Pmeta-TLA: Backdoor Attacks for Speech Classification Models via Meta-Learning with Timbre Leakage Attack
Pith reviewed 2026-07-03 11:32 UTC · model grok-4.3
The pith
Timbre leakage trigger enables meta-learning to embed multiple backdoors in speech classification models simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
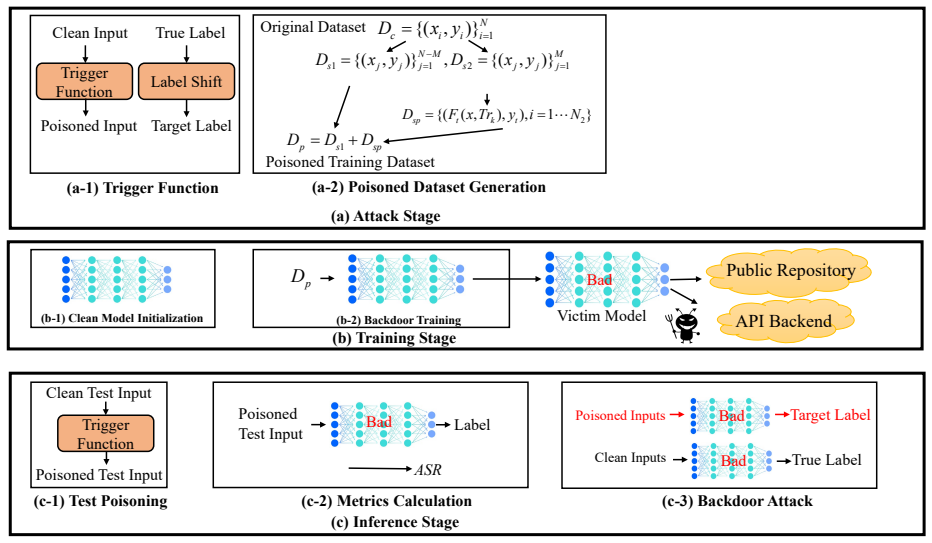
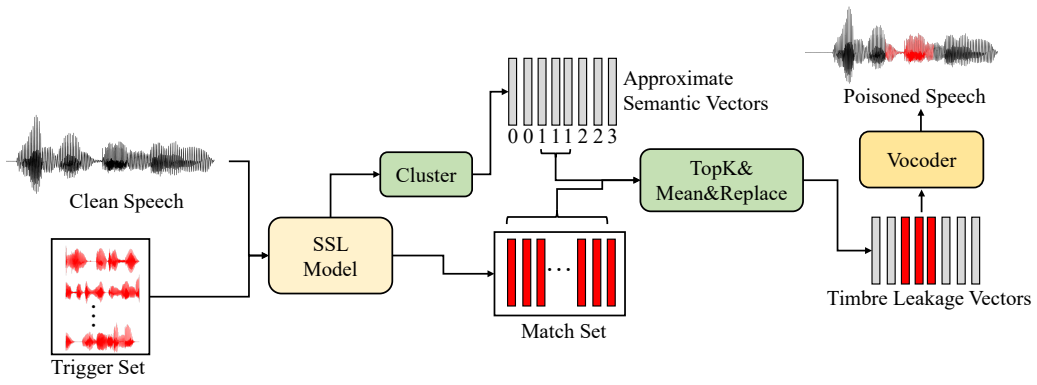
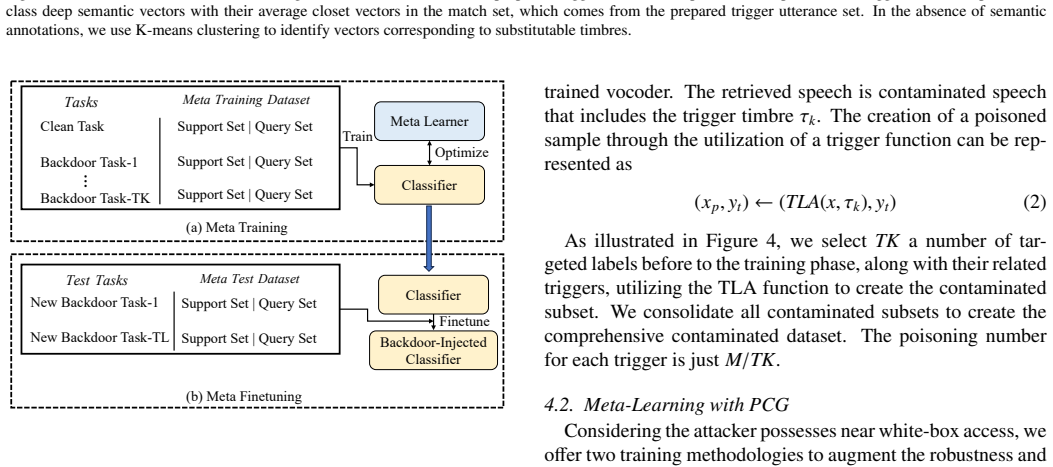
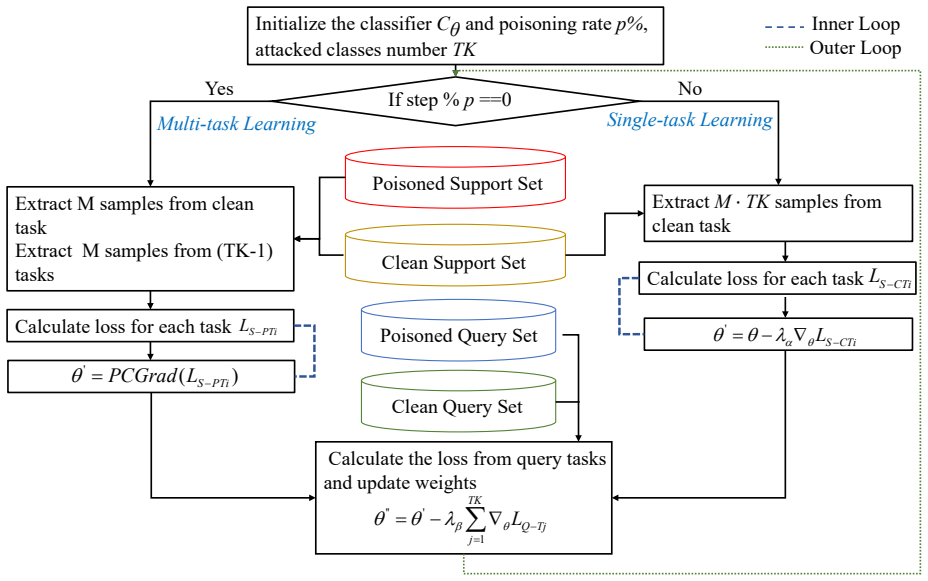
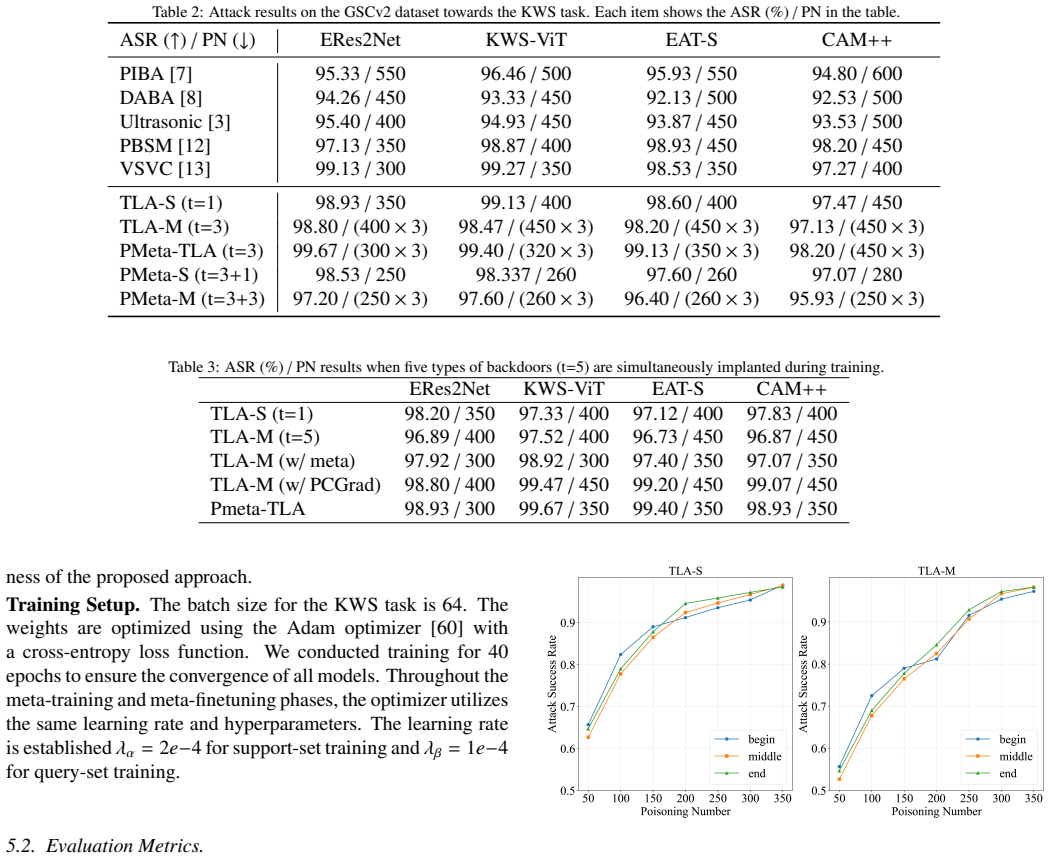
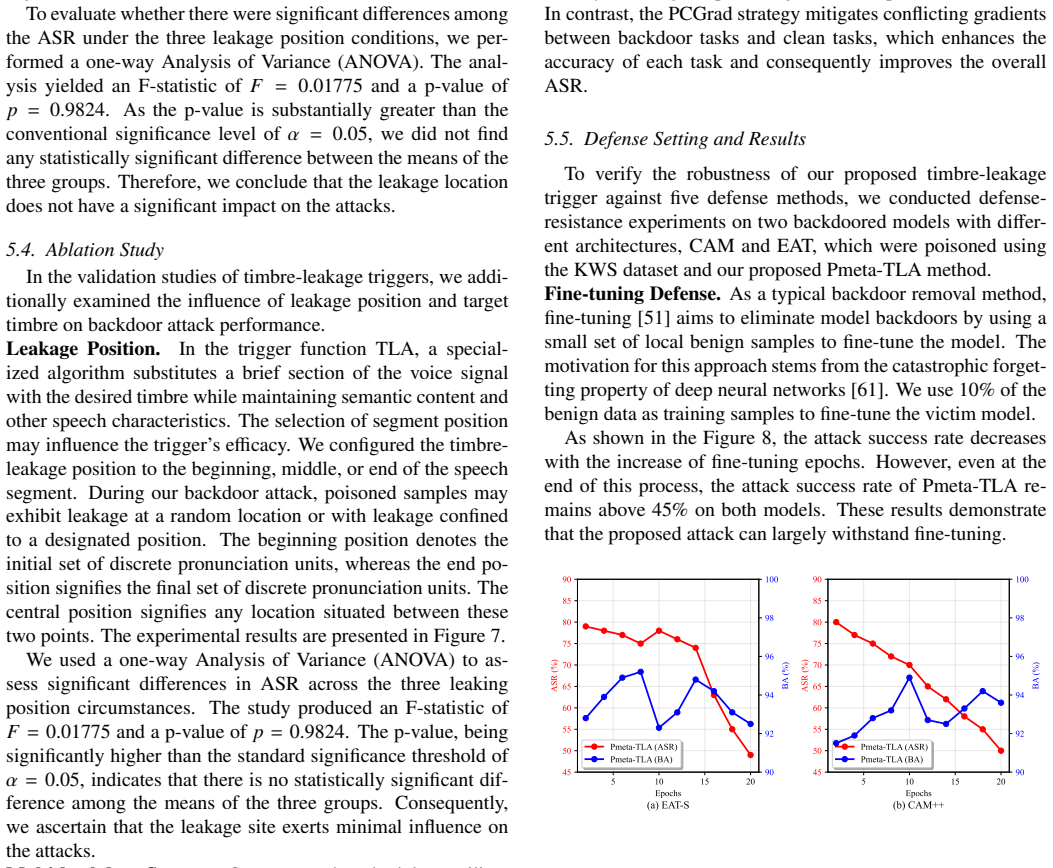
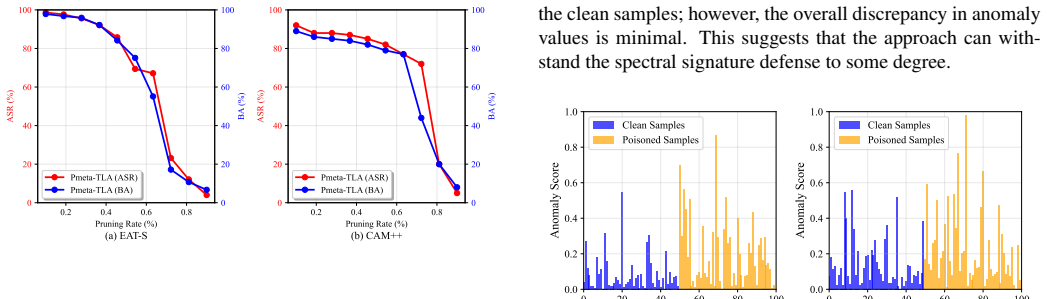
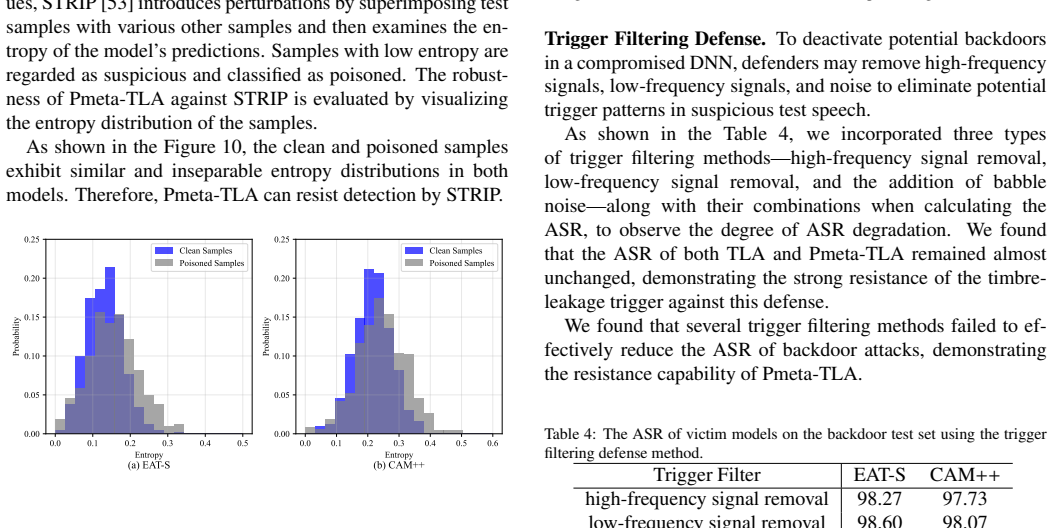
