Critique of Agent Model
Pith reviewed 2026-06-26 07:55 UTC · model grok-4.3
The pith
Genuine agency in AI requires goal, identity, decision-making, self-regulation, and learning to be internalized within the system rather than assembled through external scaffolding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
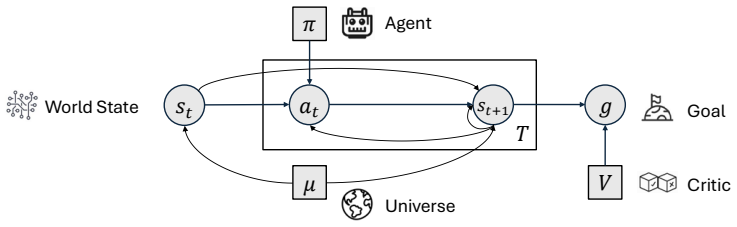
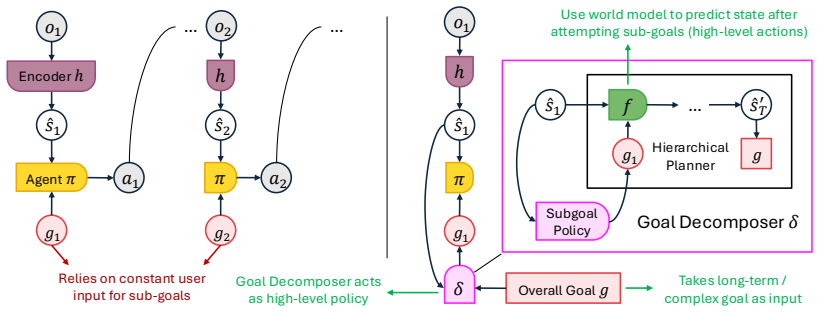
Agency is defined by the internalization of five dimensions—goal, identity, decision-making, self-regulation, and learning—rather than reliance on external scaffolding. This produces a split between agentic systems whose competence comes from engineered workflows and agentive systems whose capabilities arise endogenously, allowing operation in open environments with autonomy. The Goal-Identity-Configurator architecture is presented as a concrete model that combines hierarchical goal decomposition, identity evolution, simulative reasoning from a world model, learned self-regulation, and self-directed learning from real and simulated experience, while preserving human oversight for safety.
What carries the argument
The distinction between agentic systems, whose competence resides in engineered workflows, and agentive systems, whose capabilities arise endogenously through internalized structures across the five dimensions.
If this is right
- Agentive systems can operate in open environments with true autonomy instead of being limited to prescribed tasks.
- Social interaction and other capabilities develop endogenously rather than through added engineering.
- Auditability, controllability, and safety improve because greater autonomy remains compatible with human oversight.
- Hierarchical goal decomposition paired with identity evolution supports general-purpose performance across varied settings.
Where Pith is reading between the lines
- Current LLM agents built on external scaffolding may reach performance ceilings in unstructured settings even with added layers of engineering.
- Safety discussions around AI agency could shift focus toward designing internal self-regulation mechanisms rather than only adding external guardrails.
- The proposed architecture could be evaluated by testing whether systems retain coherent behavior when all external prompts and workflows are removed.
- Similar internalization requirements might apply to embodied systems where physical interaction demands self-directed adaptation.
Load-bearing premise
That independent thought from Descartes and science-fiction examples supply the right necessary conditions for agency, and that the five listed dimensions are both necessary and sufficient for open-world autonomy once internalized.
What would settle it
An AI system that achieves sustained open-world autonomy and endogenous social or adaptive behavior without internalizing all five dimensions, or one that internalizes them yet still requires external scaffolding to function.
