PermuQuant: Lowering Per-Group Quantization Error by Reordering Channels for Diffusion Models
Pith reviewed 2026-06-30 22:40 UTC · model grok-4.3
The pith
Reordering channels by joint second-moment similarity reduces per-group quantization error for low-bit diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PermuQuant shows that channel ordering is a controllable factor in per-group quantization; sorting channels by a joint second-moment criterion places statistically similar channels in the same group, and a calibration acceptance rule applies the reordering only when it reduces error on held-out calibration inputs, with the permutation absorbed offline into the model.
What carries the argument
Joint second-moment criterion that ranks channels so those with comparable activation and weight statistics share a quantization scale.
If this is right
- Lower per-group quantization error at W4A4 and similar low-bit settings compared with existing PTQ baselines.
- Up to 1.7× single-step speedup and 3.5× DiT memory reduction on FLUX.1-dev under W4A4 NVFP4.
- Permutations absorbed offline so inference speed and memory gains require no extra runtime operations.
- Consistent gains across multiple large diffusion models without retraining.
Where Pith is reading between the lines
- The same reordering idea could be tested on transformer-based models outside the diffusion family to check whether the second-moment grouping principle transfers.
- Combining the channel permutation with existing outlier-suppression or mixed-precision techniques might produce additive error reductions.
- The offline absorption step suggests the method can be applied once during model export and then used in any inference engine that supports static weight layouts.
Load-bearing premise
Channels grouped by similar second-moment statistics will incur lower error under a shared scale, and the calibration rule selects permutations that improve performance on unseen inputs.
What would settle it
Measure the quantization error or generation quality (FID or similar) on a held-out test set after applying the accepted permutations versus the original ordering; absence of consistent reduction would falsify the central claim.
Figures








read the original abstract
Large-scale visual generative models have achieved remarkable performance. However, their high computational and memory costs make deployment challenging in resource-constrained scenarios, such as interactive applications and personal single-GPU usage. Post-training quantization (PTQ) offers a practical solution by compressing pretrained models without expensive retraining. However, existing PTQ methods still suffer from severe quality degradation under extremely low-bit settings. In this paper, we identify channel ordering as an important but underexplored factor in per-group quantization. In this setting, each contiguous group shares one quantization scale. When channels with very different statistics are placed in the same group, the scale can be dominated by outliers and cause large quantization errors. Based on this observation, we propose PermuQuant, a simple and effective PTQ framework for low-bit diffusion models. PermuQuant sorts channels by a joint second-moment criterion before per-group quantization, placing channels with similar activation and weight statistics into the same group. It further uses a calibration-based acceptance rule to apply reordering only when the selected permutation reduces quantization error on calibration data. The selected permutations are absorbed into adjacent modules or applied to weights offline, avoiding explicit runtime permutation operations. Extensive experiments on multiple large diffusion models show that PermuQuant consistently reduces quantization error and outperforms existing PTQ baselines. On FLUX.1-dev with an RTX 5090, PermuQuant achieves up to a 1.7$\times$ single step speedup and reduces the DiT memory footprint by 3.5$\times$ under W4A4 NVFP4 quantization. Code will be available at https://github.com/yscheng04/PermuQuant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
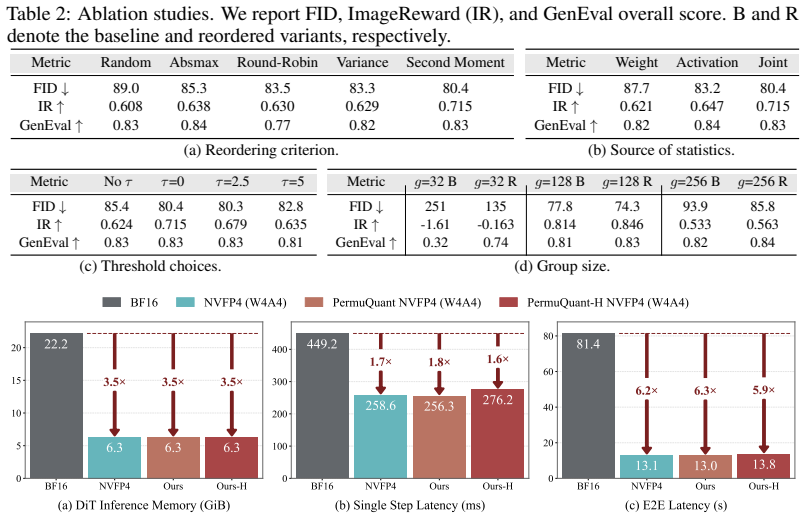
Summary. The paper proposes PermuQuant, a post-training quantization (PTQ) method for diffusion models that reorders channels according to a joint second-moment criterion before applying per-group quantization. Channels with similar activation and weight statistics are grouped to avoid outlier-dominated scales. A calibration-based acceptance rule decides whether to apply the permutation, which is then absorbed into adjacent modules or weights offline. The central empirical claim is that this consistently lowers quantization error relative to existing PTQ baselines and yields up to 1.7× single-step speedup and 3.5× DiT memory reduction on FLUX.1-dev under W4A4 NVFP4 quantization.
