MiniOpt: Reasoning to Model and Solve General Optimization Problems with Limited Resources
Pith reviewed 2026-06-26 05:16 UTC · model grok-4.3
The pith
MiniOpt trains 3B language models to solve diverse optimization problems accurately via reinforcement learning without expert data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
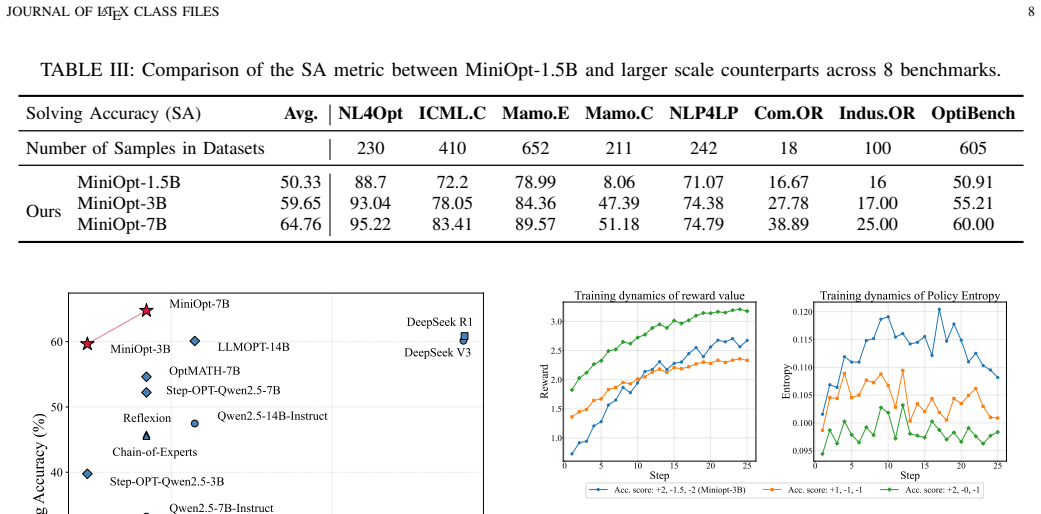
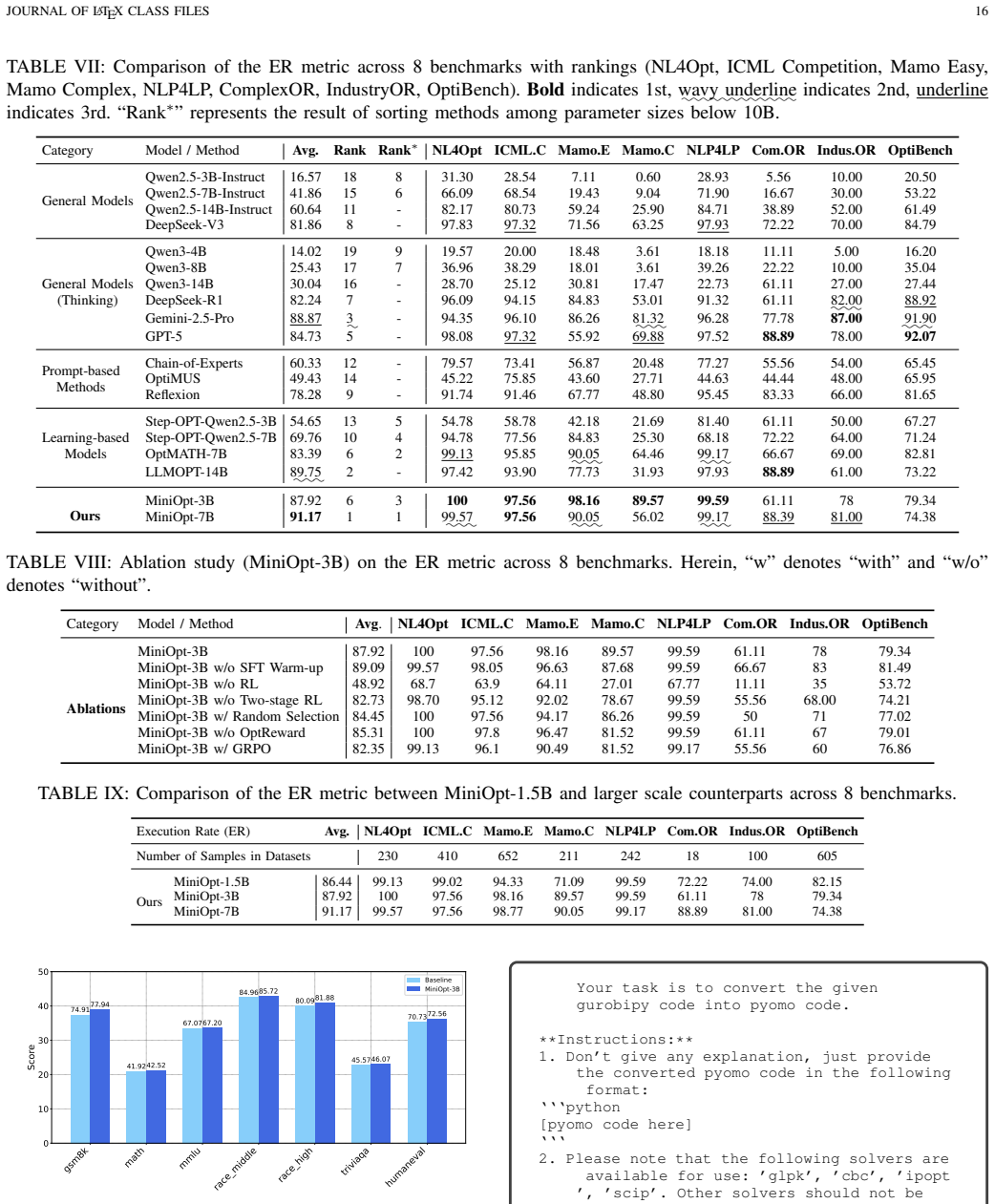
MiniOpt-3B exhibits strong optimization generalization across various optimization types, problem scenarios, and task domains. For models with fewer than 10B parameters, MiniOpt series achieves the highest average solving accuracy (SA). For models with more than 10B parameters, MiniOpt still shows competitive performance.