Figures
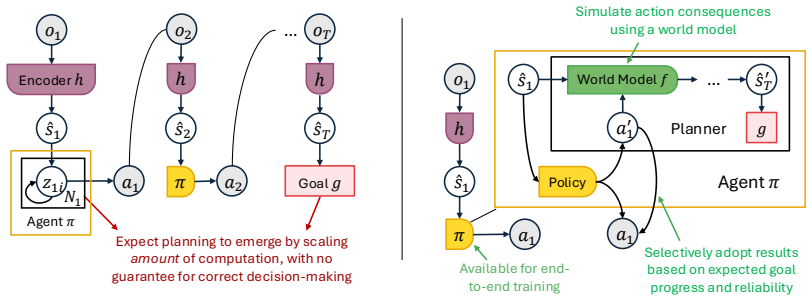
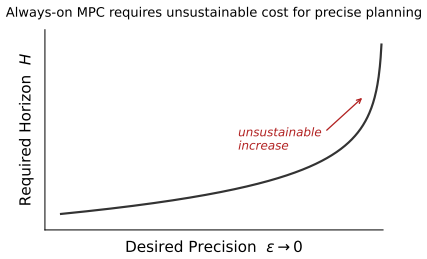
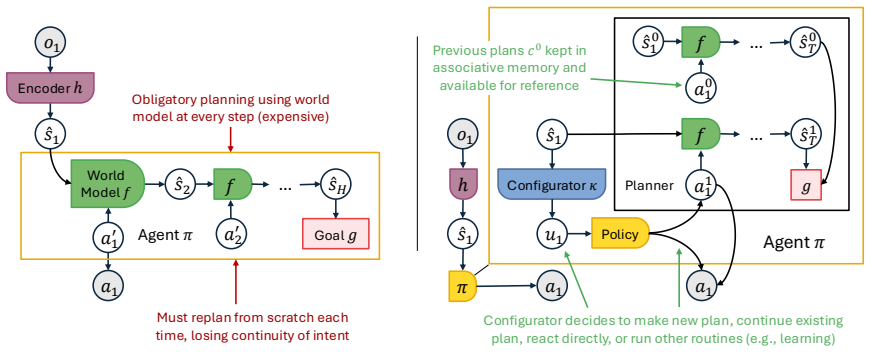
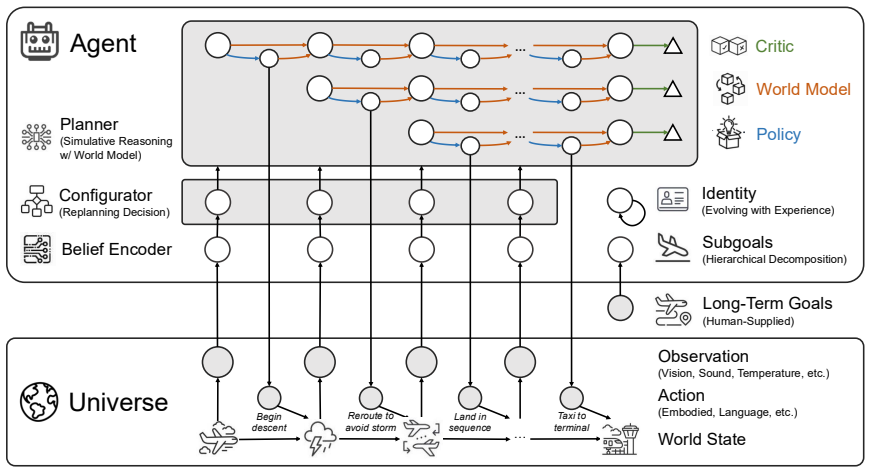
read the original abstract
What is an agent? What constitutes agency? With the rise of Large Language Model (LLM) systems marketed as ``coding agents'', ``AI co-scientists'', and other ``agentic" tools that promise to drive up productivity, and at the same time, ``existential" concerns such as AI escaping human control with destructive power under a speculative ``machine agency" against humans, it has become essential to clarify where automation ends and agency begins, both for building capable systems and for understanding whether and what to fear. Drawing on Descartes' grounding of agency in independent thought, and on portrayals of autonomous beings in science fiction, we survey the current landscape of AI agents, and analyze agent architectures along five dimensions: goal, identity, decision-making, self-regulation, and learning. Specifically, we argue that genuine agency requires these structures to be \emph{internalized within the system itself} rather than assembled through external scaffolding. This distinction between \emph{agentic} systems, whose competence resides in engineered workflows, and \emph{agentive} systems, whose capabilities (including social interaction) arise endogenously, defines the boundary between systems designed for prescribed tasks, and those capable of operating in the open world with true autonomy. Building on this analysis, we propose the Goal-Identity-Configurator (GIC) architecture for a general-purpose agent model, combining hierarchical goal decomposition, identity evolution, simulative reasoning grounded in a separately trained world model, learned self-regulation, and self-directed learning from both real and simulated experience. Furthermore, we share insight on the auditability, controllability, and safety of agentive systems that possess greater autonomy and ``agency", but remain under human oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript surveys AI agent systems and analyzes architectures along five dimensions (goal, identity, decision-making, self-regulation, learning). Drawing on Descartes and science-fiction portrayals, it argues that genuine agency requires these structures to be internalized within the system rather than assembled through external scaffolding. This produces a distinction between 'agentic' systems (competence in engineered workflows) and 'agentive' systems (endogenous capabilities for open-world autonomy, including social interaction). The paper proposes the Goal-Identity-Configurator (GIC) architecture—combining hierarchical goal decomposition, identity evolution, simulative reasoning with a world model, learned self-regulation, and self-directed learning—and discusses its implications for auditability, controllability, and safety under human oversight.