The authors establish that current speech triggers are detectable by DNN defenders, but the TLA trigger disseminates timbre information at the frame level within deep self-supervised features to generate natural-looking poisoned samples, and that Pmeta-TLA uses meta-learning and PCGrad to enable multi-backdoor injection in one training run, resulting in superior attack performance on keyword spotting tasks.
What carries the argument
The Timbre Leakage Attack (TLA) as a multi-target trigger and the Pmeta-TLA training strategy that employs meta-learning with Projected Conflicting Gradients (PCGrad) to embed numerous backdoors simultaneously.
If this is right
- Embedding multiple backdoors becomes possible in a single training run with lower overall attack cost.
- Poisoned samples remain undetectable by both humans and existing DNN-based defenders.
- The method achieves higher attack efficacy and robustness compared to baseline backdoor attacks on speech models.
- The approach applies to data-poisoning scenarios in keyword spotting using deep neural networks.
Where Pith is reading between the lines
- If the method works as described, defenders may need to develop new detection methods that analyze frame-level timbre features in self-supervised representations.
- The multi-backdoor meta-learning technique could potentially be applied to other classification domains such as images or text.
- This work suggests that speech models on consumer devices are more vulnerable to sophisticated attacks than previously thought.
Load-bearing premise
The timbre leakage trigger disseminates information at the frame level within deep self-supervised features while producing samples that appear natural to human perception and evade DNN defenders.
What would settle it
Demonstrating that the TLA trigger can be detected by current DNN defenders or that Pmeta-TLA does not outperform baselines in attack success rate would disprove the central claims.
