OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
Pith reviewed 2026-07-03 14:54 UTC · model grok-4.3
The pith
A randomized rotation creates one fixed marginal for every DiT activation coordinate, letting a single codebook quantize across all timesteps, prompts, and modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
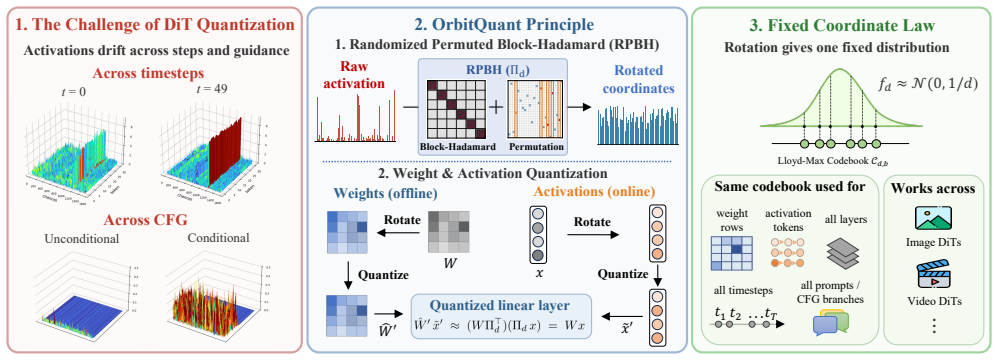
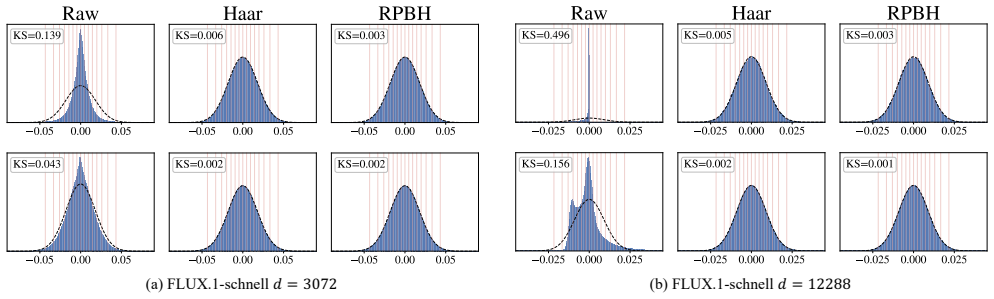
In the normalized rotated basis produced by the randomized permuted block-Hadamard rotation, each coordinate concentrates around one fixed, known marginal distribution regardless of the input, timestep, prompt, or guidance branch, so a single Lloyd-Max codebook suffices for all layers and all steps of a given input dimension; the same recipe extends unchanged from image to video diffusion transformers.
What carries the argument
The randomized permuted block-Hadamard (RPBH) rotation that maps activations to a coordinate-wise marginal distribution fixed and known in advance.
If this is right
- A single codebook per input dimension handles every timestep and prompt without recalibration.
- The identical quantizer applies to both image and video diffusion transformers with no per-modality changes.
- Weight rows can be rotated offline so the rotation cancels inside each linear layer and only activation rotation remains at inference.
