Agglomerative Attention
Pith reviewed 2026-05-24 21:28 UTC · model grok-4.3
The pith
Agglomerative attention reduces memory and computation to linear scaling while matching full attention performance on language modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
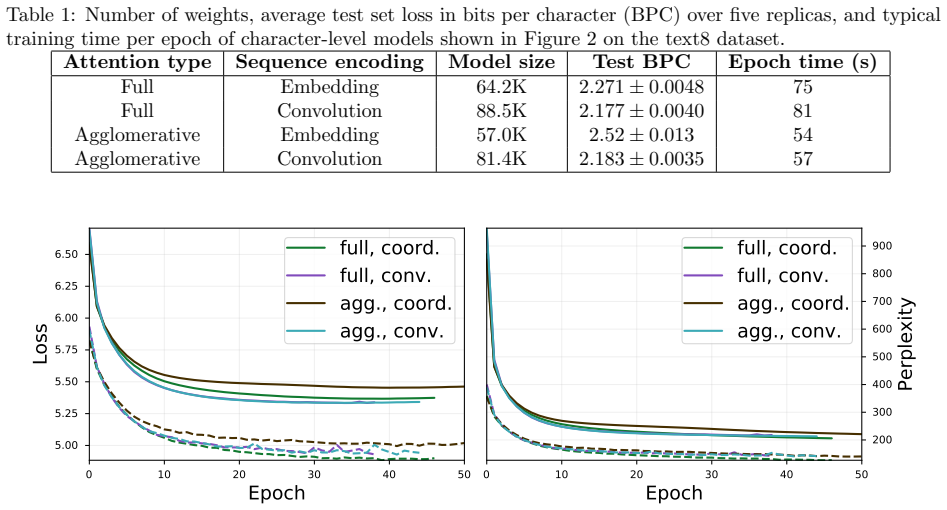
The paper introduces agglomerative attention, an attention layer that operates with linear requirements in both memory and computation time. Despite the simpler structure, neural networks that use this layer attain performance comparable to networks that employ full pairwise attention when trained and evaluated on language modeling tasks.
What carries the argument
Agglomerative attention, a linear-time attention structure that aggregates contextual information across sequence elements without exhaustive pairwise comparisons.
If this is right
- Sequence lengths can increase without a quadratic explosion in memory or compute.
- Transformer-style models can be trained at larger scale under fixed hardware budgets.
- The same linear mechanism can be substituted into existing attention-based architectures for language tasks.
- Contextual exchange remains sufficient to support next-token prediction at full-attention quality.
Where Pith is reading between the lines
- The approach may transfer to other sequence domains such as audio or time-series data where quadratic attention is also a bottleneck.
- If the linear structure preserves long-range dependencies, it could support deeper stacks of layers within the same compute envelope.
- Direct measurement of information flow across distant positions would test whether the aggregation step loses critical signals that full attention retains.
Load-bearing premise
The simplified linear attention structure still exchanges enough contextual information to match the modeling power of full pairwise attention on the target tasks.
What would settle it
A controlled language-modeling experiment in which the agglomerative-attention network produces perplexity or accuracy more than a few percent worse than an otherwise identical full-attention baseline.
Figures


read the original abstract
Neural networks using transformer-based architectures have recently demonstrated great power and flexibility in modeling sequences of many types. One of the core components of transformer networks is the attention layer, which allows contextual information to be exchanged among sequence elements. While many of the prevalent network structures thus far have utilized full attention -- which operates on all pairs of sequence elements -- the quadratic scaling of this attention mechanism significantly constrains the size of models that can be trained. In this work, we present an attention model that has only linear requirements in memory and computation time. We show that, despite the simpler attention model, networks using this attention mechanism can attain comparable performance to full attention networks on language modeling tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an 'agglomerative attention' mechanism with linear memory and computation requirements as an alternative to the quadratic full attention in transformer networks, and claims that networks using this mechanism attain comparable performance to full-attention networks on language modeling tasks.