Figures



read the original abstract
Recently, speech classification methods have gained widespread adoption in intelligent gadgets. Current study indicates that backdoor attacks provide a substantial security concern to these models, underscoring the pressing necessity to investigate additional potential attack techniques to expose and prevent such risks. This work discusses the vulnerability of current speech triggers to detection by deep neural network defenders and introduces the Timbre Leakage Attack (TLA). The suggested trigger disseminates timbre information at the frame level within the deep self-supervised features, producing poisoned samples that appear natural to human perception. Furthermore, we introduce Pmeta-TLA, an innovative training mechanism for embedding numerous backdoors one time. This method proposes a multi-backdoor injection training strategy using meta-learning and Projected Conflicting Gradients (PCGrad) and introduces TLA as a multi-target attack tool within it. We performed tests on data-poisoning backdoor attacks in keyword spotting tasks utilizing some deep neural network models. Experimental results indicate that the proposed strategy attains superior Attack efficacy, enhanced stealthiness, robustness, and a reduced attack cost relative to baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Timbre Leakage Attack (TLA) as a backdoor trigger for speech classification models, asserting that it embeds timbre information at the frame level inside deep self-supervised features to produce natural-sounding poisoned samples that evade DNN defenders. It further introduces Pmeta-TLA, a meta-learning training procedure that employs Projected Conflicting Gradients (PCGrad) to inject multiple backdoors in one training run, and reports experimental superiority over baselines in attack success rate, stealthiness, robustness, and attack cost on keyword-spotting tasks.
Significance. If the frame-level leakage mechanism and the claimed performance gains were rigorously demonstrated with ablations and defender-specific tests, the work would usefully extend the literature on backdoor attacks to self-supervised speech features and multi-target meta-learning settings.
major comments (2)
- [Abstract] Abstract: the assertion that TLA 'disseminates timbre information at the frame level within the deep self-supervised features' is load-bearing for all stealthiness and superiority claims, yet the text supplies no feature visualizations, layer-wise ablations, or spectral analyses confirming frame-level (rather than coarser) leakage.
- [Abstract] Abstract: the statement that the proposed strategy attains 'superior Attack efficacy, enhanced stealthiness, robustness, and a reduced attack cost relative to baseline methods' is presented without any reported metrics, data splits, error bars, model architectures, or defender-specific results, so the experimental superiority claim cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: 'Current study indicates' should read 'Current studies indicate'; the phrase 'utilizing some deep neural network models' is vague and should name the architectures and datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that TLA 'disseminates timbre information at the frame level within the deep self-supervised features' is load-bearing for all stealthiness and superiority claims, yet the text supplies no feature visualizations, layer-wise ablations, or spectral analyses confirming frame-level (rather than coarser) leakage.
Authors: We agree that the frame-level leakage claim is central to the stealthiness arguments and requires direct empirical support. The manuscript describes the TLA mechanism, but we acknowledge the absence of visualizations and ablations in the current version. In the revised manuscript we will add feature visualizations, layer-wise ablations, and spectral analyses to confirm frame-level (as opposed to coarser) timbre leakage within the self-supervised features. revision: yes
-
Referee: [Abstract] Abstract: the statement that the proposed strategy attains 'superior Attack efficacy, enhanced stealthiness, robustness, and a reduced attack cost relative to baseline methods' is presented without any reported metrics, data splits, error bars, model architectures, or defender-specific results, so the experimental superiority claim cannot be evaluated.