Significance. If the reported gains hold under proper controls, the work supplies a lightweight, training-free technique that directly targets a known weakness of per-group quantization in large generative models. The offline absorption of permutations and the promise of public code are practical strengths that would aid reproducibility.
major comments (3)
- [§3] §3 (method description): the joint second-moment criterion produces a single fixed permutation per layer derived from a finite calibration set at selected timesteps. Because diffusion models exhibit strong timestep-dependent variation in activation distributions, the paper must demonstrate that groupings optimal on calibration data do not increase error at other timesteps; no such analysis or cross-timestep ablation is supplied, leaving the generalization claim unsupported.
- [§4] §4 (experiments): the acceptance rule only verifies error reduction on the calibration distribution, yet the central claim is that PermuQuant “consistently reduces quantization error” on held-out runs. Without reporting calibration-set size, timestep sampling strategy, or error metrics on a disjoint set of timesteps, it is impossible to rule out overfitting to the calibration distribution.
- [Table 1 / Figure 2] Table 1 / Figure 2 (quantitative results): the reported speed and memory gains on FLUX.1-dev are presented without error bars, multiple random seeds, or an explicit statement of the calibration data used; these omissions are load-bearing because the method’s benefit is defined by the acceptance rule’s ability to select permutations that generalize.
minor comments (2)
- The abstract states that code will be released at a GitHub link, but the manuscript itself contains no pointer to supplementary material or a reproducibility checklist.
- Notation for the joint second-moment criterion is introduced without an explicit equation number; readers must infer the precise formula from surrounding text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will incorporate the requested analyses and clarifications in a revised version.
read point-by-point responses
-
Referee: [§3] §3 (method description): the joint second-moment criterion produces a single fixed permutation per layer derived from a finite calibration set at selected timesteps. Because diffusion models exhibit strong timestep-dependent variation in activation distributions, the paper must demonstrate that groupings optimal on calibration data do not increase error at other timesteps; no such analysis or cross-timestep ablation is supplied, leaving the generalization claim unsupported.
Authors: We agree that an explicit cross-timestep analysis is needed to support generalization. Our calibration samples activations across a range of timesteps, but we did not provide a dedicated ablation on unseen timesteps. In the revision we will add such an ablation demonstrating that the selected permutations do not increase error outside the calibration timesteps. revision: yes
-
Referee: [§4] §4 (experiments): the acceptance rule only verifies error reduction on the calibration distribution, yet the central claim is that PermuQuant “consistently reduces quantization error” on held-out runs. Without reporting calibration-set size, timestep sampling strategy, or error metrics on a disjoint set of timesteps, it is impossible to rule out overfitting to the calibration distribution.
Authors: We will revise the experimental section to report the exact calibration-set size, the timestep sampling strategy, and error metrics evaluated on a disjoint set of timesteps. This will directly address the overfitting concern and strengthen the consistency claim. revision: yes
-
Referee: [Table 1 / Figure 2] Table 1 / Figure 2 (quantitative results): the reported speed and memory gains on FLUX.1-dev are presented without error bars, multiple random seeds, or an explicit statement of the calibration data used; these omissions are load-bearing because the method’s benefit is defined by the acceptance rule’s ability to select permutations that generalize.