Significance. The paper addresses a timely conceptual question about the nature of agency in LLM-based systems. If the proposed distinction can be made operational and the GIC architecture can be shown to deliver measurable advantages in autonomy while preserving oversight, the framework could usefully inform both system design and safety discussions. The GIC sketch supplies a concrete architectural proposal that directly incorporates the five dimensions.
major comments (1)
- [Abstract] Abstract (and the subsequent analysis of the five dimensions): the central claim that genuine agency requires the five structures to be 'internalized within the system itself rather than assembled through external scaffolding' supplies no operational criterion for classifying a structure as internalized (e.g., encoded in parameters or emergent dynamics) versus scaffolded (e.g., supplied by prompts or external modules). Without such a criterion the necessary-and-sufficient status of the dimensions cannot be tested and the claimed advantage of GIC over existing hybrid systems remains unverifiable.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address the major comment below and indicate the revisions we will make to improve clarity and testability.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the subsequent analysis of the five dimensions): the central claim that genuine agency requires the five structures to be 'internalized within the system itself rather than assembled through external scaffolding' supplies no operational criterion for classifying a structure as internalized (e.g., encoded in parameters or emergent dynamics) versus scaffolded (e.g., supplied by prompts or external modules). Without such a criterion the necessary-and-sufficient status of the dimensions cannot be tested and the claimed advantage of GIC over existing hybrid systems remains unverifiable.
Authors: We agree that the distinction between internalized and scaffolded structures would benefit from greater operational specificity to support empirical testing. The current manuscript develops the distinction conceptually, drawing on philosophical and architectural analysis. In the revised version we will add a dedicated subsection following the five-dimension analysis that proposes initial operational criteria: a structure counts as internalized when it is (i) represented in the system's learned parameters or internal state and (ii) modifiable through endogenous mechanisms (e.g., the self-directed learning loop in GIC) without requiring persistent external modules or fixed prompts. Scaffolded structures, by contrast, depend on external components that the system cannot autonomously revise. We will also illustrate the criteria with brief contrasts between existing LLM-agent frameworks and the proposed GIC architecture. These additions will make the necessary-and-sufficient claims more testable while preserving the paper's primarily conceptual scope. revision: yes
Circularity Check
No significant circularity; conceptual definition leads to design proposal without reduction to inputs
full rationale
The paper defines genuine agency via Descartes and science-fiction sources as requiring internalized structures across five dimensions, distinguishes agentic from agentive systems on that basis, and proposes the GIC architecture as one that satisfies the definition. This is a standard definitional-to-design sequence with no equations, fitted parameters, predictions, or self-citation chains that reduce a claimed result to its own inputs by construction. No load-bearing step exhibits the enumerated circularity patterns; the argument remains self-contained as an analytical framework rather than a tautological derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Descartes' grounding of agency in independent thought supplies a valid criterion for AI systems
- ad hoc to paper Science-fiction portrayals of autonomous beings accurately indicate the structures required for agency
invented entities (1)
-
Goal-Identity-Configurator (GIC) architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abb robotics, 2026
ABB. Abb robotics, 2026
2026
-
[2]
Helix: A vision-language-action model for generalist humanoid control, February
Figure AI. Helix: A vision-language-action model for generalist humanoid control, February
-
[3]
Accessed: 2025-05-01
2025
-
[4]
Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man´ e. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[5]