Authors: The full experimental results, including quantitative metrics, data splits, error bars, model architectures, and defender-specific evaluations, appear in Sections 4 and 5. We recognize, however, that the abstract statement would be more self-contained if accompanied by key numbers. We will revise the abstract to include representative metrics and a concise reference to the experimental protocol. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper is an empirical study proposing the Timbre Leakage Attack (TLA) trigger and Pmeta-TLA training strategy for backdoor attacks on speech models. No equations, derivations, fitted parameters presented as predictions, or self-citation load-bearing uniqueness theorems appear in the abstract or description. Central claims rest on experimental comparisons of attack efficacy, stealthiness, and robustness against baselines, without any reduction of results to inputs by construction or self-definitional structures. The work is self-contained as an experimental contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Ji, X. Zhang, T. Wang, Backdoor attacks against learn- ing systems, in: 2017 IEEE Conference on Communica- tions and Network Security (CNS), IEEE, 2017, pp. 1–9
2017
-
[2]
X. Chen, C. Liu, B. Li, K. Lu, D. Song, Targeted back- door attacks on deep learning systems using data poison- ing, arXiv preprint arXiv:1712.05526 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Koffas, J
S. Koffas, J. Xu, M. Conti, S. Picek, Can you hear it? backdoor attacks via ultrasonic triggers, in: Proceedings of the 2022 ACM workshop on wireless security and ma- chine learning, 2022, pp. 57–62
2022
-
[4]
T. Zhai, Y . Li, Z. Zhang, B. Wu, Y . Jiang, S.-T. Xia, Backdoor attack against speaker verification, in: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2021, pp. 2560–2564
2021
-
[5]
Z. Ye, T. Mao, L. Dong, D. Yan, Fake the real: Back- door attack on deep speech classification via voice con- version, in: Interspeech 2023, 2023, pp. 4923–4927.doi: 10.21437/Interspeech.2023-733
-
[6]
H. Cai, P. Zhang, H. Dong, Y . Xiao, S. Koffas, Y . Li, To- ward stealthy backdoor attacks against speech recognition via elements of sound, IEEE Transactions on Information Forensics and Security 19 (2024) 5852–5866
2024
-
[7]
C. Shi, T. Zhang, Z. Li, H. Phan, T. Zhao, Y . Wang, J. Liu, B. Yuan, Y . Chen, Audio-domain position-independent backdoor attack via unnoticeable triggers, in: 28th ACM Annual International Conference on Mobile Computing and Networking, MobiCom 2022, Association for Com- puting Machinery, 2022, pp. 583–595
2022
-
[8]
Q. Liu, T. Zhou, Z. Cai, Y . Tang, Opportunistic back- door attacks: Exploring human-imperceptible vulnerabil- ities on speech recognition systems, in: Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2390–2398
2022
-
[9]
Koffas, L
S. Koffas, L. Pajola, S. Picek, M. Conti, Going in style: Audio backdoors through stylistic transformations, in: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2023, pp. 1–5
2023
-
[10]
Mittag, B
G. Mittag, B. Naderi, A. Chehadi, S. Möller, Nisqa: A deep cnn-self-attention model for multidimensional speech quality prediction with crowdsourced datasets (2021)
2021
-
[11]
Lo, S.-W
C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y . Tsao, H.-M. Wang, G. Kubin, Z. Kacic, Mosnet: Deep learning-based objective assessment for voice conversion, INTERSPEECH 2019 (2019) 1541–1545
2019
- [12]
- [13]
-
[14]
W. Yao, J. Yang, Y . He, J. Liu, W. Wen, Imperceptible rhythm backdoor attacks: Exploring rhythm transforma- tion for embedding undetectable vulnerabilities on speech recognition, Neurocomputing 614 (2025) 128779
2025
-
[15]
Z. Wu, P. L. De Leon, C. Demiroglu, A. Khodabakhsh, S. King, Z.-H. Ling, D. Saito, B. Stewart, T. Toda, M. Wester, et al., Anti-spoofing for text-independent speaker verification: An initial database, comparison of countermeasures, and human performance, IEEE/ACM Transactions on Audio, Speech, and Language Processing 24 (4) (2016) 768–783
2016
-
[16]
H. Wei, X. Cao, T. Dan, Y . Chen, Rmvpe: A robust model for vocal pitch estimation in polyphonic music, in: Proc. Interspeech 2023, 2023, pp. 5421–5425