Authors: We acknowledge the value of reporting variability. The revised manuscript will add error bars from multiple random seeds to Table 1 and Figure 2 and will explicitly describe the calibration data used for the FLUX.1-dev experiments. revision: yes
Circularity Check
Empirical PTQ heuristic with no load-bearing circular steps
full rationale
The paper presents PermuQuant as an empirical post-training quantization method that reorders channels according to a joint second-moment criterion and applies a calibration acceptance rule to retain only permutations that reduce measured quantization error on the calibration set. All reported gains are obtained by direct experimental comparison against baselines on held-out model evaluations; no equation, uniqueness theorem, or self-citation is invoked to derive the improvement by construction from the inputs themselves. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Channel ordering materially affects per-group quantization error when statistics differ within a group
Forward citations
Cited by 1 Pith paper
-
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
OrbitQuant is a data-agnostic PTQ technique for DiTs that uses RPBH rotation in a normalized basis to enable a single codebook across all inputs, achieving SOTA low-bit performance on FLUX.1, CogVideoX and similar models.
Reference graph
Works this paper leans on
-
[1]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. InNeurIPS, 2024
2024
-
[2]
ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv, 2022
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, et al. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv, 2022
2022
-
[3]
Demystifying mmd gans.arXiv, 2018
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv, 2018
2018
-
[4]
Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv, 2025
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv, 2025
2025
-
[5]
Efficientqat: Efficient quantization-aware training for large language models
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, and Ping Luo. Efficientqat: Efficient quantization-aware training for large language models. InACL, 2025
2025
-
[6]
Asyncdiff: Parallelizing diffusion models by asynchronous denoising
Zigeng Chen, Xinyin Ma, Gongfan Fang, Zhenxiong Tan, and Xinchao Wang. Asyncdiff: Parallelizing diffusion models by asynchronous denoising. InNeurIPS, 2024
2024
-
[7]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, 2021
2021
-
[8]
Pipefusion: Patch-level pipeline parallelism for diffusion transformers inference.arXiv, 2024
Jiarui Fang, Jinzhe Pan, Aoyu Li, Xibo Sun, and Jiannan Wang. Pipefusion: Patch-level pipeline parallelism for diffusion transformers inference.arXiv, 2024
2024
-
[9]
Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv, 2022
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv, 2022
2022
-
[10]
Geneval: An object-focused framework for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment. InNeurIPS, 2023
2023
-
[11]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, 2017
2017
-
[12]
Classifier-free diffusion guidance.arXiv, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv, 2022
2022
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
2020
-
[14]
Convrot: Rotation-based plug-and-play 4-bit quantization for diffusion transformers.arXiv, 2025
Feice Huang, Zuliang Han, Xing Zhou, Yihuang Chen, Lifei Zhu, and Haoqian Wang. Convrot: Rotation-based plug-and-play 4-bit quantization for diffusion transformers.arXiv, 2025
2025
-
[15]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[16]
Playground v2
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi. Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation.arXiv, 2024
2024
-
[17]
Distrifusion: Distributed parallel inference for high-resolution diffusion models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Kai Li, and Song Han. Distrifusion: Distributed parallel inference for high-resolution diffusion models. InCVPR, 2024
2024
-
[18]
Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models. InICLR, 2025
2025
-
[19]
Q-diffusion: Quantizing diffusion models
Xiuyu Li, Yijiang Liu, Long Lian, Huanrui Yang, Zhen Dong, Daniel Kang, Shanghang Zhang, and Kurt Keutzer. Q-diffusion: Quantizing diffusion models. InICCV, 2023. 10
2023
-
[20]
Snapfusion: Text-to-image diffusion model on mobile devices within two seconds
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snapfusion: Text-to-image diffusion model on mobile devices within two seconds. InNeurIPS, 2023
2023
-
[21]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InECCV, 2014
2014
-
[22]
From reusing to forecasting: Accelerating diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with taylorseers. InICCV, 2025
2025
-
[23]
Clq: Cross-layer guided orthogonal- based quantization for diffusion transformers.arXiv, 2025
Kai Liu, Shaoqiu Zhang, Linghe Kong, and Yulun Zhang. Clq: Cross-layer guided orthogonal- based quantization for diffusion transformers.arXiv, 2025
2025
-
[24]
Low-bit model quantization for deep neural networks: A survey.arXiv, 2025
Kai Liu, Qian Zheng, Kaiwen Tao, Zhiteng Li, Haotong Qin, Wenbo Li, Yong Guo, Xianglong Liu, Linghe Kong, Guihai Chen, et al. Low-bit model quantization for deep neural networks: A survey.arXiv, 2025
2025
-
[25]
Pseudo numerical methods for diffusion models on manifolds.arXiv, 2022
Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds.arXiv, 2022