What carries the argument
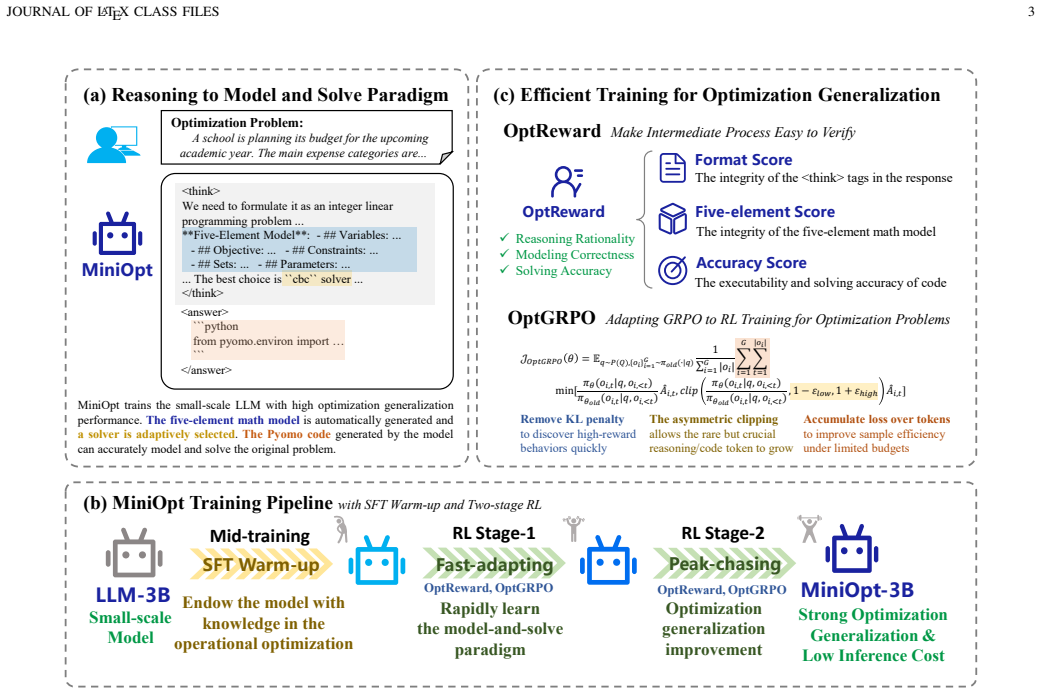
The reasoning-to-model-and-solve paradigm together with OptReward, a hierarchical reward function that jointly scores formulation and solution, plus an optimization-oriented policy optimization strategy for efficient exploration.
If this is right
- Compact models under 10B parameters reach the highest average solving accuracy on optimization tasks compared with other approaches.
- Optimization problems can be addressed without large-scale supervised datasets, costly annotations, or intermediate step verification.
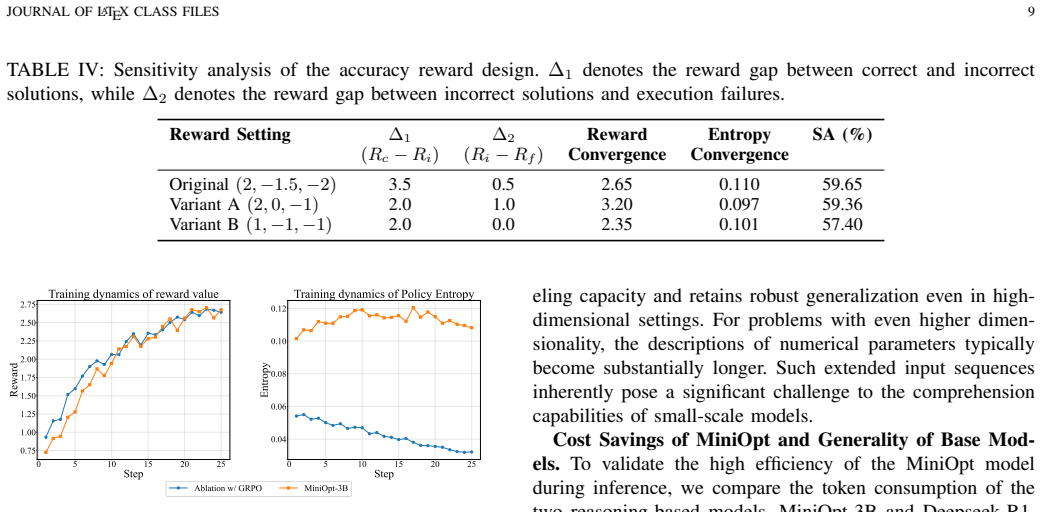
- The hierarchical reward enables stable reinforcement learning and efficient exploration specifically for smaller models.