2023
-
[17]
Hospedales, A
T. Hospedales, A. Antoniou, P. Micaelli, A. Storkey, Meta-learning in neural networks: A survey, IEEE trans- actions on pattern analysis and machine intelligence 44 (9) (2021) 5149–5169
2021
-
[18]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Haus- man, C. Finn, Gradient surgery for multi-task learning, Advances in neural information processing systems 33 (2020) 5824–5836
2020
-
[19]
S. Choi, S. Seo, B. Shin, H. Byun, M. Kersner, B. Kim, D. Kim, S. Ha, Temporal convolution for real-time key- word spotting on mobile devices, in: Proc. Interspeech 2019, 2019, pp. 3372–3376
2019
-
[20]
A. Berg, M. O’Connor, M. T. Cruz, Keyword transformer: A self-attention model for keyword spotting, in: Inter- speech 2021, ISCA, 2021, pp. 4249–4253
2021
- [21]
-
[22]
Huang, T
L. Huang, T. Yuan, Y . Liang, Z. Chen, C. Wen, Y . Xie, J. Zhang, D. Ke, Limi-vc: A light weight voice con- version model with mutual information disentanglement, in: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2023, pp. 1–5. 13
2023
-
[23]
Bartoli, T
P. Bartoli, T. Bondini, C. Veronesi, A. Giudici, N. An- tonello, F. Zappa, et al., End-to-end efficiency in keyword spotting: a system-level approach for embedded micro- controllers, in: Proceedings of IEEE Sensors 2025, 2025, pp. 1–4
2025
-
[24]
Y . Xi, H. Li, H. Li, J. Guo, X. Li, W. Ding, K. Yu, Ntc-kws: Noise-aware ctc for robust keyword spotting, in: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2025, pp. 1–5
2025
-
[25]
Biggio, B
B. Biggio, B. Nelson, P. Laskov, et al., Poisoning at- tacks against support vector machines, in: Proceedings of the 29th International Conference on Machine Learning, ICML 2012, ArXiv e-prints, 2012, pp. 1807–1814
2012
-
[26]
T. Gu, B. Dolan-Gavitt, S. Garg, Badnets: Identifying vul- nerabilities in the machine learning model supply chain, arXiv preprint arXiv:1708.06733 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Y . Li, Y . Jiang, Z. Li, S.-T. Xia, Backdoor learning: A survey, IEEE transactions on neural networks and learning systems 35 (1) (2022) 5–22
2022
-
[28]
Turner, D
A. Turner, D. Tsipras, A. Madry, Clean-label backdoor attacks (2018)
2018
-
[29]
W. You, D. Lowd, The ultimate cookbook for invisible poison: Crafting subtle clean-label text backdoors with style attributes, in: 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), IEEE, 2025, pp. 222–246
2025
-
[30]
J. Lin, L. Xu, Y . Liu, X. Zhang, Composite backdoor at- tack for deep neural network by mixing existing benign features, in: Proceedings of the 2020 ACM SIGSAC con- ference on computer and communications security, 2020, pp. 113–131
2020
-
[31]
T. A. Nguyen, A. Tran, Input-aware dynamic backdoor at- tack, Advances in Neural Information Processing Systems 33 (2020) 3454–3464
2020
-
[32]
E. Chou, F. Tramer, G. Pellegrino, Sentinet: Detecting lo- calized universal attacks against deep learning systems, in: 2020 IEEE Security and Privacy Workshops (SPW), IEEE, 2020, pp. 48–54
2020
-
[33]
Y . Dong, X. Yang, Z. Deng, T. Pang, Z. Xiao, H. Su, J. Zhu, Black-box detection of backdoor attacks with limited information and data, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16482–16491
2021
-
[34]
B. Wang, Y . Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, B. Y . Zhao, Neural cleanse: Identifying and mitigating backdoor attacks in neural networks, in: 2019 IEEE sym- posium on security and privacy (SP), IEEE, 2019, pp. 707–723
2019
-
[35]
Zhang, C
J. Zhang, C. Dongdong, Q. Huang, J. Liao, W. Zhang, H. Feng, G. Hua, N. Yu, Poison ink: Robust and invisible backdoor attack, IEEE Transactions on Image Processing 31 (2022) 5691–5705
2022
-
[36]
Wenger, J
E. Wenger, J. Passananti, A. N. Bhagoji, Y . Yao, H. Zheng, B. Y . Zhao, Backdoor attacks against deep learning sys- tems in the physical world, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 6206–6215
2021
-
[37]
J. Ye, X. Liu, Z. You, G. Li, B. Liu, Drinet: Dynamic backdoor attack against automatic speech recognization models, Applied Sciences 12 (12) (2022) 5786
2022
-
[38]