Significance. If the empirical claim is substantiated with rigorous experiments, the work would address a key scalability bottleneck in attention-based models, potentially enabling longer sequences or larger models in sequence modeling.
major comments (1)
- [Abstract] Abstract: the central claim that agglomerative attention attains 'comparable performance' on language modeling is asserted without any quantitative results, baselines, error bars, dataset details, or implementation information, rendering the claim impossible to evaluate from the manuscript text.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that agglomerative attention attains 'comparable performance' on language modeling is asserted without any quantitative results, baselines, error bars, dataset details, or implementation information, rendering the claim impossible to evaluate from the manuscript text.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. Although the body of the manuscript reports specific experimental results (perplexity on standard language modeling benchmarks, direct comparisons to full-attention baselines, and implementation details), these are not summarized in the abstract. In the revised manuscript we will update the abstract to include key quantitative metrics, dataset names, and baseline comparisons so that the performance claim can be evaluated directly from the abstract. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces an agglomerative (linear) attention mechanism and reports an empirical result: networks using it attain comparable language-modeling performance to full pairwise attention. No derivation chain, first-principles prediction, or fitted parameter is presented whose output is shown to reduce to its inputs by construction. The central claim is strictly experimental and externally falsifiable via benchmark comparisons; no self-definitional equations, self-citation load-bearing steps, or renamed known results appear in the provided abstract or claim structure. The reader's assessment of circularity score 0.0 is therefore confirmed.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Agglomerative attention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Vaswani et al. “Attention Is All You Need”. In: Advances in Neural Information Processing Systems 30 . Ed. by I. Guyon et al. Curran As- Table 2: Number of weights, average test set perplexity over five replicas, and training time per epoch of word-level models shown in Figure 3. Attention type Sequence encoding Model size T est perplexity Epoch time (s...
work page 2017
-
[2]
M. Dehghani et al. Universal Transformers . July 10, 2018. arXiv: 1807.03819. url: http: //arxiv.org/abs/1807.03819
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Language Models Are Unsu- pervised Multitask Learners
A. Radford et al. “Language Models Are Unsu- pervised Multitask Learners”. In: OpenAI Blog 1.8 (2019). url: https://openai.com/blog/ better-language-models/
work page 2019
-
[4]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Z. Dai et al. Transformer-XL: Attentive Lan- guage Models beyond a Fixed-Length Context . Jan. 9, 2019. arXiv: 1901.02860 . url: http: //arxiv.org/abs/1901.02860
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Generating Long Sequences with Sparse Transformers
R. Child et al. Generating Long Sequences with Sparse Transformers . Apr. 23, 2019. arXiv: 1904.10509 . url: http://arxiv.org/abs/ 1904.10509
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
C.-Z. A. Huang et al. Music Transformer . Sept. 12, 2018. arXiv: 1809.04281. url: http: //arxiv.org/abs/1809.04281
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
C. Payne. MuseNet. Apr. 25, 2019. url: https: //openai.com/blog/musenet/
work page 2019
-
[8]
Gradient-Based Learning Ap- plied to Document Recognition
Y. Lecun et al. “Gradient-Based Learning Ap- plied to Document Recognition”. In: Proceed- ings of the IEEE 86.11 (Nov. 1998), pp. 2278–
work page 1998
- [9]
-
[10]
ImageNet Classification with Deep Convolu- tional Neural Networks
A. Krizhevsky, I. Sutskever, and G. E. Hinton. “ImageNet Classification with Deep Convolu- tional Neural Networks”. In: Advances in Neu- ral Information Processing Systems 25 . Ed. by F. Pereira et al. Curran Associates, Inc., 2012, pp. 1097–1105. url: http : / / papers . nips . cc/paper/4824-imagenet-classification- with - deep - convolutional - neural - ...