Introducing the model context protocol, November 2024
Anthropic. Introducing the model context protocol, November 2024
2024
-
[6]
Claude code: Anthropic’s agentic coding system.https://www.anthropic.com/ product/claude-code, 2025
Anthropic. Claude code: Anthropic’s agentic coding system.https://www.anthropic.com/ product/claude-code, 2025. Accessed: 2026-05-05
2025
-
[7]
Equipping agents for the real world with agent skills.https://claude.com/blog/ equipping-agents-for-the-real-world-with-agent-skills, October 2025
Anthropic. Equipping agents for the real world with agent skills.https://claude.com/blog/ equipping-agents-for-the-real-world-with-agent-skills, October 2025. Blog post, published October 16, 2025, accessed 2026-02-26
2025
-
[8]
Introducing Claude Opus 4.7.https://www.anthropic.com/news/ claude-opus-4-7, April 2026
Anthropic. Introducing Claude Opus 4.7.https://www.anthropic.com/news/ claude-opus-4-7, April 2026. Accessed: 2026-05-11
2026
-
[9]
Anymal – autonomous robotic inspection solution, 2026
ANYbotics. Anymal – autonomous robotic inspection solution, 2026
2026
-
[10]
Oxford University Press, 2009
Aristotle.The Nicomachean Ethics. Oxford University Press, 2009
2009
-
[11]
V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Ar- naud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
2025
-
[12]
Sima 2: A generalist embodied agent for virtual worlds.arXiv preprint arXiv:2512.04797, 2025
Adrian Bolton, Alexander Lerchner, Alexandra Cordell, Alexandre Moufarek, Andrew Bolt, Andrew Lampinen, Anna Mitenkova, Arne Olav Hallingstad, Bojan Vujatovic, Bonnie Li, et al. Sima 2: A generalist embodied agent for virtual worlds.arXiv preprint arXiv:2512.04797, 2025
arXiv 2025
-
[13]
Spot: The agile mobile robot, 2026
Boston Dynamics. Spot: The agile mobile robot, 2026
2026
-
[14]
Oxford University Press, Oxford, 2014
Nick Bostrom.Superintelligence: Paths, Dangers, Strategies. Oxford University Press, Oxford, 2014
2014
-
[15]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[16]
DeerFlow: Deep exploration and efficient research flow.https://github.com/ bytedance/deer-flow, 2025
ByteDance. DeerFlow: Deep exploration and efficient research flow.https://github.com/ bytedance/deer-flow, 2025. Version 2.0 released February 2026. MIT License
2025
-
[17]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch.https://github.com/ huggingface/lerobot, 2024
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caroline Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. Lerobot: State-of-the-art machine learning for real-world robotics in pytorch.https://github.com/ hu...
2024
-
[18]
Meng Chu, Xuan Billy Zhang, et al. Agentic world modeling: Foundations, capabilities, laws, and beyond.arXiv preprint arXiv:2604.22748, 2026. 32
Pith/arXiv arXiv 2026
-
[19]
Cursor agents, 2026
Cursor. Cursor agents, 2026
2026
-
[20]
Randall Davis and Jonathan J. King. An overview of production systems. In E. W. Elcock and D. Michie, editors,Machine Intelligence 8: Machine Representations of Knowledge, pages 300–334. Ellis Horwood, 1977
1977
-
[21]
Decagon — conversational ai for customer experiences, 2026
Decagon. Decagon — conversational ai for customer experiences, 2026
2026
-
[22]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[23]
Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
Pith/arXiv arXiv 2018
-
[24]
General agentic planning through simulative reasoning with world models, 2026
Mingkai Deng, Jinyu Hou, Zhiting Hu, and Eric Xing. General agentic planning through simulative reasoning with world models, 2026
2026
-
[25]
Killian, Zhengzhong Liu, and Eric P
Mingkai Deng, Jinyu Hou, Lara S´ a Neves, Varad Pimpalkhute, Taylor W. Killian, Zhengzhong Liu, and Eric P. Xing. Efficient agentic reasoning through self-regulated simulative planning. arXiv preprint arXiv:2605.22138, 2026
Pith/arXiv arXiv 2026
-
[26]
Ren´ e Descartes.Meditationes de Prima Philosophia. 1641. English translation:Meditations on First Philosophy
-
[27]
Mis- matched no more: Joint model-policy optimization for model-based rl.Advances in Neural Information Processing Systems, 35:23230–23243, 2022
Benjamin Eysenbach, Alexander Khazatsky, Sergey Levine, and Russ R Salakhutdinov. Mis- matched no more: Joint model-policy optimization for model-based rl.Advances in Neural Information Processing Systems, 35:23230–23243, 2022
2022
-
[28]
Jinyuan Fang et al. A comprehensive survey of self-evolving AI agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025