- Generalization holds across optimization types, problem scenarios, and task domains.
Where Pith is reading between the lines
- The same reward design could be adapted to train small models on other structured reasoning tasks such as planning or scheduling.
- Deployment on edge devices becomes feasible once optimization capability fits inside a 3B model.
- Hybrid systems might combine the generated solvers with traditional optimization libraries for further gains.
Load-bearing premise
The OptReward hierarchical scoring function can jointly evaluate formulation and solution quality to drive effective policy learning without any expert demonstrations.
What would settle it
A test showing that a 3B model trained with MiniOpt achieves no higher solving accuracy than baselines on a held-out class of optimization problems never encountered during training.
Figures


read the original abstract
Achieving strong optimization generalization across diverse optimization problems while requiring limited training resources remains a challenging problem for optimization-oriented large language models (LLMs). Existing approaches typically rely on large-scale supervised datasets, costly reasoning annotations, and expensive intermediate step verification, resulting in substantial training overhead. To address these challenges, we propose MiniOpt, a reinforcement learning framework that learns to solve optimization problems through an "reasoning-to-model-and-solve" paradigm. MiniOpt decomposes optimization reasoning into structured optimization modeling and executable solver generation. Building upon this paradigm, we introduce OptReward, a reward function with hierarchical score structure that jointly evaluates formulation and solution, enabling effective policy learning without expert demonstrations. We further develop an optimization-oriented policy optimization strategy that improves exploration efficiency and stabilizes reinforcement learning for compact models. Extensive experiments show that MiniOpt-3B exhibits strong optimization generalization across various optimization types, problem scenarios, and task domains. For models with fewer than 10B parameters, MiniOpt series achieves the highest average solving accuracy (SA). For models with more than 10B parameters, MiniOpt still shows competitive performance. These results suggest that optimization-oriented reward design and reinforcement learning provide an effective pathway for developing compact optimization-specialized language models with strong optimization generalization capabilities. The code is available at https://github.com/Hsiang-1/MiniOpt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MiniOpt, a reinforcement learning framework for optimization problems that decomposes reasoning into structured modeling and executable solver generation. It introduces OptReward, a hierarchical scoring function that jointly evaluates formulation and solution to enable policy learning without expert demonstrations, along with an optimization-oriented policy optimization strategy for improved exploration in compact models. The central claim is that MiniOpt-3B exhibits strong optimization generalization across problem types, scenarios, and domains, achieving the highest average solving accuracy (SA) among models with fewer than 10B parameters while remaining competitive for larger models.
Significance. If the experimental results hold, the work would demonstrate an effective pathway for resource-efficient, optimization-specialized LLMs via reward design and RL rather than large supervised datasets. The public release of code at https://github.com/Hsiang-1/MiniOpt is a positive contribution to reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that MiniOpt-3B achieves the highest average SA among sub-10B models across diverse optimization types is presented without any description of datasets, baselines, statistical tests, number of runs, or controls for confounding factors, so the data-to-claim link cannot be evaluated.
- [OptReward] OptReward section: the hierarchical reward is load-bearing for the no-expert-demonstrations claim, yet the manuscript provides no analysis of whether its components were tuned post-hoc to the reported outcomes or whether any 'predictions' reduce to fitted quantities, raising a circularity risk for the generalization results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MiniOpt-3B achieves the highest average SA among sub-10B models across diverse optimization types is presented without any description of datasets, baselines, statistical tests, number of runs, or controls for confounding factors, so the data-to-claim link cannot be evaluated.
Authors: The abstract is intentionally concise. Full details on datasets (diverse optimization benchmarks spanning types, scenarios, and domains), baselines (comparable LLMs under 10B parameters), evaluation protocol, and controls appear in Sections 4 and 5. To strengthen the data-to-claim link within the abstract's length constraints, we will add a brief clause such as 'evaluated on standard optimization benchmarks against peer sub-10B models.' revision: yes
-
Referee: [OptReward] OptReward section: the hierarchical reward is load-bearing for the no-expert-demonstrations claim, yet the manuscript provides no analysis of whether its components were tuned post-hoc to the reported outcomes or whether any 'predictions' reduce to fitted quantities, raising a circularity risk for the generalization results.