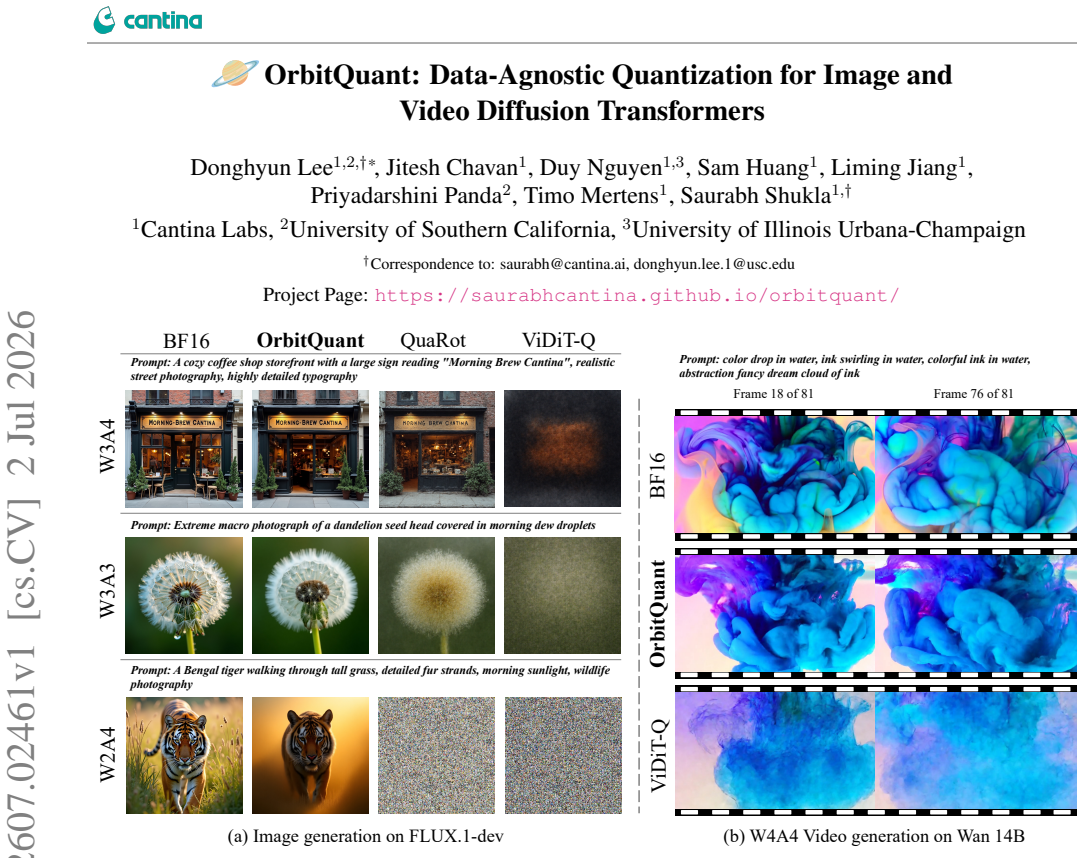
- Usable generation quality is retained at W2A4 for image diffusion transformers.
Where Pith is reading between the lines
- The approach removes the usual requirement to store or regenerate calibration sets when models are updated or switched between image and video tasks.
- Any architecture whose activations exhibit large distribution shifts across inference steps could potentially use the same rotation-plus-fixed-codebook pattern.
- If the marginal after rotation truly is universal, the method could be combined with other linear transforms that further sparsify or decorrelate coordinates.
Load-bearing premise
The RPBH rotation produces a coordinate-wise marginal that stays fixed and known independently of the specific activation distribution, timestep, prompt, or guidance branch.
What would settle it
Collect rotated activation coordinates from the same layer at two widely separated timesteps or prompts, compute their empirical histograms, and test whether the histograms match each other and the expected fixed marginal to within the tolerance set by the target bit width.
Figures

read the original abstract
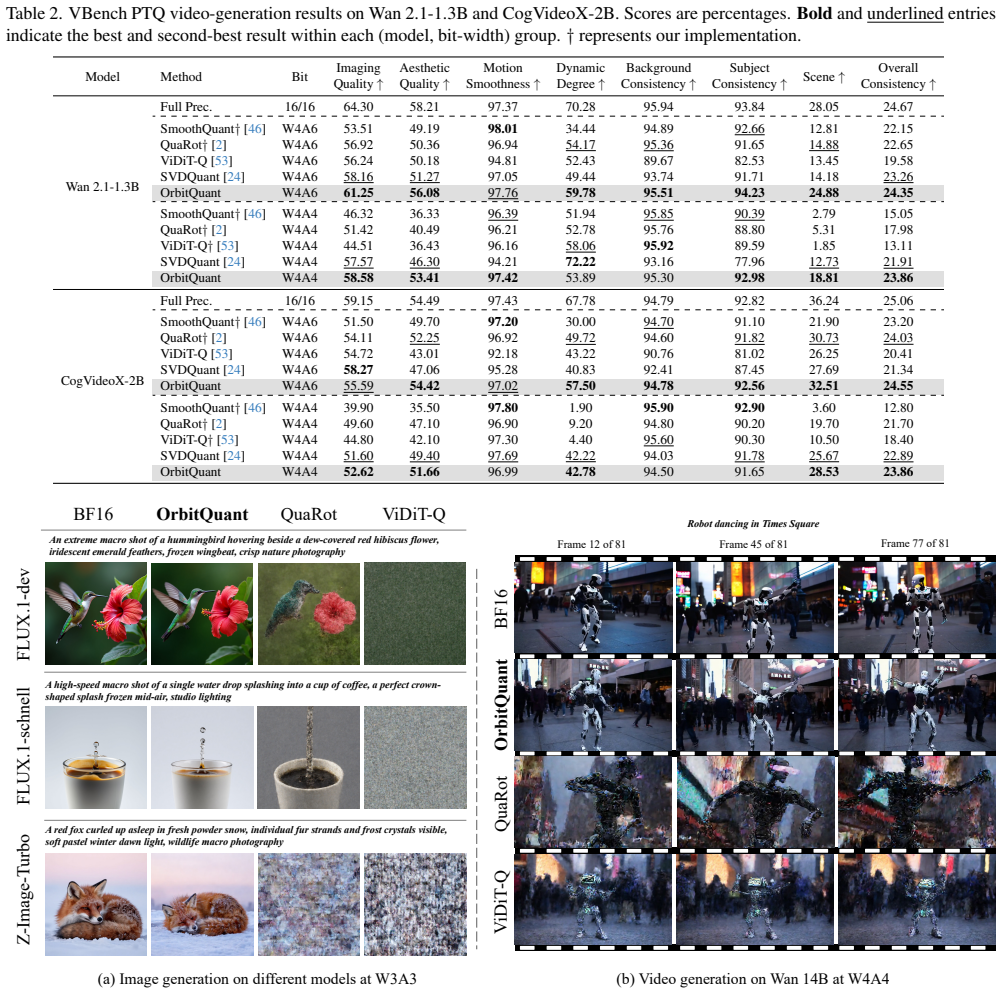
Diffusion transformers (DiTs) achieve state-of-the-art image and video generation, but their multi-step sampling and growing parameter count make inference expensive. Post-training quantization (PTQ) is the natural remedy, yet DiT activations shift across timesteps, prompts, and guidance branches, forcing prior methods to re-fit calibration data for every new checkpoint or modality. We present OrbitQuant, a data-agnostic weight-activation quantizer that bypasses range estimation by quantizing in a normalized, rotated basis. In this basis, a randomized permuted block-Hadamard (RPBH) rotation concentrates each coordinate around one fixed, known marginal regardless of the input, so a single Lloyd-Max codebook serves all timesteps, prompts, and layers of a given input dimension. We extend the same quantizer to weight rows offline, absorbing the rotation into the weights so that it cancels inside