MedEvoEval: Evaluating Continual Evolution of Doctor Agents through Simulated Clinical Episodes
Pith reviewed 2026-06-30 09:30 UTC · model grok-4.3
The pith
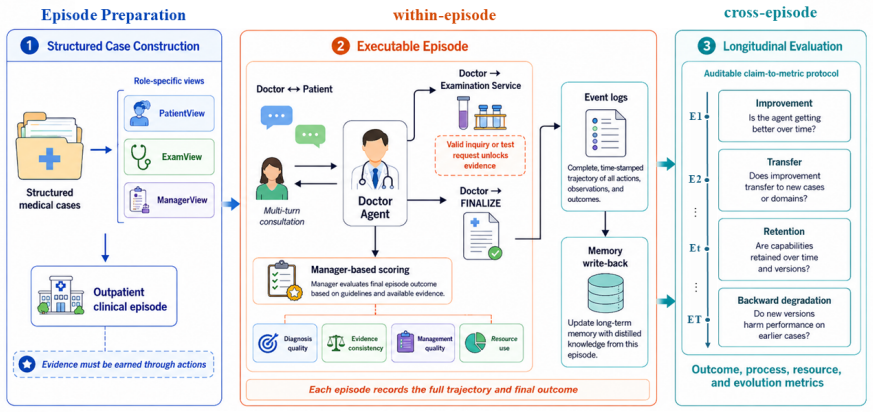
MedEvoEval supplies an executable framework of action-gated simulated episodes to measure whether doctor agents improve, transfer skills, and retain capabilities across repeated clinical encounters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