Authors: OptReward components were fixed a priori using standard optimization metrics for formulation correctness and solution feasibility; no post-hoc tuning to experimental outcomes occurred. To directly address the circularity concern, we will expand the OptReward section with a short paragraph documenting the design rationale and confirming independence from reported results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present an empirical RL framework (reasoning-to-model-and-solve paradigm, OptReward hierarchical scoring, optimization-oriented policy optimization) whose performance claims rest on experimental results across optimization problems. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are exhibited in the provided text that would reduce the central claims to inputs by construction. OptReward is described as an enabling design choice for policy learning without expert data, not a quantity whose components are shown to be post-hoc tuned or mathematically forced. This qualifies as a normal self-contained empirical paper with score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flexible job-shop scheduling via graph neural network and deep reinforcement learning,
W. Song, X. Chen, Q. Li, and Z. Cao, “Flexible job-shop scheduling via graph neural network and deep reinforcement learning,” IEEE Transactions on Industrial Informatics, vol. 19, no. 2, pp. 1600–1610, 2023
2023
-
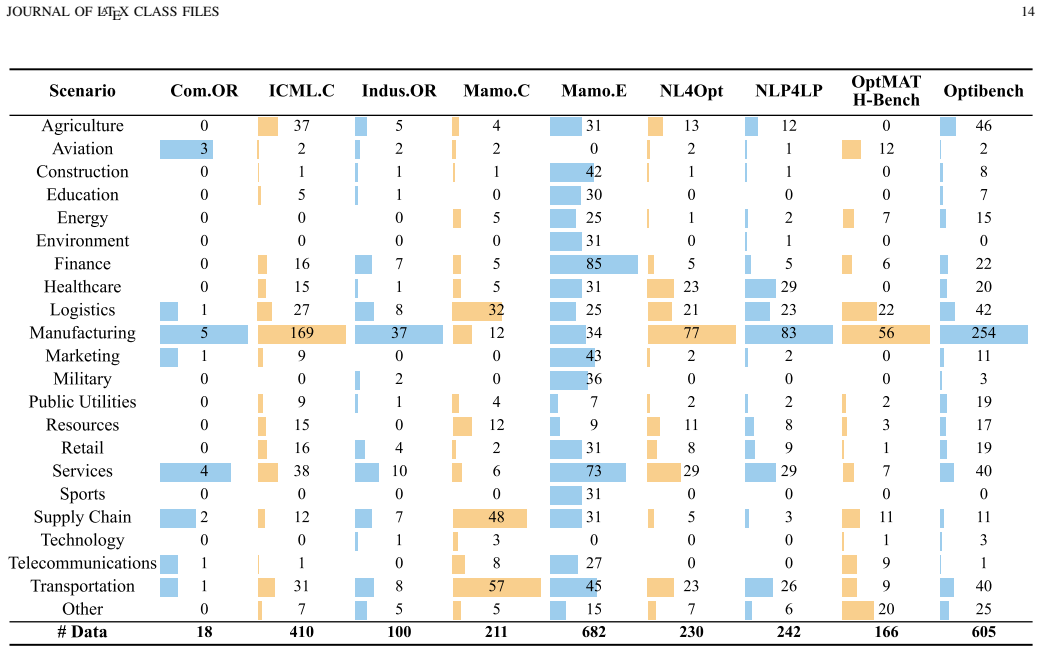
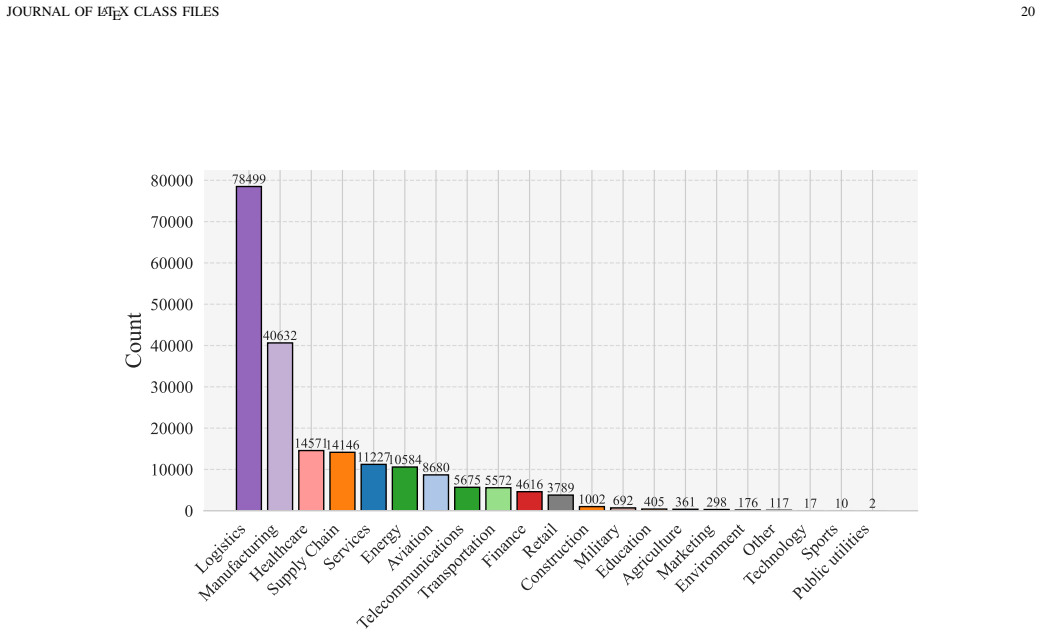
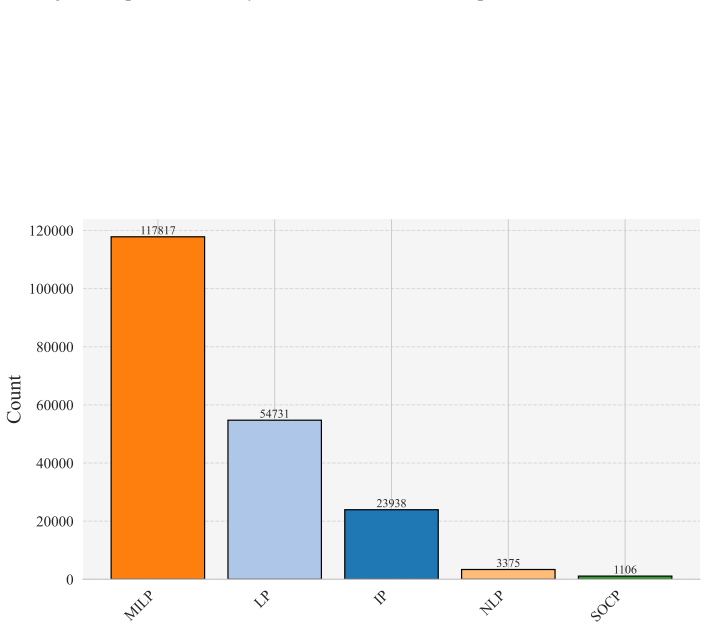
[2]
Ars: Automatic routing solver with large language models,
K. Li, F. Liu, Z. Wang, X. Tong, X. Han, M. Yuan, and Q. Zhang, “Ars: Automatic routing solver with large language models,” CoRR, vol. abs/2502.15359, 2025
arXiv 2025
-
[3]
CAFA: Coding as auto-formulation can boost large language models in solving linear programming problem,
H. Deng, B. Zheng, Y . Jiang, and T. H. Tran, “CAFA: Coding as auto-formulation can boost large language models in solving linear programming problem,” in The 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024. [Online]. Available: https: //openreview.net/forum?id=xC2xtBLmri
2024
-
[4]
AutoSAT: Automatically optimize SAT solvers via large language models,
Y . Sun, F. Ye, X. Zhang, S. Huang, B. Zhang, K. Wei, and S. Cai, “AutoSAT: Automatically optimize SAT solvers via large language models,” CoRR, vol. abs/2402.10705, 2024