each linear layer and only a forward rotation on the activations remains at runtime. The same recipe transfers from image to video with no per-modality tuning. Across FLUX.1, Z-Image-Turbo, Wan 2.1, and CogVideoX, it sets the state of the art for PTQ at several low-bit settings. It also pushes PTQ of image diffusion transformers to W2A4 with usable generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OrbitQuant, a post-training quantization (PTQ) technique for diffusion transformers (DiTs) in image and video generation. It normalizes activations to the unit sphere and applies a randomized permuted block-Hadamard (RPBH) rotation to produce a coordinate-wise marginal distribution that is fixed and independent of the input vector, timestep, prompt, or modality. This allows a single Lloyd-Max codebook per dimension to quantize all activations without per-instance range estimation or calibration data. The rotation is absorbed into the weights offline (W' = W R^T) so that only a forward activation rotation remains at inference. The same recipe is applied to image and video models without modality-specific tuning, and experiments on FLUX.1, Z-Image-Turbo, Wan 2.1, and CogVideoX report state-of-the-art PTQ results, including usable quality at W2A4.
Significance. If the invariance property holds, the approach removes a major practical bottleneck in DiT quantization by eliminating data-dependent calibration across timesteps and modalities. The theoretical grounding (unit-sphere normalization plus orthogonal transformation) is parameter-free and directly yields a known marginal, which is a clear strength. Empirical transfer to video models and low-bit results (W2A4) would represent a meaningful advance over prior PTQ methods that require re-fitting.
minor comments (3)
- The abstract and introduction state that the marginal is 'fixed and known' after RPBH rotation, but the manuscript should explicitly derive or cite the closed-form marginal (e.g., the distribution of a coordinate of a uniform vector on the unit sphere in dimension d) to make the 'known' claim fully reproducible.