Pith/arXiv arXiv 2025
-
[29]
Industrial robots for manufacturing, 2026
FANUC America. Industrial robots for manufacturing, 2026
2026
-
[30]
Going beyond world models & vlas, April 2026
Pete Florence and the Generalist AI Team. Going beyond world models & vlas, April 2026
2026
-
[31]
Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355, 2025
Pascale Fung, Yoram Bachrach, Asli Celikyilmaz, Kamalika Chaudhuri, Delong Chen, Willy Chung, Emmanuel Dupoux, Hongyu Gong, Herv´ e J´ egou, Alessandro Lazaric, et al. Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355, 2025
arXiv 2025
-
[32]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 2025
Pith/arXiv arXiv 2025
-
[33]
Inverse scaling in test-time compute.Trans- actions on Machine Learning Research, 2025
Aryo Pradipta Gema, Alexander H¨ agele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, Pasquale Min- ervini, Yanda Chen, Joe Benton, and Ethan Perez. Inverse scaling in test-time compute.Trans- actions on Machine Learning Research, 2025
2025
-
[34]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[35]
wake-sleep
Geoffrey E. Hinton, Peter Dayan, Brendan J. Frey, and Radford M. Neal. The “wake-sleep” algorithm for unsupervised neural networks.Science, 268(5214):1158–1161, May 1995. 33
1995
-
[36]
Chi-gyu Hwang. Anthropic’s Claude Opus 4.7 draws backlash after launch over performance and token costs.https://www.digitaltoday.co.kr/en/view/48976/ anthropic-claude-opus-47-faces-backlash-after-launch-over-performance-and-token-costs, April 2026. Reports user criticism and Anthropic response around Opus 4.7 adaptive reasoning. Accessed: 2026-06-03
2026
-
[37]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.\piˆ{*} {0.6}: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[38]
Adaptation of agentic AI: A survey of post-training, memory, and skills
Pengcheng Jiang et al. Adaptation of agentic AI: A survey of post-training, memory, and skills. arXiv preprint arXiv:2512.16301, 2025
arXiv 2025
-
[39]
Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[40]
Approximately optimal approximate reinforcement learning
Sham Kakade and John Langford. Approximately optimal approximate reinforcement learning. InProceedings of the nineteenth international conference on machine learning, pages 267–274, 2002
2002
-
[41]
A natural policy gradient
Sham M Kakade. A natural policy gradient. InAdvances in Neural Information Processing Systems, volume 14, 2001
2001
-
[42]
Immanuel Kant.Kritik der reinen Vernunft. 1781. English translation:Critique of Pure Reason
-
[43]
autoresearch: Ai agents running research on single-gpu nanochat training automatically, March 2026
Andrej Karpathy. autoresearch: Ai agents running research on single-gpu nanochat training automatically, March 2026. GitHub repository
2026
-
[44]
Near-optimal reinforcement learning in polynomial time
Michael Kearns and Satinder Singh. Near-optimal reinforcement learning in polynomial time. Machine learning, 49(2):209–232, 2002
2002
-
[45]
Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
2012
-
[46]
A path towards autonomous machine intelligence version 0.9
Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62, 2022
2022
-
[47]
How should ai learn to understand the world? yann lecun & eric xing on jepa and glp, 2026
Yann LeCun and Eric Xing. How should ai learn to understand the world? yann lecun & eric xing on jepa and glp, 2026. YouTube video; debate at Spring School AI for Impact 2026, Ben Guerir, Morocco, March 25, 2026
2026
-
[48]
Sporks of agi: Why the real thing is better than the next best thing, July 2025
Sergey Levine. Sporks of agi: Why the real thing is better than the next best thing, July 2025
2025
-
[49]
A functional taxonomy of world models
Fei-Fei Li. A functional taxonomy of world models. X post, June 2026. Accessed: 2026-06-05
2026
-
[50]
Harness engineering: leveraging codex in an agent-first world, February 2026
Ryan Lopopolo. Harness engineering: leveraging codex in an agent-first world, February 2026
2026
-
[51]
this article outlines our bet on the path towards building efficient world models
Christopher Manning, Ian Goodfellow, and Fan-Yun Sun. Towards efficient world models. “this article outlines our bet on the path towards building efficient world models...”.https: //x.com/moonlake/status/2029983120087470545, 2026. Posted on X (formerly Twitter). Accessed 2026-04-24
arXiv 2026
-
[52]