arXiv 2024
-
[5]
AutoPBO: LLM-powered optimization for local search PBO solvers,
J. Li, Y . Chu, Y . Sun, M. Zou, and S. Cai, “AutoPBO: LLM-powered optimization for local search PBO solvers,” CoRR, vol. abs/2509.04007, 2025
arXiv 2025
-
[6]
LLMOPT: learning to define and solve general optimization problems from scratch,
C. Jiang, X. Shu, H. Qian, X. Lu, J. Zhou, A. Zhou, and Y . Yu, “LLMOPT: learning to define and solve general optimization problems from scratch,” in Advances in The Thirteenth International Conference on Learning Representations, Singapore, 2025
2025
-
[7]
BPP-search: Enhancing tree of thought reasoning for mathematical modeling problem solving,
T. Wang, W. Y . Yu, Z. He, Z. Liu, H. HaileiGong, H. Wu, X. Han, W. Shi, R. She, F. Zhu, and T. Zhong, “BPP-search: Enhancing tree of thought reasoning for mathematical modeling problem solving,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pi...
2025
-
[8]
Text2Zinc: A cross- domain dataset for modeling optimization and satisfaction problems in MiniZinc,
A. Singirikonda, S. Kadioglu, and K. Uppuluri, “Text2Zinc: A cross- domain dataset for modeling optimization and satisfaction problems in MiniZinc,” CoRR, vol. abs/2503.10642, 2025
arXiv 2025
-
[9]
Training LLMs for optimization modeling via iterative data synthesis and structured validation,
Y . Wu, Y . Zhang, Y . Wu, Y . Wang, J. Zhang, and J. Cheng, “Training LLMs for optimization modeling via iterative data synthesis and structured validation,” in Findings of the Association for Computational Linguistics: EMNLP 2025, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics,...
2025
-
[10]
OptMATH: A scalable bidirectional data synthesis framework for optimization mod- eling,
H. Lu, Z. Xie, Y . Wu, C. Ren, Y . Chen, and Z. Wen, “OptMATH: A scalable bidirectional data synthesis framework for optimization mod- eling,” in Forty-second International Conference on Machine Learning, 2025
2025
-
[11]
A survey of optimization modeling meets LLMs: Progress and future directions,
Z. Xiao, J. Xie, L. Xu, S. Guan, J. Zhu, X. Han, X. Fu, W. Yu, H. Wu, W. Shi, Q. Kang, J. Duan, T. Zhong, M. Yuan, J. Zeng, Y . Wang, G. Chen, and D. Zhang, “A survey of optimization modeling meets LLMs: Progress and future directions,” in Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25, J. Kwok, Ed. In...