- Section describing the weight-absorption step should clarify whether the absorbed rotation affects the weight quantization codebook or only the activation path, and whether any rounding error is introduced in the offline W' computation.
- The experimental tables would benefit from reporting the exact bit-width configurations (e.g., W4A4 vs. W2A4) and the number of calibration samples used by the competing baselines for fair comparison.
Simulated Author's Rebuttal
We thank the referee for the careful reading, accurate summary of the method, and the recommendation to accept. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The derivation rests on the geometric fact that unit-sphere normalization followed by any orthogonal matrix (RPBH being one instance) yields a coordinate marginal depending only on dimension; the Lloyd-Max codebook is then computed from that fixed marginal and the rotation is absorbed by the standard W' = W R^T identity. No equation or claim in the abstract reduces a prediction to a fitted quantity defined from the same activations, nor does any load-bearing step invoke a self-citation, uniqueness theorem, or ansatz smuggled from prior work by the same authors. The argument is therefore self-contained against external mathematical benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The fast johnson– lindenstrauss transform and approximate nearest neighbors
Nir Ailon and Bernard Chazelle. The fast johnson– lindenstrauss transform and approximate nearest neighbors. SIAM Journal on computing, 39(1):302–322, 2009. 4
2009
-
[2]
Quarot: Outlier- free 4-bit inference in rotated llms.Advances in Neural In- formation Processing Systems, 37:100213–100240, 2024
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alis- tarh, Torsten Hoefler, and James Hensman. Quarot: Outlier- free 4-bit inference in rotated llms.Advances in Neural In- formation Processing Systems, 37:100213–100240, 2024. 1, 2, 4, 5, 6, 7, 8, 3
2024
-
[3]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22669–22679, 2023. 2
2023
-
[4]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christo- pher M De Sa. Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023. 2
2023
-
[6]
Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. In European Conference on Computer Vision, pages 74–91. Springer, 2024. 2
2024
-
[7]
Q-dit: Ac- curate post-training quantization for diffusion transformers
Lei Chen, Yuan Meng, Chen Tang, Xinzhu Ma, Jingyan Jiang, Xin Wang, Zhi Wang, and Wenwu Zhu. Q-dit: Ac- curate post-training quantization for diffusion transformers. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 28306–28315, 2025. 2, 5, 6
2025
-
[8]
PermuQuant: Lowering Per-Group Quantization Error by Reordering Channels for Diffusion Models
Yongsen Cheng, Kai Liu, Kaiwen Tao, Junxian Li, Zhixin Wang, Zhikai Chen, Renjing Pei, and Yulun Zhang. Per- muquant: Lowering per-group quantization error by re- ordering channels for diffusion models.arXiv preprint arXiv:2605.09503, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, De- nis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless llm weight compression.arXiv preprint arXiv:2306.03078, 2023. 2
-
[10]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[11]
Weilun Feng, Haotong Qin, Chuanguang Yang, Xiangqi Li, Han Yang, Yuqi Li, Zhulin An, Libo Huang, Michele Magno, and Yongjun Xu. S2 q-vdit: Accurate quantized video diffu- sion transformer with salient data and sparse token distilla- tion.arXiv preprint arXiv:2508.04016, 2025. 2
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Hongyaoxing Gu, Lijuan Hu, Liye Yu, Haowei Li, and Fangfang Liu. Lopro: Enhancing low-rank quantiza- tion via permuted block-wise rotation.arXiv preprint arXiv:2601.19675, 2026. 4
-
[14]
Fast matrix multi- plications for lookup table-quantized llms
Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric Xing, and Yoon Kim. Fast matrix multi- plications for lookup table-quantized llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12419–12433, 2024. 4
2024
-
[15]
Polarquant: Vector quantization with po- lar transformation
Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, and Amir Zandieh. Polarquant: Vector quantization with po- lar transformation. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. 2