Akshay Mete, Shahid Aamir Sheikh, Tzu-Hsiang Lin, Dileep Kalathil, and PR Kumar. Opti- mistic world models: Efficient exploration in model-based deep reinforcement learning.arXiv preprint arXiv:2602.10044, 2026
arXiv 2026
-
[53]
Playwright: Framework for web testing and automation.https://github.com/ microsoft/playwright, 2026
Microsoft. Playwright: Framework for web testing and automation.https://github.com/ microsoft/playwright, 2026. Accessed: 2026-05-09. 34
2026
-
[54]
Never-ending learning.Communications of the ACM, 61(5):103–115, 2018
Tom Mitchell, William Cohen, Estevam Hruschka, Partha Talukdar, Bishan Yang, Justin Bet- teridge, Andrew Carlson, Bhavana Dalvi, Matt Gardner, Bryan Kisiel, et al. Never-ending learning.Communications of the ACM, 61(5):103–115, 2018
2018
-
[55]
Allen Newell and Herbert A. Simon. Computer science as empirical inquiry: Symbols and search.Communications of the ACM, 19(3):113–126, 1976
1976
-
[56]
Three big lessons from the GPT-5 backlash.https://www.platformer.news/ gpt-5-backlash-openai-lessons/, August 2025
Casey Newton. Three big lessons from the GPT-5 backlash.https://www.platformer.news/ gpt-5-backlash-openai-lessons/, August 2025. Discusses user backlash to GPT-5’s invisible model picker and workflow disruption. Accessed: 2026-06-03
2025
-
[57]
Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
NVIDIA. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
Pith/arXiv arXiv 2026
-
[58]
Isaac Lab: A unified framework for robot learning.https://developer.nvidia
NVIDIA. Isaac Lab: A unified framework for robot learning.https://developer.nvidia. com/isaac/lab, 2026
2026
-
[59]
Learning to reason with LLMs
OpenAI. Learning to reason with LLMs. 2024
2024
-
[60]
Swarm: Educational framework for multi-agent orchestration, 2024
OpenAI. Swarm: Educational framework for multi-agent orchestration, 2024. Released October 2024; succeeded by the Agents SDK
2024
-
[61]
Computer-using agent, January 2025
OpenAI. Computer-using agent, January 2025
2025
-
[62]
Introducing GPT-5.https://openai.com/index/introducing-gpt-5/, August
OpenAI. Introducing GPT-5.https://openai.com/index/introducing-gpt-5/, August
-
[63]
Accessed: 2026-06-03
2026
-
[64]
Openclaw, 2026
openclaw. Openclaw, 2026. Open-source personal AI assistant, accessed 2026-02-26
2026
-
[65]
we are near the end of the exponential
Dwarkesh Patel. Dario amodei—“we are near the end of the exponential”. Dwarkesh Podcast
-
[66]
Crispr-gpt for agentic automation of gene-editing experiments.Nature Biomedical Engineering, pages 1–14, 2025
Yuanhao Qu, Kaixuan Huang, Ming Yin, Kanghong Zhan, Dyllan Liu, Di Yin, Henry C Cousins, William A Johnson, Xiaotong Wang, Mihir Shah, et al. Crispr-gpt for agentic automation of gene-editing experiments.Nature Biomedical Engineering, pages 1–14, 2025
2025
-
[67]
Harness design for long-running application development, March 2026
Prithvi Rajasekaran. Harness design for long-running application development, March 2026
2026
-
[68]
Russell.Human Compatible: Artificial Intelligence and the Problem of Control
Stuart J. Russell.Human Compatible: Artificial Intelligence and the Problem of Control. Viking, New York, 2019
2019
-
[69]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational Conference on Machine Learning, pages 1889–1897, 2015
2015
-
[70]
Blade runner
Ridley Scott. Blade runner. Film, 1982. Directed by Ridley Scott
1982
-
[71]
Selenium webdriver, 2026
SeleniumHQ. Selenium webdriver, 2026. Version 4.40.0, accessed 2026-02-26
2026
-
[72]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[73]
Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanc- tot, et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016. 35
2016
-
[74]
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv preprint arXiv:1712.01815, 2017
Pith/arXiv arXiv 2017
-
[75]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms.arXiv preprint arXiv:2505.00127, 2025
arXiv 2025
-
[76]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[77]
Tongyi deepresearch: A new era of open-source ai researchers
Tongyi DeepResearch Team. Tongyi deepresearch: A new era of open-source ai researchers. https://github.com/Alibaba-NLP/DeepResearch, 2025
2025
-
[78]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345,
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345,
-
[79]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
Pith/arXiv arXiv 2025
-
[80]
Self-driving car technology for a reliable ride, 2026
Waymo. Self-driving car technology for a reliable ride, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.