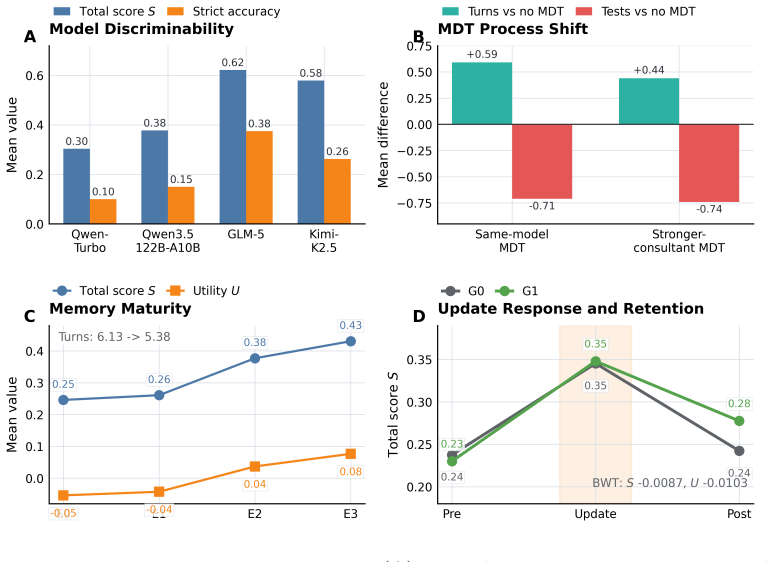
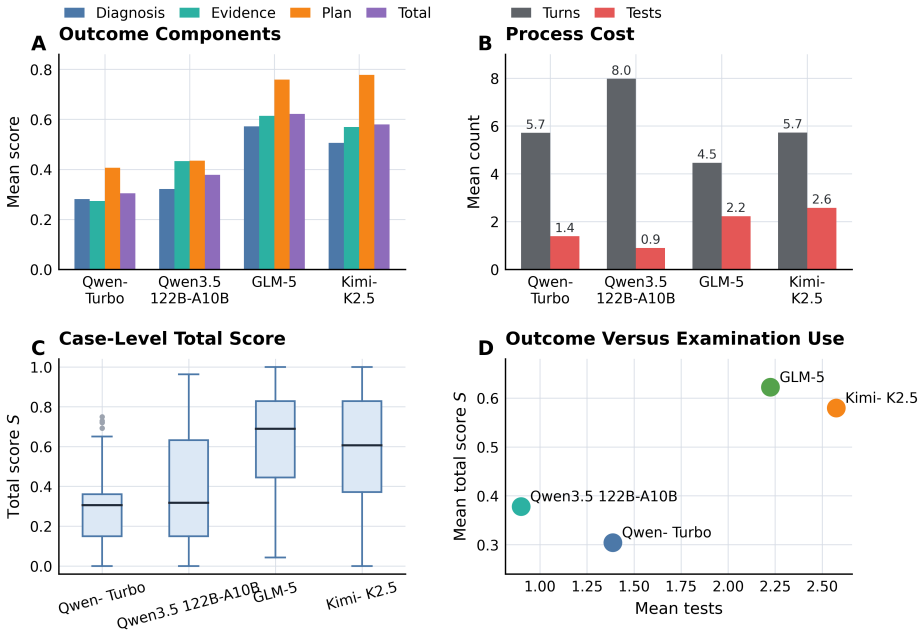
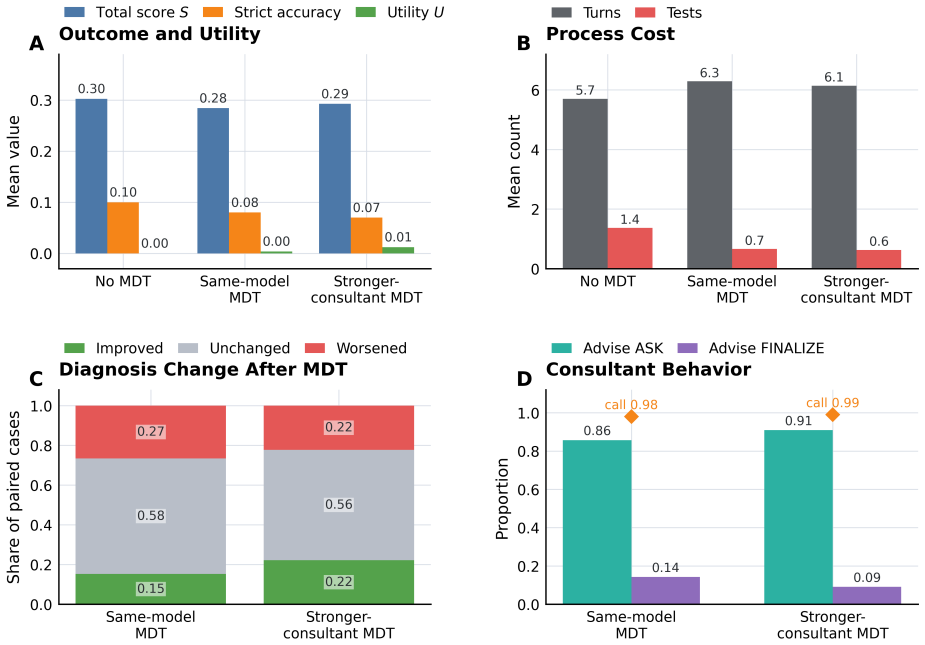
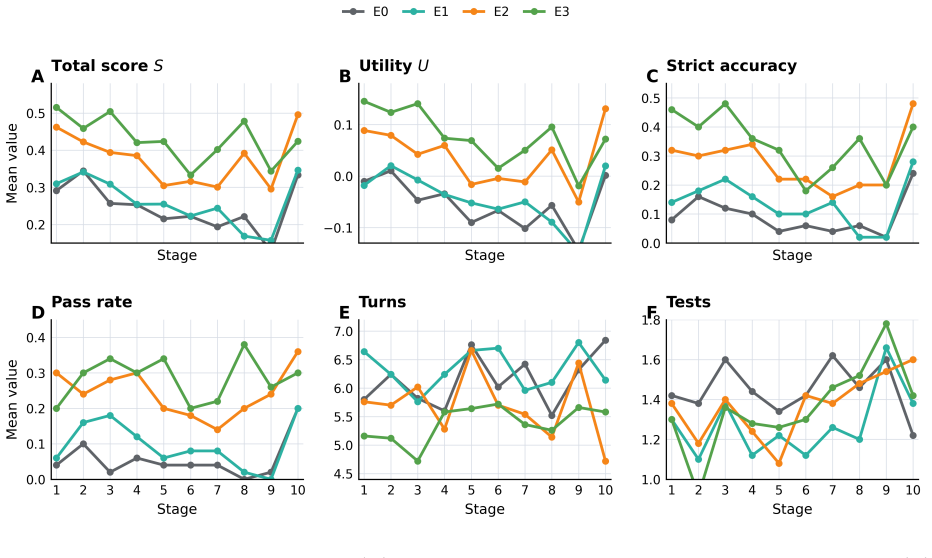
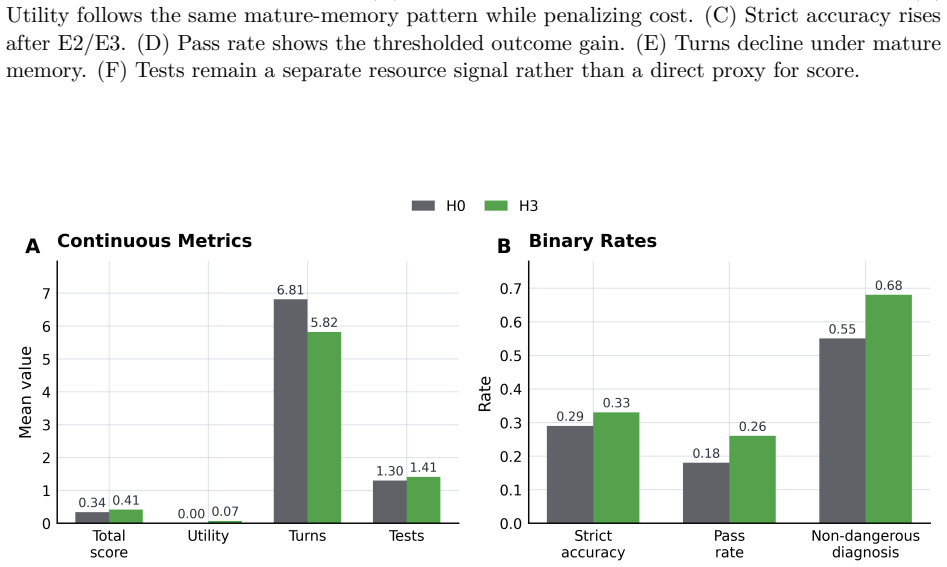
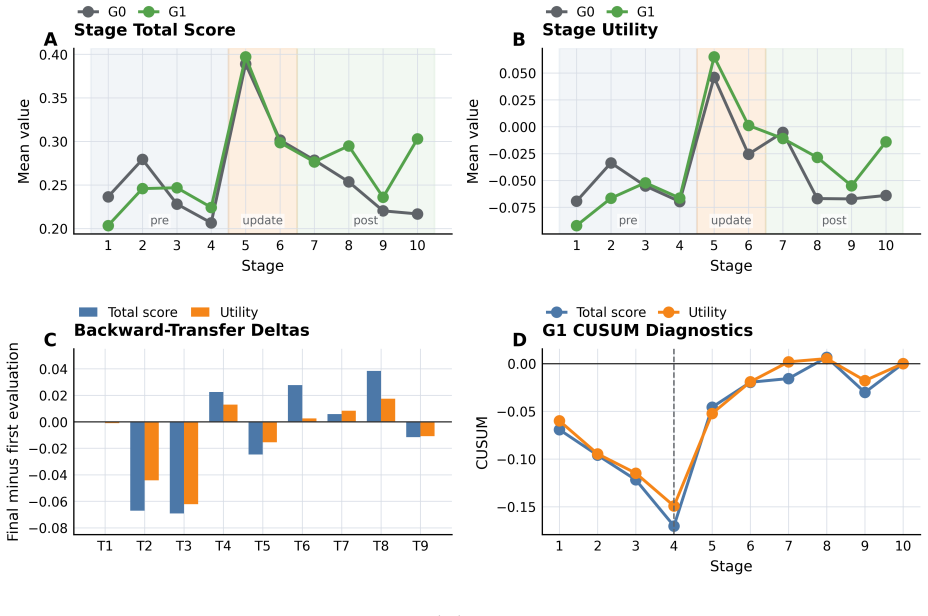
MedEvoEval provides a concrete basis for evaluating whether doctor agents improve through experience, transfer useful behavior, and retain earlier capabilities over time. Each source case becomes executable outpatient episodes with action-gated evidence access; structured traces record the full sequence of observations, actions, final outputs, and manager scores, plus optional experience write-back. Experiments with the released artifact of 700 episodes demonstrate that these traces surface process costs invisible to final-answer scoring, show resource reallocation under MDT-style consultation, and enable direct longitudinal analyses of memory, transfer, update response, and retention.