B. Li, Y . Ge, Z. Fang, T. Wang, L. Zhao, Q. Lu, N. Jiang, Q. Wang, Cuckooattack: Towards practical backdoor attack against automatic speech recognition sys- tems, IEEE Transactions on Dependable and Secure Com- puting (2025)
2025
-
[39]
Zong, Y .-W
W. Zong, Y .-W. Chow, W. Susilo, K. Do, S. Venkatesh, Trojanmodel: A practical trojan attack against automatic speech recognition systems, in: 2023 IEEE Symposium on Security and Privacy (SP), IEEE, 2023, pp. 1667–1683
2023
- [40]
-
[41]
Y . Liu, X. Ma, J. Bailey, F. Lu, Reflection backdoor: A natural backdoor attack on deep neural networks, in: Computer vision–ECCV 2020: 16th European confer- ence, Glasgow, UK, August 23–28, 2020, proceedings, part X 16, Springer, 2020, pp. 182–199
2020
-
[42]
T. A. Nguyen, A. T. Tran, Wanet-imperceptible warping- based backdoor attack, in: International Conference on Learning Representations
-
[43]
H. Guo, X. Chen, J. Guo, L. Xiao, Q. Yan, Masterkey: Practical backdoor attack against speaker verification sys- tems, in: Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, 2023, pp. 1–15
2023
-
[44]
J. Xin, X. Lyu, J. Ma, Natural backdoor attacks on speech recognition models, in: International Conference on Ma- chine Learning for Cyber Security, Springer, 2022, pp. 597–610
2022
-
[45]
P. Liu, S. Zhang, C. Yao, W. Ye, X. Li, Backdoor at- tacks against deep neural networks by personalized audio steganography, in: 2022 26th International Conference on Pattern Recognition (ICPR), IEEE, 2022, pp. 68–74
2022
-
[46]
Likas, N
A. Likas, N. Vlassis, J. J. Verbeek, The global k-means clustering algorithm, Pattern recognition 36 (2) (2003) 451–461. 14
2003
-
[47]
C. Finn, P. Abbeel, S. Levine, Model-agnostic meta- learning for fast adaptation of deep networks, in: Inter- national conference on machine learning, PMLR, 2017, pp. 1126–1135
2017
-
[48]
J. Guo, Y . Li, X. Chen, H. Guo, L. Sun, C. Liu, Scale-up: An efficient black-box input-level backdoor detection via analyzing scaled prediction consistency, in: ICLR, 2023
2023
-
[49]
Xiang, Z
Z. Xiang, Z. Xiong, B. Li, Umd: Unsupervised model de- tection for x2x backdoor attacks, in: International Con- ference on Machine Learning, PMLR, 2023, pp. 38013– 38038
2023
-
[50]
N. M. Jebreel, J. Domingo-Ferrer, Y . Li, Defending against backdoor attacks by layer-wise feature analysis, in: Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2023, pp. 428–440
2023
-
[51]
Y . Liu, Y . Xie, A. Srivastava, Neural trojans, in: 2017 IEEE 35th International Conference on Computer Design (ICCD), IEEE Computer Society, 2017, pp. 45–48
2017
-
[52]
K. Liu, B. Dolan-Gavitt, S. Garg, Fine-pruning: Defend- ing against backdooring attacks on deep neural networks, in: International symposium on research in attacks, intru- sions, and defenses, Springer, 2018, pp. 273–294
2018
-
[53]
Y . Gao, D. Wang, S. Chen, D. C. Ranasinghe, S. Nepal, Strip, in: Proceedings of the 35th Annual Computer Secu- rity Applications Conference, ACM, 2019
2019
-
[54]
B. Tran, J. Li, A. Madry, Spectral signatures in backdoor attacks, Advances in neural information processing sys- tems 31 (2018)
2018
- [55]
-
[56]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, Speech Commands: A Dataset for Limited- V ocabulary Speech Recognition, ArXiv e-prints (Apr. 2018).arXiv:1804.03209. URLhttps://arxiv.org/abs/1804.03209
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[57]
Y . Chen, S. Zheng, H. Wang, L. Cheng, Q. Chen, J. Qi, An enhanced res2net with local and global feature fusion for speaker verification, in: INTERSPEECH, 2023
2023
-
[58]
A. Gazneli, G. Zimerman, T. Ridnik, G. Sharir, A. Noy, End-to-end audio strikes back: Boosting augmentations towards an efficient audio classification network, arXiv preprint arXiv:2204.11479 (2022)
- [59]
-
[60]
Kingma, L
D. Kingma, L. Ba, et al., Adam: A method for stochastic optimization (2015)
2015
-
[61]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ra- malho, A. Grabska-Barwinska, et al., Overcoming catas- trophic forgetting in neural networks, Proceedings of the national academy of sciences 114 (13) (2017) 3521–3526. 15
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.