2022
-
[26]
Reactnet: Towards precise binary neural network with generalized activation functions
Zechun Liu, Zhiqiang Shen, Marios Savvides, and Kwang-Ting Cheng. Reactnet: Towards precise binary neural network with generalized activation functions. InECCV, 2020
2020
-
[27]
Spinquant: Llm quantization with learned rotations.arXiv, 2024
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations.arXiv, 2024
2024
-
[28]
Post-training quantization for vision transformer
Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. Post-training quantization for vision transformer. InNeurIPS, 2021
2021
-
[29]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. InNeurIPS, 2022
2022
-
[30]
Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv, 2023
2023
-
[31]
Accelerating diffusion models via early stop of the diffusion process.arXiv, 2022
Zhaoyang Lyu, Xudong Xu, Ceyuan Yang, Dahua Lin, and Bo Dai. Accelerating diffusion models via early stop of the diffusion process.arXiv, 2022
2022
-
[32]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InCVPR, 2024
2024
-
[33]
Daniel Marco and David L. Neuhoff. The validity of the additive noise model for uniform scalar quantizers.TIT, 2005
2005
-
[34]
Training binary neural networks with real-to-binary convolutions
Brais Martinez, Jing Yang, Adrian Bulat, and Georgios Tzimiropoulos. Training binary neural networks with real-to-binary convolutions. InICLR, 2020
2020
-
[35]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InCVPR, 2023
2023
-
[36]
A white paper on neural network quantization.arXiv, 2021
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart Van Baalen, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv, 2021
2021
-
[37]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InICML, 2021
2021
-
[38]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InCVPR, 2022
2022
-
[39]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[40]
Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv, 2023. 11
2023
-
[41]
Forward and backward information retention for accurate binary neural networks
Haotong Qin, Ruihao Gong, Xianglong Liu, Mingzhu Shen, Ziran Wei, Fengwei Yu, and Jingkuan Song. Forward and backward information retention for accurate binary neural networks. InCVPR, 2020
2020
-
[42]
Quantsr: Accurate low-bit quantization for efficient image super-resolution
Haotong Qin, Yulun Zhang, Yifu Ding, Yifan liu, Xianglong Liu, Martin Danelljan, and Fisher Yu. Quantsr: Accurate low-bit quantization for efficient image super-resolution. InNeurIPS, 2023
2023
-
[43]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[44]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, 2015
2015
-
[45]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv, 2022
2022
-
[46]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InECCV, 2024
2024
-
[47]
Post-training quantization on diffusion models
Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, and Yan Yan. Post-training quantization on diffusion models. InCVPR, 2023
2023
-
[48]
Omniquant: Omnidirectionally calibrated quantiza- tion for large language models.arXiv, 2023
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantiza- tion for large language models.arXiv, 2023
2023
-
[49]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InICML, 2015
2015
-
[50]
Denoising diffusion implicit models.arXiv, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv, 2020
2020
-
[51]
Score-based generative modeling through stochastic differential equations.arXiv, 2020
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv, 2020
2020
-
[52]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, 2023
2023
-
[53]
Efficient neural network deployment for microcontroller.arXiv, 2020
Hasan Unlu. Efficient neural network deployment for microcontroller.arXiv, 2020
2020
-
[54]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InICML, 2023
2023
-
[55]
Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv, 2025
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv, 2025
2025
-
[56]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. InNeurIPS, 2023
2023
-
[57]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. InNeurIPS, 2024
2024
-
[58]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, 2024
2024
-
[59]
Fast sampling of diffusion models with exponential integrator.arXiv, 2022
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator.arXiv, 2022. 12 A Table of Contents In the supplementary material, we provide complete proofs, implementation details, analysis, and results, including: • Sec. B: Proofs of the expected quantization error bound, the optimality of second-moment sorting, and the a...
2022
-
[60]
, x[π(K)]from global memory; 16
loads one activation row asx[π(1)], . . . , x[π(K)]from global memory; 16
-
[61]
computes the RMS statistic or the mean and variance on the loaded values
-
[62]
applies the corresponding channel-wise scale or modulation
-
[63]
In this way, the reordering is absorbed into the mandatory input-read stage of normalization
writes the reordered normalized output contiguously. In this way, the reordering is absorbed into the mandatory input-read stage of normalization. The fused kernel avoids a standalone reorder pass over the activation tensor. The only additional work is reading the permutation indices and generating indexed memory addresses. This is much cheaper than mater...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.