2025
-
[12]
An agent-based framework for the automatic validation of mathematical optimization models,
A. Zadorojniy, S. Wasserkrug, and E. Farchi, “An agent-based framework for the automatic validation of mathematical optimization models,” 2025. [Online]. Available: https://arxiv.org/abs/2511.16383
Pith/arXiv arXiv 2025
-
[13]
Equivamap: Leveraging LLMs for automatic equivalence checking of optimization formulations,
H. Zhai, C. Lawless, E. Vitercik, and L. Leqi, “Equivamap: Leveraging LLMs for automatic equivalence checking of optimization formulations,” in 2nd AI for Math Workshop @ ICML 2025, 2025. [Online]. Available: https://openreview.net/forum?id=RvdjzNlksm
2025
-
[14]
OptiMUS: Scalable opti- mization modeling with (MI)LP solvers and large language models,
A. AhmadiTeshnizi, W. Gao, and M. Udell, “OptiMUS: Scalable opti- mization modeling with (MI)LP solvers and large language models,” in Advances in Forty-first International Conference on Machine Learning, Vienna, Austria, 2024
2024
-
[15]
OPT-BENCH: evaluating LLM agent on large-scale search spaces optimization problems,
X. Li, J. Chen, X. Fang, S. Ding, H. Duan, Q. Liu, and K. Chen, “OPT-BENCH: evaluating LLM agent on large-scale search spaces optimization problems,” CoRR, vol. abs/2506.10764, 2025
arXiv 2025
-
[16]
LLMs for mathe- matical modeling: Towards bridging the gap between natural and math- ematical languages,
X. Huang, Q. Shen, Y . Hu, A. Gao, and B. Wang, “LLMs for mathe- matical modeling: Towards bridging the gap between natural and math- ematical languages,” in Findings of the Association for Computational Linguistics 2025, Albuquerque, New Mexico, 2025, pp. 2678–2710
2025
-
[17]
Benchmarking LLMs for optimization modeling and enhancing reasoning via reverse socratic synthesis,
Z. Yang, Y . Huang, W. Shi, L. Feng, L. Song, Y . Wang, X. Liang, and J. Tang, “Benchmarking LLMs for optimization modeling and enhancing reasoning via reverse socratic synthesis,” CoRR, vol. abs/2407.09887, 2024
arXiv 2024
-
[18]
OptiBench meets ReSocratic: Measure and improve LLMs for optimization modeling,
Z. Yang, Y . Wang, Y . Huang, Z. Guo, W. Shi, X. Han, L. Feng, L. Song, X. Liang, and J. Tang, “OptiBench meets ReSocratic: Measure and improve LLMs for optimization modeling,” in The Thirteenth International Conference on Learning Representations, Singapore, 2025
2025
-
[19]
Chain-of-Experts: When LLMs meet complex operations research problems,
Z. Xiao, D. Zhang, Y . Wu, L. Xu, Y . J. Wang, X. Han, X. Fu, T. Zhong, J. Zeng, M. Song, and G. Chen, “Chain-of-Experts: When LLMs meet complex operations research problems,” in The Twelfth International Conference on Learning Representations, Vienna, Austria, 2024
2024
-
[20]
Optitree: Hierarchical thoughts generation with tree search for LLM optimization modeling,
H. Liu, J. Wang, Y . Cai, X. Han, Y . Kuang, and J. HAO, “Optitree: Hierarchical thoughts generation with tree search for LLM optimization modeling,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=Ej20yjWMCj
2025
-
[21]
Llm for large-scale optimization model auto-formulation: A lightweight few-shot learning approach,
K. Liang, Y . Lu, J. Mao, S. Sun, C. Yang, C. Zeng, X. Jin, H. Qin, R. Zhu, and C.-P. Teo, “Llm for large-scale optimization model auto-formulation: A lightweight few-shot learning approach,” 2025. [Online]. Available: https://dx.doi.org/10.2139/ssrn.5329027
-
[22]
LLaMoCo: Instruction tuning of large language models for optimization code generation,
Z. Ma, H. Guo, J. Chen, G. Peng, Z. Cao, Y . Ma, and Y . Gong, “LLaMoCo: Instruction tuning of large language models for optimization code generation,” CoRR, vol. abs/2403.01131, 2024
arXiv 2024
-
[23]
Ner4Opt: Named entity recogni- tion for optimization modelling from natural language,
P. P. Dakle, S. Kadioglu, K. Uppuluri, R. Politi, P. Raghavan, S. Ral- labandi, and R. Srinivasamurthy, “Ner4Opt: Named entity recogni- tion for optimization modelling from natural language,” in Integration of Constraint Programming, Artificial Intelligence, and Operations Research - 20th International Conference, vol. 13884, Nice, France, 2023, pp. 299–319
2023
-
[24]
C. Zhou, T. Xu, J. Lin, and D. Ge, “Steporlm: A self-evolving framework with generative process supervision for operations research language models,” 2025. [Online]. Available: https://arxiv.org/abs/2509.22558
arXiv 2025
-
[25]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” in Advances in Neural Information Processing Systems 3...
2022
-
[26]
T ¨ULU 3: Pushing fron- tiers in open language model post-training,
N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F. Brahman, L. J. V . Miranda, A. Liu, N. Dziri, S. Lyu, Y . Gu, S. Malik, V . Graf, J. D. Hwang, J. Yang, R. L. Bras, O. Tafjord, C. Wilhelm, L. Soldaini, N. A. Smith, Y . Wang, P. Dasigi, and H. Hajishirzi, “T ¨ULU 3: Pushing fron- tiers in open language model post-training,” CoRR, vol. abs/2411...