2026
-
[16]
Efficientdm: Efficient quantization-aware fine- tuning of low-bit diffusion models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. Efficientdm: Efficient quantization-aware fine- tuning of low-bit diffusion models. InInternational Con- ference on Learning Representations, pages 15731–15750,
-
[17]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
2020
-
[18]
Xing Hu, Yuan Cheng, Dawei Yang, Zukang Xu, Zhihang Yuan, Jiangyong Yu, Chen Xu, Zhe Jiang, and Sifan Zhou. Ostquant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting.arXiv preprint arXiv:2501.13987, 2025. 2
-
[19]
Feice Huang, Zuliang Han, Xing Zhou, Yihuang Chen, Lifei Zhu, and Haoqian Wang. Convrot: Rotation-based plug- and-play 4-bit quantization for diffusion transformers.arXiv preprint arXiv:2512.03673, 2025. 3
-
[20]
Qvgen: Pushing the limit of quantized video generative models.arXiv preprint arXiv:2505.11497, 2025
Yushi Huang, Ruihao Gong, Jing Liu, Yifu Ding, Cheng- tao Lv, Haotong Qin, and Jun Zhang. Qvgen: Pushing the limit of quantized video generative models.arXiv preprint arXiv:2505.11497, 2025. 2, 5, 3
-
[21]
Squeezellm: Dense-and-sparse quanti- zation,
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization.arXiv preprint arXiv:2306.07629, 2023. 2
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
-
[24]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, 9 and Song Han. Svdquant: Absorbing outliers by low- rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024. 2, 5, 6, 7, 3
-
[25]
Q-dm: An efficient low-bit quantized dif- fusion model.Advances in neural information processing systems, 36:76680–76691, 2023
Yanjing Li, Sheng Xu, Xianbin Cao, Xiao Sun, and Baochang Zhang. Q-dm: An efficient low-bit quantized dif- fusion model.Advances in neural information processing systems, 36:76680–76691, 2023. 3
2023
-
[26]
Dvd-quant: Data-free video diffusion transformers quantization.arXiv preprint arXiv:2505.18663, 2025
Zhiteng Li, Hanxuan Li, Junyi Wu, Kai Liu, Haotong Qin, Linghe Kong, Guihai Chen, Yulun Zhang, and Xiaokang Yang. Dvd-quant: Data-free video diffusion transformers quantization.arXiv preprint arXiv:2505.18663, 2025. 3, 2
-
[27]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms.Advances in Neural Infor- mation Processing Systems, 37:87766–87800, 2024
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms.Advances in Neural Infor- mation Processing Systems, 37:87766–87800, 2024. 2, 4
2024
-
[28]
Awq: Activation-aware weight quantization for on-device llm compression and accelera- tion.Proceedings of machine learning and systems, 6:87– 100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and accelera- tion.Proceedings of machine learning and systems, 6:87– 100, 2024. 2
2024
-
[29]
Spin- quant: Llm quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge So- ran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spin- quant: Llm quantization with learned rotations. InIn- ternational Conference on Learning Representations, pages 92009–92032, 2025. 2
2025
-
[30]
Least squares quantization in pcm.IEEE trans- actions on information theory, 28(2):129–137, 1982
Stuart Lloyd. Least squares quantization in pcm.IEEE trans- actions on information theory, 28(2):129–137, 1982. 3
1982
-
[31]
Quantizing for minimum distortion.IRE Transac- tions on Information Theory, 6(1):7–12, 1960
Joel Max. Quantizing for minimum distortion.IRE Transac- tions on Information Theory, 6(1):7–12, 1960. 3
1960
-
[32]
Francesco Mezzadri. How to generate random matrices from the classical compact groups.arXiv preprint math- ph/0609050, 2006. 3
-
[33]
Sora: Creating video from text.https:// openai.com/sora, 2024
OpenAI. Sora: Creating video from text.https:// openai.com/sora, 2024. Accessed: 2024-02-15. 2
2024
-
[34]
Lut-gemm: Quan- tized matrix multiplication based on luts for efficient in- ference in large-scale generative language models
Gunho Park, Minsub Kim, Sungjae Lee, Jeonghoon Kim, Beomseok Kwon, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, Dongsoo Lee, et al. Lut-gemm: Quan- tized matrix multiplication based on luts for efficient in- ference in large-scale generative language models. InIn- ternational Conference on Learning Representations, pages 38069–38086, 2024. 4
2024