What carries the argument
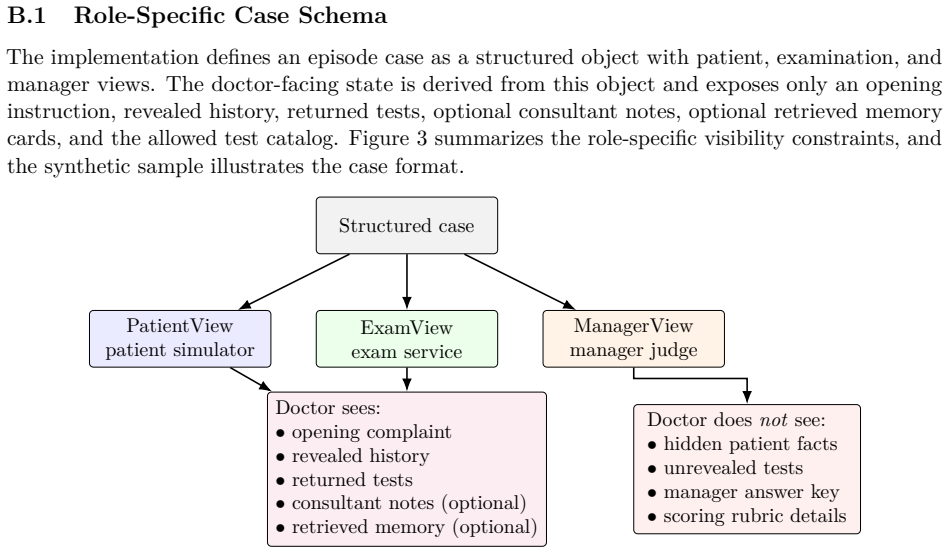
MedEvoEval, an executable longitudinal evaluation framework that converts cases into role-specific views, gates evidence behind valid actions, and records structured traces of observations, actions, scores, and experience updates.
If this is right
- Episode traces reveal process costs such as unnecessary consultations or repeated tests that final-answer scoring conceals.
- MDT-style consultation changes how agents allocate examination and manager resources within an episode.
- Longitudinal runs can quantify memory maturation, held-out transfer of behaviors, response to update stages, and backward retention of prior capabilities.
- The released artifact supplies schemas, runner, scoring scripts, and derivatives that let others replicate or extend the same measurements.
Where Pith is reading between the lines
- If agents demonstrate measurable improvement on the framework, the same trace format could be adapted to test continual learning in other sequential decision domains such as legal case handling.
- The action-gated design makes it possible to insert controlled interventions at specific steps and measure their downstream effect on later episodes.
- Release of the full E&D artifact lowers the barrier for comparing different memory or reflection mechanisms under identical longitudinal conditions.
Load-bearing premise
The simulated outpatient episodes with action-gated evidence access and structured traces accurately model real clinical information gathering and decision evolution without introducing artifacts that distort measurements of agent improvement or retention.
