero-shot, real- time video anomaly detection. arXiv preprint arXiv:2505.15205 (2025)
-
[13]
In: CVPR (2024)
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR (2024)
2024
-
[14]
In: NeurIPS (2024)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2024)
2024
-
[15]
In: CVPR (2018)
Liu,W.,Luo,W.,Lian,D.,Gao,S.:Futureframepredictionforanomalydetection– a new baseline. In: CVPR (2018)
2018
-
[16]
In: ICCV (2013)
Lu, C., Shi, J., Jia, J.: Abnormal event detection at 150 fps in matlab. In: ICCV (2013)
2013
-
[17]
arXiv preprint arXiv:2401.05702 (2024)
Lv, H., Sun, Q.: Video anomaly detection and explanation via large language mod- els. arXiv preprint arXiv:2401.05702 (2024)
-
[18]
In: Proceedings of the 16 Mitchell Piehl and Muchao Ye 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maharana, A., Lee, D.H., Tulyakov, S., Bansal, M., Barbieri, F., Fang, Y.: Evalu- ating very long-term conversational memory of llm agents. In: Proceedings of the 16 Mitchell Piehl and Muchao Ye 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13851–13870 (2024)
2024
-
[19]
Advances in Neural Information Processing Systems37, 8901–8929 (2024)
Nikitin, A., Kossen, J., Gal, Y., Marttinen, P.: Kernel language entropy: Fine- grained uncertainty quantification for llms from semantic similarities. Advances in Neural Information Processing Systems37, 8901–8929 (2024)
2024
-
[20]
Packer, C., Fang, V., Patil, S., Lin, K., Wooders, S., Gonzalez, J.: Memgpt: towards llms as operating systems. (2023)
2023
-
[21]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[22]
IEEE transactions on pattern analysis and machine intelligence 44(5), 2293–2312 (2020)
Ramachandra, B., Jones, M.J., Vatsavai, R.R.: A survey of single-scene video anomaly detection. IEEE transactions on pattern analysis and machine intelligence 44(5), 2293–2312 (2020)
2020
-
[23]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Rasmussen, P., Paliychuk, P., Beauvais, T., Ryan, J., Chalef, D.: Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. arXiv preprint arXiv:2410.17434 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Song, E., Chai, W., Wang, G., Zhang, Y., Zhou, H., Wu, F., Chi, H., Guo, X., Ye, T., Zhang, Y., et al.: Moviechat: From dense token to sparse memory for long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18221–18232 (2024)
2024
-
[26]
In: CVPR (2018)
Sultani, W., Chen, C., Shah, M.: Real-world anomaly detection in surveillance videos. In: CVPR (2018)
2018
-
[27]
In: NeurIPS (2024)
Tang, J., Lu, H., Wu, R., Xu, X., Ma, K., Fang, C., Guo, B., Lu, J., Chen, Q., Chen, Y.C.: Hawk: Learning to understand open-world video anomalies. In: NeurIPS (2024)
2024
-
[28]
In: ICCV (2021)
Tian, Y., Pang, G., Chen, Y., Singh, R., Verjans, J.W., Carneiro, G.: Weakly- supervised video anomaly detection with robust temporal feature magnitude learn- ing. In: ICCV (2021)
2021
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
In: ECCV (2020)
Wu, P., Liu, J., Shi, Y., Sun, Y., Shao, F., Wu, Z., Yang, Z.: Not only look, but also listen: Learning multimodal violence detection under weak supervision. In: ECCV (2020)
2020
-
[31]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wu, P., Zhou, X., Pang, G., Zhou, L., Yan, Q., Wang, P., Zhang, Y.: Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6074–6082 (2024)
2024
-
[32]
NeurIPS (2025)
Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., Zhang, Y.: A-mem: Agentic memory for llm agents. NeurIPS (2025)
2025
-
[33]
In: ECCV (2024)
Yang, Y., Lee, K., Dariush, B., Cao, Y., Lo, S.Y.: Follow the rules: Reasoning for video anomaly detection with large language models. In: ECCV (2024)
2024
-
[34]
IEEE transactions on pattern analysis and machine intelligence45(1), 444–459 (2022)
Yao, Y., Wang, X., Xu, M., Pu, Z., Wang, Y., Atkins, E., Crandall, D.J.: Dota: Unsupervised detection of traffic anomaly in driving videos. IEEE transactions on pattern analysis and machine intelligence45(1), 444–459 (2022)
2022
-
[35]
In: CVPR (2025) LATERN: Test-Time Context-Aware Explainable Video Anomaly Detection 17
Ye, M., Liu, W., He, P.: Vera: Explainable video anomaly detection via verbalized learning of vision-language models. In: CVPR (2025) LATERN: Test-Time Context-Aware Explainable Video Anomaly Detection 17
2025
-
[36]
In: ACM international conference on multimedia (2019)
Ye,M.,Peng,X.,Gan,W.,Wu,W.,Qiao,Y.:Anopcn:Videoanomalydetectionvia deep predictive coding network. In: ACM international conference on multimedia (2019)
2019
-
[37]
In: CVPR (2024)
Zanella, L., Menapace, W., Mancini, M., Wang, Y., Ricci, E.: Harnessing large language models for training-free video anomaly detection. In: CVPR (2024)
2024
-
[38]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Zeng, X., Qiu, K., Zhang, Q., Li, X., Wang, J., Li, J., Yan, Z., Tian, K., Tian, M., Zhao, X., et al.: Streamforest: Efficient online video understanding with persistent event memory. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[39]
arXiv preprint arXiv:2406.08085 (2024)
Zhang, H., Wang, Y., Tang, Y., Liu, Y., Feng, J., Dai, J., Jin, X.: Flash-vstream: Memory-based real-time understanding for long video streams. arXiv preprint arXiv:2406.08085 (2024)
-
[40]
arXiv preprint arXiv:2406.12235 (2024)
Zhang, H., Xu, X., Wang, X., Zuo, J., Han, C., Huang, X., Gao, C., Wang, Y., Sang, N.: Holmes-vad: Towards unbiased and explainable video anomaly detection via multi-modal llm. arXiv preprint arXiv:2406.12235 (2024)
-
[41]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, H., Xu, X., Wang, X., Zuo, J., Huang, X., Gao, C., Zhang, S., Yu, L., Sang, N.: Holmes-vau: Towards long-term video anomaly understanding at any granular- ity. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13843–13853 (2025)
2025
-
[42]
Long Context Transfer from Language to Vision
Zhang, P., Zhang, K., Li, B., Zeng, G., Yang, J., Zhang, Y., Wang, Z., Tan, H., Li, C., Liu, Z.: Long context transfer from language to vision. arXiv preprint arXiv:2406.16852 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Zhu, J., Ong, Y.S., Shen, C., Pang, G.: Fine-grained abnormality prompt learning for zero-shot anomaly detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22241–22251 (2025) 18 Mitchell Piehl and Muchao Ye Algorithm 1Context-Aware Anomaly Scoring (CEA) Require:VideoV, segment index set{t i}h i=1, summary strideS, mi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.