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[37]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 2
2022
-
[38]
Pushing the Limits of Block Rotations in Post-Training Quantization
Sai Sanjeet, Ian Colbert, Pablo Monteagudo-Lago, Giuseppe Franco, Yaman Umuroglu, and Nicholas J Fraser. Pushing the limits of block rotations in post-training quantization. arXiv preprint arXiv:2601.22347, 2026. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426, 2024
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, et al. Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426, 2024. 2
-
[41]
Improved analysis of the subsampled random- ized hadamard transform.Advances in Adaptive Data Anal- ysis, 3(01n02):115–126, 2011
Joel A Tropp. Improved analysis of the subsampled random- ized hadamard transform.Advances in Adaptive Data Anal- ysis, 3(01n02):115–126, 2011. 4
2011
-
[42]
Quip#: Even better llm quantization with hadamard incoherence and lattice code- books.Proceedings of machine learning research, 235: 48630, 2024
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: Even better llm quantization with hadamard incoherence and lattice code- books.Proceedings of machine learning research, 235: 48630, 2024. 2, 4, 8
2024
-
[43]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Ptq4dit: Post-training quantization for diffu- sion transformers.Advances in neural information process- ing systems, 37:62732–62755, 2024
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, and Yan Yan. Ptq4dit: Post-training quantization for diffu- sion transformers.Advances in neural information process- ing systems, 37:62732–62755, 2024. 2
2024
-
[46]
Smoothquant: Accurate and effi- cient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and effi- cient post-training quantization for large language models. In International conference on machine learning, pages 38087– 38099. PMLR, 2023. 2, 5, 6, 7, 3
2023
-
[47]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al. Sana: Efficient high-resolution image syn- thesis with linear diffusion transformers.arXiv preprint arXiv:2410.10629, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
RobuQ: Pushing DiTs to W1.58A2 via Robust Activation Quantization
Kaicheng Yang, Xun Zhang, Haotong Qin, Yucheng Lin, Kaisen Yang, Xianglong Yan, and Yulun Zhang. Robuq: Pushing dits to w1. 58a2 via robust activation quantization. arXiv preprint arXiv:2509.23582, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Lianwei Yang, Haokun Lin, Tianchen Zhao, Yichen Wu, Hongyu Zhu, Ruiqi Xie, Zhenan Sun, Yu Wang, and Qingyi Gu. Lrq-dit: Log-rotation post-training quantization of dif- fusion transformers for image and video generation.arXiv preprint arXiv:2508.03485, 2025. 2
-
[50]
Cogvideox: Text-to- video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xi- 10 aohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to- video diffusion models with an expert transformer. InIn- ternational Conference on Learning Representations, pages 83048–83077, 2025. 2, 6
2025
-
[51]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mir- rokni. Turboquant: Online vector quantization with near- optimal distortion rate.arXiv preprint arXiv:2504.19874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Shaoqiu Zhang, Zizhong Ding, Kaicheng Yang, Junyi Wu, Xianglong Yan, Xi Li, Bingnan Duan, Jianping Fang, and Yulun Zhang. Adatsq: Pushing the pareto frontier of dif- fusion transformers via temporal-sensitivity quantization. arXiv preprint arXiv:2602.09883, 2026. 2, 5, 6
-
[53]
Tianchen Zhao, Tongcheng Fang, Haofeng Huang, Enshu Liu, Rui Wan, Widyadewi Soedarmadji, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, et al. Vidit-q: Efficient and accurate quantization of diffusion transformers for im- age and video generation.arXiv preprint arXiv:2406.02540,
-
[54]
Proof Sketch for RPBH Incoherence Setup.Fix a unit vector ˜x∈R d and writed=kh
1, 2, 5, 6, 7, 3 11 OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers Supplementary Material A. Proof Sketch for RPBH Incoherence Setup.Fix a unit vector ˜x∈R d and writed=kh. Let y=P π˜xhave blocksy (j) ∈R h with massesM j = ∥y(j)∥2 2 summing to1, outputsz (j) =H hDjy(j) with (Hh)li =±1/ √ handD j Rademacher, andµ ∞ =∥ ˜x∥...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.