What would settle it
Run the same set of agents on MedEvoEval and on a matched set of real outpatient cases; if the ranking of agents by improvement and retention differs substantially between the two, the simulation's validity for measuring continual evolution is challenged.
Figures
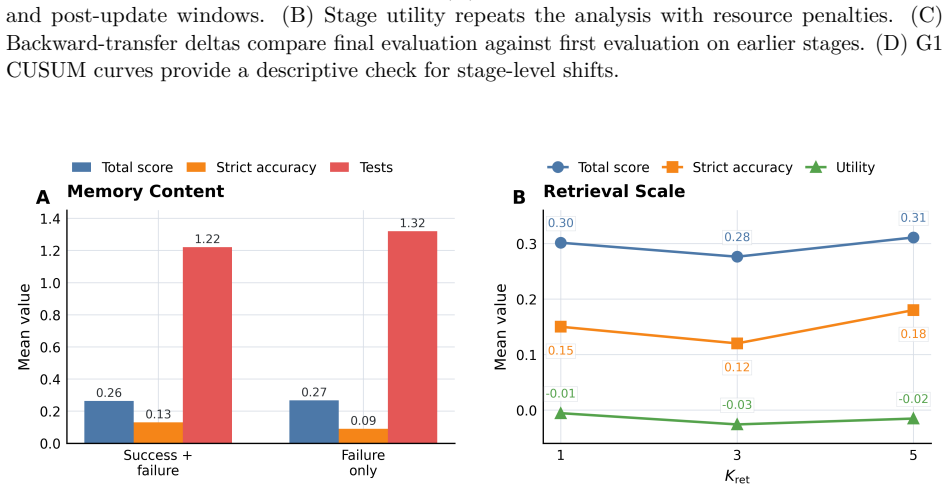
read the original abstract
Doctor agents are moving beyond single-turn answer generation toward evolving clinical decision systems. Within an outpatient episode, they acquire evidence, use examination and consultation resources, and decide when to finalize a diagnosis and management plan. Across episodes, their behavior may change through memory, retrieval, reflection, or other update mechanisms. Current evaluations only partially cover this setting. Fixed-input medical QA benchmarks score final answers from complete inputs, whereas many interactive benchmarks still focus on individual encounters or fixed runs, providing limited support for evaluating how episode-level decisions interact with cross-episode experience. We introduce MedEvoEval, an executable longitudinal evaluation framework based on action-gated simulated outpatient episodes. Each source case is converted into role-specific patient, examination, and manager views; evidence is revealed only through valid actions; and each episode records a structured trace that links observations, actions, final outputs, manager scores, and optional experience write-back. We release a runnable E&D artifact with 700 processed episodes, provenance notes, schemas, an episode runner, scoring scripts, configurations, example logs, analysis code, and trajectory- and step-level derivatives. Experiments show that episode traces expose process costs hidden by final-answer scoring, show how MDT-style consultation reallocates resources, and support longitudinal analyses of memory maturation, held-out transfer, update-stage response, and backward retention. Together, these results show that MedEvoEval provides a concrete basis for evaluating whether doctor agents improve through experience, transfer useful behavior, and retain earlier capabilities over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedEvoEval, an executable longitudinal evaluation framework for doctor agents based on action-gated simulated outpatient episodes. Each source case is converted into role-specific patient, examination, and manager views with evidence revealed only through valid actions; episodes record structured traces linking observations, actions, final outputs, manager scores, and optional experience write-back. The authors release a runnable artifact with 700 processed episodes, provenance notes, schemas, an episode runner, scoring scripts, configurations, example logs, and analysis code. Experiments illustrate that traces expose process costs hidden by final-answer scoring, show resource reallocation under MDT-style consultation, and support longitudinal analyses of memory maturation, held-out transfer, update-stage response, and backward retention, thereby providing a concrete basis for evaluating whether doctor agents improve through experience, transfer useful behavior, and retain earlier capabilities.