Pith/arXiv arXiv 2024
-
[27]
Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations,
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui, “Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), Bangkok, Thailand, 2024, pp. 9426–9439
2024
-
[28]
Logic-RL: Unleashing LLM reasoning with rule- based reinforcement learning,
T. Xie, Z. Gao, Q. Ren, H. Luo, Y . Hong, B. Dai, J. Zhou, K. Qiu, Z. Wu, and C. Luo, “Logic-RL: Unleashing LLM reasoning with rule- based reinforcement learning,” CoRR, vol. abs/2502.14768, 2025
Pith/arXiv arXiv 2025
-
[29]
On designing effective RL reward at training time for LLM reasoning,
J. Gao, S. Xu, W. Ye, W. Liu, C. He, W. Fu, Z. Mei, G. Wang, and Y . Wu, “On designing effective RL reward at training time for LLM reasoning,” CoRR, vol. abs/2410.15115, 2024
arXiv 2024
-
[30]
CodeDPO: Aligning code models with self generated and verified source code,
K. Zhang, G. Li, Y . Dong, J. Xu, J. Zhang, J. Su, Y . Liu, and Z. Jin, “CodeDPO: Aligning code models with self generated and verified source code,” in Advances in the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), Vienna, Austria, 2025, pp. 15 854–15 871
2025
-
[31]
DeepSeek-Prover-V1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search,
H. Xin, Z. Z. Ren, J. Song, Z. Shao, W. Zhao, H. Wang, B. Liu, L. Zhang, X. Lu, Q. Du, W. Gao, H. Zhang, Q. Zhu, D. Yang, Z. Gou, Z. F. Wu, F. Luo, and C. Ruan, “DeepSeek-Prover-V1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search,” in Advances in the Thirteenth International Conference on Learning Representatio...
2025
-
[32]
Training software engineering agents and verifiers with SWE-gym,
J. Pan, X. Wang, G. Neubig, N. Jaitly, H. Ji, A. Suhr, and Y . Zhang, “Training software engineering agents and verifiers with SWE-gym,” in ICLR 2025 Third Workshop on Deep Learning for Code, 2025. JOURNAL OF LATEX CLASS FILES 11
2025
-
[33]
Solver-Informed RL: Grounding large language models for authentic optimization modeling,
Y . Chen, J. Xia, S. Shao, D. Ge, and Y . Ye, “Solver-Informed RL: Grounding large language models for authentic optimization modeling,” CoRR, vol. abs/2505.11792, 2025
arXiv 2025
-
[34]
Z. Ding, Z. Tan, J. Zhang, and T. Chen, “Or-r1: Automating modeling and solving of operations research optimization problem via test-time reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2511.09092
arXiv 2025
-
[35]
C. Tu, X. Zhang, R. Weng, R. Li, C. Zhang, Y . Bai, H. Yan, J. Wang, and X. Cai, “A survey on llm mid-training,” 2025. [Online]. Available: https://arxiv.org/abs/2510.23081
arXiv 2025
-
[36]
Qwen2.5-Coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Dang, A. Yang, R. Men, F. Huang, X. Ren, X. Ren, J. Zhou, and J. Lin, “Qwen2.5-Coder technical report,” CoRR, vol. abs/2409.12186, 2024
Pith/arXiv arXiv 2024
-
[37]
NL4Opt competition: Formulating optimization problems based on their natural language descriptions,
R. Ramamonjison, T. Yu, R. Li, H. Li, G. Carenini, B. Ghaddar, S. He, M. Mostajabdaveh, A. Banitalebi-Dehkordi, Z. Zhou, and Y . Zhang, “NL4Opt competition: Formulating optimization problems based on their natural language descriptions,” in Proceedings of the NeurIPS 2022 Competitions Track, vol. 220, 2022, pp. 189–203
2022
-
[38]
ICML 2024 Challenges on Automated Math Rea- soning - Track 3: Automated Optimization Problem-Solving with Code,
Ai4mathICML2024, “ICML 2024 Challenges on Automated Math Rea- soning - Track 3: Automated Optimization Problem-Solving with Code,” https://www.codabench.org/competitions/2438, 2024
2024
-
[39]
DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,” CoRR, vol. abs/2402.03300, 2024
Pith/arXiv arXiv 2024
-
[40]
ORLM: A customizable framework in training large models for automated optimization modeling,
C. Huang, Z. Tang, S. Hu, R. Jiang, X. Zheng, D. Ge, B. Wang, and Z. Wang, “ORLM: A customizable framework in training large models for automated optimization modeling,” Operations Research, May 2025
2025
-
[41]
C. Xiao, J. Cai, W. Zhao, B. Lin, G. Zeng, J. Zhou, Z. Zheng, X. Han, Z. Liu, and M. Sun, “Densing law of llms,” Nature Machine Intelligence, vol. 7, no. 11, pp. 1823–1833, Nov 2025. [Online]. Available: https://doi.org/10.1038/s42256-025-01137-0
-
[42]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qiu, “Qwen2...
Pith/arXiv arXiv 2024
-
[43]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
Pith/arXiv arXiv 2024
-
[44]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. Ta...
Pith/arXiv arXiv 2025
-
[45]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W...
Pith/arXiv arXiv 2025
-
[46]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. S. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, L. Marris, S. Petulla, C. Gaffney, A. Aharoni, N. Lintz, T. C. Pais, H. Jacobsson, I. Szpektor, N. Jiang, K. Haridasan, A. Omran, N. Saunshi, D. Bahri, G. Mishra, E. Chu, T. Boyd, B. Hekman, A. Parisi, C. Zhang, K. Kawintiranon, T. Bed...