work page 2012
-
[11]
Visualizing and Understanding Convolutional Networks
M. D. Zeiler and R. Fergus. “Visualizing and Understanding Convolutional Networks”. In: Computer Vision ECCV 2014 . Ed. by D. Fleet et al. Lecture Notes in Computer Sci- ence. Springer International Publishing, 2014, pp. 818–833. isbn: 978-3-319-10590-1
work page 2014
-
[12]
C. Olah, A. Mordvintsev, and L. Schu- bert. “Feature Visualization”. In: Distill 2.11 (Nov. 7, 2017), e7. issn: 2476-0757. doi: 10 . 23915/distill.00007
work page 2017
-
[13]
Bi-Directional Block Self- Attention for Fast and Memory-Efficient Se- quence Modeling
T. Shen et al. “Bi-Directional Block Self- Attention for Fast and Memory-Efficient Se- quence Modeling”. In: International Confer- ence on Representation Learning . 2018
work page 2018
- [14]
-
[15]
Segtree Transformer: Iterative Re- finement of Hierarchical Features
Z. Ye et al. “Segtree Transformer: Iterative Re- finement of Hierarchical Features”. In: ICLR 2019 Workshop on ”Representation Learning on Graphs and Manifolds”. 2019. url: https: //rlgm.github.io/papers/
work page 2019
-
[16]
Dominant Forces in Protein Fold- ing
K. A. Dill. “Dominant Forces in Protein Fold- ing”. In: Biochemistry 29.31 (Aug. 7, 1990), pp. 7133–7155. issn: 0006-2960. doi: 10.1021/ bi00483a001
work page 1990
-
[17]
Initial Hydrophobic Collapse in the Folding of Barstar
V. R. Agashe, M. C. R. Shastry, and J. B. Udgaonkar. “Initial Hydrophobic Collapse in the Folding of Barstar”. In: Nature 377.6551 (Oct. 1995), p. 754. issn: 1476-4687. doi: 10. 1038/377754a0
work page 1995
-
[18]
How Fast Is Protein Hydrophobic Collapse?
M. Sadqi, L. J. Lapidus, and V. Muoz. “How Fast Is Protein Hydrophobic Collapse?” In: Proceedings of the National Academy of Sci- ences 100.21 (Oct. 14, 2003), pp. 12117–12122. issn: 0027-8424, 1091-6490. doi: 10 . 1073 / pnas.2033863100. pmid: 14530404
work page 2003
-
[19]
Hydrophobic Collapse in (in Silico) Protein Folding
M. Brylinski, L. Konieczny, and I. Roter- man. “Hydrophobic Collapse in (in Silico) Protein Folding”. In: Computational Biology and Chemistry 30.4 (Aug. 1, 2006), pp. 255–
work page 2006
-
[20]
issn: 1476-9271. doi: 10 . 1016 / j . compbiolchem.2006.04.007
work page 2006
-
[21]
Consciousness and cognition20(4), 1847–1854 (2011) https://doi.org/10.1016/j
G. Haran. “How, When and Why Proteins Col- lapse: The Relation to Folding”. In: Current Opinion in Structural Biology 22.1 (Feb. 2012), pp. 14–20. issn: 0959-440X. doi: 10.1016/j. sbi.2011.10.005. pmid: 22104965
work page doi:10.1016/j 2012
- [22]
- [23]
-
[24]
F. Chollet. Keras. GitHub, 2015. url: https: //github.com/fchollet/keras
work page 2015
-
[25]
Improving Language Un- derstanding by Generative Pre-Training
A. Radford et al. “Improving Language Un- derstanding by Generative Pre-Training”. In: (2018), p. 12
work page 2018
-
[26]
M. Mahoney. About the Test Data . Dec. 17,
-
[27]
url: https://cs.fit.edu/ ~mmahoney/ compression/textdata.html. 6
-
[28]
Pointer Sentinel Mixture Models
S. Merity et al. Pointer Sentinel Mixture Mod- els. Sept. 26, 2016. arXiv: 1609 . 07843. url: http://arxiv.org/abs/1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
M. D. Zeiler. ADADELTA: An Adaptive Learn- ing Rate Method . Dec. 22, 2012. arXiv: 1212
work page 2012
- [30]
-
[31]
S. Bai, J. Z. Kolter, and V. Koltun. An Em- pirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. Mar. 3, 2018. arXiv: 1803.01271. url: http: //arxiv.org/abs/1803.01271
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Neural Machine Translation of Rare Words with Subword Units
R. Sennrich, B. Haddow, and A. Birch. Neural Machine Translation of Rare Words with Sub- word Units. Aug. 31, 2015. arXiv: 1508.07909. url: http://arxiv.org/abs/1508.07909
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
P. Schwaller et al. “”Found in Translation”: Predicting Outcomes of Complex Organic Chemistry Reactions Using Neural Sequence- to-Sequence Models”. In: Chemical Science 9.28 (2018), pp. 6091–6098. doi: 10 . 1039 / C8SC02339E
work page 2018
-
[34]
A. Rives et al. “Biological Structure and Func- tion Emerge from Scaling Unsupervised Learn- ing to 250 Million Protein Sequences”. In: bioRxiv (May 29, 2019), p. 622803. doi: 10 . 1101/622803. 7
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.