Significance. If the simulation mechanics produce measurements that reflect transferable clinical behavior rather than artifacts, the framework fills a gap between fixed-input medical QA benchmarks and single-encounter interactive evaluations by enabling assessment of cross-episode evolution. The release of the full E&D artifact (700 episodes, runner, scoring scripts, provenance, and analysis code) is a clear strength that supports reproducibility and extension by other researchers.
major comments (1)
- [Episode construction and trace recording (abstract and methods)] The central claim that episode traces support valid longitudinal analyses of improvement, transfer, and retention requires that the action-gated outpatient episodes and structured traces accurately model real clinical information gathering without introducing distorting artifacts. The manuscript describes conversion of source cases into role-specific views with evidence revealed only via valid actions and manager scoring, but reports no external anchoring such as correlation of trace statistics with real physician sequences or expert realism ratings. This is load-bearing for the claim in the abstract and the experiments section on longitudinal analyses.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger grounding of the simulation's fidelity. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Episode construction and trace recording (abstract and methods)] The central claim that episode traces support valid longitudinal analyses of improvement, transfer, and retention requires that the action-gated outpatient episodes and structured traces accurately model real clinical information gathering without introducing distorting artifacts. The manuscript describes conversion of source cases into role-specific views with evidence revealed only via valid actions and manager scoring, but reports no external anchoring such as correlation of trace statistics with real physician sequences or expert realism ratings. This is load-bearing for the claim in the abstract and the experiments section on longitudinal analyses.
Authors: We agree that external anchoring (e.g., correlation of trace statistics with real physician sequences or expert realism ratings) is absent from the current manuscript and would strengthen claims about the absence of distorting artifacts. The framework prioritizes controlled, reproducible simulation with action-gated evidence release and manager scoring to enable longitudinal tracking; source cases are converted into role-specific views with provenance documented in the released artifact. However, this design choice means we do not claim direct ecological validity. In revision we will (1) add an explicit Limitations subsection in the Discussion that addresses simulation fidelity, the lack of real-world correlation data, and reliance on internal consistency mechanisms, and (2) qualify the abstract and experiments section to state that MedEvoEval supplies a controlled basis for evaluating agent evolution rather than asserting direct modeling of real clinical sequences. revision: yes
Circularity Check
Framework proposal exhibits no circularity in derivation chain
full rationale
The paper introduces MedEvoEval as an executable longitudinal evaluation framework based on action-gated simulated outpatient episodes, with released artifacts including 700 episodes, schemas, runner, and analysis code. No mathematical derivations, parameter fittings, predictions of quantities from fitted inputs, or load-bearing self-citations appear in the text. The central claim—that the framework provides a concrete basis for evaluating agent improvement, transfer, and retention—is presented as a direct consequence of the defined simulation mechanics and trace structures, without reducing to self-defined quantities or prior author results by construction. This is a standard framework proposal whose validity rests on external validation of simulation fidelity rather than internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Converting source cases into role-specific patient, examination, and manager views with action-gated evidence produces traces that meaningfully reflect clinical decision dynamics.
Reference graph
Works this paper leans on
-
[1]
Medagentsim: Self-evolving multi-agent simulations for realistic clinical interactions
Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. Medagentsim: Self-evolving multi-agent simulations for realistic clinical interactions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 362–372. Springer, 2025
2025
-
[2]
Hierarchical multi-scale feature fusion network for multi- center major depressive disorder classification with T1-weighted MRI
Zhaoyang Cong, Ziyang Wang, Hao Zhang, Guowei Zheng, Keming Cao, Lina Zhao, Ruipeng Song, Jianqing Li, and Chengyu Liu. Hierarchical multi-scale feature fusion network for multi- center major depressive disorder classification with T1-weighted MRI. In2025 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), ...