Pith/arXiv arXiv 2025
-
[47]
GPT-5 system card,
OpenAI, “GPT-5 system card,” https://cdn.openai.com/ gpt-5-system-card.pdf, 2025
2025
-
[48]
Reflex- ion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, New Orleans, LA, 2023
2023
-
[49]
Training verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schul- man, “Training verifiers to solve math word problems,” CoRR, vol. abs/2110.14168, 2021
Pith/arXiv arXiv 2021
-
[50]
Measuring mathematical problem solv- ing with the MATH dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solv- ing with the MATH dataset,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[51]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” in 9th International Conference on Learning Representations, 2021
2021
-
[52]
RACE: large-scale ReAding comprehension dataset from examinations,
G. Lai, Q. Xie, H. Liu, Y . Yang, and E. H. Hovy, “RACE: large-scale ReAding comprehension dataset from examinations,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, M. Palmer, R. Hwa, and S. Riedel, Eds., 2017
2017
-
[53]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 2017
2017
-
[54]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
Pith/arXiv arXiv 2021
-
[55]
under a limited training budget. The objective is to construct a training set that simultaneously covers diverse JOURNAL OF LATEX CLASS FILES 15 optimization types and scenarios, while preserving the scenario proportions observed in the real distribution. Starting from the OptMATH-Train pool containing 201K problems, we label each instance with types and ...
-
[56]
Don’t give any explanation, just provide the converted pyomo code in the following format: ‘‘‘python [pyomo code here] ‘‘‘
-
[57]
Other solvers should not be utilized
Please note that the following solvers are available for use: ’glpk’, ’cbc’, ’ipopt ’, ’scip’. Other solvers should not be utilized
-
[58]
Please add ‘from pyomo.environ import *‘ at the beginning of your code
-
[59]
Please print the optimal objective value at the end of the code. **Gurobipy code: ** {gurobipy} JOURNAL OF LATEX CLASS FILES 17 This section provides the system prompt to guide MiniOpt models in autonomously selecting solvers after modeling op- timization problems. PROMPT FORSOLVERSELECTION **Solver Selection Guide: ** - ‘‘glpk‘‘: Best for small-to-medium...
-
[63]
SYSTEMPROMPT FORRL TRAINING You are a helpful assistant
Nonlinearity presence (use ipopt/scip) This section provides the system prompt used by MiniOpt models during reinforcement learning (RL) training. SYSTEMPROMPT FORRL TRAINING You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclo...
-
[64]
Detailed reasoning about the problem within <think> </think> tags
-
[65]
Write the corresponding five-element model (derived from your analysis)
-
[66]
Determine the mathematical properties of problem and select an appropriate solver from ’glpk’, ’cbc’, ’ipopt’, ’scip’
-
[67]
- Verify the five-element model fully captures the problem’s requirements
Recheck and correct if necessary at the end of the <think> </think> section. - Verify the five-element model fully captures the problem’s requirements. - Confirm no constraints/variables are missing or over-simplified. - Ensure the solver choice aligns with the problem’s mathematical properties
-
[68]
Provide the corresponding Pyomo code based on checked five-element model within < answer> </answer> tags. In mathematics, optimization problem can be modeled as the following expression $\\ min_{{\\boldsymbol{{x}} \\in \\mathcal{{X }}}} f(\\boldsymbol{{x}}), {{\\rm s.t.}} G(\\boldsymbol{{x}}) \\leq \\boldsymbol{{ c}}$, where $\\boldsymbol{{x}} = (x_1, x_2...
-
[69]
Variable types (continuous vs integer/ binary)
-
[70]
Linearity of objective/constraints
-
[71]
Problem scale (small: glpk/cbc, large: scip/ipopt)
-
[72]
‘‘‘python\n(.*?)‘‘‘
Nonlinearity presence (use ipopt/scip) Please select an appropriate solver based on the type and quantity of variables, objectives, and constraints. After thinking, when you finally reach the five -element model, you should give the corresponding Pyomo code within the < answer> </answer> tags, i.e., <answer> ‘‘‘python\n code here‘‘‘ </answer>. The user wi...
-
[73]
Linear Programming (LP): Problems with linear objective function and linear constraints, all continuous variables
-
[74]
Integer Programming (IP): Problems with linear or nonlinear components where ALL variables are discrete/integer
-
[75]
Mixed Integer Linear Programming (MILP): Problems with linear components containing BOTH continuous and discrete variables
-
[76]
Nonlinear Programming (NLP): Problems with nonlinear objective function and/or nonlinear constraints (variables may be continuous/discrete)
-
[77]
Combinatorial Optimization (CO): Problems focused on selecting/discrete structures (graphs, permutations, sets) with typically binary variables
-
[78]
Multi-objective Programming (MOP): Problems explicitly optimizing multiple conflicting objectives simultaneously
-
[79]
Second-Order Cone Programming (SOCP): Problems with a linear objective function , linear constraints, and second-order cone constraints (e.g., \(\|Ax + b\| \leq cˆT x + d\)) # Problem: {{Question}} # Output Analyze the mathematical structure step by step and classify its type. Finally, output the type abbreviation in the following format: Type: Abbreviati...
-
[80]
Supply Chain: Decisions about inventory management, distribution network, warehousing operations
-
[81]
Finance: Decisions about portfolio management, investments, risk management, financial planning
-
[82]
Manufacturing: Decisions about production processes, quality control, factory operations
-
[83]
Transportation: Decisions about routing, vehicle scheduling, fleet management, traffic flow, carrier selection
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.