2025
-
[3]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, and Fei Huang. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. InProceedings of the 31st International Conference on Computational Linguistics, pages 10183–10213. Association for Computational Linguistics, 2025
2025
-
[4]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. Medagentbench: A realistic virtual ehr environment to benchmark medical llm agents.arXiv preprint arXiv:2501.14654, 2025
-
[6]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. doi: 10.3390/app11146421
-
[7]
Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J. Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. MIMIC-IV, a freely accessible electronic health record dataset.Scientific Data, 10(1):1, 2023
2023
-
[8]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, et al. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.arXiv preprint arXiv:2205.00445, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S. Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W. Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
2024
-
[10]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kahn, Mike Power, Daniel Khashabi, Tushar Khot, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[11]
Mmedagent: Learning to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, and Yixin Wang. Mmedagent: Learning to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, 2024
2024
-
[12]
CAMEL: Communicative agents for “mind” exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society. InAdvances in Neural Information Processing Systems, volume 36, pages 51991–52008, 2023
2023
-
[13]
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma, et al. Agent hospital: A simulacrum of hospital with evolvable medical agents.arXiv preprint arXiv:2405.02957, 2024
-
[14]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, volume 30, 2017. 12
2017
-
[15]
arXiv preprint arXiv:2311.16452 , year=
Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, et al. Can generalist foundation models outcompete special-purpose tuning? case study in medicine.arXiv preprint arXiv:2311.16452, 2023
-
[16]
Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xiaoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, Matthew P. Lungren, et al. Sequential diagnosis with language models.arXiv preprint arXiv:2506.22405, 2025
-
[17]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InProceedings of the Conference on Health, Inference, and Learning, pages 248–260. PMLR, 2022
2022
-
[18]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
2019
-
[19]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023. doi: 10.1145/3586183.3606763
-
[20]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
2023
-
[21]
HuggingGPT: Solving AI tasks with ChatGPT and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI tasks with ChatGPT and its friends in hugging face. InAdvances in Neural Information Processing Systems, volume 36, pages 38154–38180, 2023
2023
-
[22]
Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
2025
-
[23]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, pages 8634–8652, 2023
2023
-
[24]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. Agentic retrieval-augmented generation: A survey on agentic RAG.arXiv preprint arXiv:2501.09136, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Pfohl, Heather Cole-Lewis, et al
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature Medicine, 31(3):943–950, 2025
2025
-
[26]
Medagents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. Medagents: Large language models as collaborators for zero-shot medical reasoning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 599–621. Association for Computational Linguistics, 2024
2024
-
[27]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024. 13
2024
-
[28]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
2024
-
[29]
Jinjie Wei, Dingkang Yang, Yanshu Li, Qingyao Xu, Zhaoyu Chen, Mingcheng Li, Yue Jiang, Xiaolu Hou, and Lihua Zhang. MedAide: Towards an omni medical aide via specialized LLM-based multi-agent collaboration.arXiv preprint arXiv:2410.12532, 2024
-
[30]
Chaoyi Wu, Weixiong Lin, Xiaoming Zhang, Ya Zhang, Weidi Xie, and Yanfeng Wang. PMC- LLaMA: Toward building open-source language models for medicine.Journal of the American Medical Informatics Association, 31(9):1833–1843, 2024. doi: 10.1093/jamia/ocae045
-
[31]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
2024
-
[32]
Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
-
[33]
Failures pave the way: Enhancing large language models through tuning-free rule accumulation
Zeyuan Yang, Peng Li, and Yang Liu. Failures pave the way: Enhancing large language models through tuning-free rule accumulation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1751–1777, 2023
2023
-
[34]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[35]
Evaluation of retrieval-augmented generation: A survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. Evaluation of retrieval-augmented generation: A survey. InCCF Conference on Big Data, pages 102–120. Springer, 2024
2024
-
[36]
Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, and Hao Xu. Sensitivity-LoRA: Low-load sensitivity-based fine-tuning for large language models.arXiv preprint arXiv:2509.09119, 2025
-
[37]
Hao Zhang, Zhenjia Li, Runfeng Bao, Yifan Gao, Xi Xiao, Heng Zhang, Shuyang Zhang, Bo Huang, Yuhang Wu, Tianyang Wang, et al. HyperAdaLoRA: Accelerating LoRA rank allocation during training via hypernetworks without sacrificing performance.arXiv preprint arXiv:2510.02630, 2025
-
[38]
Hao Zhang, Mengsi Lyu, Zhuo Chen, Xingrun Xing, Yulong Ao, and Yonghua Lin. Pdtrim: Targeted pruning for prefill-decode disaggregation in inference.arXiv preprint arXiv:2509.04467, 2025
-
[39]
Hao Zhang, Mengsi Lyu, Chenrui He, Yulong Ao, and Yonghua Lin. TrimTokenator: Towards adaptive visual token pruning for large multimodal models.arXiv preprint arXiv:2509.00320, 2025
-
[40]
Hao Zhang, Mengsi Lyu, Bo Huang, Yulong Ao, and Yonghua Lin. TrimTokenator-LC: Towards adaptive visual token pruning for large multimodal models with long contexts.arXiv preprint arXiv:2512.22748, 2025. 14 A Artifact Inventory and Responsible Use This appendix documents the released executable evaluation artifact forMedEvoEval. The artifact contains the s...
-
[41]
Output valid JSON only
-
[42]
Choose exactly one action from: ASK, REQUEST_TEST, CALL_MDT, FINALIZE
-
[43]
Do not invent symptoms, examination results, laboratory values, imaging findings, or prior diagnoses
-
[44]
REQUEST_TEST must use an exact test_name from the allowed catalog
-
[45]
CALL_MDT may ask for diagnostic advice, but the final decision remains your responsibility
-
[46]
Provide diagnosis, evidence, plan, and followup
FINALIZE only when evidence is sufficient or the turn limit requires termination. Provide diagnosis, evidence, plan, and followup
-
[47]
Use retrieved memory cards as experience hints, not as patient facts. Episode state: - patient_opening: {patient_opening} - allowed_tests: {allowed_tests} - max_total_turns: {max_total_turns} - max_tests_per_visit: {max_tests_per_visit} - revealed_history: {revealed_history} - returned_tests: {returned_tests} - consultant_notes: {consultant_notes} - retri...
-
[48]
Do not diagnose yourself
-
[49]
Do not reveal examination, laboratory, imaging, or manager-only fields
-
[50]
If the doctor asks about a listed hidden_history_fact, answer directly
-
[51]
If the doctor asks about something not specified, say that you are not sure or that you do not recall
-
[52]
Keep the answer natural, brief, and patient-like
-
[53]
answer":
Output valid JSON only. hidden_patient_view: {patient_view} doctor_question: {question} Return: { 17 "answer": "string", "revealed_facts": ["fact id or short fact text"], "unanswered_reason": "none|not_in_patient_view|unclear_question" } Prompt B.3: Examination-service prompt You are an examination-result service for a simulated outpatient episode. Return...
-
[54]
Match the requested test to the closest allowed catalog item
-
[55]
If there is no allowed match, return returned=false and do not invent a result
-
[56]
If the test is available, return the stored result verbatim or as a concise paraphrase without adding new findings
-
[57]
returned
Output valid JSON only. allowed_tests: {allowed_tests} exam_view: {exam_view} requested_test: {requested_test} Return: { "returned": true, "matched_test_name": "string", "match_type": "exact|alias|none", "result": "string", "reason": "string" } Prompt B.4: MDT-consultant prompt You are an MDT consultant in a simulated diagnostic episode. Provide a second ...
-
[58]
You cannot order tests directly
-
[59]
You cannot access hidden labels or unrevealed examination results
-
[60]
Recommend at most one next question if more information is needed
-
[61]
If the evidence is sufficient, recommend FINALIZE and give a concise diagnosis suggestion
-
[62]
action":
Output valid JSON only. revealed_context: {revealed_context} attending_state: {attending_state} 18 B.3 Structured Output Templates Template B.1: Doctor structured output { "action": "ASK|REQUEST_TEST|CALL_MDT|FINALIZE", "utterance": "string", "question": "string", "test_name": "string", "rationale": ["string"], "working_diagnoses": ["string"], "needs_mdt"...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.